




嵌套查询
在SQL语言中,一个SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询(nested query)。例如:
SELECT Sname
FROM Student
WHERE Sno IN
(SELECT Sno
FROM SC
WHERE Cno='2');
本例中,下层查询块SELECT Sno FROM SC WHERE Cno='2'是嵌套在上层查询块SELECT Sname FROM Student WHERE Sno IN的WHERE条件中的。上层的查询块称为外层查询或父查询,下层查询块称为内层查询或子查询。
SQL语言允许多层嵌套查询,即一个子查询中还可以嵌套其他子查询。需要特别指出的是,子查询的SELECT语句中不能使用ORDER BY子句,ORDER BY子句只能对最终查询结果排序。
嵌套查询使用户可以用多个简单查询构成复杂的查询,从而增强SQL的查询能力。以层层嵌套的方式来构造程序正是SQL中“结构化”的含义所在。
①带有IN谓词的子查询
在嵌套查询中,子查询的结果往往是一个集合,所以谓词IN是嵌套查询中最经常使用的谓词。
【例1】查询与“刘晨”在同一个系学习的学生。
先分步来完成此查询,然后再构造嵌套查询。
①确定“刘晨”所在系名
SELECT Sdept
FROM Student
WHERE Sname='刘晨';
结果为CS。
②查找所有在CS系学习的学生。
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept='CS';
结果为

将第一步查询嵌入到第二步查询的条件中,构造嵌套查询如下:
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept IN
(SELECT Sdept
FROM Student
WHERE Sname='刘晨';
本例中,子查询的查询条件不依赖于父查询,称为不相关子查询。一种求解方法是由里向外处理,即先执行子查询,子查询的结果用于建立其父查询的查找条件。得到如下的语句:
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept IN ('CS');
然后执行该语句。
本例中的查询也可以用自身连接来完成:
SELECT S1.Sno, S1.Sname, S1.Sdept
FROM Student S1, Student S2
WHERE S1.Sdept=S2.Sdept AND S2.Sname='刘晨';
可见,实现同一个查询请求可以有多种方法,当然不同的方法其执行效率可能会有差别,甚至会差别很大。这就是数据库编程人员应该掌握的数据库性能调优技术,有兴趣的可以参考本章相关文献资料和具体产品的性能调优方法。
【例2】查询选修了课程名为“信息系统”的学生学号和姓名。
本查询涉及学号、姓名和课程名三个属性。学号和姓名存放在Student表中,课程名存放在Course表中,但Student与Course两个表之间没有直接联系,必须通过SC表建立它们二者之间的联系。所以本查询实际上涉及三个关系。
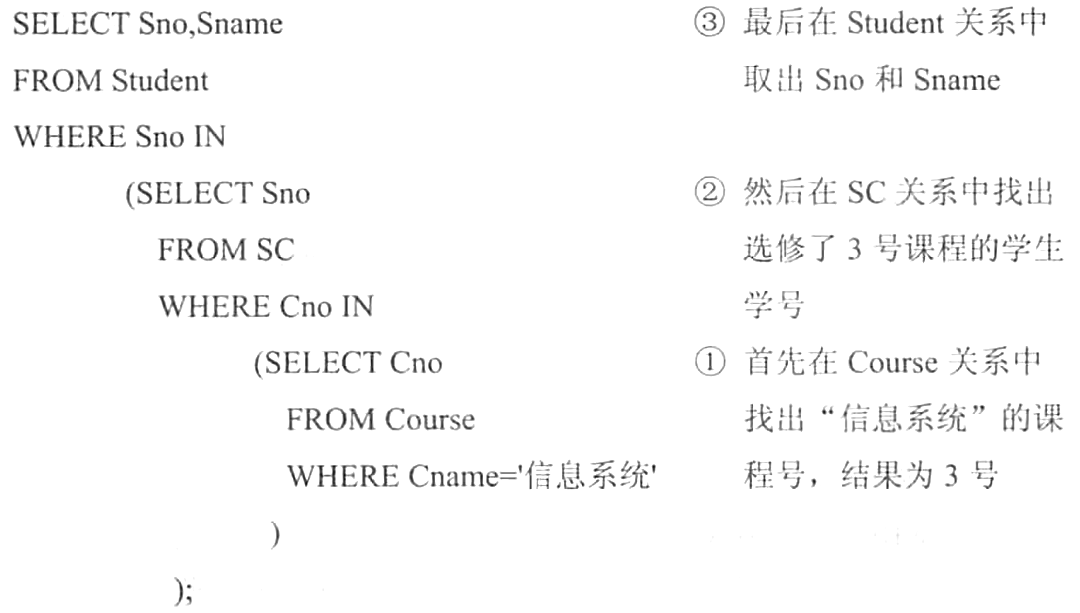
本查询同样可以用连接查询实现:
SELECT Student.Sno,Sname
FROM Student,SC,Course
WHERE Student.Sno=SC.Sno
AND SC.Cno=Course.Cno
AND Course.Cname='信息系统';
有些嵌套查询可以用连接运算替代,有些是不能替代的。从例1和例2可以看到,查询涉及多个关系时,用嵌套查询逐步求解层次清楚,易于构造,具有结构化程序设计的优点。但是相比于连接运算,目前商用关系数据库管理系统对嵌套查询的优化做得还不够完善,所以在实际应用中,能够用连接运算表达的查询尽可能采用连接运算。
例1和例2中子查询的查询条件不依赖于父查询,这类子查询称为不相关子查询。不相关子查询是较简单的一类子查询。如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询(correlated subquery),整个查询语句称为相关嵌套查询(correlated nested query)语句。
例3就是一个相关子查询的例子。
②带有比较运算符的子查询
带有比较运算符的子查询是指父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是单个值时,可以用>、<、=、>=、<=、!=或<>等比较运算符。
例如在例1中,由于一个学生只可能在一个系学习,也就是说内查询的结果是一个值,因此可以用=代替IN:
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept =
(SELECT Sdept
FROM Student
WHERE Sname='刘晨');
【例3】找出每个学生超过他自己选修课程平均成绩的课程号。
SELECT Sno,Cno
FROM SC x
WHERE Grade >=
(SELECT AVG(Grade)
FROM SC y
WHERE y.Sno=x.Sno);
x是表SC的别名,又称为元组变量,可以用来表示SC的一个元组。内层查询是求一个学生所有选修课程平均成绩的,至于是哪个学生的平均成绩要看参数x.Sno的值,而该值是与父查询相关的,因此这类查询称为相关子查询。
这个语句的一种可能的执行过程采用以下三个步骤。
①从外层查询中取出SC的一个元组x,将元组x的Sno值(201215121)传送给内层查询。
SELECT AVG(Grade)
FROM SC y
WHERE y.Sno='201215121';
②执行内层查询,得到值88(近似值),用该值代替内层查询,得到外层查询:
SELECT Sno.Cno
FROM SC x
WHERE Grade >=88;
③执行这个查询,得到
(201215121,1)
(201215121,3)
然后外层查询取出下一个元组重复做上述①至③步骤的处理,直到外层的SC元组全
部处理完毕。结果为
(201215121,1)
(201215121,3)
(201215122,2)
求解相关子查询不能像求解不相关子查询那样一次将子查询求解出来,然后求解父查询。内层查询由于与外层查询有关,因此必须反复求值。
③带有ANY(SOME)或ALL谓词的子查询
子查询返回单值时可以用比较运算符,但返回多值时要用ANY(有的系统用SOME)或ALL谓词修饰符。而使用ANY或ALL谓词时则必须同时使用比较运算符。其语义如下所示:

【例4】查询非计算机科学系中比计算机科学系任意一个学生年龄小的学生姓名和年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage<ANY
(SELECT Sage
FROM Student
WHERE Sdept=' CS')
AND Sdept<>'CS';
结果如下:
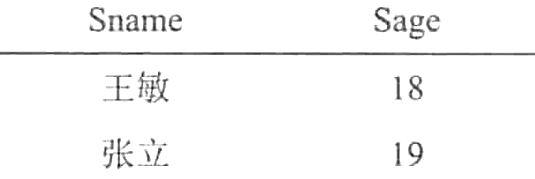
关系数据库管理系统执行此查询时,首先处理子查询,找出CS系中所有学生的年龄,构成一个集合(20,19);然后处理父查询,找所有不是CS系且年龄小于20或19的学生。
本查询也可以用聚集函数来实现,首先用子查询找出CS系中最大年龄(20),然后在父查询中查所有非CS系且年龄小于20岁的学生。SQL语句如下:
SELECT Sname,Sage
FROM Student
WHERE Sage
(SELECT MAX(Sage)
FROM Student
WHERE Sdept='CS')
AND Sdept<>'CS';
【例5】查询非计算机科学系中比计算机科学系所有学生年龄都小的学生姓名及年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < ALL
(SELECT Sage
FROM Student
WHERE Sdept='CS')
AND Sdept <>'CS';
关系数据库管理系统执行此查询时,首先处理子查询,找出CS系中所有学生的年龄,构成一个集合(20,19)。然后处理父查询,找所有不是CS系且年龄既小于 20,也小于19的学生。查询结果为

