




摘要:本文整理自中启乘数科技唐成的分享。本篇内容主要分为三个部分:
一、PolarDB 数据库介绍
二、高新能PolarDB一体机CData介绍
三、PolarDB一体机CData使用场景
一、PolarDB 数据库介绍
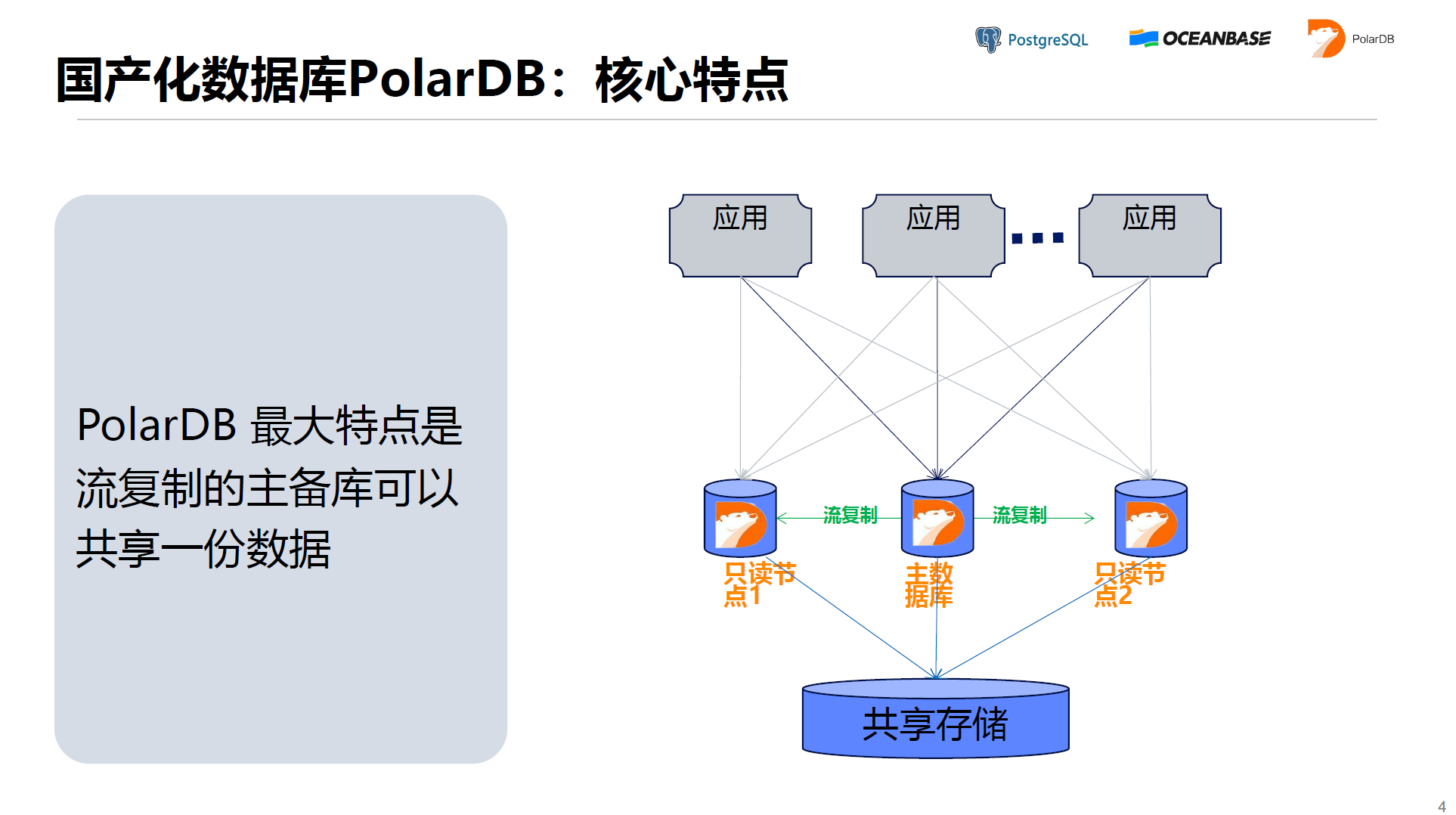
PolarDB是一个增强的PostgreSQL数据库,是一款国产化数据库。它最大特点是流复制的主备库可以共享一份数据。我认为目前它已经实现了一半Oracle Graph的功能,即共享存储上的备库有10+个节点都可以。

PolarDB有如下几个特点:
秒级增加备库。因为备库和主库是同一套数据,所以在增加或者减少备库的时候,不需要复制数据。比如给一个70+T的PG库搭建一个备库,不使用PolarDB的话,就需要我们将这70+T的数据复制到另外一台机器上,这个时间通常在半个小时到数个小时之间。但如果使用了PolarDB,就可以在主备库底下做一个共享存储,这样秒级就可以搭建备库了。
