排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
通透地讲解Spark与Flink对比
通透地讲解Spark与Flink对比
BAT大数据架构
2021-09-30
1350
-
Spark缺点
-
无论是
Spark Streaming
还是
Structured Streaming
,
Spark
流处理的实时性还不够,所以无法用在一些对实时性要求很高的流处理场景中。
这是因为
Spark
的流处理是基于所谓微批处理
( Micro- batch processing)
的思想,即它把流
处理看作是批处理的一种特殊形式,每次接收到一个时间间隔的数据才会去处理,所以天生很难在实时性上有所提升。
虽然在
Spark2.3
中提出了连续处理模型
( Continuous Processing Model)
,但是现在只支持
很有限的功能,并不能在大的项目中使用。
Spark
还需要做出很大的努力才能改进现有的流处理模型想要在流处理的实时性上提升,就不能継续用微批处理的模式,而要想办法实现真正的流处理即每当有一条数据输入就立刻处理,不做等待。
Flink采用了基于操作符(
Operator
)的连续流模型,可以做到微秒级别的延迟。
-
Flink核心模型简介
-
Flink
最核心的数据结构是
Stream
,它代表一个运行在多分区上的并行流。
在
Stream
上同样可以进行各种转换操作(
Transformation
。与
Spark
的
RDD
不同的是,
Stream
代表一个数据流而不是静态数据的集合。所以,它包含的数据是随着时间增长而变化的。而且
Stream
上的转换操作都是逐条进行的,即每当有新的数据进来,整个流程都会被执行并更新结果。这样的基本处理模式决定了
Flink
会比
Spark Streaming
有更低的流处理延迟性。
当一个
Flink
程序被执行的时候,它会被映射为
Streaming Dataflow
,下图就是一个
Streaming Dataflow
的示意图。
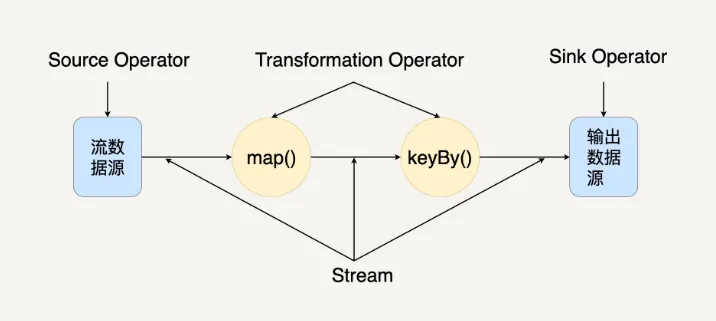
在图中,你可以看出
Streaming Dataflow
包括
Stream
和
Operator
(操作符)。转换操作符把一个或多个
Stream
转换成多个
Stream
。每个
Dataflow
都有一个输入数据源(
Source
)和输出数据源(
Sink
)。与
Spark
的
RDD
转换图类似,
Streaming Dataflow
也会被组合成一个有向无环图去执行。
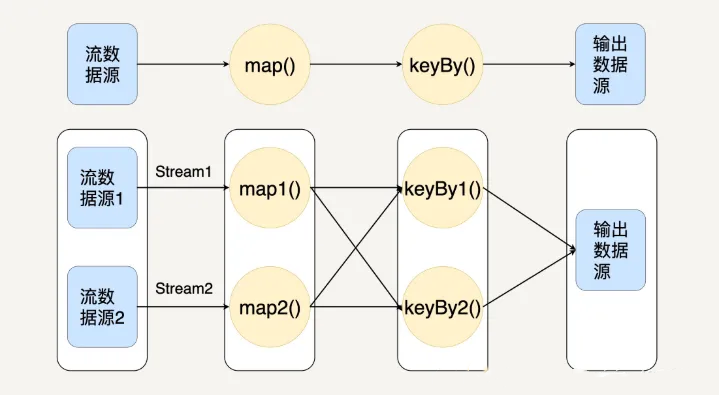
在
Flink
中,程序天生是并行和分布式的。一个
Stream
可以包含多个分区(
Stream Partitions
),一个操作符可以被分成多个操作符子任务,每一个子任务是在不同的线程或者不同的机器节点中独立执行的。如下图所示:
从上图你可以看出,
Stream
在操作符之间传输数据的形式有两种:一对一和重新分布。
一对一(
One-to-one
):
Stream
维护着分区以及元素的顺序,比如上图从输入数据源到
map
间。这意味着
map
操作符的子任务处理的数据和输入数据源的子任务生产的元素的数据相同。你有没有发现,它与
RDD
的窄依赖类似。
重新分布(
Redistributing
):
Stream
中数据的分区会发生改变,比如上图中
map
与
keyBy
之间。操作符的每一个子任务把数据发送到不同的目标子任务。
-
Flink的架构
-
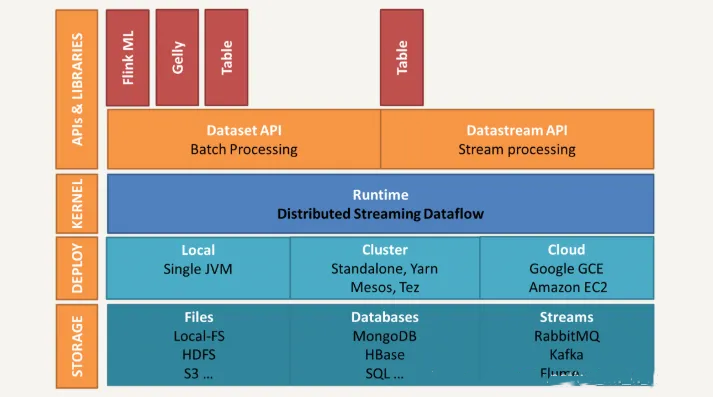
当前版本
Flink
的架构如下图所示
这个架构和
Spark
架构比较类似,都分为四层:存储层、部署层、核心处理引擎、
high-level
的
API
和库。
从存储层来看,
Flink
同样兼容多种主流文件系统如
HDFS
、
Amazon S3
,多种数据库如
HBase
和多种数据流如
Kafka
和