本查询同样也可以用聚集函数实现。SQL语句如下:
SELECT Sname,Sage
FROM Student
WHERE Sage <
(SELECT MIN(Sage)
FROM Student
WHERE Sdept='CS')
AND Sdept <>'CS';
事实上,用聚集函数实现子查询通常比直接用ANY或ALL查询效率要高。ANY、ALL与聚集函数的对应关系如下表所示。

表中,=ANY等价于IN谓词,<ANY等价于<MAX,ALL等价于NOT IN谓词,<ALL等价于<MIN,等等。
④带有EXISTS谓词的子查询
EXISTS代表存在量词∃。带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
可以利用EXISTS来判断x∈S、S⊆R、S=R、S∩R非空等是否成立。
【例6】查询所有选修了1号课程的学生姓名。
本查询涉及Student和SC表。可以在Student中依次取每个元组的Sno值,用此值去检查SC表。若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno='1',则取此Student.Sname送入结果表。将此想法写成SQL语句是
SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno
AND Cno='1');
使用存在量词EXISTS后,若内层查询结果非空,则外层的WHERE子句返回真值,否则返回假值。
由EXISTS引出的子查询,其目标列表达式通常都用*,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义。
本例中子查询的查询条件依赖于外层父查询的某个属性值(Student的Sno值),因此也是相关子查询。这个相关子查询的处理过程是:首先取外层查询中Student表的第一个元组,根据它与内层查询相关的属性值(Sno值)处理内层查询,若WHERE子句返回值为真,则取外层查询中该元组的Sname放入结果表;然后再取Student表的下一个元组;重复这一过程,直至外层Student表全部检查完为止。
本例中的查询也可以用连接运算来实现,读者可以参照有关的例子自己给出相应的SQL语句。
与EXISTS谓词相对应的是NOT EXISTS谓词。使用存在量词NOT EXISTS后,若内层查询结果为空,则外层的WHERE子句返回真值,否则返回假值。
【例7】查询没有选修1号课程的学生姓名。
SELECT Sname
FROM Student
WHERE NOT EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno
AND Cno='1');
一些带EXISTS或NOT EXISTS谓词的子查询不能被其他形式的子查询等价替换,但所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换。例如带有IN谓词的例1可以用如下带EXISTS谓词的子查询替换:
SELECT Sno,Sname,Sdept
FROM Student S1
WHERE EXISTS
(SELECT ·
FROM Student S2
WHERE S2.Sdept=S1.Sdept
AND S2.Sname='刘晨');
由于带EXISTS量词的相关子查询只关心内层查询是否有返回值,并不需要查具体值,因此其效率并不一定低于不相关子查询,有时是高效的方法。
【例8】查询选修了全部课程的学生姓名。
SQL中没有全称量词 (for all),但是可以把带有全称量词的谓词转换为等价的带有存在量词的谓词:
(∀x)P≡┐(∃x(┐P))
由于没有全称量词,可将题目的意思转换成等价的用存在量词的形式:查询这样的学生,没有一门课程是他不选修的。其SQL语句如下:
SELECT Sname
FROM Student
WHERE NOT EXISTS
(SELECT *
FROM Course
WHERE NOT EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno
AND Cno=Course.Cno));
从而用EXIST/NOT EXIST来实现带全称量词的查询。
【例9】查询至少选修了学生201215122选修的全部课程的学生号码。
本查询可以用逻辑蕴涵来表达:查询学号为x的学生,对所有的课程y,只要201215122学生选修了课程y,则×也选修了y。形式化表示如下:
用p表示谓词“学生201215122选修了课程y”
用q表示谓词“学生x选修了课程y”
则上述查询为
(∀y)p→q
SQL语言中没有蕴涵(implication)逻辑运算,但是可以利用谓词演算将一个逻辑蕴涵的谓词等价转换为
p→q≡┐pVq
该查询可以转换为如下等价形式:
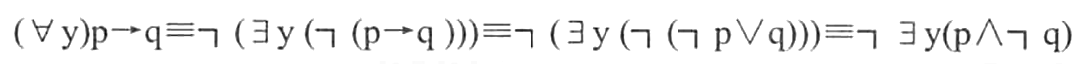
它所表达的语义为:不存在这样的课程y,学生201215122选修了y,而学生x没有选。用SQL语言表示如下:



