




PG在跨境电商的应用
演讲人:于培恒,智赢跨境创始人、PG中国社区MVP
首先做个自我介绍,我早年间就职于新浪,后来在垂直电商领域做技术总监,几年前到杭州创业,创业时选型了PG数据库。所以,本文主要从应用角度来为大家分享在工作中如何应用PG数据库。
一、PG数据库的优点
首先介绍下PG数据库的优点。众所周知,PG有免费、开源和扩展性好的优点,是像我这样的创业人喜欢的技术,因为省钱的技术才是真技术,不变的技术才是硬通货。
我做的ERP现在可以在国内排名前三、四名,每天大概有六万多人在上面。创业八年时间,已经积累了60亿条数据,大概5T的数据库、80T的图片。数据库的年成本占比年利润比例不到百分之一,这都是PG数据库的低成本的价值所在。
说完成本再来说说技术,所谓不变的技术才是硬通货是什么意思呢?比如SQL这个技术,50年来几乎没什么变化,所以越底层的东西越值钱,越SQL的东西越没什么变化。所以数据库技术是值得我们去花时间学习的。
具体展开介绍下PG数据库的优点。
- 数据类型多
如下图所示PG数据库的数据类型很多,有数字类型、字符类型、事件类型、位串类型、几何类型等等。这么多的数据类型有什么好处呢?
举个例子,在做地图的时候,传统的方法是把数据拖到中间层,然后在内存或代码中去计算,甚至可以在数据库里写枚举。比如计算两个点之间的距离,有了数据库就非常简单了,可以直接把数字拉出来就可以了,省了很多网络传输的瓶颈,这对于初创公司是非常有好的。

- 索引类型多
写SQL的同学们都知道,有个第一法则就是要把SQL应用到索引上去。大家会发现,这么多针对不同数据类型的索引,可以做到毫秒级查询,既省钱又省时。

- 多列索引。PG数据库还能做到多列查询。当用户希望不访问数据库直接毫秒查询出结果,比如1000万数据毫秒返回,肯定要建一个符合索引,想要查的数据都在这个索引里面。
- 不分索引。当表特别大,用户不希望记录所有索引,那么就可以部分用where这个语句。
- 表达式索引。这是PG数据库最强大的地方,可以用一个函数算出来一个值,然后对这个值进行索引。
- 函数多插件多
以前干什么都需要搞个中间件,但是对于PG数据库就非常简单了,一个插件就能搞定,而且插件应有尽有。阿里云这边扩展了很多插件,几乎不用自己安装,用起来还是非常方便的。

二、如何使用Json:使用Json的应用场景
那么PG有这么多数据类型,其中最经典最厉害的是下图紫色的两个数据类型,分别是集合类型和搜索类型。

集合类型中包含数组,有了数组意味着质变,用户可以做任何数据机构。可以简单理解为,有了数组基本上就拥有了一个最简单的数据集合,其他东西都是数组的变形。
- 用户权限
如下图所示,Json界面的一个权限,业务权限没有技术权限“增、删、改、查”那么简单。业务权限在系统里、产品里、订单里、平台里都具有非常详细的定义和要求。如果从头开始写这些是很复杂的,经过长期的实践,我们发现Json是很简单的。因为权限不是一开始就定下的,而是在客户不断提要求的前提下不断增加的。那么随着增加得越来越多,如何维护呢?这时就可以用Json来表达这种关系了。
用了Json可以不用增加任何列就可以任意扩展和修改数据结构,所以它不仅仅是Json那么简单。同时它用了索引,那么如果用户想做任何字段,用了Json字段再加上索引就可以了,相当一个表结构。

