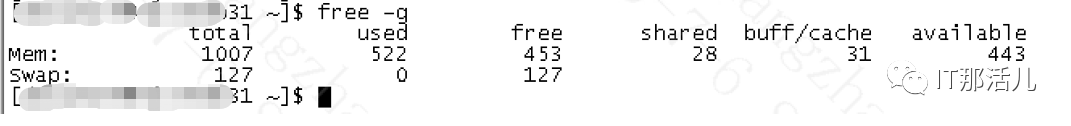点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!环境是HP的系统,12C的版本。
业务反馈数据库慢,实时查看数据库有大量的enq: TX - index contention出现严重问题时,业务称2节点卡顿严重,业务决策重启2节点。启动2节点期间1节点出现大量的library cache lock事件。先有索引分裂事件,随之业务持续进行,逐渐进展成严重的性能问题。
下午 14:39分业务反应数据库慢,查看到有大量enq: TX - index contention
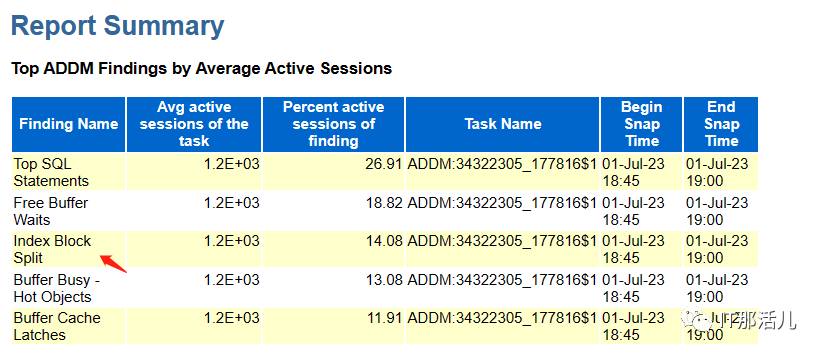
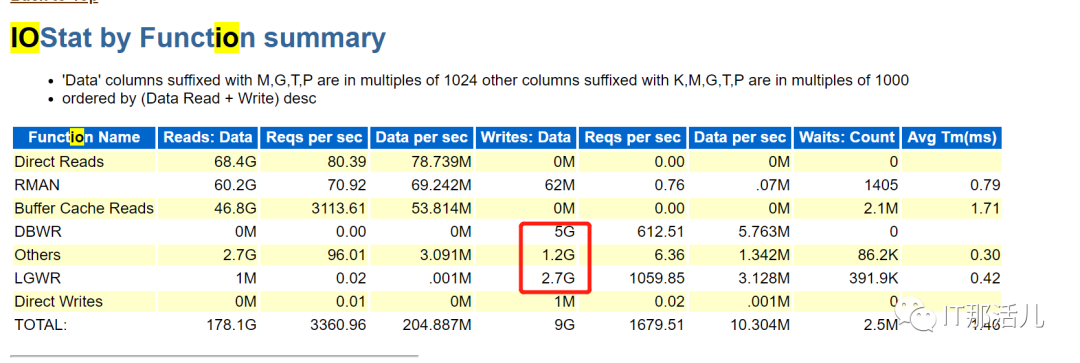
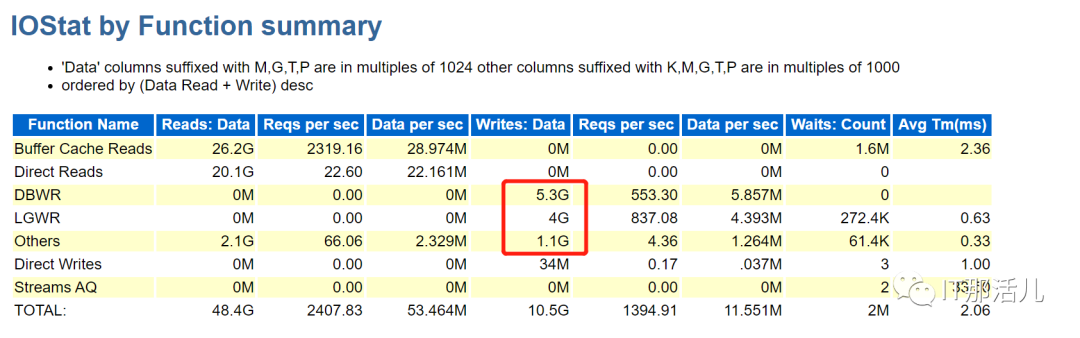
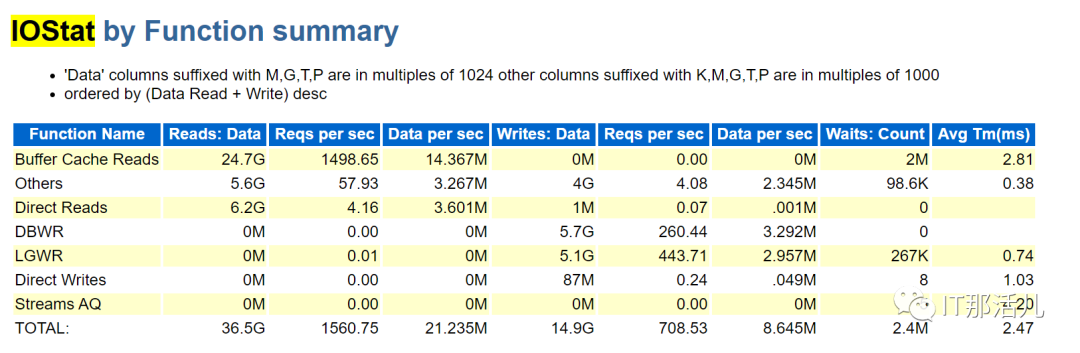
当时查询到的信息截图,可见正有较多的session正在处于enq: TX - index contention事件中,现场查询到相关事件会话正处于一部分的delete语句当中,同时session和event处于动态的变化过程中,随后观察到一个merge into和insert语句在批量执行。该问题后分析为该sql引起的性能问题,该sql在报告期内执行了15073次,产生了Buffer busy waits、index contention、latch: cache buffers lru chain,在繁忙度正常的系统上,index contention是很少出现的,如果出现了,则数据库可能在局部上开始呈现性能问题,这样的情况要看后续的业务是继续增长还是消退。同时这个sql产生了较高的DBTIME。已知下午时发生过类似问题,且该业务系统在月初可能存在较多的批量业务,18:57分时业务报数据库缓慢,则再次查看相关事件,也有大量的index contention。在该时间点后数据库的性能表现未能改善,且表现为更严重的性能问题。在处理问题时,对相关的索引竞争的session进行去重后的sql检索,可见insert语句为主,至少某种程度说明业务在批量入数。首先这个出现索引竞争,其次awr addm报告中出现Index Block Split,说明在数据库层面至少是发生了相关的事情。11g查refference则只有index block split事件:https://docs.oracle.com/cd/E11882_01/server.112/e40402/waitevents003.htm#REFRN00561是否i/o系统性能不足从而导致这些事件迟迟无法完成,是否为主要性原因?并不是,有以下佐证。- 查看Load Profile中关于i/o的统计并未发现严重性的问题。
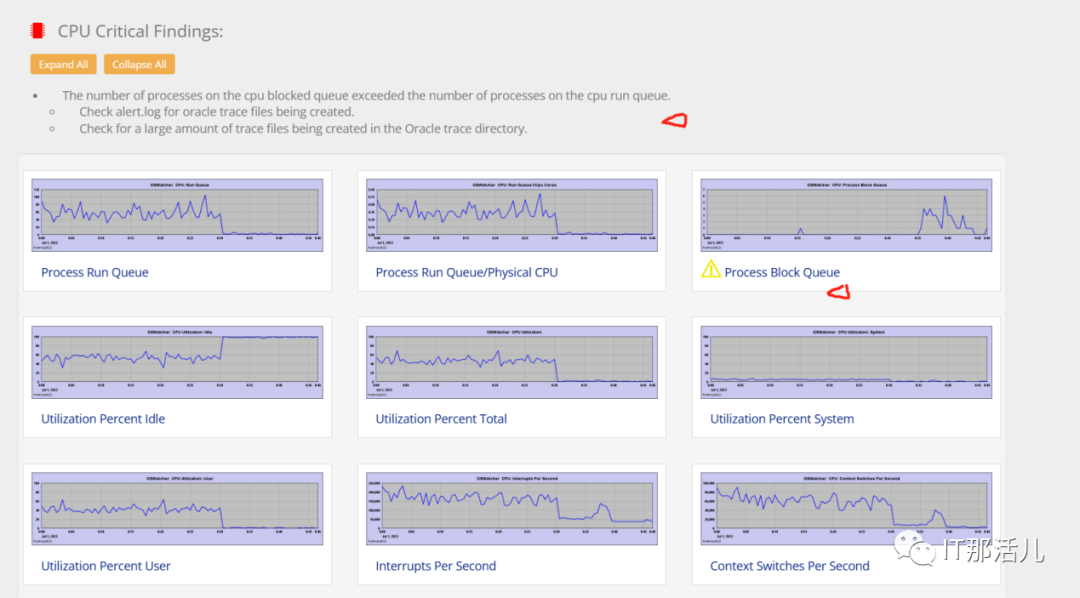
- 查看Key Instance Activity Stats、IOStat by Function summary等也没发现问题。
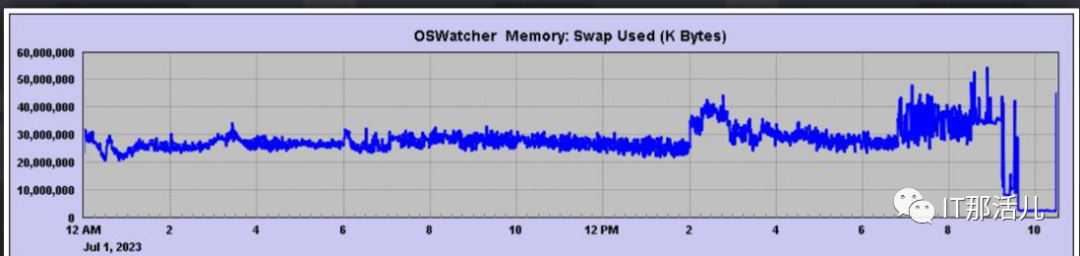
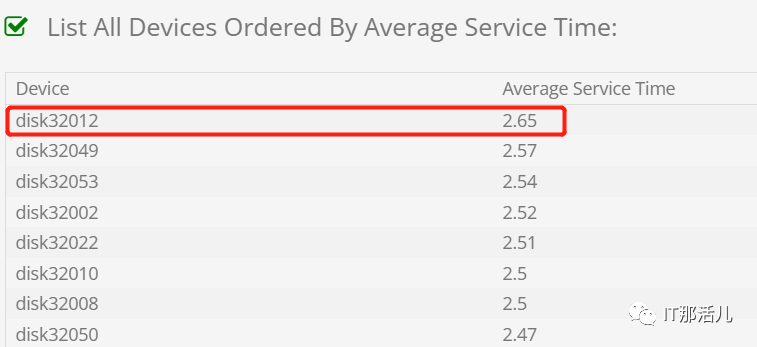
Swappiness可以具有0到100之间的值。值0指示内核积极地避免尽可能长时间地交换。值100将积极地将进程交换出物理内存:Process block queue 在部分时间升高:4份报告中,较明显的有32012,同时它的平均service time在榜首,考虑是否索引块刚好落在该磁盘?结合lgwr中的alert日志时而出现的告警超时告警,存在IO系统在短时间内的问题,这也可能是系统上层对下层的调用问题而出现。但无论如何,性能问题期间存续时间是更长的,相对退一步来说,即使i/o系统有性能问题,也应该是间歇性的,不会存续太长时间。查看相关的IO统计,并未发现写入量指数级的增长。(对于底层的数据块,可能存在串行写入的情况,可能会造成变慢情形)以一般的数据库(LINUX系统)对比,正常的系统并不会使用到swap。则问题sql高数据库时间的,并未在cpu和io上有体现相关的指标。但问题期间的insert 都很慢,且查看慢插入的sql在表级分类上具有局部性,addm报告的相关sql慢的情况都是相关insert语句。to_number(to_char(sysdate,'yyyymmdd')||to_char(seq_billadjustseq_id.nextval);
to_char(sysdate,'yyyymmddhh24mi')||to_char(T2.acctbk_payment_srl)||seq_acctbkpaymentseq_id.nextval;
to_char(T2.operating_srl) || seq_acctbkpaymentseq_id.nextval;
这些字段在时间+序列 拼接后,还是一个递增特性的值,同时sql上的插入语法为绑定变量,赋值后为正常的sql,(非insert into A select * from形式),此角度看不属“低质量”sql,在短期内同时入数时,易同块竞争产生,jzdb2为12c版本,无scalabale seqence特性(结合了instance_number和sid的序列),该特性可以降低竞争。优化方向提示:考虑sql中的取值增大离散程度。Awr报告中sql单次耗时长,但次数少的不一定是重点。再查看SQL ordered by Executions的topsql,排行榜易被一些select占着不易看到问题所在。dbtime和cputime反应了对应业务量的处理速度。查SQL ordered by Elapsed Time月初业务量大,event多集中在enq: TX - index contention,addm亦提示Index Block Split,考虑追踪这些相关sql的耗时和相关的表、索引结构、体量;也可以让业务尝试修改索引列的取值,增大离散程度,可以做相关测试验证性能提升。
同时索引并不是只有优点,也会带来插入数据时的维护问题,这是会影响系统效率的,应控制索引的数量和关联列,使得在带来更多收益。业务上如可以,亦可考虑表分区获益。期间的insert 业务多,耗时变长(平均插入时长)。与出现问题的起点:enq: TX - index contention一致(且7.1下午2点时已出现过相关问题),Hard parses未见异常,说明不是新的sql,或者在全局中的占比不大。查看Foreground Wait Events模块:总的等待时间和平均等待时间,对比正常时间段的事件等待时间有如下异常。enq: TX - index contention
enq: TX - row lock contention
enq: SQ – contention
library cache load lock
enq: TX - allocate ITL entry
Key Instance Activity Stats中db block changes并未见明显问题。