




作者介绍

李伟超,数据库系统架构师,YashanDB架设技术开发负责人,10年以上数据库内核技术开发经验。
*全文4510个字,阅读时长约11分钟。
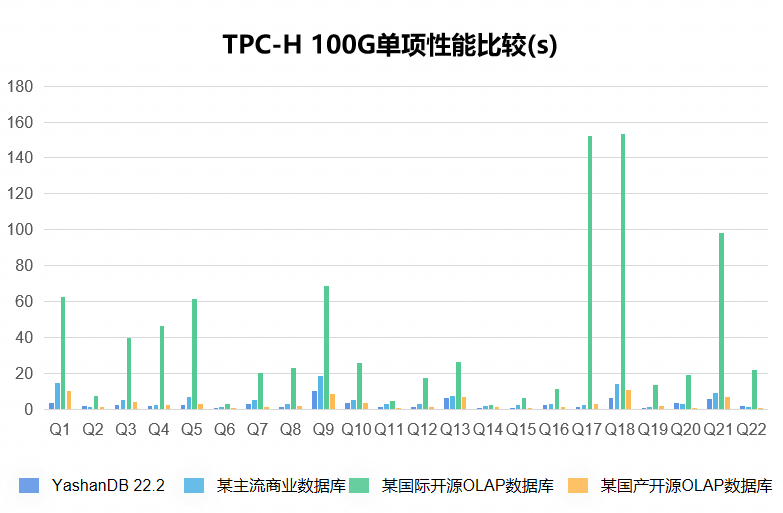
图1 TPC-H测试结果
硬件配置:2288虚拟机(16核,160G内存,3.4T SSD)
软件版本:OS(CentOS 7),DB(YashanDB 22.2、Oracle 19C Inmemory 、Greenplum 6.17.1)
测试模型:TPC-H 100G数据
为什么需要向量化计算?
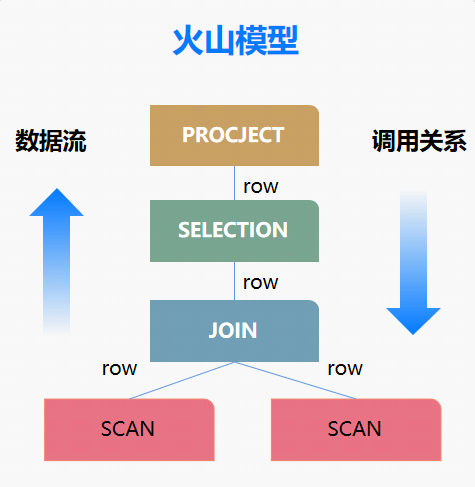
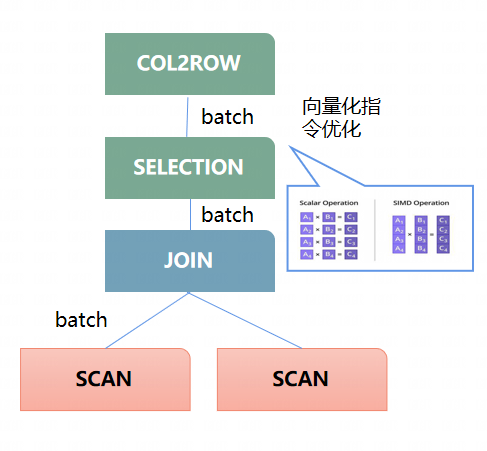
如何实现向量化执行引擎?