华为的Gauss和PolarDB都是基于PG做的,它们之间的区别在于,openGauss是基于PG 9.1版本,虽然后来有把一些PG更新的特性带回到openGauss里,但还是有很多的特性以及性能优化没合进来。
之前我自己实测一下,在内存里做了一个全能扫描。不产生IO的情况下,我发现Gauss比PG的14慢了很多,包括对PolarDB。一位南大通的预研发总监认为我的参数可能调的不对,但我把所有参数重新调了一遍后发现其实没什么关系。
而吕海波老师说他之前发现Gauss的CPU运行指数其实多了很多条,所以openGauss最大改造点是它把PG的进程模式改成了线程,然后把PG的源码拿c++包了一下。
还有人说Gauss是能分布式的,但没开源的Gauss以前PG XL改的开源的单机版,还是有差别的。这里面的9.2最大的区别是,PG有一个很大的生态。比如PolarDB可以支持很多第三方的插件,但华为因为改造比较多,所以很多插件用不了。
与PostgreSQL完全兼容。我们知道PG现在是全球第四大数据库,所以你走在哪个生态里还是很重要的,拿OceanBase来说,它就和生态有很大的关系,此外,还有PG的生态。
只读节点延迟很低。这在一些金融领域还是比较重要的,因为PG在准备存储是XX的,所以一旦改动在备库就要应用参战io,但在操作的时候因为它是共享存储的它就不需要这个东西了,延迟可以达到毫秒级别的储备库延迟。
大库在线扩容。PolarDB底下做了一个共享存储,如果我们包一个分布存储,那么它久可以做到数据的海量扩容,就相当于存储计算分离了。
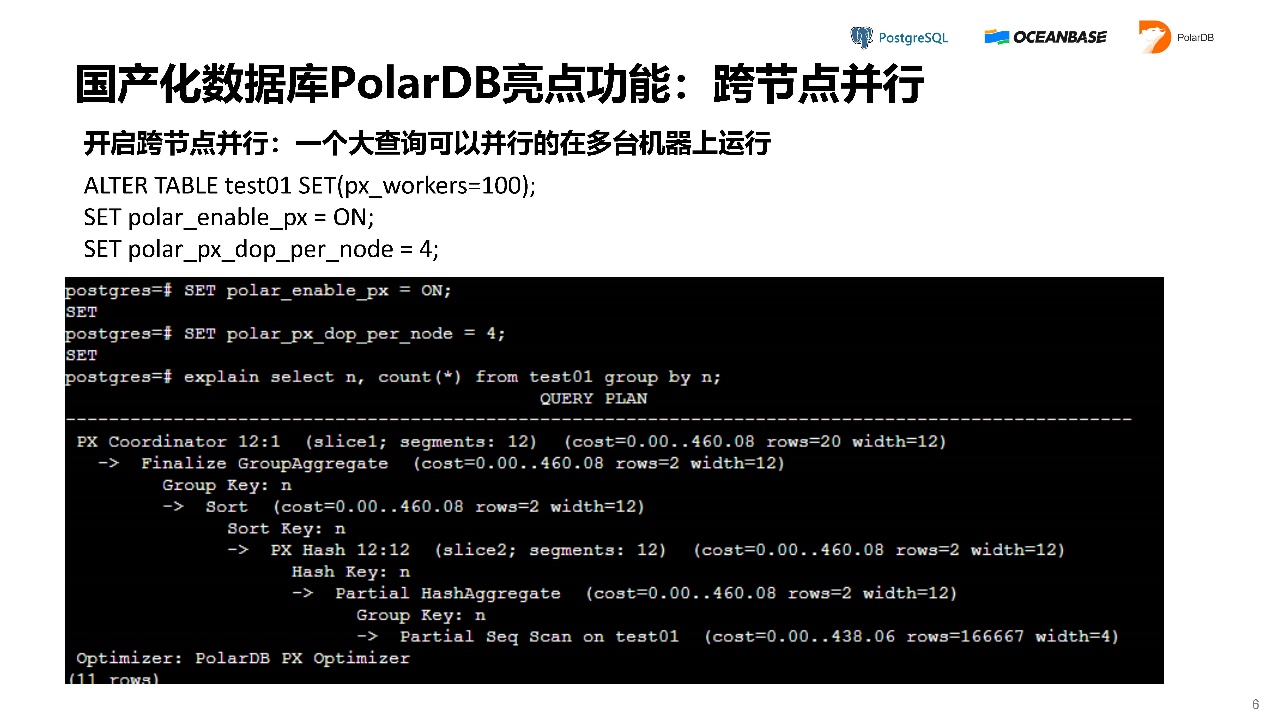
PolarDB除了刚才说的最核心的功能以外,还做了一些我认为比较有用的功能。比如我们建了一个70T的大扩,很多东西可能都是混合场景的,有可能有一个数仓在里面,因此就需要并行,而PolarDB可以做到跨节点并行。如果把10亿条数据全放在内存里,它可以在几秒内把结果算出来。
此外,还有一个功能亮点是并行DML。
详情请参考:https://polardbpg.com/document。
二、高新能PolarDB一体机CData介绍

