2023年9月22日消息,基于开源数据库DuckDB的商业化数据库公司 MotherDuck 宣布完成 5250 万美元 B 轮融资,使迄今为止的融资总额达到 1 亿美元。此轮融资由 Felicis 领投,新老投资者参与其中,包括 a16z、Madrona、Amplify Partners、Altimeter、Redpoint、Zero Prime 等。MotherDuck 的最新投资将推动 DuckDB 协作和可扩展性功能的持续发展,与 DuckDB 的开发人员创新其数据库引擎以及 DuckDB 采用率的增长保持同步。
2022年MotherDuck成立,并在当年获得了由RedPoint领投的125万美元的种子轮、由a16z领投的3500万美元的A轮。在toB融资环境快速冷却的2022年,MotherDuck成为了难得的明星项目。

MotherDuck 首席执行官兼联合创始人 Jordan Tigani 表示:“我们对去年与 DuckDB 社区和 DuckDB Labs 团队一起取得的成就感到自豪。” “我们的初始资金使我们能够壮大我们的工程团队,从而推出我们的平台并让近 2,000 名分析师使用。凭借这笔资金以及围绕我们平台和 DuckDB 的采用的势头,天空是极限。”
“关键是 SQL 分析的简化扩展方法;对于我们中 95% 没有 PB 级数据的人来说,基于 DuckDB 等引擎的扩展分析方法比分布式架构更快、更便宜、更用户友好。”Tigani 继续说道。“上周在阿姆斯特丹与 DuckDB 团队一起度过的时光巩固了 DuckDB 的未来。我们很高兴能够将其简单性的力量大规模地带给组织,并全面改善分析师的体验。”
随着本轮融资的宣布,MotherDuck 将不再为那些寻求试用该平台的人设置等待名单障碍。据该公司称,感兴趣的人只需在 MotherDuck 网站上注册即可开始大规模利用 DuckDB 的强大功能。
这笔资金还伴随着根据客户反馈推出的多项新功能的推出,包括更快的数据导入、具有 SQL 自动完成功能的增强型笔记本界面、优化的混合查询规划以及改进的数据库共享。
MotherDuck 生态系统随着其成功而不断发展,带来了 11 个与平台的新集成,包括 Cube、dltHub、Evidence、GoodData、Kestra、Metabase、InfinyOn、LlamaIndex、Sling、Streamlit 和 Voltron Data 的集成。新的 Airbyte 集成将于今天向用户提供。即将推出与 Fivetran 和 Tableau 的集成。
MotherDuck 的融资公告先于 DuckDB 即将发布的 0.9.0 版本,该版本将提供给 MotherDuck 用户。

MotherDuck背后是哪些人?
MotherDuck的创始人Jordan是DuckDB的早期用户。 Jordan此前是Google BigQuery的创始工程师和产品经理,后来在SingleStore担任CPO期间,出于对DuckDB的欣赏,开始做side-project来丰富DuckDB生态,希望通过增加云端的serverless版本来真正实现EasyQuery。在Jordan与Google前同事Lloyd的交流中,有着Looker成功创业经验的Lloyd看到了Jordan所做副业的更大潜力,便说服其将副业项目作为主业投入更多时间精力,还体贴地帮忙介绍RedPoint的投资人、帮忙与DuckDB Labs团队牵线,还为新项目命名MotherDuck。
于是,去年5月,MotherDuck成立,并在当年获得了由RedPoint领投的125万美元的种子轮、由a16z领投的3500万美元的A轮。在toB融资环境快速冷却的2022年,MotherDuck成为了难得的明星项目。“种子看人、VC看事、PE看数”的投资规律在MotherDuck身上得到了应验——在一个急转直下的融资赛道中逆流而上的项目背后,是一支从Google BigQuery走出的全明星团队:
- 产品负责人Tino:此前在BigQuery和YouTube团队担任产品经理,随后去了Snowflake的直接竞争对手Firebolt担任产品VP
- 负责市场和开发者关系的Ryan:此前在Google、Neo4j、Databricks有累计15年的开发者关系的工作经历,并担任众多科技公司的GTM咨询顾问
- 创始工程师们:有着Snowflake, Databricks, AWS, Google, Microsoft, Teradata, ElasticSearch, SingleStore, Meta等一众科技巨头的工作经历背书
- 兼职专家顾问们:有First Round Capital的Myoung做财务支撑,有Looker和Firebolt的Nouras做合作伙伴关系建设,有身为ACM Fellow的CWI数据库教授Peter做“实习生”


MotherDuck目前能帮助用户作什么?
