




点击上方蓝字关注我们

1
执行计划的生成
语法分析:将查询语句解析成一棵语法树。 语义分析:对语法树进行语义分析,包括表名解析、列名解析、类型检查等等。 优化器:对查询语句进行分布式查询优化,生成最优的执行计划。 执行:将优化后的执行计划转换成可执行的代码,然后通过与后端存储shard 做交互来完成分布式查询执行。交互的方法就是根据SQL语句的需要和数据表分区在后端shard的分布信息,为相关的后端存储shard生成SQL语句。
2
Explain语法
EXPLAIN [ ( option [, ...] ) ] statementEXPLAIN [ ANALYZE ] [ VERBOSE ] statementwhere option can be one of:ANALYZE [ boolean ]VERBOSE [ boolean ]COSTS [ boolean ]BUFFERS [ boolean ]TIMING [ boolean ]SUMMARY [ boolean ]FORMAT { TEXT | XML | JSON | YAML }
ANALYZE选项为TRUE会实际执行SQL,并获得相应的查询计划,默认为FALSE。如果优化一些修改数据的SQL需要真实的执行但是不能影响现有的数据,可以放在一个事务中,分析完成后可以直接回滚。 VERBOSE选项为TRUE会显示查询计划的附加信息,默认为FALSE。附加信息包括查询计划中每个节点(后面具体解释节点的含义)输出的列(Output),表的SCHEMA信息,函数的SCHEMA信息,表达式中列所属表的别名,被触发的触发器名称等。 COSTS选项为TRUE会显示每个计划节点的预估启动代价(找到第一个符合条件的结果的代价)和总代价,以及预估行数和每行宽度,默认为TRUE。 TIMING选项为TRUE会显示每个计划节点的实际启动时间和总的执行时间,默认为TRUE。该参数只能与ANALYZE参数一起使用。因为对于一些系统来说,获取系统时间需要比较大的代价,如果只需要准确的返回行数,而不需要准确的时间,可以把该参数关闭。 SUMMARY选项为TRUE会在查询计划后面输出总结信息,例如查询计划生成的时间和查询计划执行的时间。当ANALYZE选项打开时,它默认为TRUE。 FORMAT指定输出格式,默认为TEXT。各个格式输出的内容都是相同的,其中XML | JSON | YAML 更有利于我们通过程序解析SQL 语句的查询计划,为了更有利于阅读,我们下文的例子都是使用TEXT格式的输出结果。