高性能的硬件需要配套优秀的数据库以及高性的存储软件才能发挥出极致的性能。举个例子,我们买了一个很贵的硬件,但软件不行,那么硬件的钱就白花了。

接下来分享一下高新能PolarDB一体机:CData核心技术。它的核心技术是要把软硬件的强大功能发挥出来。
- 计算能力:高性能国产CPU提供强劲的运算能力。
- 网络能力:56Gb/s或100Gb/s或200Gb/s RDMA网络提供高效的计算和存储互联。
- 存储能力:高性能NVMe的新一代存储产品提供极高的性能、可靠性和耐用性。

- 高性能分布式存储软件:通过CFabric高效连接,让数据库能结合RDMASSD、NVM等特性达到快速传输和高效访问。
- 高性能RDMA访问协议:通过RDMA协议 (远程内存直接访问) ,在高O处理的场景下,达到极低的CPU开销。
- 高性能高带宽低延迟:56G/100G/200G Infiniband高吞吐,低延迟做到ns级通信时延,计算存储信息超高速互联。
- 高性能闪存SSD、NVMe:应用闪存SSD、NVMe,为数据库提供极高的O能力和存储效率。
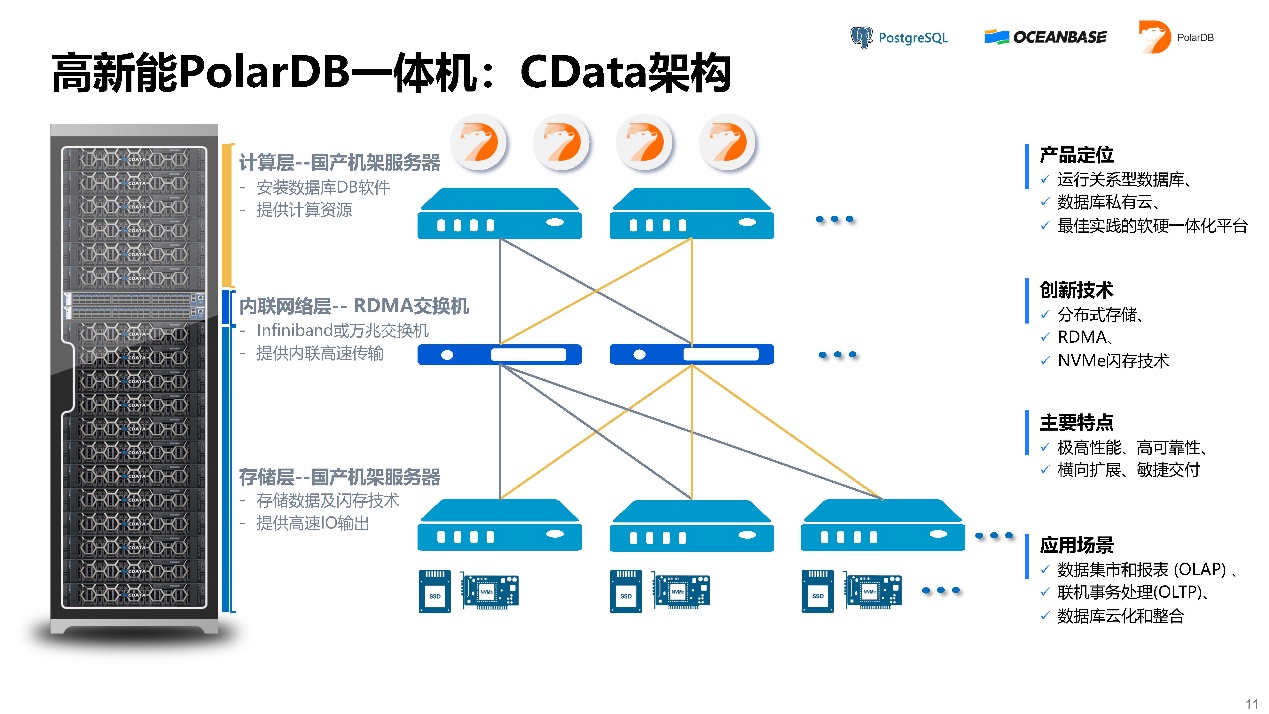
上图是CData的架构图,比如它的只读节点储备库可以增加底下存储空间。
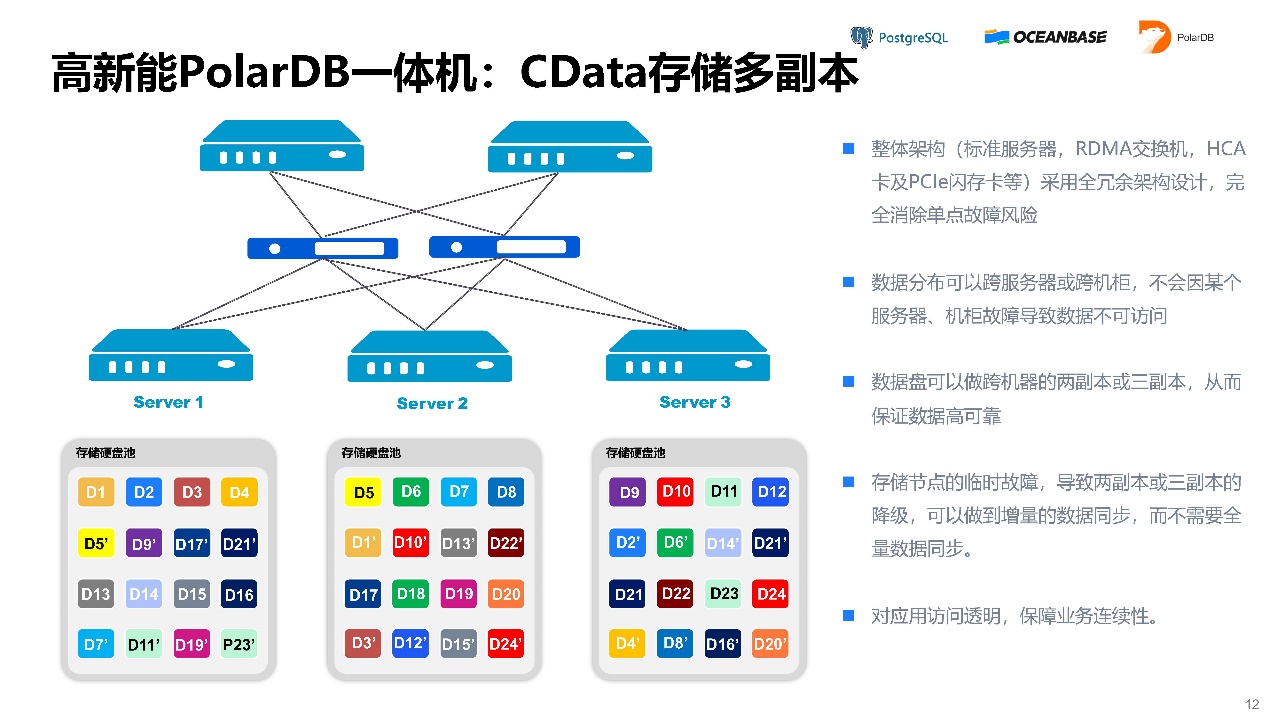
CData存储多副本。数据可以通过做两副本、三副本来保证数据的高可用。
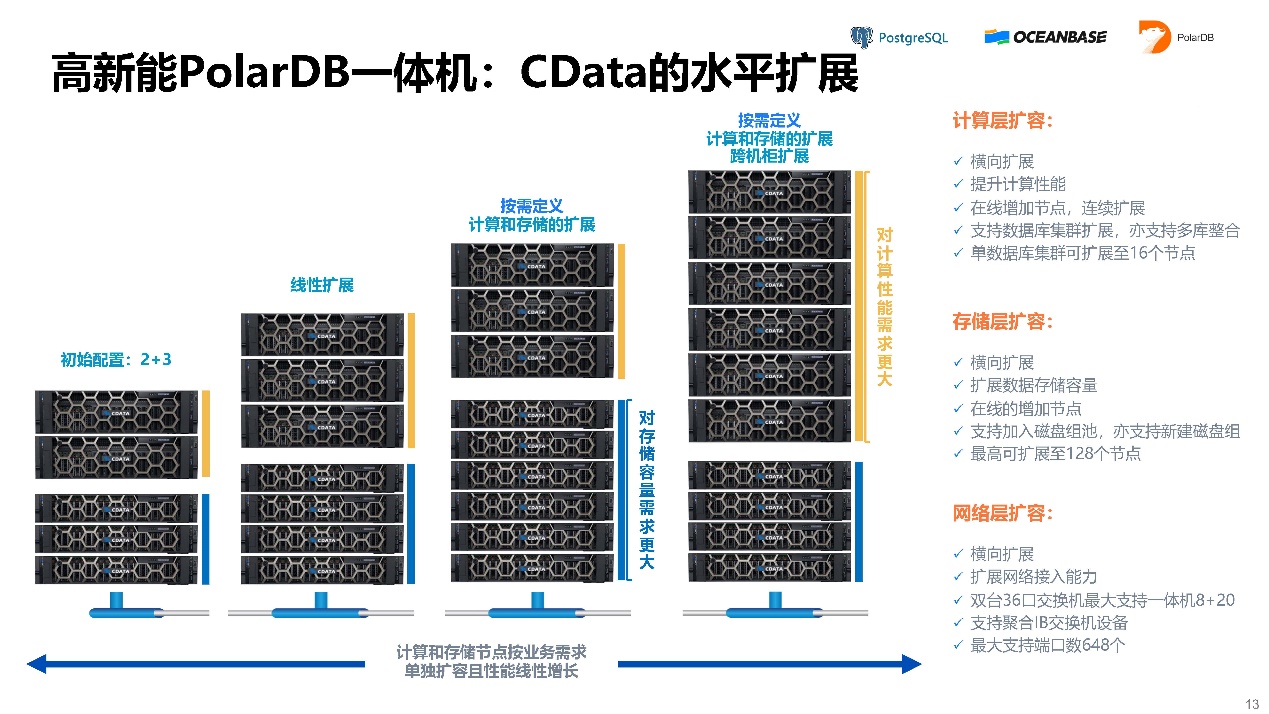
CData的水平扩展。计算机存储节点加速器能扩得更大的容量。
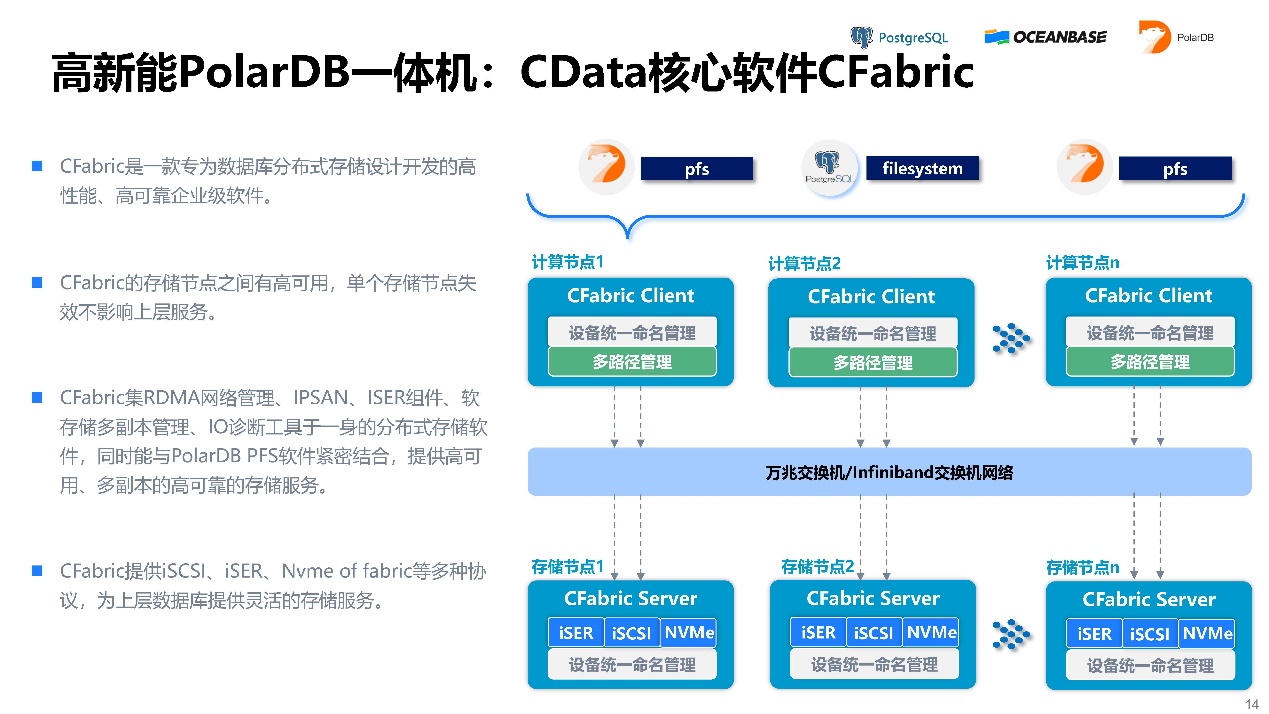
CData核心软件CFabric,它是一款专为数据库分布式存储设计开发的高 filesystem pfs性能、高可靠企业级软件。
PolarDB没有存储软件也能跑,比如买一个散存储,然后共享到主机上光纤的卡。PolarDB底下有一个pfs文件系统,我们知道一般普通的文件系统是不能共享的。但PolarDB有很大的贡献,它开源了pfs,可以把它看作是一个共享的文件系统,如果没有东西的话它是跑不起来,然后我们在这套软件的底下提供了共享存储。
