




关键字:人大金仓、KFS、数据过滤器
1. 开源 OR 闭源?
在瞬息多变的软件市场上,开源软件和闭源软件总是一个恒久不变的话题。开源软件得益于基础架构和基本功能的全面开放,诸多开发者能自由的使用和开发开源软件,但是这种使用的前提便是需要投入大量的成本对软件进行摸底,后续的维护也需要投入一定的精力。 反之,闭源软件依靠于开发厂商,在软件的稳定上优于开源软件,也正是因为闭源的原因,当一个软件出现错误时,客户需要联系厂商进行问题的定位和修复,对效率就会产生验证的负面影响,严重时甚至会阻塞一定的项目流程。
KFS基于此提供了一种半开半闭的软件使用形态。KFS对外不开放自己的基础架构和基础功能,但是在这个基础上,对一些核心功能的扩展提供了开放接口的形式,客户或者开发者可利用这些接口进行二次开发以适配自己的项目或者一些特殊场景,极大的提高了KFS软件的易用性和可维护性。
2. KFS开放能力-数据过滤器
KFS运行架构
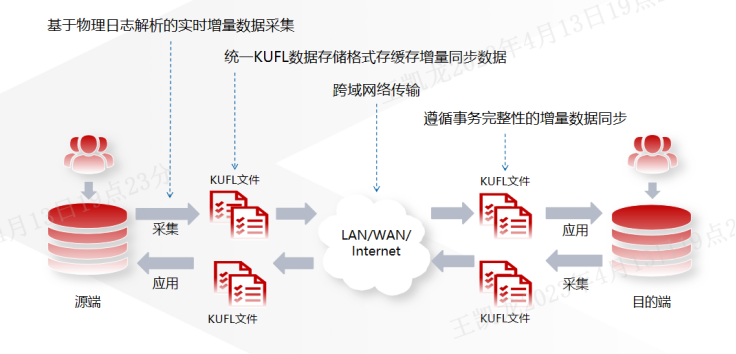
KFS的主要角色分为源端和目标端,其中源端连接源数据库,通过实时采集数据库的日志信息并解析处理,统一成以KUFL数据存储格式的物理文件。目标端通过网络连接到源端,不断获取由源端产生的KUFL文件,解析以后由目标端连接目标数据库,以遵循事务完整性的原则将数据写入到目标数据库中。而过滤器可配置在采集阶段或者应用阶段,以适用与不同的数据过滤场景。
数据过滤器
KFS的过滤器主要用于对同步数据的操作,可以对数据进行计算、校验后是否需要进行同步或者过滤。其中KFS支持两种过滤器的扩展方式,第一种为原生Java,第二种为JavaScript脚本。本文介绍基于JavaScript脚本的扩展方式。
KFS目前支持的过滤器包括:
1、replaceStatementFilter,DDL语句转换过滤器
2、dropcolumnFilter,列不同步过滤器
3、dataMarkFilter,数据标记过滤器
4、还有诸如dropStatementData(DDL过滤器),replicate(表过滤器),skipeventbyvalue(值过滤器)等使用与不同需求环境的过滤器。
过滤器的出现,可以大大拓宽KFS的使用场景,比如:
1、使用replaceStatementFilter来进行异构数据库之间DDL语句涉及语法内容的转换。
2、使用dropcolumnFilter来进行某个表指定列不同步。主要用于过滤数据汇集时一些没有业务需求的列。
3、使用dataMarkFilter来进行增删改数据的操作标记和操作时间标记。主要用于一些需要对数据变更进行操作记录的场景。
KFS过滤器具体接口及功能如下:
名称 | 含义 |
prepare | 启动时调用一次,主要用于过滤器配置参数的初始化。如预设的一些条件,文件资源等,通过在prepare阶段预处理后用于后续程序的使用。 |
translate | 每个事务调用一次,主要用于实现主要的过滤逻辑。 |
release | 停止时调用一次,主要用于释放在使用过滤器阶段时所开启的一些资源,以保证资源使用后的完整性和安全性。 |
3. 手把手教你做一个KFS数据过滤器
3.1. 使用场景
在进行数据汇集的过程中,诸多源端服务所传输的大量数据中,有大部分的数据是冗杂的,无用的,但是冗杂的数据有一定的规律(例如:冗杂数据是以0000开头)。如果这些数据也一起同步到了目标端,在目标端数据入库时会挤占正常数据入库所需要的资源,基于这种情况,设计一个过滤器插件用来对相关数据进行过滤就显得很有必要。
3.2. 插件设计和示例
3.2.1. 给插件命名
uselessDataFilter
3.2.2. 设计和开发
入参:
replicator.filter.uselessdata.rule |
该参数的设计是基于使用场景中所设计的需求:需要过滤具有一定规律的冗杂数据。
代码逻辑:
1. 准备
prepare rule=filterProperties.getString(“rule”); |
此处主要是获取参数的值,该值由用户在配置文件中所定义。
2. 匹配 translate
if(columnValue.startwith(rule)); columnValues.remove(columnValue); |
此处的实现主要是基于使用场景中的描述:冗杂数据以0000开头,因此对于相关数据的匹配就调用startwith()方法,进行开头数据的匹配。当匹配成功时,就需要将匹配的冗杂数据从过滤的数据集中删去。
3. 清理 release
该过滤器不涉及系统资源的调用,因此不需要释放相关的资源。
上述逻辑具体需要实现在名为uselessdata.js的文件中,具体实现如下:
function prepare() { rule=filterProperties.getString("rule"); //获取配置文件中所设定的参数值 } function filter(event) { data=event.getData(); //获取一个事务中含有的总数据集合 for(int i=0;i<data.size();i++) { d=data.get(i); if(d!=null&&d instanceof com.kingbase.flysync.replicator.dbms.RowChangeData) //判断数据类型是否为DML,RownchangeData即为KFS中对DML类型定义的数据结构 { rowData=d.getRowchange(); //获取数据的变化集合 for(j=0;j<rowData.size();j++) { orc=rowChanges.get(j); //获取一行数据的信息集合 columnVals=orc.getColumnValues(); //获取一行数据集合中的数值 for(c=0;c<columnVals.size();c++) { value=columnVals.get(c); if(value.startWith(rule)) //判断数据开头是否为所定义的参数值 { columnVals.remove(c); } } } } } } |
3.2.3. 导入KFS
1. Js文件导入
将编写好的过滤器uselessdata.js文件,移动到下述目录中:
flysync-replicator/support/filters-javascript |
2. 配置文件编写
在安装目录的flysync-replicator/samples/conf/filters/default中新建一个 以新增过滤器名称小写的以.tpl为后缀的文件,其中内容主要为:
replicator.filter.uselessdata=com.kingbase.flysync.replicator.filter.JavaScriptFilter replicator.filter.uselessdata.script=${replicator.home.dir}/support/filters-javascrupt/useless.js replicator.filter.uselessdata.rule= |
在目标端flysync.ini文件中添加如下参数:
svc-remote-filters=useless property=replicator.filter.uselessdata.rule=0000; |
3. 重新安装部署
进入安装目录中tool下,执行./fspm install
4. 效果展示
4.1. 测试模型
硬件环境
内存大小:8G
硬盘大小:180G
操作系统:CentOs7-x86_64
表结构展示
create table mytest1(c1 varcha(50),c2 varcha(50),c3 varcha(50));
create table mytest2(c1 varcha(50),c2 varcha(50),c3 varcha(50));
create table mytest3(c1 varcha(50),c2 varcha(50),c3 varcha(50));
create table mytest4(c1 varcha(50),c2 varcha(50),c3 varcha(50));
create table mytest5(c1 varcha(50),c2 varcha(50),c3 varcha(50));
每张表各插入一万条数据。
业务模型:
五张业务表中,每张表有三列数据,其中冗杂数据随机出现在不同表的不同列中,且冗杂数据所占比例为50%。单表数据量为1万条。
4.2. 使用过滤器前、后所需入库数据量及入库耗时对比
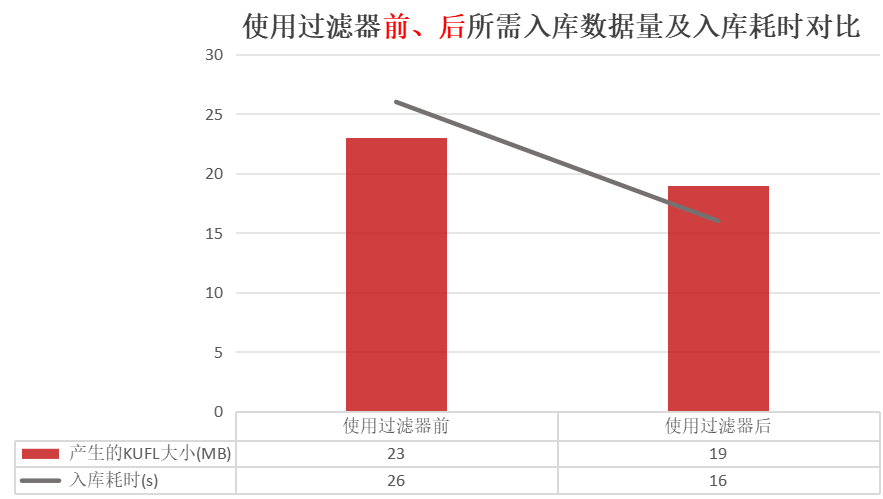
4.3. 说明
在此基础上可以增加更多的判断规则及有关的判断功能选择。此处根据场景将过滤的匹配功能固定为判断开头的数据是否等于自定义的数据,如果等于就进行过滤。除此而外,还可以添加是否包含数据,是否以数据的末尾进行判断,是否等于某些数据等功能,不同功能可以添加额外添加功能选择参数(例如:replicator.filter.uselessdata.type)去控制在匹配数据是所生效的匹配功能。