那么,MotherDuck在DuckDB产品能力基础上做了什么呢?
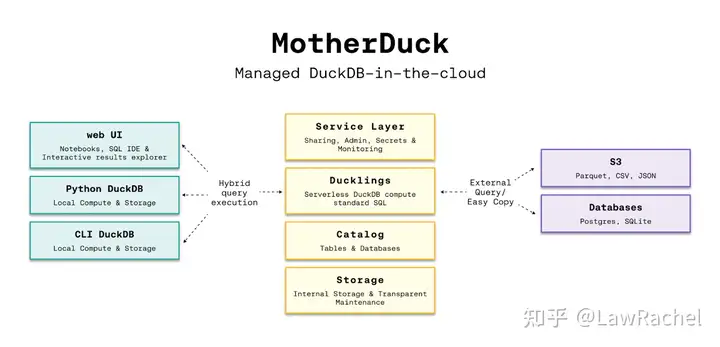
(1)产品架构
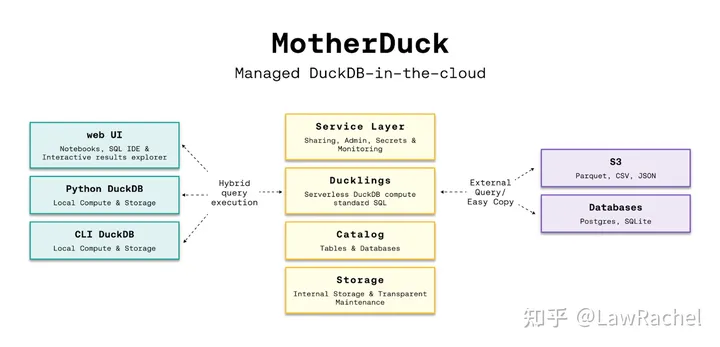
MotherDuck在官方文档对其产品架构给出了答复:
- Cloud Service:提供身份管理、认证授权、监控审计等安全类功能,提供数据分享功能,并提供Web UI进行访问;
- Compute:以Serverless方式调用本地和远程的DuckDB实例,调用CPU和内存执行计算任务;
- Storage:在DuckDB的易失性存储的基础上,提供云端的非易失性存储,支持用户将数据导入至MotherDuck进行持久化存储;
- Client SDK:除了Web UI访问外,还给Python用户和DuckDB CLI用户提供了SDK,调用时通过MotherDuck的Token进行身份认证后可以直接从该Client访问MotherDuck;并支持在JDBC Driver, Go Driver, DBeaver, Alchemy等终端进行访问;
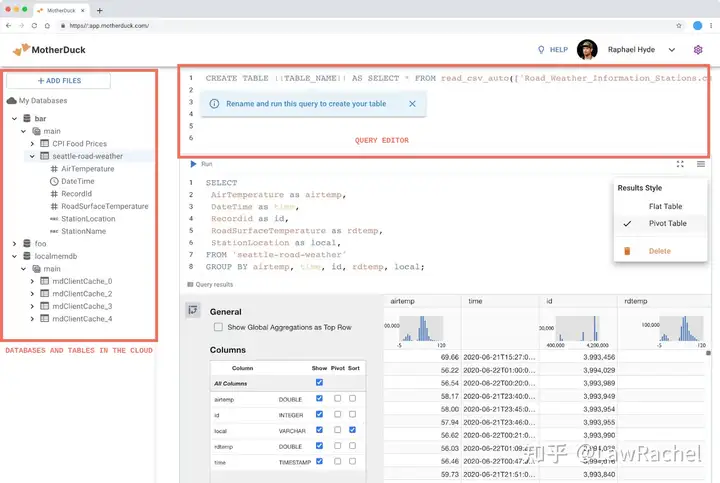
(2)从Web UI接入
MotherDuck目前采用的云端技术方案是:域名在GoDaddy购买,DNS和CDN等网络访问使用AWS CloudFront,数据托管在AWS S3。其官网宣传主页是http://motherduck.com,产品环境放在了二级域名http://app.motherduck.com下。在Web UI登录后,Landing Page即是Query Editor。