3
执行计划的解读

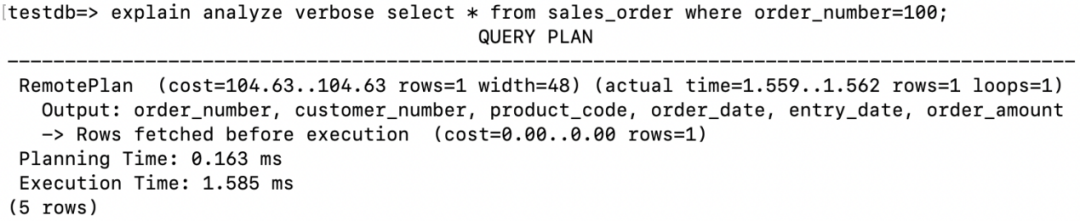
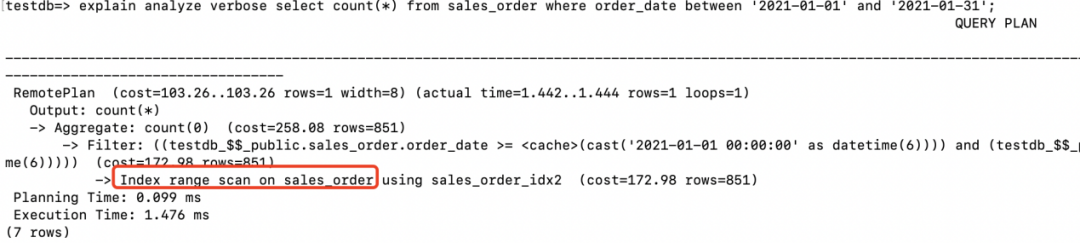
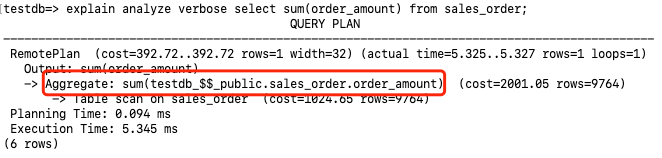
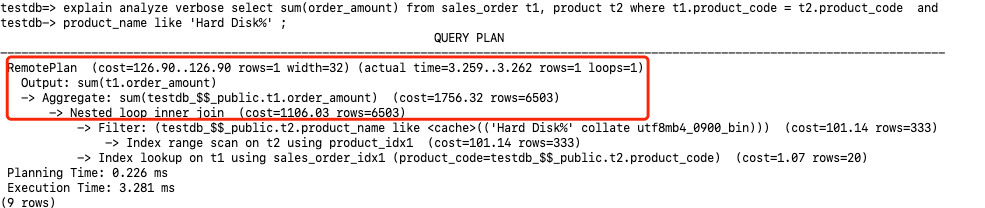
访问方式。RemotePlan是Klustron新增的查询计划节点,用于获取存储节点上的用户数据。从上面执行计划RemotePlan可以看出这条SQL完全是在存储节点执行的,在存储节点的数据访问方式是Table scan。在存储节点的过滤条件为testdb_$$_public.sales_order.product_code = 1。 访问成本。cost=343.15..343.15执行查询的成本估算为343.15。 返回行数。查询估计返回的行数为rows=49, 实际返回的行数为rows=19。而下面的Table scan估计sales_order全表的行数为rows=9862,在执行过滤之后(product_code=1)估计返回的行数为rows=986。这里可以看到RemotePlan的估算值rows=49和执行过滤之后预估的行数rows=986不太匹配,这是因为RemotePlan的估计行数是由计算节点估算的,而RemotePlan下面的算子和代价的估算则是由存储节点MySQL完成的。并且在analyze情况下展示的MySQL的执行计划步骤不包含实际的执行时间。 执行时间。Planning Time部分表示生成执行计划的时间为0.066ms,Execution部分表示真实的执行时间为2.299ms。


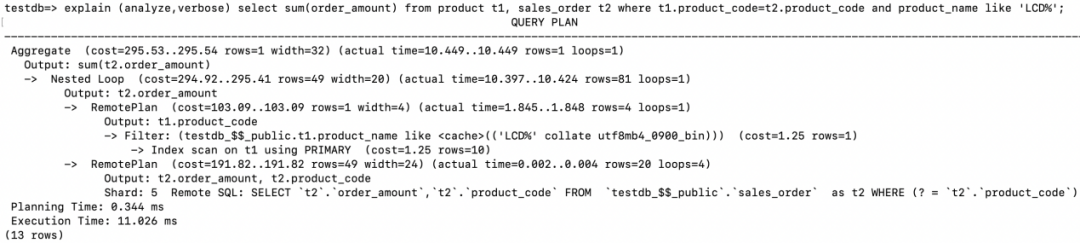
Nested Loop的驱动表为product,其访问的方式为RemotePlan,在存储节点的主键索引上执行了Index scan,通过字段t1.product_name like ‘LCD%’进行过滤,最后返回满足条件的4条记录(rows=4)给计算节点。 在计算节点拿着步骤1返回的每条记录的product_code发给存储节点执行Remote SQL Remote SQL: SELECT `t2`.`order_amount`,`t2`.`product_code` FROM `testdb_$$_public`.`sales_order` as t2 WHERE (? = `t2`.`product_code`), 循环执行次数为4次(loops=4),执行结果集同样也送回到计算节点。 满足Join条件的结果集有81行(rows=81)。 最后在计算节点完成最后的SUM。
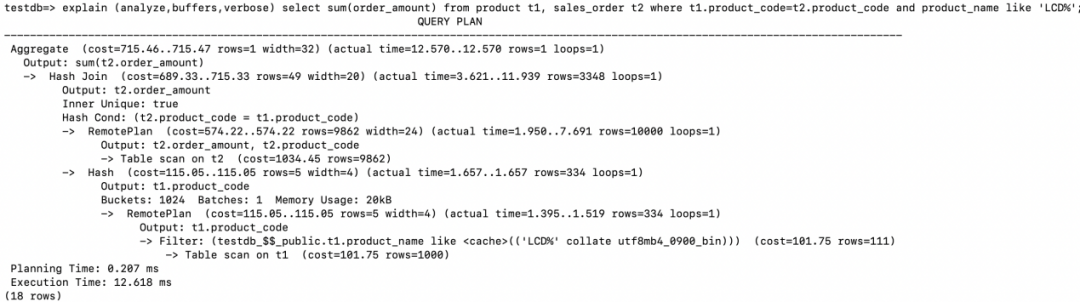
先在存储节点执行Table scan on t1, 并且进行过滤(product_name like ‘LCD%’),之后将结果集返回给计算节点。 在计算节点上根据Join的字段创建Hash table。Hash table的情况为: Buckets: 1024 Batches: 1 Memory Usage: 20kB 在存储节点执行Table scan to t2, 返回字段order_amount和product_code给计算节点。 在计算节点进行Hash Join,通过步骤2中创建的Hash table去probe步骤3中返回的结果集。Hash Cond: (t2.product_code = t1.product_code),返回满足join条件记录的order_amount值。 最后执行sum(order_amount)的聚集操作。
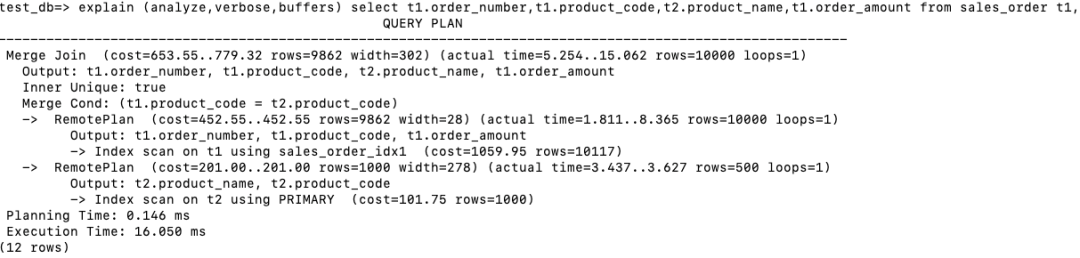
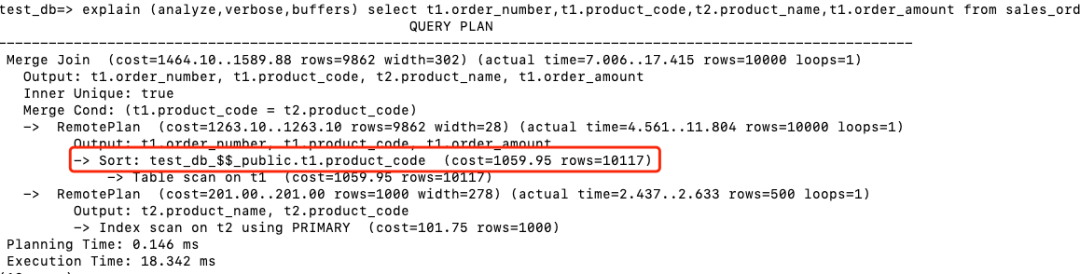
在存储节点执行Index scan on t1, 回表后返回product_code,order_amount和order_number。 在存储节点执行 Index scan on t2, 回表后返回product_code和product_name。 在计算节点进行Merge Join。注意由于Index返回的结果都是根据product_code排序的,所以省略了Sort步骤。
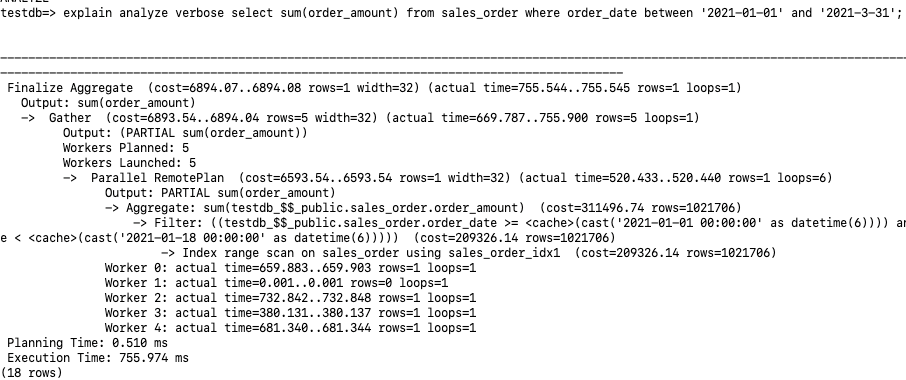