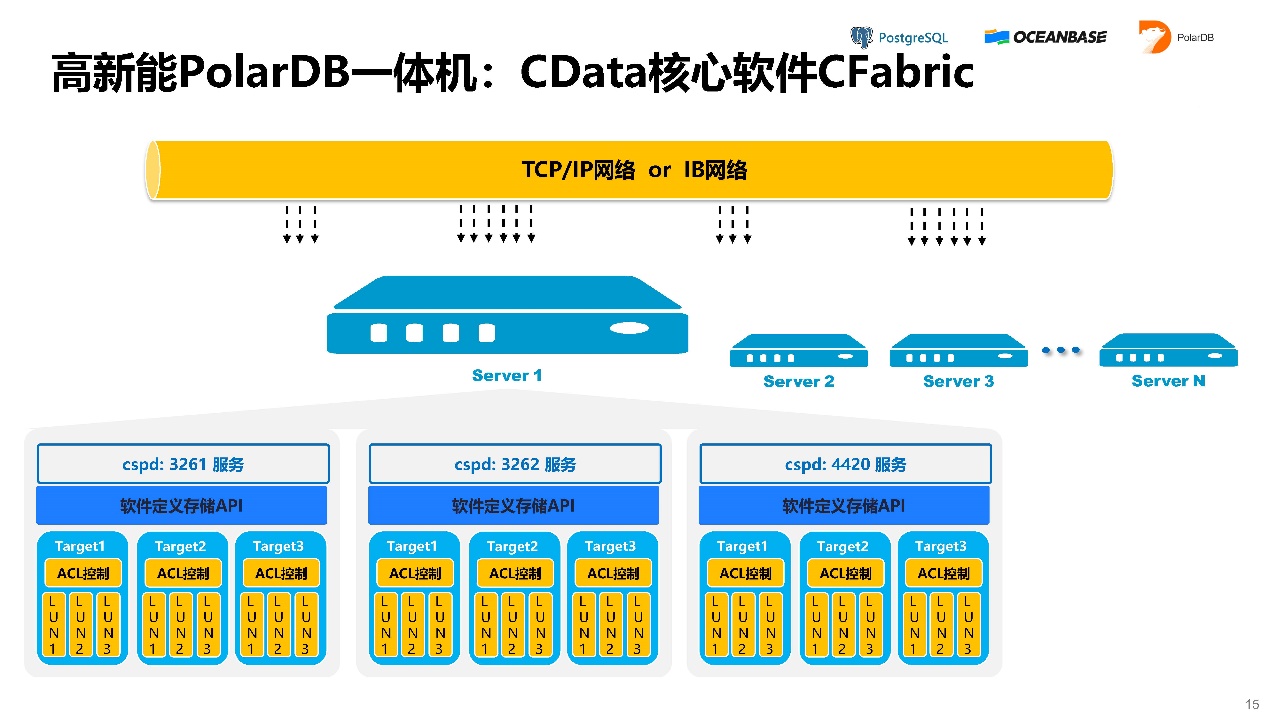
上图是CData核心软件CFabric的架构图。它有几种模式可以走,比如TPC、iSCSI、RDMA等等。
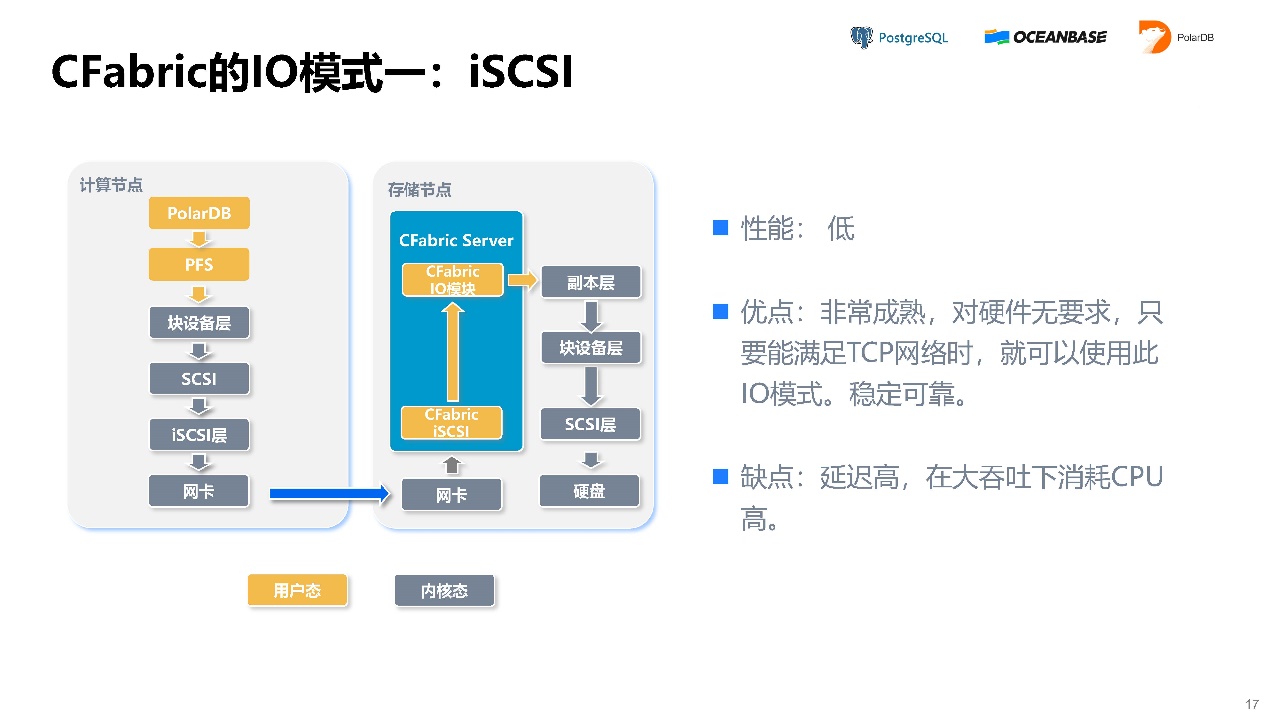
CFabric的IO有四种模式。模式一,iSCSI。它的优点是任何一个TCP/IP网络都能跑。缺点是性能不高,延迟较大。
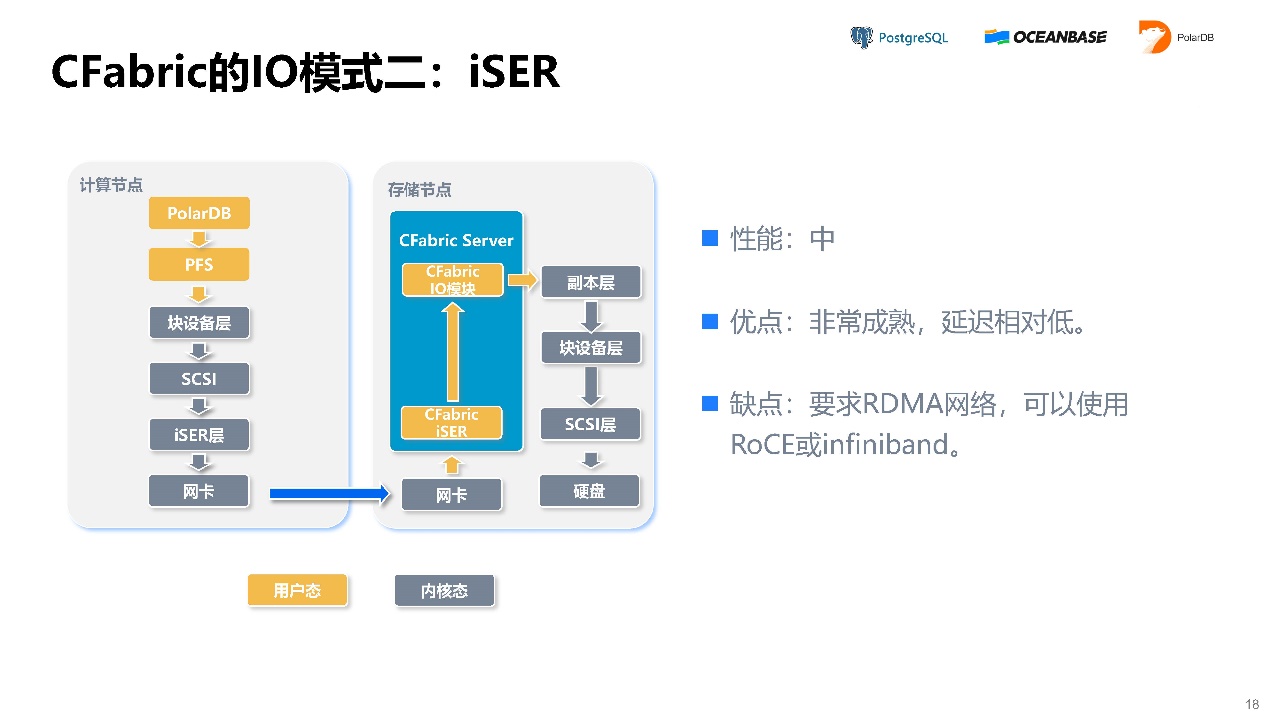
模式二,iSER。在iSCSI协议上把传输层换成RDMA。它的缺点是需要支持RDMA网络,优点是非常成熟,延迟较低。
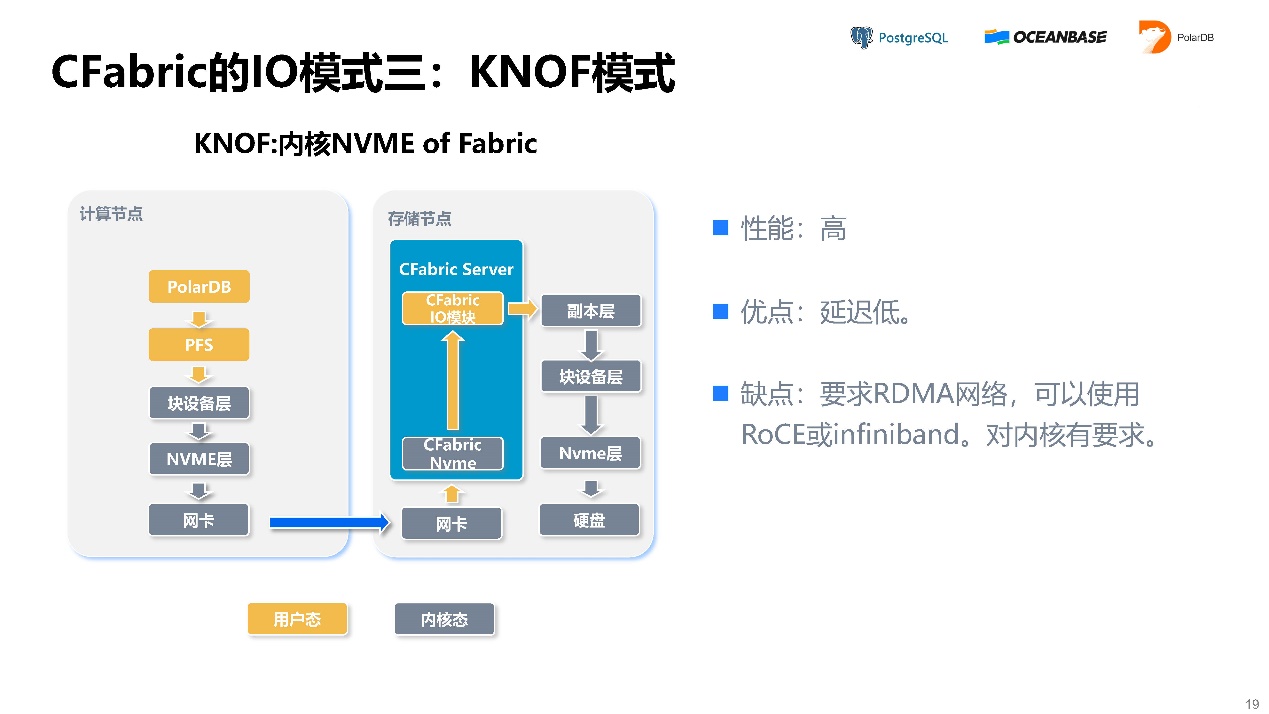
模式三,KNOF模式。这种模式的性能很高,优点是延迟低,缺点是需要支持RDMA网络,且对核有要求。
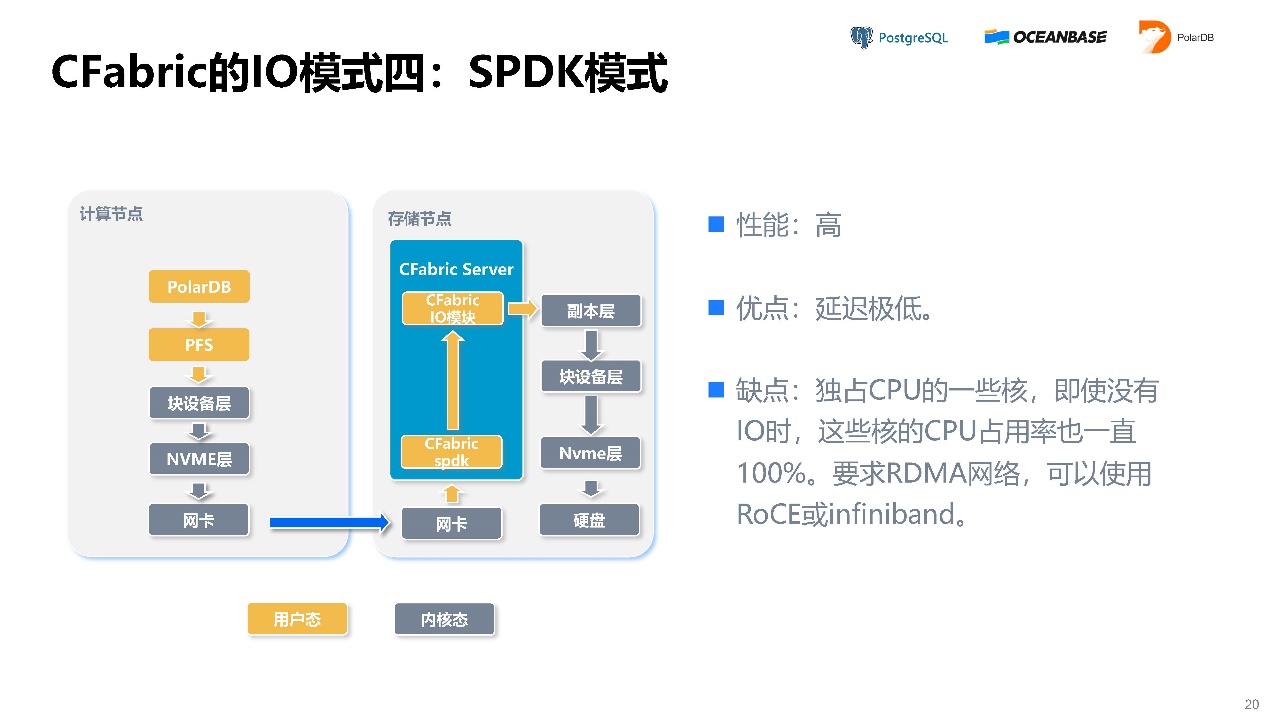
模式四,SPDK模式,它是英特尔做出来的黑科技。它的延迟可以做到极低,可以达到十几个微秒的延迟,但它缺点是独占CPU的一些核,即使没有IO时,这些核的CPU占用率也一直100%。要求RDMA网络,可以使用RoCE或infiniband。
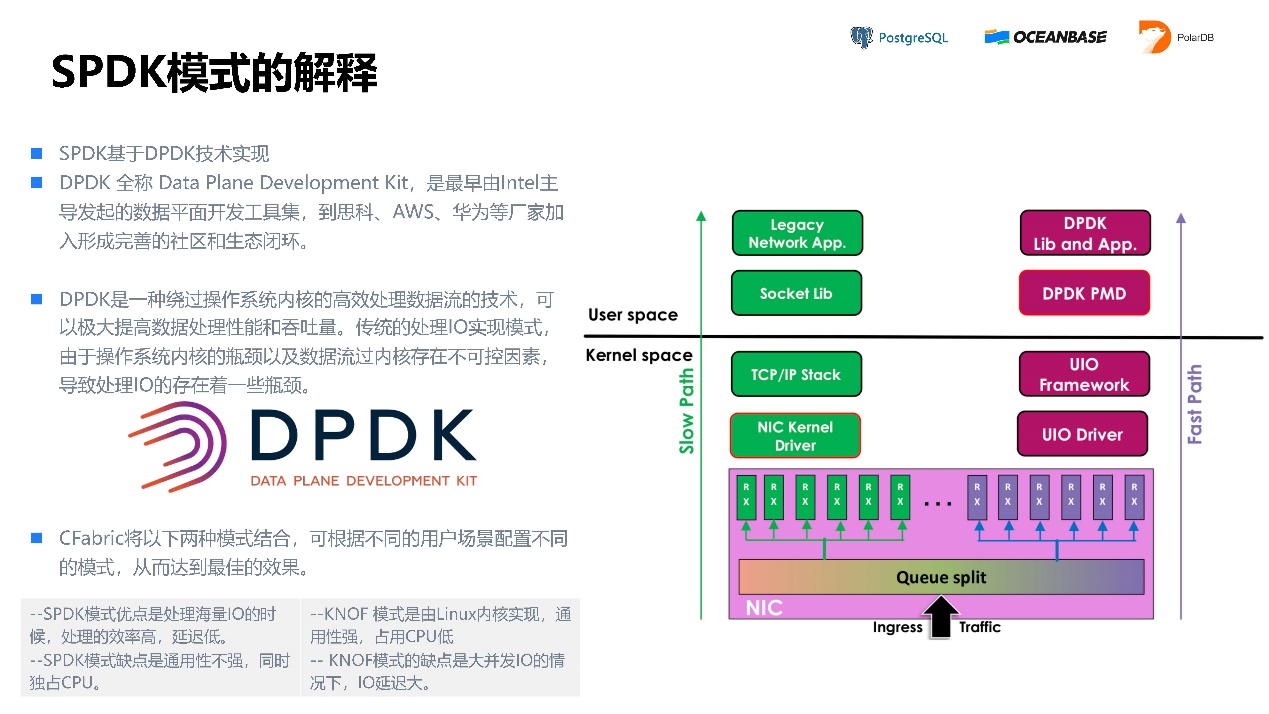
SPDK基于DPDK技术实现,DPDK技术可以不通过操作系统内核直接和硬件打交道。现在阿里云上有些流量清洗就走了PC服务器来做DPDK技术的。SPDK是一个开源的项目,大家感兴趣的话可以了解一下。
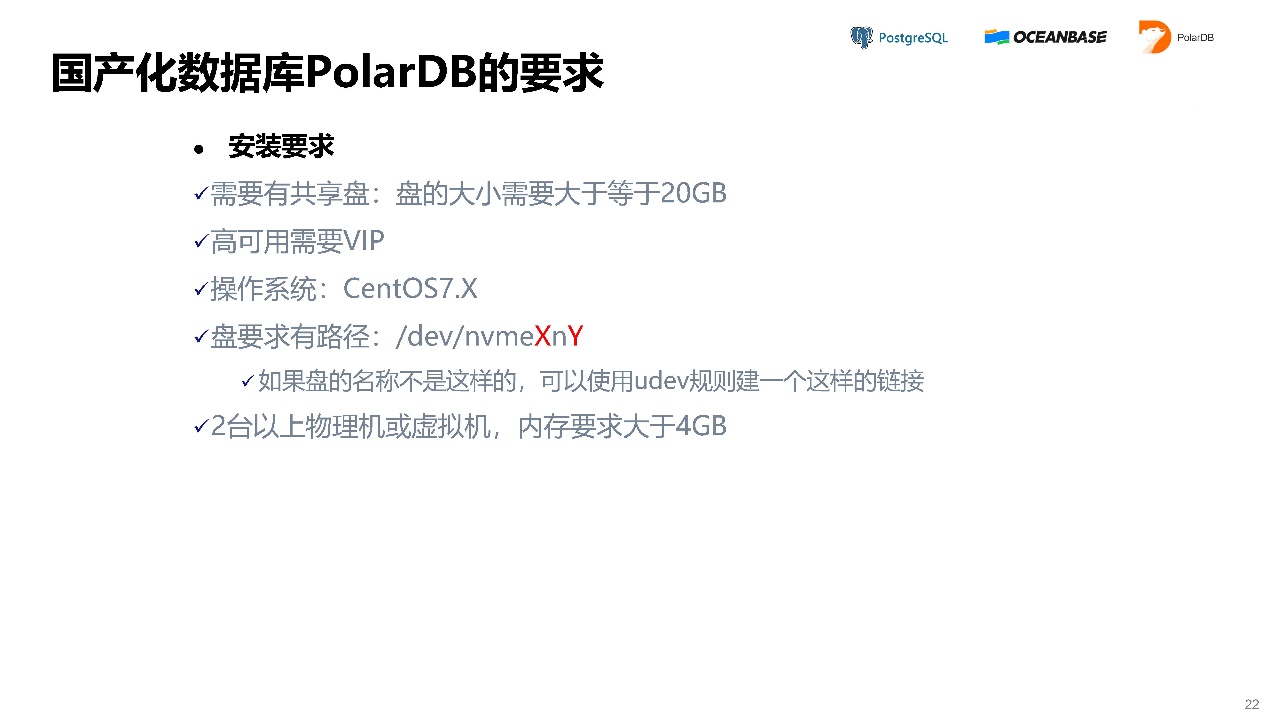
国产化数据库PolarDB的要求,首先需要有一个共享存储,操作系统可以选择CentOS7.X,也可以选择其他的,因为都是开源的,可以重新编译。盘的路径也有要求,可以使用udev规则建一个正阳的链接就可以了。
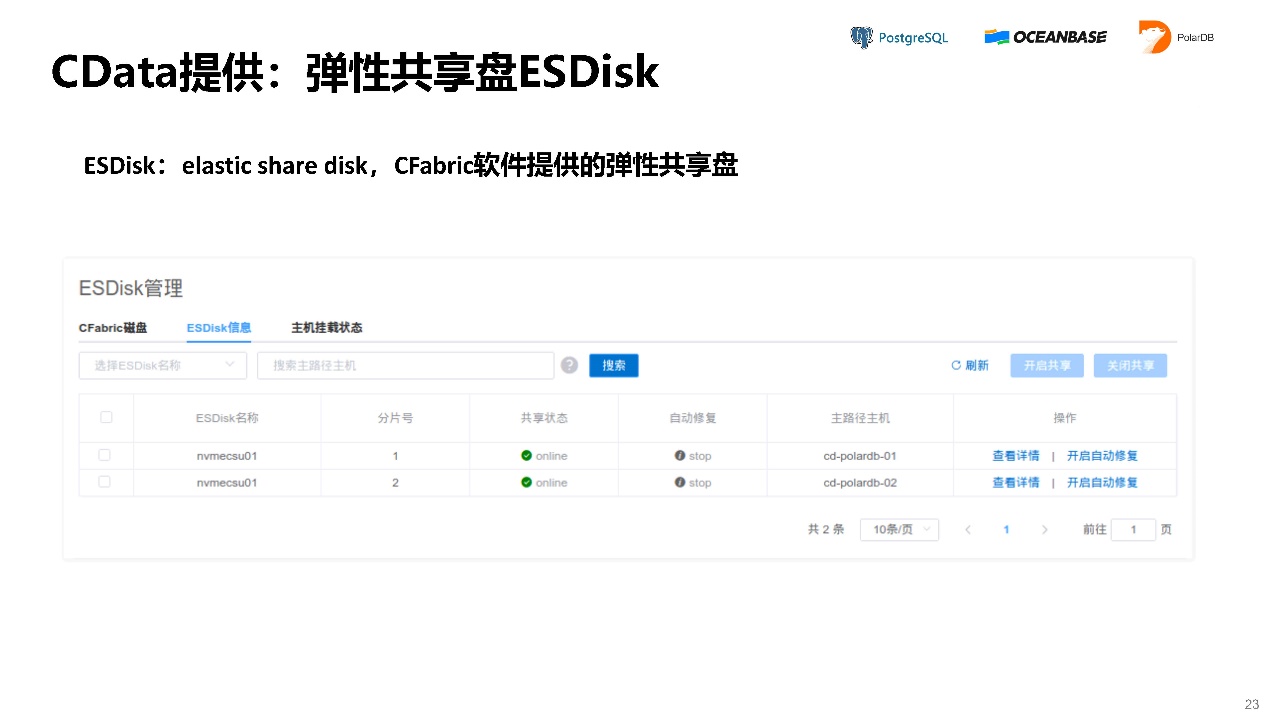
CData还提供了弹性共享盘ESDisk,把它挂在各个机上,它就能够跑起来。
