




备份数据库是一件至关重要的事情,在发生灾难性事件的时候,如服务器宕机、数据库崩溃等情况下,可以正常恢复数据。无论你的数据库运行在Docker,虚拟机或云上,备份数据库都是很重要的。话虽如此,为组织或个人决定备份和恢复策略可能是一个痛点。这当然需要了解您的应用程序、业务和成本。让我们了解从哪里开始以及如何选择 PostgreSQL 备份策略。
- 让我们深入探讨,这样一种情况:
我有一个以 PostgreSQL 作为后端的电子商务应用程序。 数据库大小不大,大约100GB。 我们的大多数用户都活跃到晚上 7 点,并且大多不会 24 小时访问。 我们每天晚上 12 点进行每日完整逻辑备份,大约需要 2 小时的时间,这是合理的,然后我们运行一些日常数据库操作。
周一早上 10 点,我们的系统崩溃了,数据盘不见了。 我们唯一的选择是从头开始重新创建数据库并使用逻辑备份从备份中恢复它。 恢复数据库大约需要3个小时。 我们做了一些内务管理、基本功能测试,并于下午 2 点为用户提供了应用程序。
我强调2点:
- 数据库是从前一天晚上的备份中恢复的。 10 小时的数据丢失。 –> 您丢失了多少数据或者您能够恢复到什么程度重要?
- 应用程序停机时间为 4 小时。 –> 您恢复数据库并使应用程序联机的速度有多快?
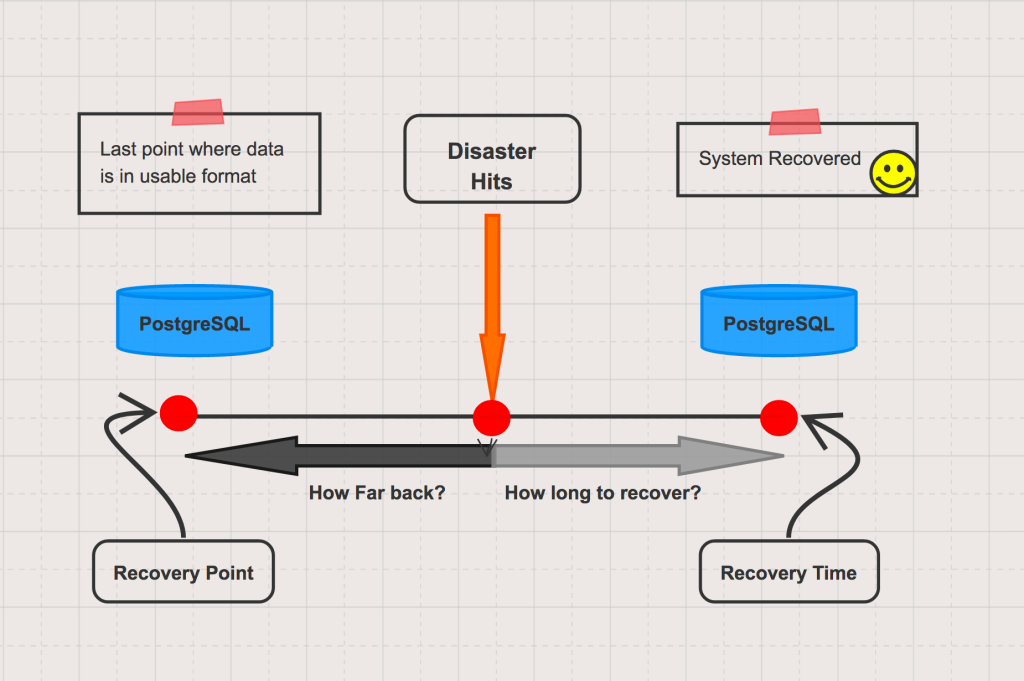
什么是恢复点目标 (RPO) 和恢复时间目标 (RTO)?
恢复点目标是对最大可容忍丢失数据量的测量。 它还有助于衡量上次数据备份与灾难之间可以发生多长时间,而不会对您的业务造成严重损害。 RPO 对于确定执行 PostgreSQL 备份的频率非常有用。
RPO 很重要,因为在大多数情况下,灾难发生时您可能会丢失一些数据。 即使实时备份的数据也存在部分数据丢失的风险。 大多数企业都会以固定的时间间隔备份数据——每小时一次、每天一次,或者可能每周一次。 RPO 衡量您可以承受因灾难而丢失的数据量。
例如,假设您每天午夜备份一次数据,而灾难在早上八点发生。 在这种情况下,您将丢失八小时的数据。 如果您的 RPO 为二十四小时或更长,那么您就处于良好状态。 但如果您的 RPO 是四个小时,那么您就不是。
恢复时间目标(RTO):
恢复时间目标是一个指标,可帮助计算灾难发生后恢复应用程序(应用程序 + 数据库)和服务所需的速度,以保持业务连续性。
RTO 是根据您的企业在灾难发生后恢复正常运营之前可以生存的时间来衡量的。 如果您的 RTO 是二十四小时,则意味着您已确定企业可以在没有正常数据和基础设施可用的情况下维持这段时间内的运营。 如果数据和基础设施无法在二十四小时内恢复,业务可能会遭受无法挽回的损失。
根据您的目标(就 RPO 和 RTO 而言),您必须决定您的备份策略。 要记住的关键事情之一是您的 PostgreSQL 备份策略包括:
- 备份方式(在线、离线、逻辑)
- PostgreSQL 备份的频率(每周、每日每小时)
在我提到的场景中,如果我们想以最小的数据丢失恢复数据库,我们可以使用以下策略
- 启用存档(将 WAL 存储到安全位置)
- 带有增量/归档备份的在线完整 PostgreSQL 备份 (PITR)。
- 每周完整备份
- 每日增量-午夜
我们可以通过从完整备份恢复数据库然后将增量(存档的 WAL)应用到最新点来使用时间点恢复。
最常见的PostgreSQL备份策略(根据环境)
在我的大部分专业经验中,作为数据库工程师,我意识到仅根据数据库的大小来定义备份策略是不明智的。 虽然在某些情况下结合在线和逻辑(pg_dump/pg_dumpall)是个好主意,但是应该考虑它是什么类型的数据以及在灾难性情况下您准备损失多少。
- 关键任务数据库和生产数据库的每周在线备份和每日增量备份。
- 非关键或开发数据库的逻辑备份 - 频率 - 每周或每两周一次。
备用备份方法
最常见和最常用的方法之一是进行在线备份,即pg_basebackup或将DB置于备份模式后执行文件系统级备份(复制数据目录)。 但是,如果您使用底层磁盘的存储管理器,则磁盘级快照是另一种方法。 如果您有非常大的数据库大小(2+ TB),卷快照会更快并且非常有用
如何降低RPO和RTO?
现在我们都了解 RPO 和 RTO 的用途以及它对于任何业务或运营的重要性。 以下是数据库级别的一些最常见和最佳实践,可帮助您降低 RPO 和 RTO:
-
具有自动故障转移功能的同步复制:如果您无法承受丢失数据的损失(关键任务应用程序、银行业、金融机构),那么同步 PostgreSQL 复制肯定会有所帮助,并且还可以确保您已提交数据副本(取决于同步模式) 您选择的)在备用节点上。 如果发生任何灾难,您可以自动/手动故障转移到备用状态,并显着降低 RTO 和 RPO。 除非您将应用程序设计为在完成事务之前等待数据库上的提交,否则此方法无法确保零数据丢失。 这种 PostgreSQL 同步复制方法还会增加应用程序性能的额外开销。
-
具有自动故障转移的异步复制:默认情况下,流式复制是异步的,在这种情况下,在主数据库中提交事务和更改在备用数据库中变得可见之间存在很小的延迟。 然而,这种延迟比基于文件的日志传送要小得多,并且还取决于负载/事务和网络带宽。 使用流式复制,不需要 archive_timeout 来减少数据丢失窗口。 我们还看到客户使用延迟 24 小时的备用来处理某些恢复情况,其中用户意外删除了表,延迟备用有助于恢复它。
recovery_min_apply_delay = '1h'
- 灾难恢复站点的考虑:PostgreSQL 确实允许您使用 WAL 创建到另一个区域的灾难恢复站点。 这对于确保您在另一个区域或数据中心拥有最新的数据库副本尤其重要,以防发生整个数据中心消失或无法访问的灾难情况。 您可能会或可能不会遭受数据丢失(恢复点目标)的打击,但即使站点完全消失,RTO 也会降低。
结论:
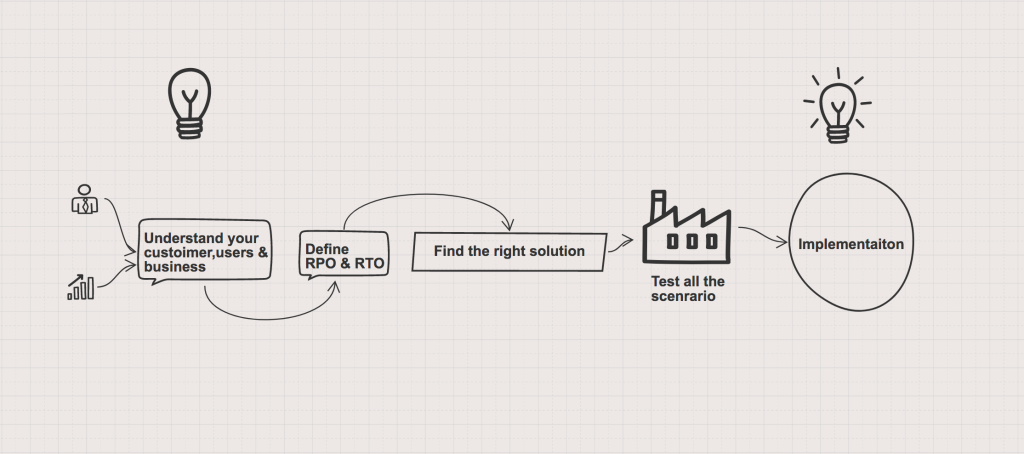
成功备份策略的关键是了解最终用户和企业。 它将帮助您了解数据的重要性以及您希望在发生灾难性情况时以多快的速度使系统可用。 这有助于我们定义 RTO 和 RPO。 找到正确的解决方案,无论是备份、备用还是任何灾难恢复策略,并确保其经过正确测试并最终实施。
原文标题:How to decide your PostgreSQL backup strategy?
原文作者:PostgreSQL Blog
原文地址:https://www.postgresql-blog.com/postgresql-backup-strategy-recovery-pitr-wal/