- 商品变体,颜色尺寸
跨境电商里有个最重要的场景,那就是商品变体。比如一个杯子有大有小,一件衣服有蓝有绿,这个就是商品变体。
如下图左侧表格所示,商品颜色3种和商品尺码3种,拼合而成就是商品的库存数量,包含不同价格、不同SKU和不同图片,这才是一个完整的产品。
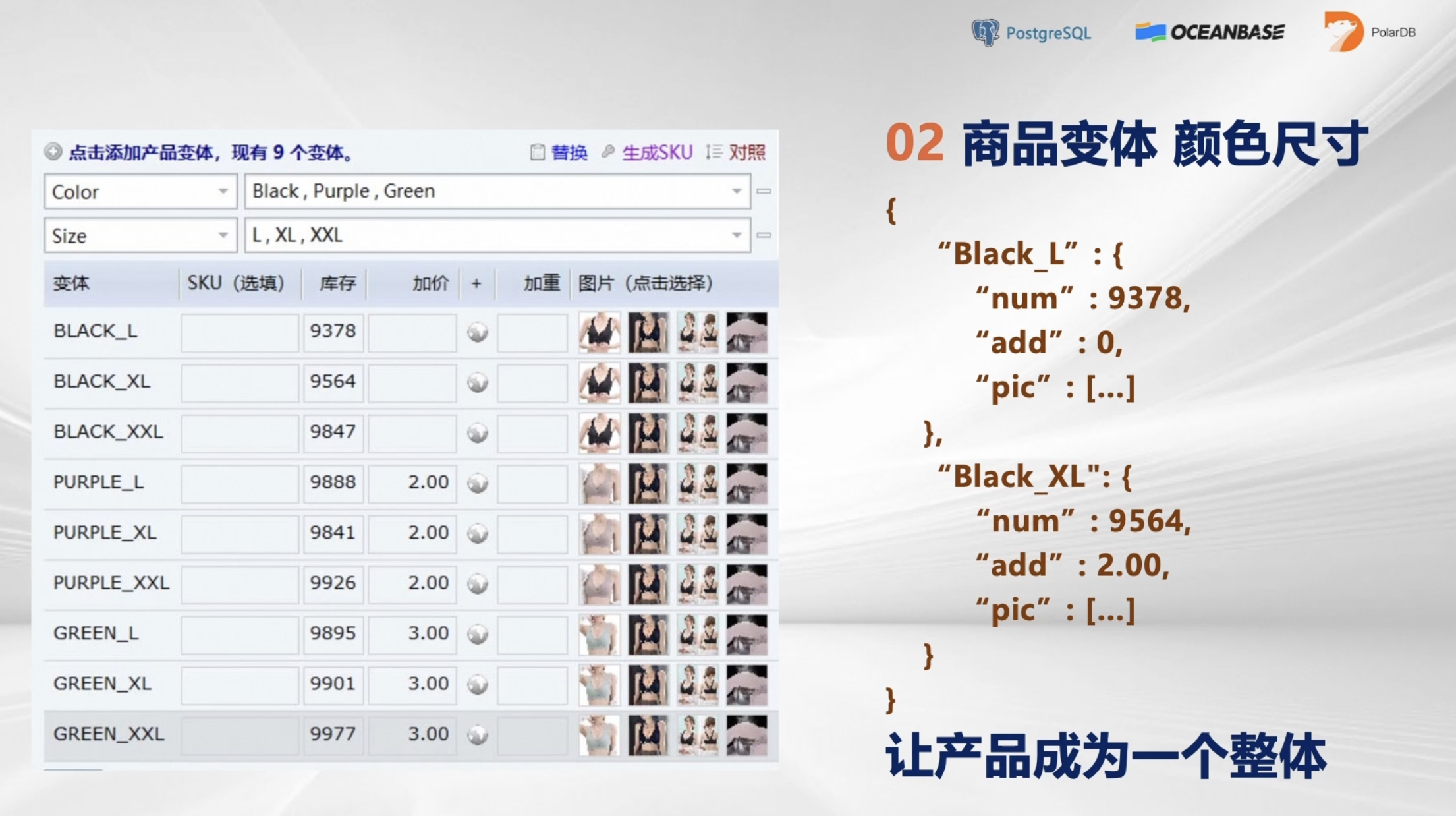
这样的结构存在于电商的每一个角落,这种随时变化产品该如何去表达它呢?用Json表达是个好办法,可以使得整个产品成为一个整体。
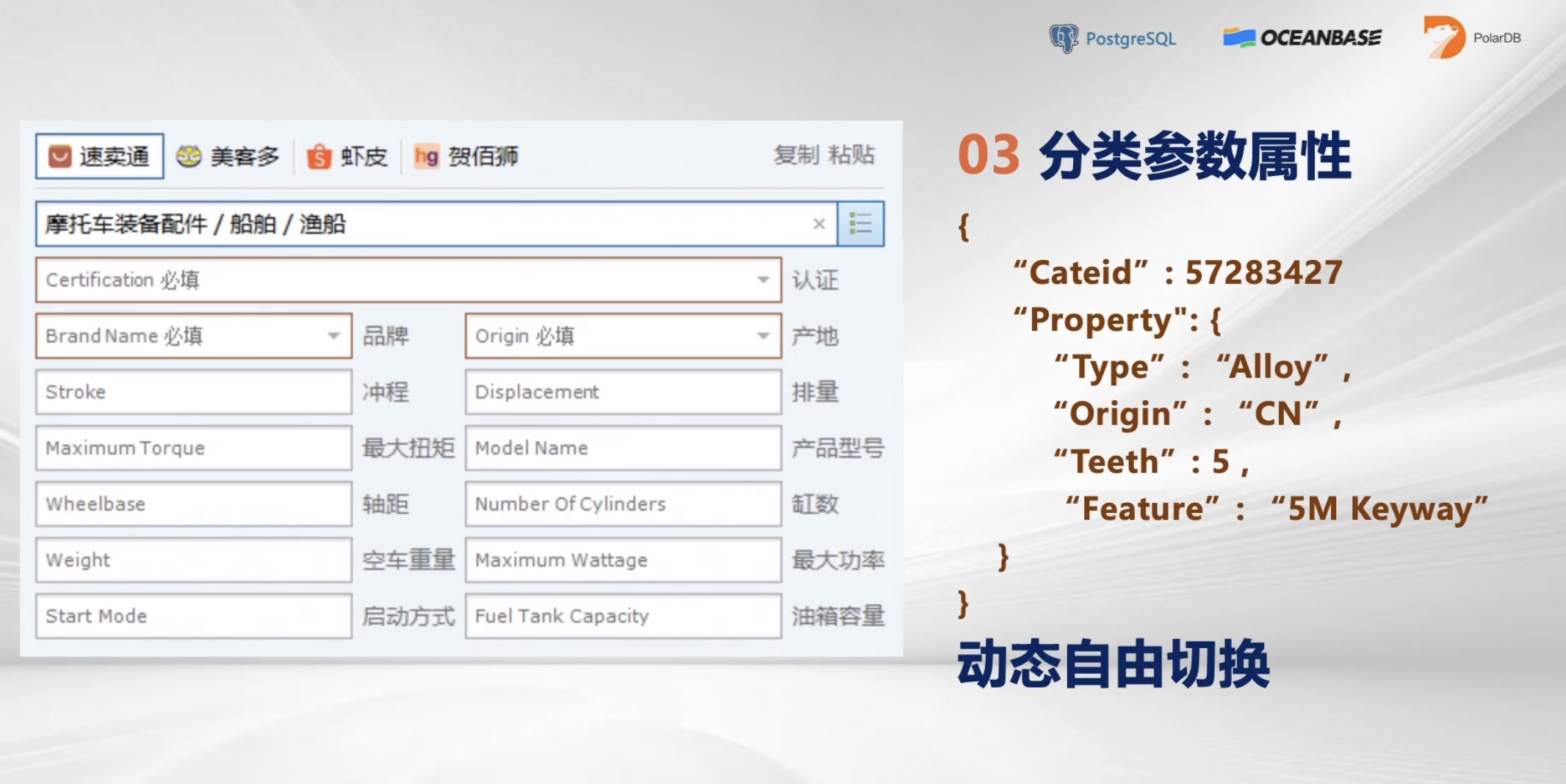
- 分类参数属性
举个例子用速卖通,选不同分类的时候,下面的参数会全部变化,因为每一个分类下都有不同属性。如果用Json,你会发现这个事情会变得异常简单,而且它里面有索引,不用担心搜索不到。
- 多语言
做跨境电商的业务,多语言是必须的。当用户A用两种语言,用户B用三种语言,我们不可能将所有100多种语言都建成列,那么用Json就最方便了,用它语言可以任意扩展。而且支持索引,可以单节点的支持搜索。
总结而言,所有不确定的结构都可以用Json,而且Json的序列化很强大。

