







数据源多样:常用的数据源有数百种,版本不兼容。随着新技术的出现,出现了更多的数据源。用户很难找到能够全面快速支持这些数据源的工具。 复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、全库同步等多种同步场景。 资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或 JDBC 连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。 缺乏质量和监控:数据集成和同步过程经常会丢失或重复数据。同步过程缺乏监控,无法直观了解任务过程中数据的真实情况。
./bin/seatunnel.sh -m local -c ./config/localfile-oss.config
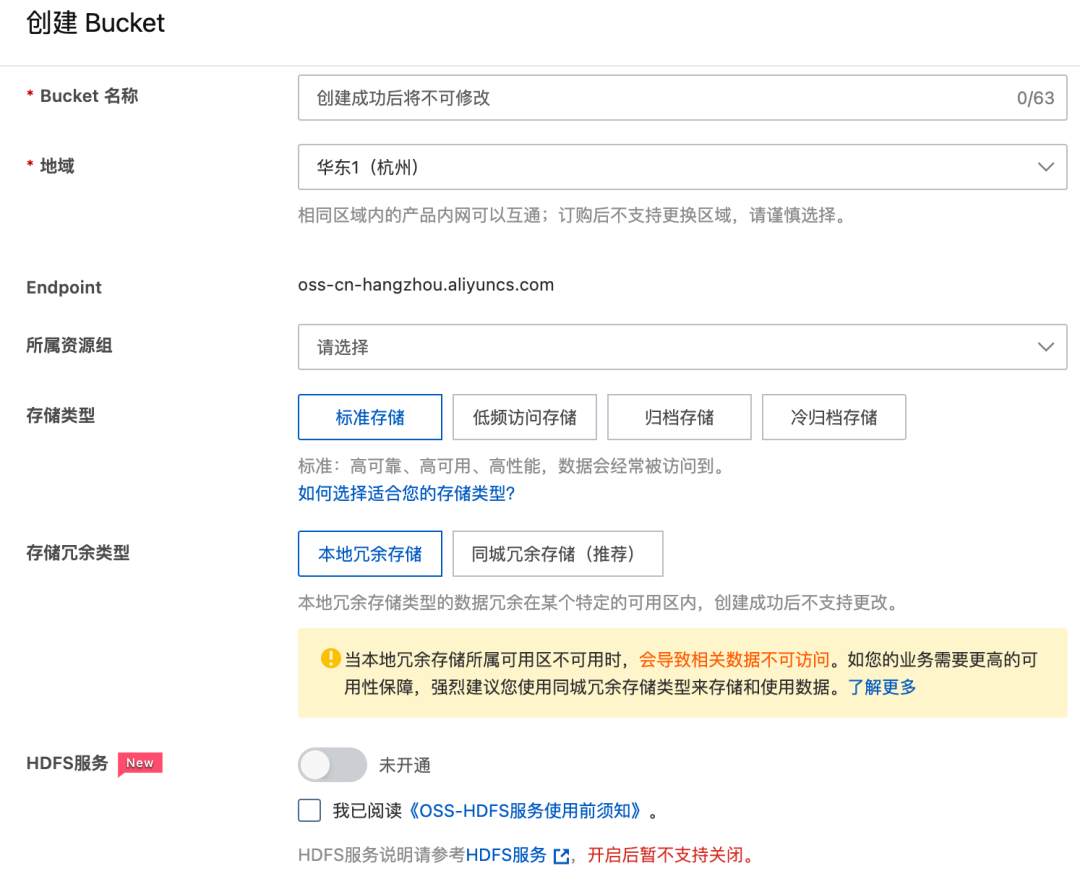
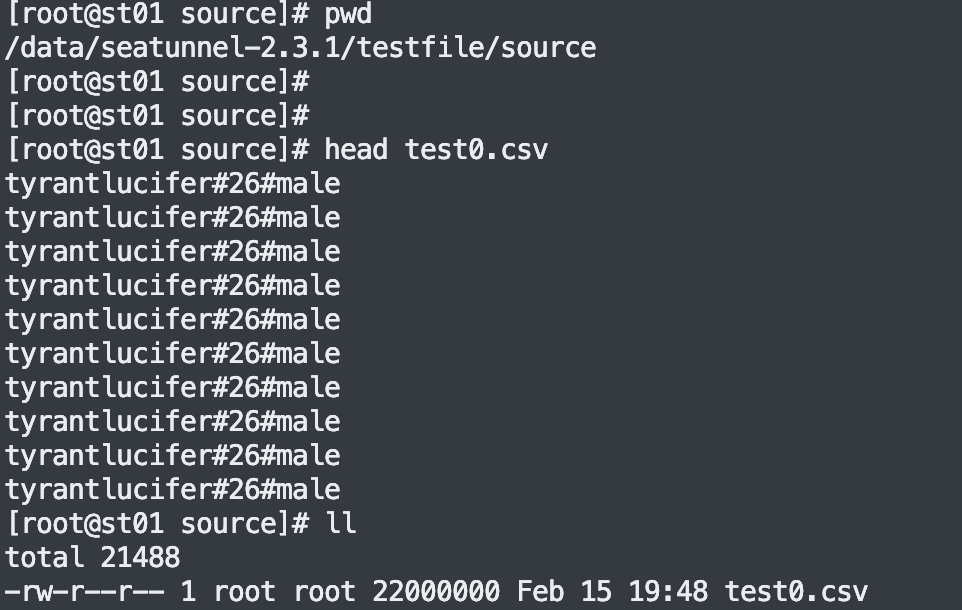
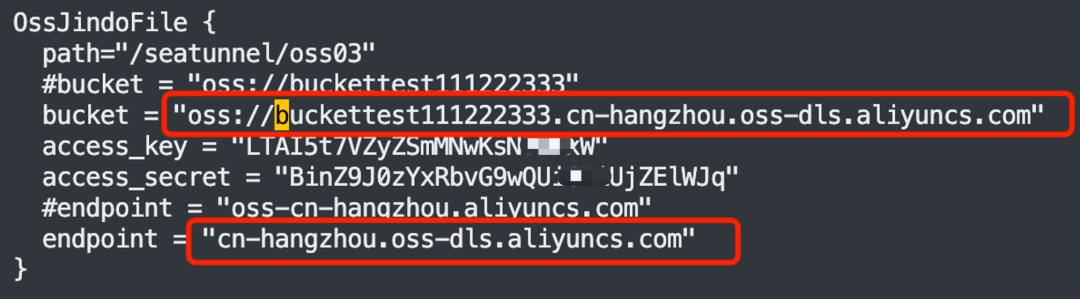
env {# You can set SeaTunnel environment configuration hereexecution.parallelism = 10job.mode = "BATCH"checkpoint.interval = 10000#execution.checkpoint.interval = 10000#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"}source {LocalFile {#本地待同步的数据文件夹, 本例子中只有一个 test0.csv 文件,具体内容参考下图path = "/data/seatunnel-2.3.3/testfile/source"type = "csv"delimiter = "#"schema {fields {name = stringage = intgender = string}}}}sink {OssJindoFile {path="/seatunnel/oss03"bucket = "oss://bucket123456654321234.cn-hangzhou.oss-dls.aliyuncs.com"access_key = "I5**********W"access_secret = "Bi***********TA"endpoint = "cn-hangzhou.oss-dls.aliyuncs.com"}}
Apache SeaTunnel
精彩推荐
一键三连-点赞在看转发⭐️!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
