




流式数据库是基于PostgreSQL开发而来,SQL语法方面在满足PostgreSQL已有全部语法的同时扩展了流处理相关的语法。流式数据库既具有数据库的功能又具有流处理功能,关于数据库功能部分参考PostgreSQL官方操作手册,本手册只关注基于PostgreSQL新增的流处理功能相关的SQL语法,主要包括流对象DDL、流数据增删改查、流式窗口聚集、流式join。
连接流式数据库
psql连接流式数据库的参数和连接PostgreSQL的参数一样,后面要带上-P pager=off。
psql -h localhost -d postgres -P pager=off
-h localhost -d postgres表示登录本地postgres数据库,根据实际情况改变参数。-P pager=off表示关闭翻页显示,如果是流式查询必须加上。

create database mydb; 创建mydb数据库。

\c mydb 切换到mydb数据库。

CREATE STREAM
创建流对象,可以作为流数据的入口点。
CREATE STREAM stream_name ( [
{ column_name data_types [ column_constraint [ ... ] }
[, ...
]] )
where column_constraint is:
{ NOT NULL |
NULL |
CHECK ( expression ) [ NO INHERIT ] |
DEFAULT default_expr
例:
- 创建没有入库时间的流对象
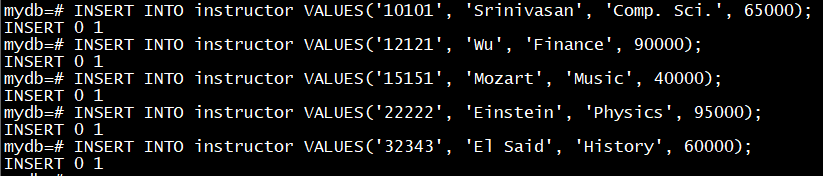
mydb=# CREATE STREAM instructor (ID text, name text, dept_name text, salary float);
CREATE STREAM
- 创建带入库时间的流对象
mydb=# CREATE STREAM instructor1 (intime char not null default hlcnextval(), ID text, name text, dept_name text, salary float);
CREATE STREAM
创建流对象instructor ,指定intime字段是入库时间字段, default hlcnextval()表示默认取系统当前的hlc时间戳为值。
- 查看结果
\dt查看当前数据库有多少个表和流对象
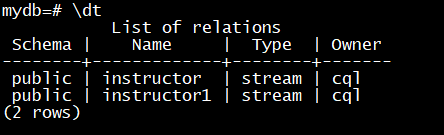
\d stream_name查看流对象的结构
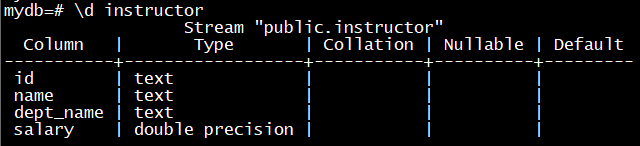
CREATE STREAM AS
CREATE STREAM stream_name [ (column_name [, ...] ) ] AS query
其中STREAM关键字表示创建流对象。
column_name表示从查询结果中取指定字段创建新的流对象或流式物化视图对象,如果不提供column_name表示从查询结果中取所有字段。
query流式查询语句,可以是SELECT、NORMAL AGGREGATION、WINDOW AGGREGATION、JOIN,参见后面几节。
例:从流对象instructor过滤年薪80000美元的流数据物化成super_instructor

\dt查看当前数据库有多少个表和流对象
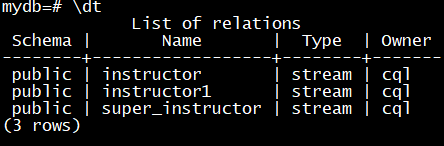
\d stream_name查看流对象的结构
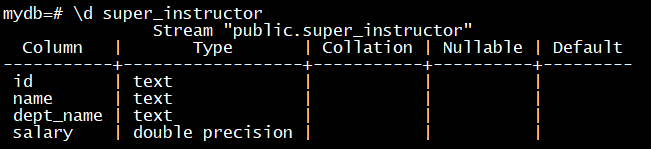
DROP STREAM
删除已存在的流对象
DROP STREAM super_instructor;

删除super_instructor流对象
INSERT
往流对象中插入流数据
INSERT INTO stream_name [ AS alias ] [ ( column_name [, ...] ) ]
{ VALUES ( expression [, ...] ) | query }
其中query流式查询语句,可以是SELECT、NORMAL AGGREGATION、WINDOW AGGREGATION、JOIN。
SELECT
流对象的查询操作包括:传统的PULL模式查询,流式处理新增的PUSH模式查询。
流对象的PULL模式查询就是流对象当做表对象处理,查询语法和表的查询一样。
流对象的PUSH模式查询,流的查询长期运行着,一有增量数据立即执行后续的查询操作。
SELECT [ * | expression [ [ AS ] output_name ] [, ...] ]
FROM stream_name [ [ AS ] alias ]
[ WHERE condition ] [ EMIT CHANGES ]
例:
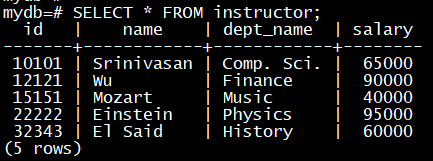
流对象instructor 的PULL查询:
SELECT * FROM instructor;
流对象instructor的PUSH查询:
SELECT * FROM instructor WHERE salary >= 80000 EMIT CHANGES;