三、如何使用数组:使用数组的应用场景
- 图片数组
以前存图片需要在SQL里用逗号、竖线分隔,但是众所周知,现在很多图片是网络地址,不是以前的.jpg的格式,那么网络地址里就可能包含逗号,所以继续用之前的办法分隔,可能无法回避转译的问题。
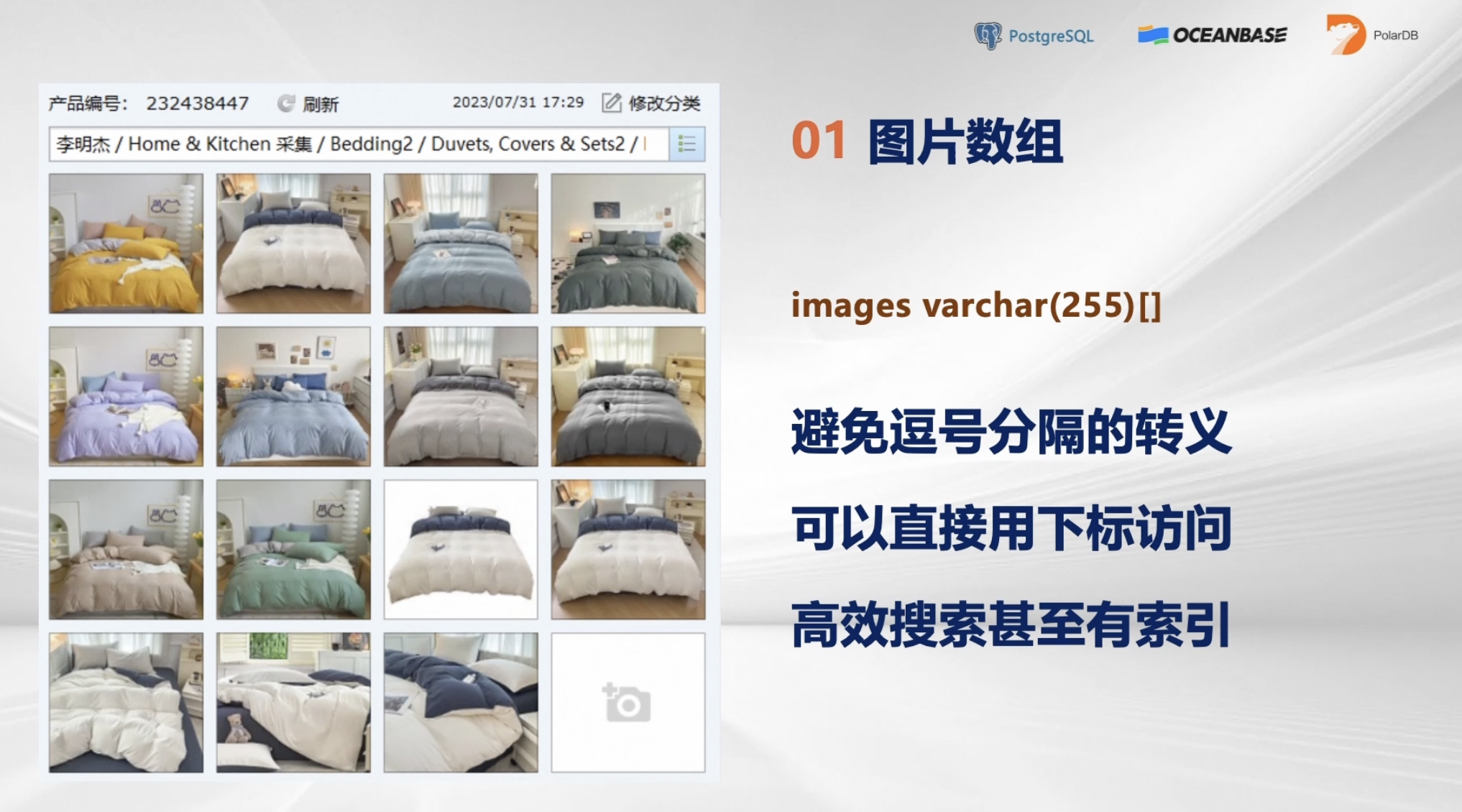
另外,用以前的办法无法精准定位图片位置。找图片的时候需要把代码拉出来,在里面去找需要的图片。那么当产品图片已经积累到上亿数量级的时候,如何搜索定位需要的图片,用代码就很难做到了。另外,如果想要的图片没有搜索到,解决方案也不能将所有的图片都过滤已一遍。
遇到以上的情况,有了数组就可以迎刃而解了。数组加一个索引,不仅查找图片简便,而且还能避免转译的问题。所以数组才是真正在对数据集合而不是对字符串进行处理。
- 表达多对多关系
数据库的核心是写代码面向的对象,但是个人理解这还不全面。写代码的数据库,增删改都没问题,因为这三个面向的是个体,但是查询会对业务发挥有影响,因为查询面对的是关系。在代码中可以用数列表达一对多的关系,但多对多的关系就很难表达了。
表达多对多的关系用表就简单多了。
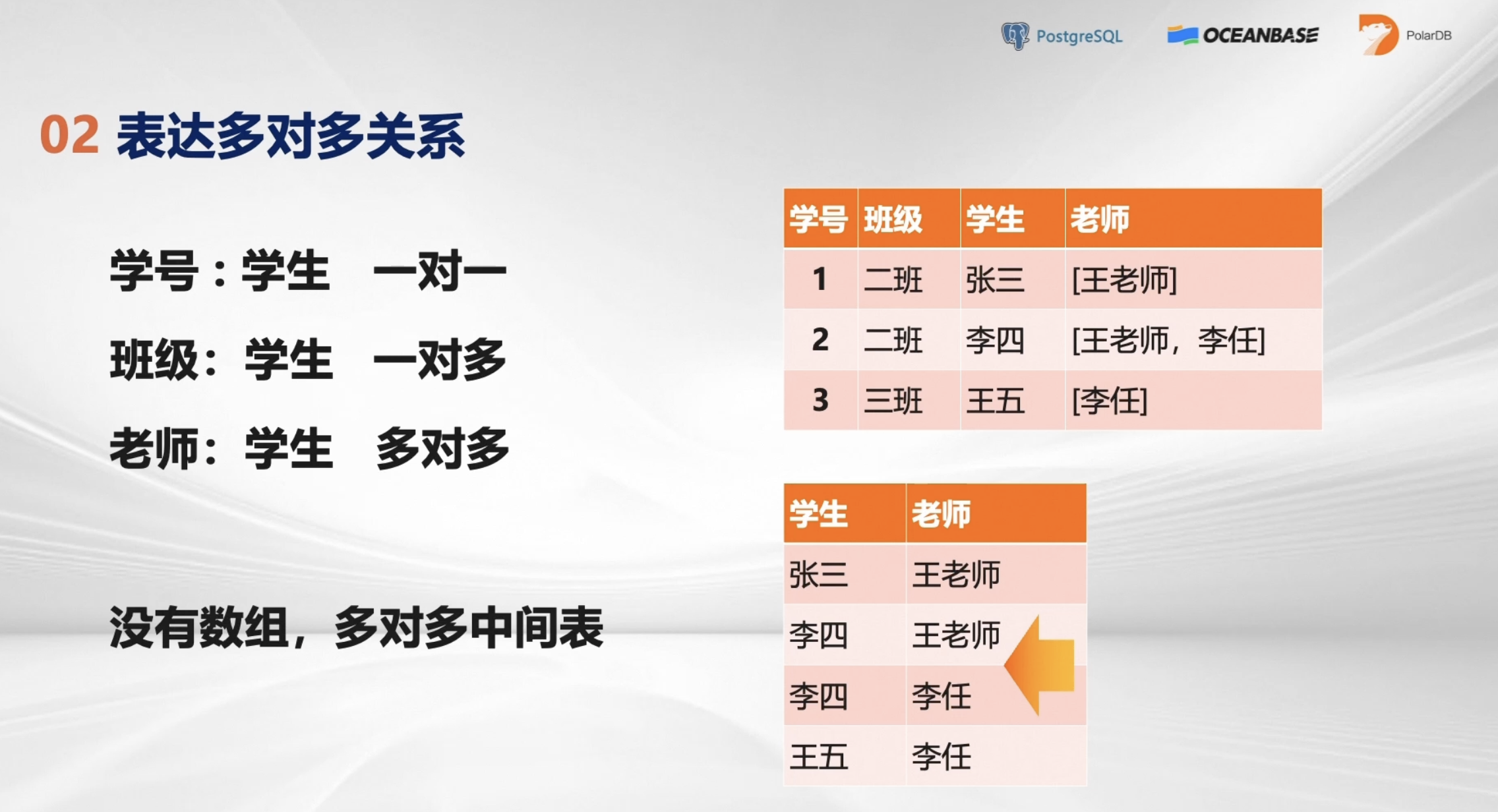
如上图所示,表有三种结构:关于学号的一对一、关于班级的一对多、关于老师的多对多。
如果没有数组,那就是PG数据库中,如上图右上角的表格,老师变成了数组,从学生角度来看变成了一对多的关系。
那么上图右下角的表,是基于以前数据库一个PID来的,会发现学生李四重复了,这表就叫做关系表,但是这个关系表缺少原子性。那么在做任何业务操作的时候,都需要将这些都筛选一遍,当数据过亿的情况下,筛选的方法就很麻烦也耗费时间。更好的办法是做拆表,但是当把学生表拆成了100个表,那么他们之间的关系如何拆分呢,这个就更复杂了。
PG数据库可以很简单的解决上述问题,多余的关系都可以用一张表来表达清楚,因为有数组。
四、如何使用全文检索:使用搜索类型的应用场景
- 全文检索只需要两步
当我们要查询一个产品的时候,比如在搜索框中输入Deep Groove,会发现标红的产品描述都是搜出来的结果。在PG数据库中,只需要两步,第一步是tsvector,即准备可搜索的分词文档;第二步是tsquery,即对文档执行的搜索查询。