我们看到Workers Planned:5 Workers Launched:5 , 其实总共分配了6个并行进程:Leader,Worker 0-4。通过Parallel RemotePlan最后的loops=6也可以看出6个并行。 每个并行进程在存储节点都执行了Index range scan on sales_order using sales_order_idx1, 各自进行sum(order_amount),输出PARTIAL sum(order_amount)的结果给计算节点。由于是部分结果集的汇总,所以这里多了”PARTIAL”的字样。 Leader进程Gather其它5个sum(order_amount)的结果,然后进行最后的汇总。

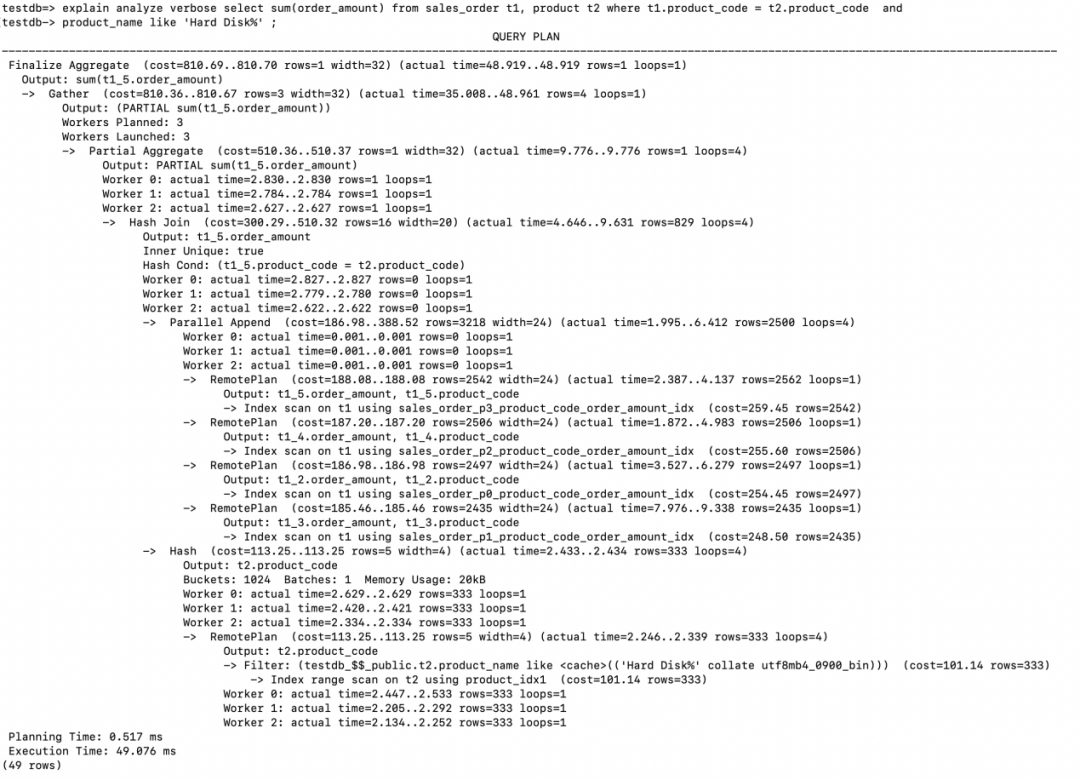
同样我们看到Workers Planned:3, Workers Launched:3,但是总共并行工作的进程有4个:Leader, Worker 0, Worker 1, Worker 2。另外从loops=4可以窥到一些端倪。 两张表Join的方式为Hash Join, 驱动表product是一个非分区表,在存储节点上4个并行的进程采用了Index range scan分别扫描了product表一次。满足条件的结果集有333行,返回给计算节点创建Hash Table。 
Parallel Append说明采用并行的方式Index Scan了sales_order的4个索引分区。将获取到满足条件的记录返回给计算节点。(2562+2506+2497+2435) 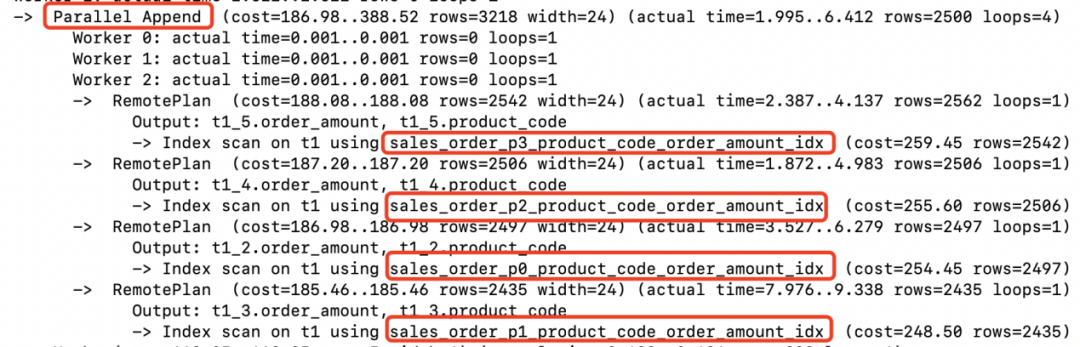
在计算节点并行完成Hash Join 
Partial Aggregate 对每个并行worker的Hash Join返回的行做了聚集运算。 Gather收集每个worker进程返回的结果,leader进程执行Gather以及Gather之上的部分。Gather需要把结果集送给Finalize Aggregate从而用每个worker的Partial Aggregate 结果形成最终的输出。 


文章转载自KunlunBase 昆仑数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