虽然一开始看起来,MotherDuck和DuckDB的WASM版功能是一样的,但不同的是, MotherDuck可以同时调用本地计算机和远程服务器的DuckDB实例。例如,在联网时,打开MotherDuck和DuckDB WASM;断网后,都能在二者执行上传本地文件、查询等命令,但可以在DuckDB WASM执行建表操作,但无法在MotherDuck执行建表;联网后,在MotherDuck的Web UI的建表语句点击Run后会,会调用manifest和DoAction API向远程服务器发送请求。
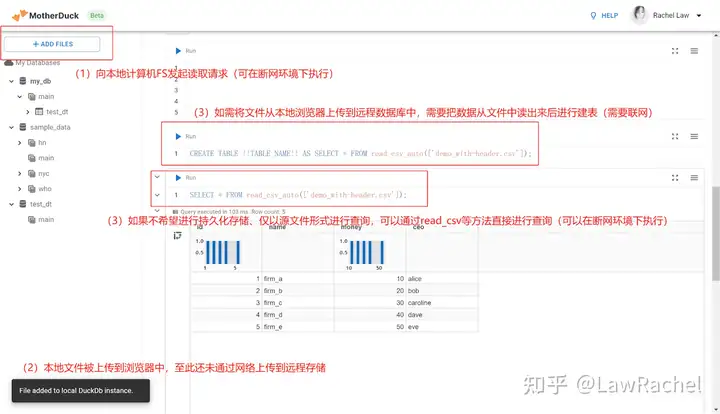
(3)从Client接入
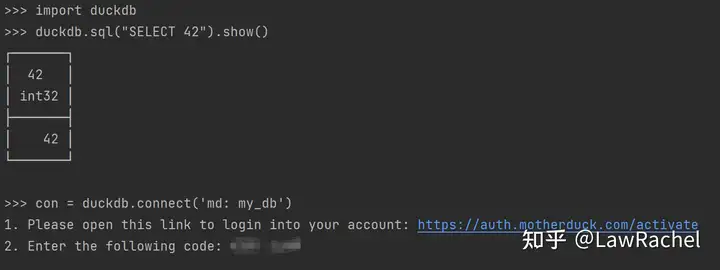
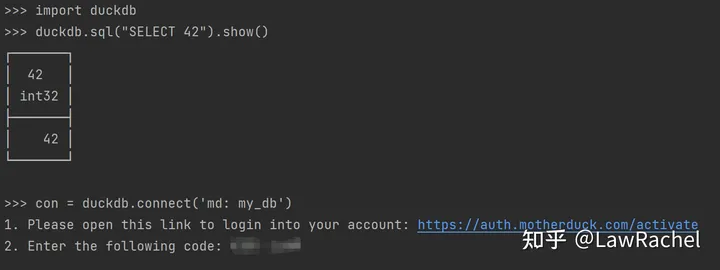
此外,在不使用Web UI作为Client的使用场景下,MotherDuck还支持将DuckDB CLI和Python Client作为接入终端:
- Python:通过
duckdb.connect(‘md:’)命令唤起身份认证,在MotherDuck验证身份后可以在该Python Client连接到MotherDuck - DuckDB:通过
open md: 命令唤起身份认证,然后在DuckDB CLI对MotherDuck后台进行读写
(4)杀手级功能
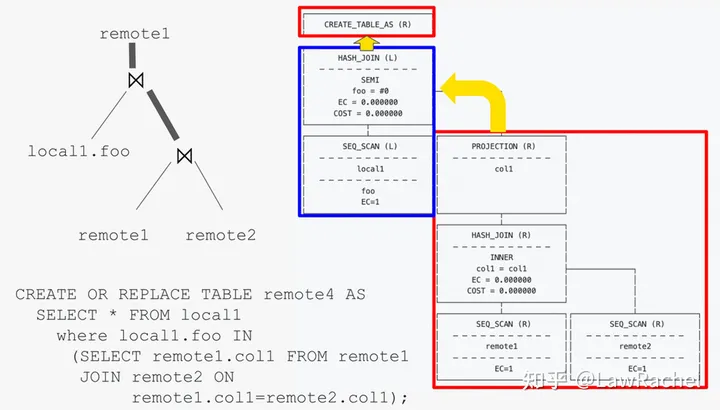
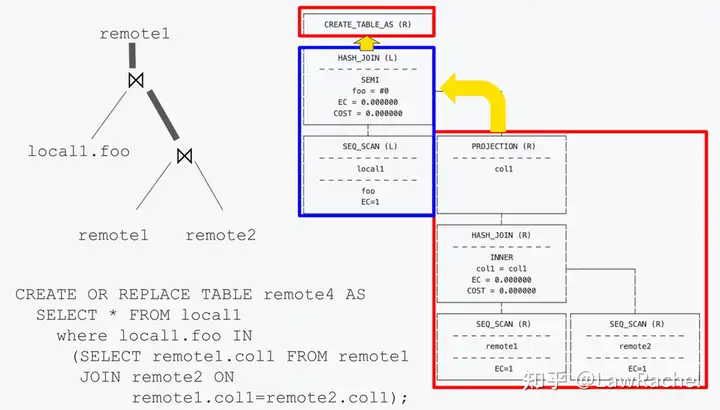
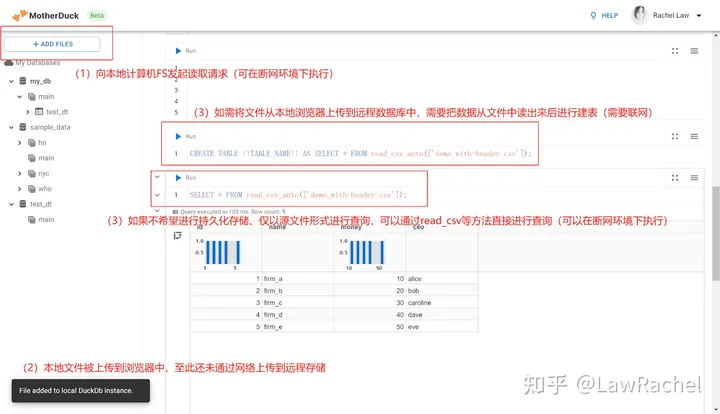
如果说DuckDB的杀手级功能是在去ELT基础上直接对本地和远程的不同文件进行Hybrid Query的话,那么MotherDuck的杀手级功能就是: 在Hybrid Query基础上对本地计算机和远程服务器计算资源综合调用的Hybrid Execution,将DuckDB的能力从Client扩展至Cloud。
