




数据查询
数据查询是数据库的核心操作。SQL提供了SELECT语句进行数据查询,该语句具有灵活的使用方式和丰富的功能。其一般格式为

整个SELECT语句的含义是,根据WHERE子句的条件表达式从FROM子句指定的基本表、视图或派生表中找出满足条件的元组,再按SELECT子句中的目标列表达式选出元组中的属性值形成结果表。
如果有GROUP BY子句,则将结果按<列名1>的值进行分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。如果GROUP BY子句带HAVING短语,则只有满足指定条件的组才予以输出。
如果有ORDER BY子句,则结果表还要按<列名2>的值的升序或降序排序。
SELECT语句既可以完成简单的单表查询,也可以完成复杂的连接查询和嵌套查询。下面以学生-课程数据库为例说明SELECT语句的各种用法。
单表查询
单表查询是指仅涉及一个表的查询。
①选择表中的若干列
选择表中的全部或部分列即关系代数的投影运算。
(1)查询指定列
在很多情况下,用户只对表中的一部分属性列感兴趣,这时可以通过在SELECT子句的<目标列表达式>中指定要查询的属性列。
【例1】查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
该语句的执行过程可以是这样的:从Student表中取出一个元组,取出该元组在属性Sno和Sname上的值,形成一个新的元组作为输出。对 Student 表中的所有元组做相同的处理,最后形成一个结果关系作为输出。
【例2】查询全体学生的姓名、学号、所在系。
SELECT Sname,Sno,Sdept
FROM Student;
<目标列表达式>中各个列的先后顺序可以与表中的顺序不一致。用户可以根据应用的需要改变列的显示顺序。本例中先列出姓名,再列出学号和所在系。
(2)查询全部列
将表中的所有属性列都选出来有两种方法,一种方法就是在SELECT关键字后列出所有列名;如果列的显示顺序与其在基表中的顺序相同,也可以简单地将<目标列表达式>指定为*。
【例3】查询全体学生的详细记录。

(3)查询经过计算的值
SELECT子句的<目标列表达式>不仅可以是表中的属性列,也可以是表达式。
【例4】查询全体学生的姓名及其出生年份。
SELECT Sname,2014-Sage
FROM Student;
查询结果中第2列不是列名而是一个计算表达式,是用当时的年份(假设为2014年)减去学生的年龄。这样所得的即是学生的出生年份。输出的结果为

<目标列表达式>不仅可以是算术表达式,还可以是字符串常量、函数等。
【例5】查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表示系名。

用户可以通过指定别名来改变查询结果的列标题,这对于含算术表达式、常量、函数名的目标列表达式尤为有用。例如对于例5可以定义如下列别名:

②选择表中的若干元组
(1)消除取值重复的行
两个本来并不完全相同的元组在投影到指定的某些列上后,可能会变成相同的行。可以用DISTINCT消除它们。
【例6】查询选修了课程的学生学号。
SELECT Sno
FROM SC;
执行上面的SELECT语句后,结果为
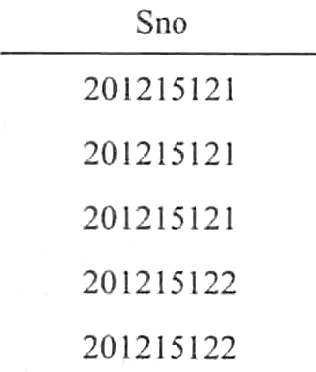
该查询结果里包含了许多重复的行。如想去掉结果表中的重复行,必须指定DISTINCT:
SELECT DISTINCT Sno
FROM SC;
则执行结果为
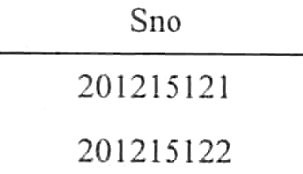
如果没有指定DISTINCT关键词,则默认为ALL,即保留结果表中取值重复的行。
SELECT Sno
FROM SC;
等价于
SELECT ALL Sno
FROM SC;
(2)查询满足条件的元组
查询满足指定条件的元组可以通过WHERE子句实现。WHERE子句常用的查询条件如下表所示。

①比较大小
用于进行比较的运算符一般包括=(等于),>(大于),<(小于),>=(大于等于),<=(小于等于),!=或<>(不等于),!>(不大于),!<(不小于)。
【例7】查询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept='CS';
关系数据库管理系统执行该查询的一种可能过程是:对Student表进行全表扫描,取出一个元组,检查该元组在Sdept列的值是否等于CS',如果相等,则取出Sname列的值形成一个新的元组输出;否则跳过该元组,取下一个元组。重复该过程,直到处理完Student表的所有元组。
如果全校有数万个学生,计算机系的学生人数是全校学生的5%左右,可以在Student表的Sdept列上建立索引,系统会利用该索引找出Sdept=CS'的元组,从中取出Sname列值形成结果关系。这就避免了对Student表的全表扫描,加快了查询速度。注意如果学生较少,索引查找不一定能提高查询效率,系统仍会使用全表扫描。这由查询优化器按照某些规则或估计执行代价来作出选择。
【例8】查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage<20;
【例9】查询考试成绩不及格的学生的学号。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
这里使用了DISTINCT短语,当一个学生有多门课程不及格,他的学号也只列一次。
②确定范围
谓词BETWEEN...AND...和NOT BETWEEN...AND...可以用来查找属性值在(或不在)指定范围内的元组,其中BETWEEN后是范围的下限(即低值),AND后是范围的上限(即高值)。
【例10】查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
【例11】查询年龄不在20~23岁之间的学生姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
③确定集合
谓词IN可以用来查找属性值属于指定集合的元组。
【例12】查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN('CS','MA,'IS');
与IN相对的谓词是NOT IN,用于查找属性值不属于指定集合的元组。
【例13】查询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept NOT IN('CS',MA'IS');
④字符匹配
谓词LIKE可以用来进行字符串的匹配。其一般语法格式如下:
[NOT] LIKE'匹配串>’ [ESCAPE'<换码字符>]
其含义是查找指定的属性列值与<匹配串>相匹配的元组。<匹配串>可以是一个完整的字符
串,也可以含有通配符%和_。其中:
%(百分号)代表任意长度(长度可以为0)的字符串。例如a%b表示以a开头,以b结尾的任意长度的字符串。如acb、addgb、ab等都满足该匹配串。
_(下横线)代表任意单个字符。例如ab表示以a开头,以b结尾的长度为3的任意字符串。如acb、afb等都满足该匹配串。
【例14】查询学号为201215121的学生的详细情况。
SELECT*
FROM Student
WHERE Sno LIKE '201215121';
等价于
SELECT*
FROM Student
WHERE Sno="201215121;
如果LIKE后面的匹配串中不含通配符,则可以用=(等于)运算符取代LIKE谓词,用!=或<>(不等于)运算符取代NOT LIKE谓词。
【例15】查询所有姓刘的学生的姓名、学号和性别。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE‘刘%';
【例16】查询姓“欧阳”且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_';
注意:数据库字符集为ASCII时一个汉字需要两个_;当字符集为GBK时只需要一个_。
【例17】查询名字中第二个字为“阳”的学生的姓名和学号。
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE'_阳%';
【例18】查询所有不姓刘的学生的姓名、学号和性别。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE'刘%';
如果用户要查询的字符串本身就含有通配符%或_,这时就要使用ESCAPE '<换码字符>'短语对通配符进行转义了。
【例19】查询DB_Design课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE ‘DB\_Design' ESCAPE'\';
ESCAPE'\’表示“\”为换码字符。这样匹配串中紧跟在“\”后面的字符“_”不再具有通配符的含义,转义为普通的“_”字符。
【例20】查询以“DB_”开头,且倒数第三个字符为i的课程的详细情况。
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__' ESCAPE'\';
这里的匹配串为“DB\_%i__”。第一个_前面有换码字符\,所以它被转义为普通的字符。而i后面的两个_ 的前面均没有换码字符\,所以它们仍作为通配符。
⑤涉及空值的查询
【例21】某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;
注意这里的“IS”不能用等号(=)代替。
【例22】查所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
⑥多重条件查询
逻辑运算符AND和OR可用来连接多个查询条件。AND的优先级高于OR,但用户可以用括号改变优先级。
【例23】查询计算机科学系年龄在20岁以下的学生姓名。
SELECT Sname
FROM Student
WHERE Sdept='CS' AND Sage<20;
在例12中的IN谓词实际上是多个OR运算符的缩写,因此该例中的查询也可以用OR运算符写成如下等价形式:
SELECT Sname,Ssex
FROM Student
WHERE Sdept='CS' OR Sdept='MA' OR Sdept='IS';
③ORDER BY子句
用户可以用ORDER BY子句对查询结果按照一个或多个属性列的升序(ASC)或降序(DESC)排列,默认值为升序。
【例24】查询选修了3号课程的学生的学号及其成绩,查询结果按分数的降序排列。
SELECT Sno,Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC;
对于空值,排序时显示的次序由具体系统实现来决定。例如按升序排,含空值的元组最后显示:按降序排,空值的元组则最先显示。各个系统的实现可以不同,只要保持一致就行。
【例25】查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT*
FROM Student
ORDER BY Sdept,Sage DESC;
④聚集函数
为了进一步方便用户,增强检索功能,SQL提供了许多聚集函数,主要有:

如果指定DISTINCT短语,则表示在计算时要取消指定列中的重复值。如果不指定DISTINCT短语或指定ALL短语(ALL为默认值),则表示不取消重复值。
【例26】查询学生总人数。
SELECT COUNT(*)
FROM Student;
【例27】查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno)
FROM SC;
学生每选修一门课,在SC中都有一条相应的记录。一个学生要选修多门课程,为避免重复计算学生人数,必须在COUNT函数中用DISTINCT短语。
【例28】计算选修1号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno='1';
【例29】查询选修1号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHERE Cno="1';
【例30】查询学生201215012选修课程的总学分数。
SELECT SUM(Ccredit)
FROM SC,Course
WHERE Sno='201215012' AND SC.Cno=Course.Cno;
当聚集函数遇到空值时,除COUNT(*)外,都跳过空值而只处理非空值。COUNT(*)是对元组进行计数,某个元组的一个或部分列取空值不影响COUNT的统计结果。
注意,WHERE子句中是不能用聚集函数作为条件表达式的。聚集函数只能用于SELECT子句和GROUP BY中的HAVING子句.
⑤GROUP BY子句
GROUP BY子句将查询结果按某一列或多列的值分组,值相等的为一组。
对查询结果分组的目的是为了细化聚集函数的作用对象。如果未对查询结果分组,聚集函数将作用于整个查询结果,如前面的例26~30。分组后聚集函数将作用于每一个组,即每一组都有一个函数值。
【例31】求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
该语句对查询结果按Cno的值分组,所有具有相同Cno值的元组为一组,然后对每一组作用聚集函数COUNT进行计算,以求得该组的学生人数。
查询结果可能为

如果分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用HAVING短语指定筛选条件。
【例32】查询选修了三门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*)>3;
这里先用GROUP BY子句按Sno进行分组,再用聚集函数COUNT对每一组计数;HAVING短语给出了选择组的条件,只有满足条件(即元组个数>3,表示此学生选修的课超过3门)的组才会被选出来。
WHERE子句与HAVING短语的区别在于作用对象不同。WHERE子句作用于基本表或视图,从中选择满足条件的元组。HAVING短语作用于组,从中选择满足条件的组。
【例33】查询平均成绩大于等于90分的学生学号和平均成绩。
下面的语句是不对的:
SELECT Sno,AVG(Grade)
FROM SC
WHERE AVG(Grade)>=90
GROUP BY Sno;
因为WHERE子句中是不能用聚集函数作为条件表达式的,正确的查询语句应该是:
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90;