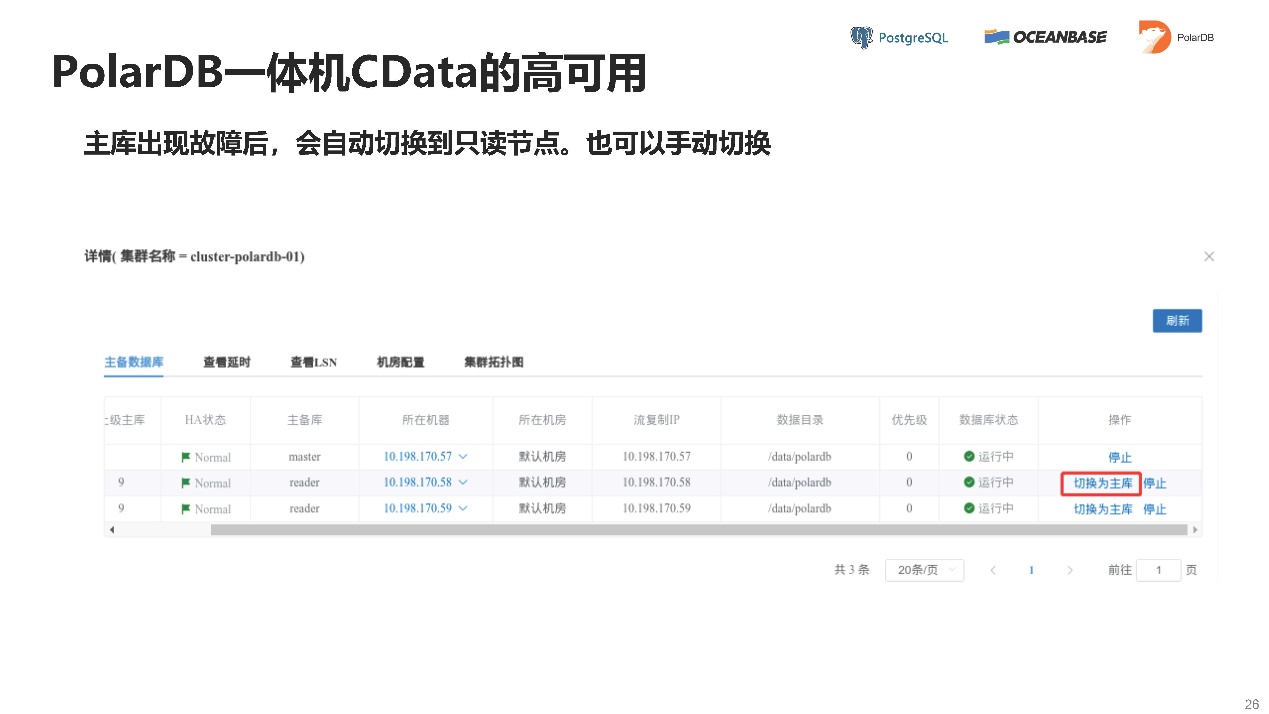
PolarDB一体机CData的高可用。主备可以互相切换,切换的也比较快,因为不涉及到数据。
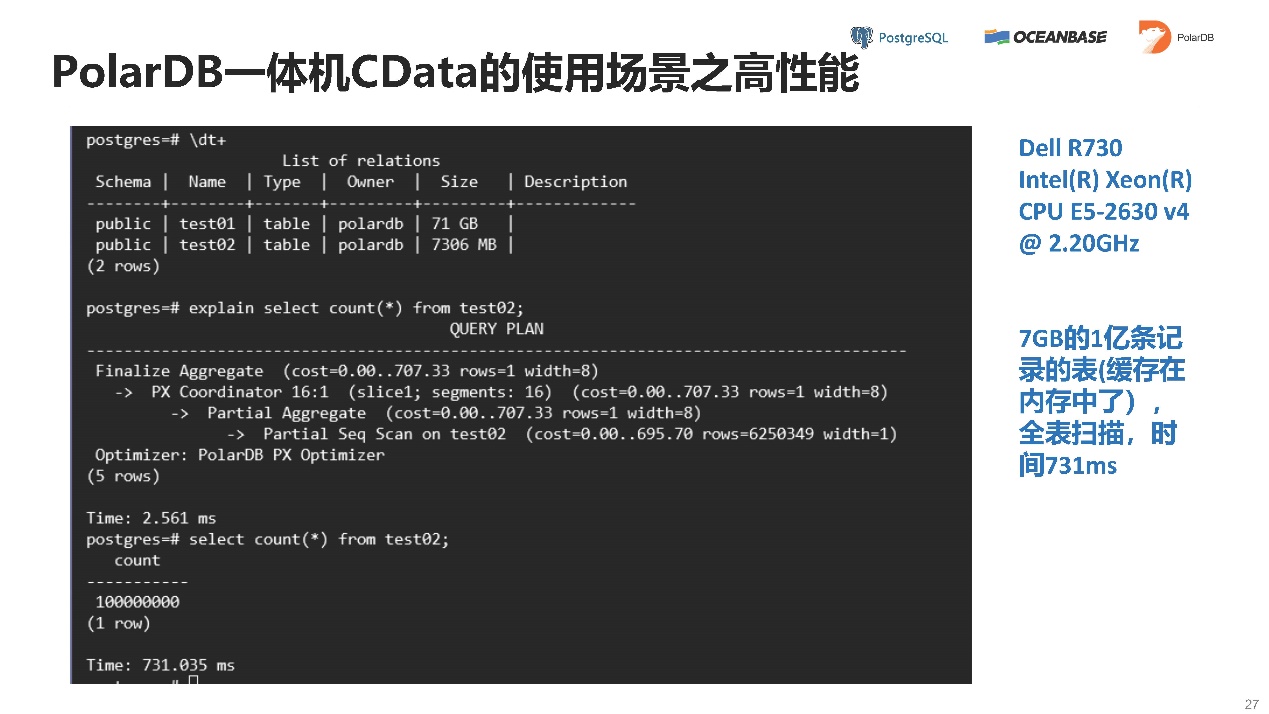
如上图所示,走了IO的情况下,7GB的1亿条记录的表,不到1秒就扫描出来了。
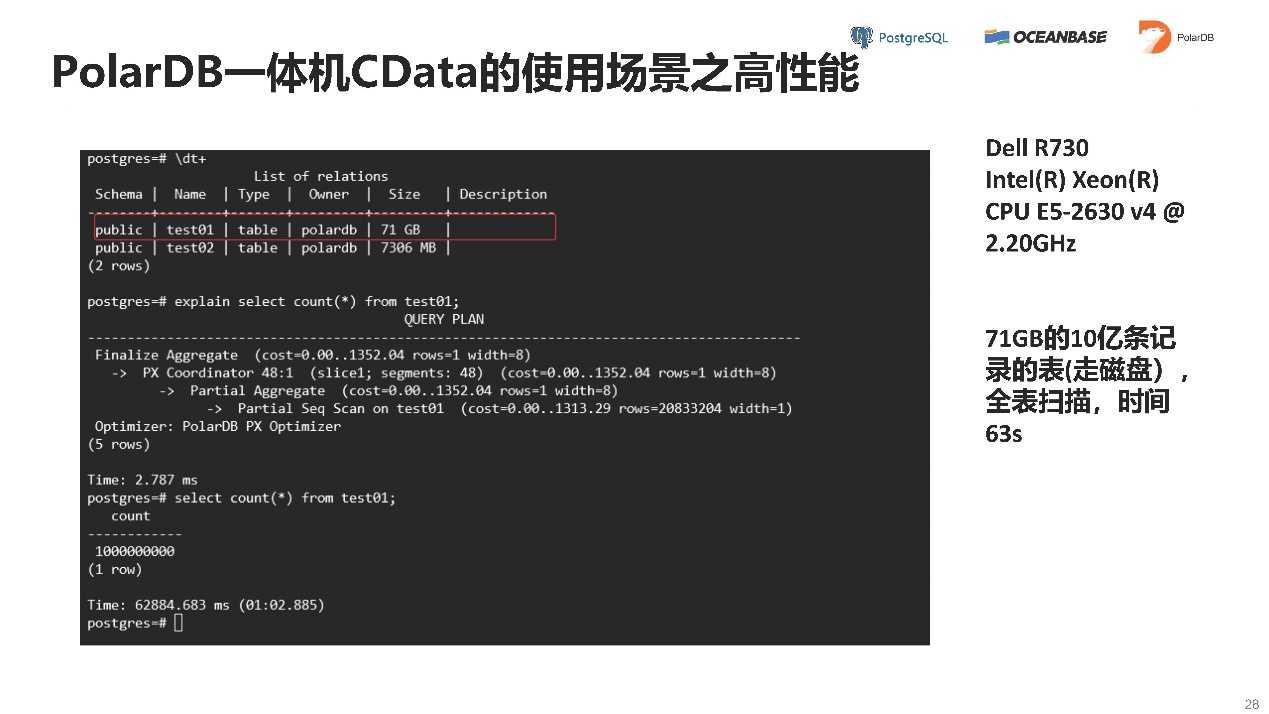
走了IO的情况下,71GB的10亿条记录的表,63秒就扫描出来了。
三、PolarDB一体机CData使用场景

最后介绍一下PolarDB一体机CData的使用场景之高性能。
第一个,百万QPS场景。
第二个,几十GB/s的吞吐场景。
第三个,难以做分库分表的高性能复杂业务,支持复杂的SQL。

在金融的一致性保障的场景下,储备库同步很快。对于专门做分布式数据的可能没人敢做,但如果你是从过去Oracle rake走过来的人,就会有一种感触。

在大容量场景下,你可以做一个PB级的数据量,然后在一个大的存储上加一个数据库。