基于列存的组织结构:为了实现对数据的向量化计算,需要设计按列组织的内存结构,以充分利用CPU的缓存以及使用SIMD指令加速计算。
向量化的计算框架:在列存内存组织的基础上,提供一套基于列存的算子和表达式框架,以支持灵活可扩展的定义和实现各类算子和表达式。
针对查询计划执行的优化技术:通过优化器、向量化执行引擎和存储引擎的紧密配合,实现将查询条件下推到存储引擎以及针对HashJoin实现运行时过滤(Runtime Filter)。
内存管理:包括运行时的动态内存管理和针对物化算子的物化内存管理。
01
基于列存的组织结构
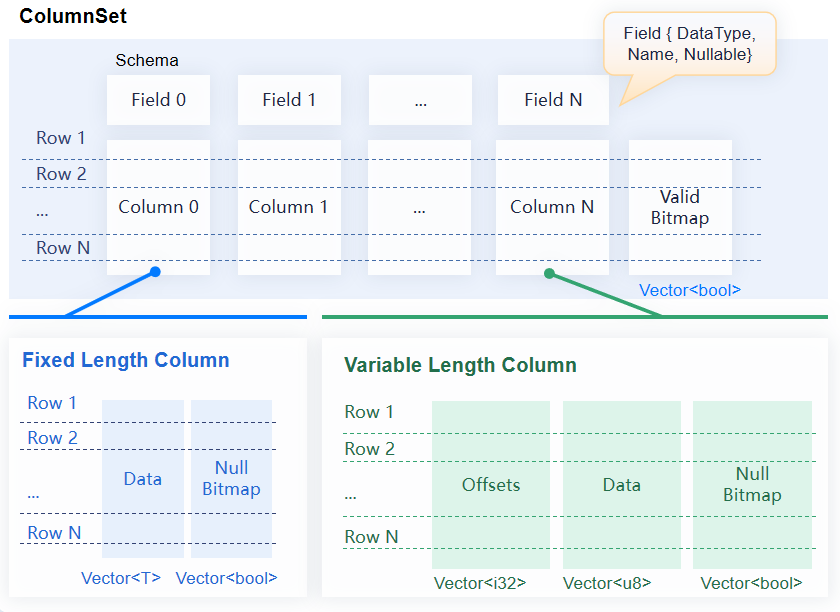
图4:YashanDB基于列存的组织结构
ColumnSet:我们将以列存的方式组织到一起的一批记录称为ColumnSet,它是一个二维的数据集,由许多相邻的向量组成,每个向量的记录数相同,不同向量之间按行逻辑对齐。与表类似,ColumnSet也有一个Schema,该模式必须匹配其向量的数据类型。ColumnSet是一个便于序列化和计算的工作单元,每个ColumnSet还有一个可选的位图用来表示ColumnSet中的行是否有效。
Schema:用来描述二维数据集的结构。它包含一系列Field和一些可选的模式范围的元数据。Field描述列的名称及其元数据。
Column:是一个与Field绑定在一起的分块向量,同时列还有一个可选的位图用来表示列中的值是否为空值。根据数据类型分为定长列(Fixed Length Column)和变长列(Variable Length Column)。定长列可以对数据直接按下标随机访问;而变长列需要先根据偏移向量计算出数据的起始位置和长度,然后访问数据。
Vector:表示已知长度并具有相同数据类型的标量值的序列。向量中的值由一块连续的内存存储,值的数量和意义由向量的数据类型决定。
02
计算框架
内存安全,高性能;
基于ColumnSet的批量计算,实现只读数据、无锁并发的向量化计算;
支持功能丰富的表达式计算和算子,完整支持TPC-H、TPC-DS语法;
高度灵活的可扩展性。