以Web UI方式使用MotherDuck时:
- 用户登录http://app.motherduck.com后, 会在本地浏览器和远程服务器中分别启动DuckDB实例;
- 当用户从本地文件系统上传文件至浏览器中的DuckDB,并仅对浏览器中的文件进行读写查询、不访问远程文件时, MotherDuck会把查询任务路由回浏览器中的DuckDB,仅调用本地计算机的计算资源;用户无需等待云端服务器,可以直接在断网情况下执行查询任务,并支持跨文件JOIN;
- 当用户仅访问远程API或S3文件时,MotherDuck会把文件中的数据读到其服务器中的DuckDB, 并在不导入文件、转换格式、进行持久化存储的情况下,直接对远程文件进行读写查询;仅调用远程服务器的计算资源,必须在能正常访问MotherDuck的情况下执行查询任务,支持跨文件JOIN;
- 当用户从本地文件系统或者远程S3、API读取文件并通过建表、更新、插入、替换等命令将文件导入到MotherDuck服务器进行持久化存储时,MotherDuck调用其服务器中的DuckDB;仅调用远程服务器的计算资源,必须在能正常访问MotherDuck的情况下执行查询任务,支持跨文件JOIN;
- 当用户的查询请求目标对象同时包含本地文件、远程API或S3文件、MotherDuck存储的文件时, MotherDuck对查询语句解析和优化后,将不同的子任务拆分给本地浏览器和远程服务器中的DuckDB实例,同时调用本地和远程的计算资源;
以Python SDK或者DuckDB CLI SDK使用MotherDuck时,计算资源调用逻辑同Web UI使用方式,但不涉及浏览器进程,仅涉及Python或者CLI。
Who:MotherDuck背后是哪些人?