- 英文中文分词
PG数据库的全文检索只需要用分词即可实现,如下图所示,英文用“summer holiday is comming”,用to_tsvertor把这句话分词成“come”、“holiday”、“summer”,其中come的时态改变了,单复数也进行了处理,并且忽略了像is、the这样的介词。
如果是中文的话,装一个中文插件就可以。如下图所示,“中国是发展中国家”可以通过to_tsvector拆分成“中国”、“发展中”、“国家”。
总而言之,在PG数据库中,装个插件写一行命令就可以完成分词。

- 检索方法
分词之后的搜索也很简单。只需要查一个表,什么字段,准备好to_tsvector的文档,这个文档中包含搜索词,就可以了。

把准备文档的函数放进索引里建完,无论是什么级别的数据,哪怕是上亿的,也能实现毫秒级查询。PG数据库在一亿以下的数据量级,几乎是不用做任何中间件的,只要优化好了,硬件稍微强大一些就可以了。
如果出现近似的词排在前面,如何处理呢?可以用ts_rank来进行排序近似度。
另外介绍PG数据库中两个索引,gin索引,查询更快,但是创建慢一点;gist索引,创建更快,但是查询慢一点。根据不同的场景可以使用不同的索引。
五、如何实现模糊搜索:实现任意字段的模糊搜索
只有全文搜索还不够,还需要模糊搜索。
- Like%和iLike%,前缀搜索
Like语句大概从学SQL的第一个星期开始就会学到,但是如何做到毫秒级,这是一个很大的问题。

如上图所示,当我们对型号、电话有严格要求的模糊搜索,只能用Like(iLike不区分大小写)。用的语法就是Like%,这个%可以通过建立一个Btree索引即可实现毫秒级。
- %Like和%iLike,后缀搜索
如果业务要求尾号搜索,比如手机号尾号,就可以用%Like这样的语句,通过reverse函数,实现后缀索引。

- %Like%,搜备注
备注搜索的语句是%Like%,在PG数据库中只需要装两个插件即可实现。如果是英文,就装trgm插件;如果是中文就装bigm插件。

如上图所示例,这两个插件是将一句话中的每三个字符拆分成一个字符段,然后整体建立索引,也就是说搜索的时候按照这种拆分方法就变成了,数组里是否包含,PG数据库里对数组知识索引,所以百万级仍然可以实现毫秒搜索。
阿里在这里也扩展并支持了亚洲字符,由于亚洲字符是两个字节,所以是双元符。如上图“不断发展壮大”这句话的拆分成数组。拆分之后查询Like即可,建一个Json索引就行,也是毫秒级的速度。
通过以上PG数据库的介绍,大家可以看到,使用PG数据库可以将精力聚焦在业务上,如果有技术上的支持只需要安装一个插件就可以解决。
六、如何实现近似搜索:实现任意字段的近似搜索
- 问题的产生
近似搜索的需求是怎么产生的呢?举个例子,如果做跨境电商,首先需要注册一个商标,如何判断自己想注册的商标是否可以注册,就可以使用近似搜索来查询,如下图所示,以HUAWEI为例,搜索出来的有HUAWEI+、HUAWEI A等等近似的结果。
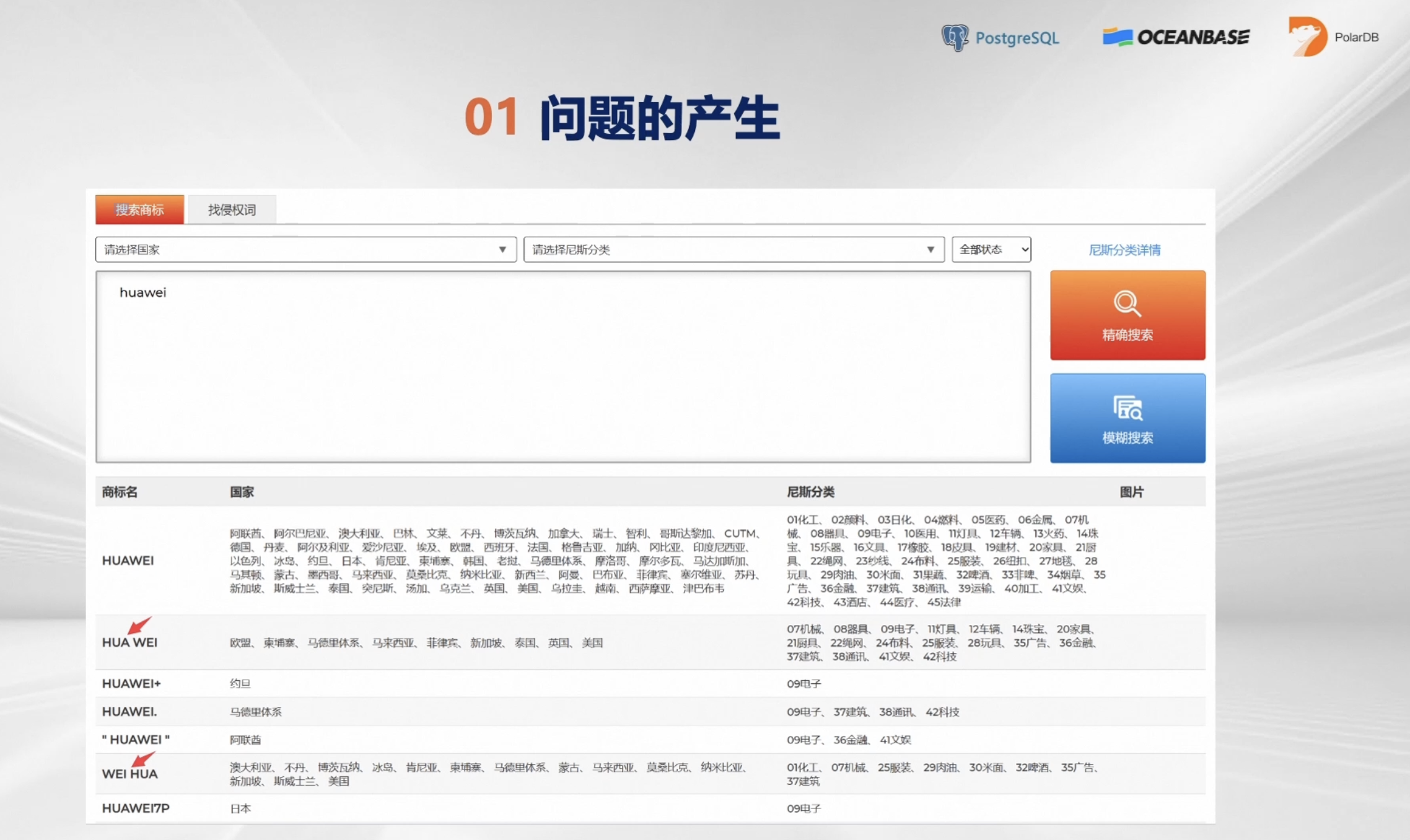
所以遇到有近似的查询结果的话,就不能注册原本想注册的商标了。
- 相似度
遇到以上需要近似搜索的需求,PG数据库也能轻松应对。PG数据库引入了一个操作符,=%,不是绝对等于,而是相似性的搜索。另外用插件中带的函数来计算字符的相似度,然后进行排序,就完成了。

PG数据库也有缺点,它是单机版不能做分布式,没法做集群。如果不止想用单机版,可以使用PolarDB,它具备了PG数据库的属性,并且不用自己拆表。
PolarDB开源官网:https://openpolardb.com/home