这时如果其它进程往instructor插数据,PUSH查询就会实时显示增量处理结果。
UPDATE
修改流对象里的流数据
UPDATE stream_name [ * ] [ [ AS ] alias ]
SET { column_name = expression } [ WHERE condition ]
例:
用带pg_state(xmax)的PUSH查询显示流数据状态:


这时PUSH查询显示两条增量数据,一条pg_state状态为'-'的老数据,表示删除老数据;一条pg_state状态为'+'的新数据,表示新增数据。

DELETE
DELETE FROM table_name [ [ AS ] alias ]
[ WHERE condition ]
例:
用带pg_state(xmax)的PUSH查询显示流数据状态:


这时PUSH查询显示一条pg_state状态为'-'的老数据,表示删除老数据。

NORMAL AGGREGATION
常规聚集就是全局窗口聚集,和普通窗口聚集表现形式不一样,所以单独做一节进行说明。常规聚集因为窗口无限大,所以聚集结果不需显示窗口开始时间和结束时间。
SELECT expression [ [ AS ] output_name ] [, ...] FROM table_name [ WHERE condition ] GROUP BY grouping_element [ HAVING condition ] EMIT CHANGES]
where grouping_element can be one of:
( )
expression
( expression [, ...] )
例:实时统计各个科系教师的人数和薪资总额

例:把各个各个科系教师的人数和薪资总额实时统计结果物化成dept_cost流对象

WINDOW AGGREGATION
前面术语部分介绍过窗口操作,可以将一个无限的数据流拆分成很多个有限大小的“桶”,然后在这些桶上执行计算。根据窗口定义可以分为:滚动窗口、滑动窗口、会话窗口、全局窗口。其中全局窗口上一小节已经介绍过,会话窗口暂不支持;这里重点介绍滚动窗口和滑动窗口的流式聚集,语法如下:
SELECT expression [ [ AS ] output_name ] [, ...]
[, getWindowBegin() [[ AS ] output_name]
[, getWindowEnd() [[AS] output_name]] ]
FROM stream_name
[ WHERE condition ]
GROUP BY grouping_element
[[ { TUMBLE ( event_time_field, <window_size> ) |
HOP ( event_time_field, <window_size>, <slide_size> ) }
[ { WATERMARK | DELAY } <watermark_size> ][ALLOWEDLATENESS <allowedlateness_size>] EMIT CHANGES] | [EMIT CHANGES]
<window_size> <slide> <watermark_size> are interval 'quantity unit'
其中窗口的大小、步长、水位线都是以INTERVAL ‘quantity unit’ 间隔时长表示,单位支持如下简称或全称:
简称 | 全称 |
|---|---|
H | Hours |
M | Minutes |
S | Seconds |
MS | Milliseconds |
滚动窗口示例:每隔10秒钟实时统计各个科系新增教师的人数、薪资总额和平均薪资,延后5秒输出结果。
#创建带事件时间的流对象instructor2:


#模拟流数据接入,一秒一条往instructor2插数据,看窗口聚集的输出结果。
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('33456', 'Gold', 'Physics', 87000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('45565', 'Katz', 'Comp. Sci.', 75000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('22222', 'Einstein', 'Physics', 95000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('58583', 'Califieri', 'History', 62000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('32343', 'El Said', 'History', 60000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('76543', 'Singh', 'Finance', 80000);
INSERT INTO instructor2(ID, name, dept_name, salary) VALUES('76766', 'Crick', 'Biology', 72000);

滚动窗口聚集的结果也可以物化成其它流对象,参见前面第3.3小节。
例:把各个各个科系教师的人数、薪资总额和平均薪资的滚动窗口统计结果实时物化成dept_cost2流对象。
CREATE STREAM dept_cost2 AS SELECT count(ID), sum(salary), avg(salary), dept_name, window_begin(*), window_end(*) FROM instructor2 GROUP BY dept_name TUMBLE(evt_time, INTERVAL '10 s') WATERMARK INTERVAL '5s' EMIT CHANGES;

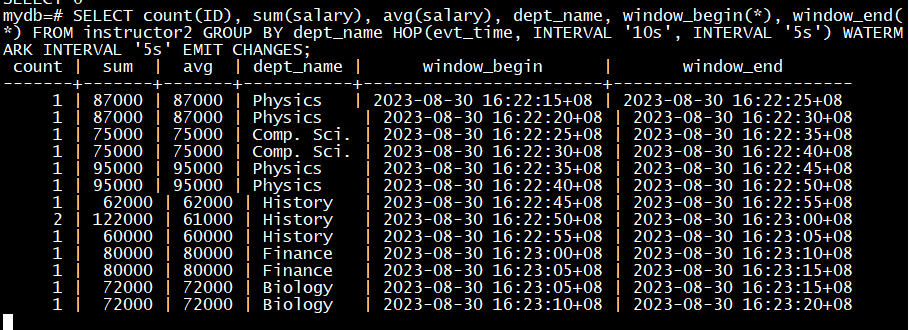
滑动窗口示例:指定滑动窗口大小为10秒(第一个间隔类型参数),滑动步长为5秒(第二个间隔类型参数),按科系统计每个窗口周期内新增教师的人数、薪资总额和平均薪资,延后5秒输出结果。
SELECT count(ID), sum(salary), avg(salary), dept_name, window_begin(*), window_end(*) FROM instructor2 GROUP BY dept_name HOP(evt_time, INTERVAL '10s', INTERVAL '5s') WATERMARK INTERVAL '5s' EMIT CHANGES;
#模拟流数据接入,一秒一条往instructor2插数据,看窗口聚集的输出结果。会出现窗口没5s移动一次,同一条记录即会统计入前一个大小为10s的窗口又会统计入后一个大小为10s的窗口中,原因是窗口大小10s滑动步长5s,所以有2个窗口前后相互重叠。试想如果窗口大小10s滑动步长2s,则有5个窗口前后相互重叠。
滑动窗口聚集的结果也可以物化成其它流对象,参见前面第3.3小节。
例:把前面例子中滑动窗口的统计结果实时物化成dept_cost3流对象。

流式JOIN
流式数据库的JOIN包括流表join、流流join。其中流流join是指两个流对象的join,使用方式和流表join一样,这里举流表join作为例子。
SELECT [ * | expression [ [ AS ] output_name ] [, ...] ]
FROM {stream_name | table_name} [ [ AS ] alias ]
JOIN {stream_name | table_name} [ [ AS ] alias ]
[ ON join_condition | USING ( join_column [, ...] ) ]
[ WHERE condition ] [ EMIT CHANGES ]
例:实时查询新增的教师所属的科系以及所在办公楼信息。
# 创建科系表:
CREATE TABLE department(ID text, dept_name text, building text, budget float);

INSERT INTO department VALUES('01', 'Biology', 'Watson', 90000), ('02', 'Comp. Sci.', 'Taylor', 100000), ('03', 'Elec. Eng.', 'Taylor', 85000), ('04', 'Finance', 'Painter', 120000), ('05', 'History', 'Painter', 50000),
('06', 'Music', 'Packard', 80000), ('07', 'Physics', 'Watson', 70000);

# 创建教师信息流对象instructor3:
CREATE STREAM instructor3 (ID text, name text, dept_name text, salary float);
# 教师信息流对象instructor3和科系表department做流表join:

SELECT instructor3.ID, name,salary, department.dept_name, building FROM instructor3 JOIN department ON instructor3.dept_name = department.dept_name EMIT CHANGES;

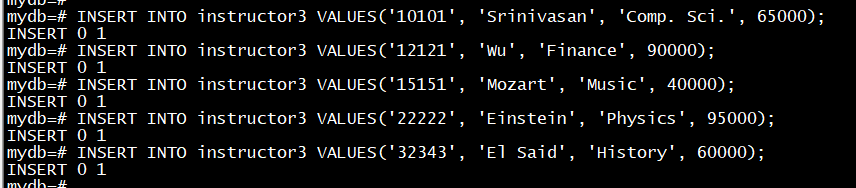
# 往教师信息流对象instructor3中插数据,看流表join的结果显示:
INSERT INTO instructor3 VALUES('10101', 'Srinivasan', 'Comp. Sci.', 65000);
INSERT INTO instructor3 VALUES('12121', 'Wu', 'Finance', 90000);
INSERT INTO instructor3 VALUES('15151', 'Mozart', 'Music', 40000);
INSERT INTO instructor3 VALUES('22222', 'Einstein', 'Physics', 95000);
INSERT INTO instructor3 VALUES('32343', 'El Said', 'History', 60000);
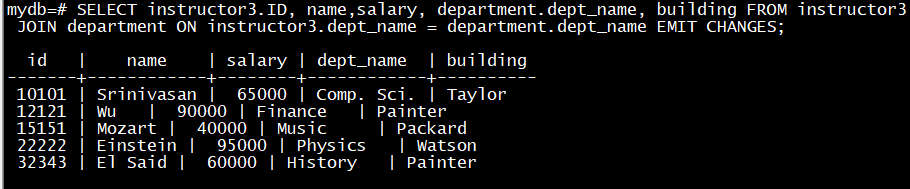
流表join、流流join的结果也可以物化成其它流对象或流式物化视图对象,参见前面第3.3小节。
如:实时查询新增的教师所属的科系以及所在办公楼信息,结果实时物化成instructor_dept流对象。
CREATE STREAM instructor3_dept AS SELECT instructor3.ID, name,salary, department.dept_name, building FROM instructor3 JOIN department ON instructor3.dept_name = department.dept_name EMIT CHANGES;

关于AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