pub trait Operator {fn bind(&self, ctx: Arc<dyn Context>) -> Result<Box<dyn Cursor>>;}pub trait Cursor {fn next(&mut self) -> Result<Option<ColumnSet>>;}pub trait Expression {fn bind(&self, ctx: Arc<dyn Context>, schema: &Schema) -> Result<Box<dyn BoundExpression>>;}pub trait BoundExpression {fn evaluate(&mut self, column_set: &ColumnSet) -> Result<Arc<dyn Column>>;}
03
条件下推
支持多个字段的AND条件下推;
单个字段的多个条件,条件是OR的关系;
条件为等值查询和范围查询,比较值必须是常量。
Extent粒度的布隆过滤:支持等值条件;
块粒度的稀疏索引过滤:支持and,or,<,>,=,>=,<=,in等运算下的常量表达式;
支持编码数据的行级过滤;
向量化过滤计算。
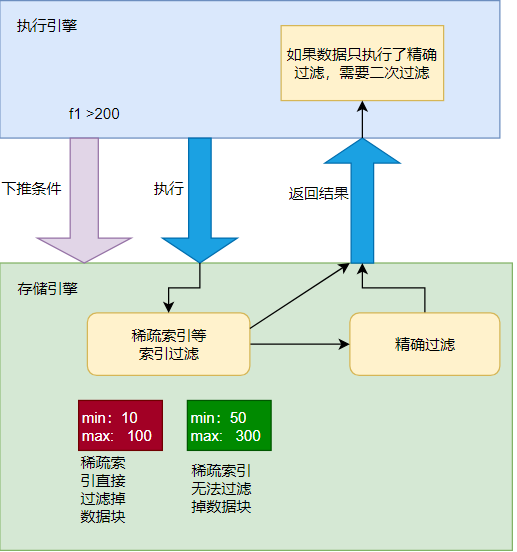
图5:YashanDB 条件下推示意
04
运行时过滤
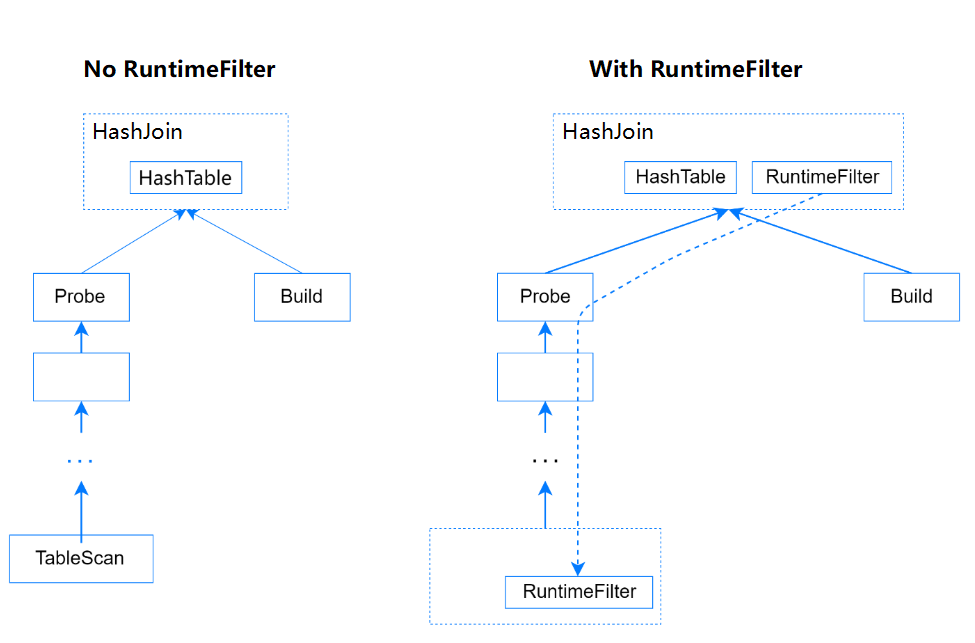
取出Build表所有数据;
根据Build表数据构建HashTable;
再取出Probe表所有数据,同时基于HashTable生成Join结果;
05
动态内存管理
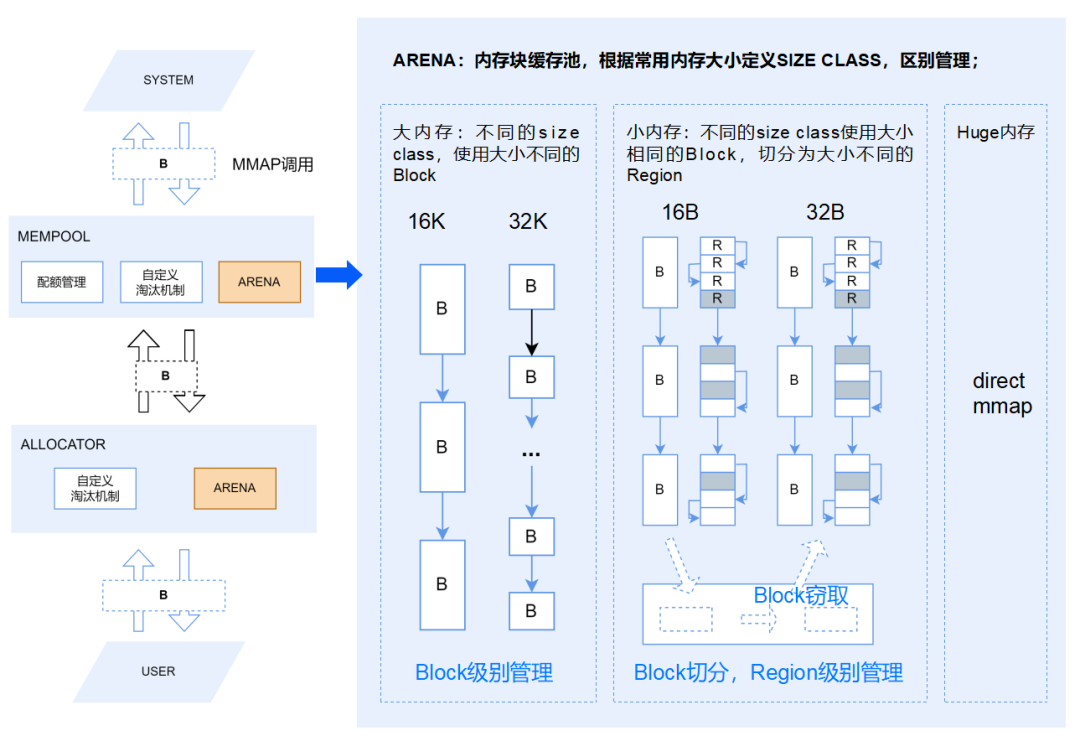
大内存:不同的SizeClass使用大小不同的Block,进行Block级别管理;
小内存:不同的SizeClass使用大小相同的Block,Block切分成大小不同的Region,进行Region级别的管理;由于不同SizeClass使用的Block大小是相同的,在某个SizeClass无空闲内存时,可以先从具有相同Block大小的SizeClass中窃取空闲内存块,都没有时,再向内存池申请;
HUGE内存:大于2M的内存块,不进行缓存处理,执行通过MMAP/MUNMAP向操作系统申请和释放。
06
物化内存管理
>>相关阅读<<