MotherDuck的创始人Jordan是DuckDB的早期用户。 Jordan此前是Google BigQuery的创始工程师和产品经理,后来在SingleStore担任CPO期间,出于对DuckDB的欣赏,开始做side-project来丰富DuckDB生态,希望通过增加云端的serverless版本来真正实现EasyQuery。在Jordan与Google前同事Lloyd的交流中,有着Looker成功创业经验的Lloyd看到了Jordan所做副业的更大潜力,便说服其将副业项目作为主业投入更多时间精力,还体贴地帮忙介绍RedPoint的投资人、帮忙与DuckDB Labs团队牵线,还为新项目命名MotherDuck。
于是,去年5月,MotherDuck成立,并在当年获得了由RedPoint领投的125万美元的种子轮、由a16z领投的3500万美元的A轮。在toB融资环境快速冷却的2022年,MotherDuck成为了难得的明星项目。“种子看人、VC看事、PE看数”的投资规律在MotherDuck身上得到了应验——在一个急转直下的融资赛道中逆流而上的项目背后,是一支从Google BigQuery走出的全明星团队:
- 产品负责人Tino:此前在BigQuery和YouTube团队担任产品经理,随后去了Snowflake的直接竞争对手Firebolt担任产品VP
- 负责市场和开发者关系的Ryan:此前在Google、Neo4j、Databricks有累计15年的开发者关系的工作经历,并担任众多科技公司的GTM咨询顾问
- 创始工程师们:有着Snowflake, Databricks, AWS, Google, Microsoft, Teradata, ElasticSearch, SingleStore, Meta等一众科技巨头的工作经历背书
- 兼职专家顾问们:有First Round Capital的Myoung做财务支撑,有Looker和Firebolt的Nouras做合作伙伴关系建设,有身为ACM Fellow的CWI数据库教授Peter做“实习生”

3.2 What:MotherDuck目前能帮助用户作什么?
那么,MotherDuck在DuckDB产品能力基础上做了什么呢?
(1)产品架构
MotherDuck在官方文档对其产品架构给出了答复:
- Cloud Service:提供身份管理、认证授权、监控审计等安全类功能,提供数据分享功能,并提供Web UI进行访问;
- Compute:以Serverless方式调用本地和远程的DuckDB实例,调用CPU和内存执行计算任务;
- Storage:在DuckDB的易失性存储的基础上,提供云端的非易失性存储,支持用户将数据导入至MotherDuck进行持久化存储;
- Client SDK:除了Web UI访问外,还给Python用户和DuckDB CLI用户提供了SDK,调用时通过MotherDuck的Token进行身份认证后可以直接从该Client访问MotherDuck;并支持在JDBC Driver, Go Driver, DBeaver, Alchemy等终端进行访问;
(2)从Web UI接入
MotherDuck目前采用的云端技术方案是:域名在GoDaddy购买,DNS和CDN等网络访问使用AWS CloudFront,数据托管在AWS S3。其官网宣传主页是http://motherduck.com,产品环境放在了二级域名http://app.motherduck.com下。在Web UI登录后,Landing Page即是Query Editor。
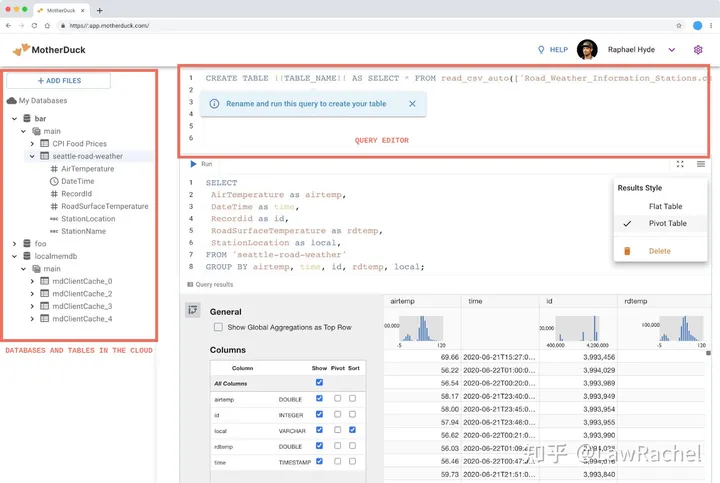
虽然一开始看起来,MotherDuck和DuckDB的WASM版功能是一样的,但不同的是, MotherDuck可以同时调用本地计算机和远程服务器的DuckDB实例。例如,在联网时,打开MotherDuck和DuckDB WASM;断网后,都能在二者执行上传本地文件、查询等命令,但可以在DuckDB WASM执行建表操作,但无法在MotherDuck执行建表;联网后,在MotherDuck的Web UI的建表语句点击Run后会,会调用manifest和DoAction API向远程服务器发送请求。
(3)从Client接入
此外,在不使用Web UI作为Client的使用场景下,MotherDuck还支持将DuckDB CLI和Python Client作为接入终端:
- Python:通过
duckdb.connect(‘md:’)命令唤起身份认证,在MotherDuck验证身份后可以在该Python Client连接到MotherDuck - DuckDB:通过
open md: 命令唤起身份认证,然后在DuckDB CLI对MotherDuck后台进行读写
(4)杀手级功能
如果说DuckDB的杀手级功能是在去ELT基础上直接对本地和远程的不同文件进行Hybrid Query的话,那么MotherDuck的杀手级功能就是: 在Hybrid Query基础上对本地计算机和远程服务器计算资源综合调用的Hybrid Execution,将DuckDB的能力从Client扩展至Cloud。
以Web UI方式使用MotherDuck时:
- 用户登录http://app.motherduck.com后, 会在本地浏览器和远程服务器中分别启动DuckDB实例;
- 当用户从本地文件系统上传文件至浏览器中的DuckDB,并仅对浏览器中的文件进行读写查询、不访问远程文件时, MotherDuck会把查询任务路由回浏览器中的DuckDB,仅调用本地计算机的计算资源;用户无需等待云端服务器,可以直接在断网情况下执行查询任务,并支持跨文件JOIN;
- 当用户仅访问远程API或S3文件时,MotherDuck会把文件中的数据读到其服务器中的DuckDB, 并在不导入文件、转换格式、进行持久化存储的情况下,直接对远程文件进行读写查询;仅调用远程服务器的计算资源,必须在能正常访问MotherDuck的情况下执行查询任务,支持跨文件JOIN;
- 当用户从本地文件系统或者远程S3、API读取文件并通过建表、更新、插入、替换等命令将文件导入到MotherDuck服务器进行持久化存储时,MotherDuck调用其服务器中的DuckDB;仅调用远程服务器的计算资源,必须在能正常访问MotherDuck的情况下执行查询任务,支持跨文件JOIN;
- 当用户的查询请求目标对象同时包含本地文件、远程API或S3文件、MotherDuck存储的文件时, MotherDuck对查询语句解析和优化后,将不同的子任务拆分给本地浏览器和远程服务器中的DuckDB实例,同时调用本地和远程的计算资源;
以Python SDK或者DuckDB CLI SDK使用MotherDuck时,计算资源调用逻辑同Web UI使用方式,但不涉及浏览器进程,仅涉及Python或者CLI。