Flume
。
从部署层来看,
Flink
不仅支持本地运行,还能在独立集群或者在被
YARN
或
Mesos
管理的集群上运行,也能部署在云端。
核心处理引擎就是我们刚才提到的分布式
Streaming Dataflow
,所有的高级
API
及应用库都会被翻译成包含
Stream
和
Operator
的
Dataflow
来执行。
Flink
提供的两个核心
API
就是
DataSet APl
和
DataStream APl
。你没看错,名字和
Spark
的
DataSet
、
DataFrame
非常相似。顾名思义,
DataSet
代表有界的数据集,而
DataStream
代表流数据。所以,
DataSet API
是用来做批处理的,而
DataStream API
是做流处理的。
也许你会问,
Flink
这样基于流的模型是怎样支持批处理的?在内部,
DataSet
其实也用
Stream
表示,静态的有界数据也可以被看作是特殊的流数据,而且
DataSet
与
DataStream
可以无缝切换。所以,
Flink
的核心是
DataStream
。
-
Flink和Spark对比
-
通过前面的学习,我们了解到,
Spark
和
Flink
都支持批处理和流处理,接下来让我们对这两种流行的数据处理框架在各方面进行对比。首先,这两个数据处理框架有很多相同点。
•都基于内存计算;
•都有统一的批处理和流处理
APl
,都支持类似
SQL
的编程接口;
•都支持很多相同的转换操作,编程都是用类似于
Scala Collection APl
的函数式编程模式;
•都有完善的错误恢复机制;
•都支持
Exactly once
的语义一致性。
当然,它们的不同点也是相当明显,我们可以从
4
个不同的角度来看。
从流处理的角度来讲,
Spark
基于微批量处理,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性只能做到秒级。而
Flink
基于每个事件处理,每当有新的数据输入都会立刻处理,是真正的流式计算,支持毫秒级计算。由于相同的原因,
Spark
只支持基于时间的窗口操作(处理时间或者事件时间),而
Flink
支持的窗口操作则非常灵活,不仅支持时间窗口,还支持基于数据本身的窗口,开发者可以自由定义想要的窗口操作。
从
SQL
功能的角度来讲,
Spark
和
Flink
分别提供
SparkSQL
和
Table APl
提供
SQL
交互支持。
两者相比较,
Spark
对
SQL
支持更好,相应的优化、扩展和性能更好,而
Flink
在
SQL
支持方面还有很大提升空间。
从迭代计算的角度来讲,
Spark
对机器学习的支持很好,因为可以在内存中缓存中间计算结果来加速机器学习算法的运行。但是大部分机器学习算法其实是一个有环的数据流,在
Spark
中,却是用无环图来表示。而
Flink
支持在运行时间中的有环数据流,从而可以更有效的对机器学习算法进行运算。
从相应的生态系统角度来讲,
Spark
的社区无疑更加活跃。
Spark
可以说有着
Apache
旗下最多的开源贡献者,而且有很多不同的库来用在不同场景。而
Flink
由于较新,现阶段的开源社区不如
Spark
活跃,各种库的功能也不如
Spark
全面。但是
Flink
还在不断发展,各种功能也在逐渐完善。
-
如何选择Spark和Flink
-
对于以下场景,你可以选择
Spark
。
•数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等);
•基于历史数据的交互式查询,要求响应较快;
•基于实时数据流的数据处理,延迟性要求在在数百毫秒到数秒之间。
Spark
完美满足这些场景的需求,而且它可以一站式解决这些问题,无需用别的数据处理平台。由于
Flink
是为了提升流处理而创建的平台,所以它适用于各种需要非常低延迟(微秒到毫秒级)的实时数据处理场景,比如实时日志报表分析。
而且
Flink
用流处理去模拟批处理的思想,比
Spark
用批处理去模拟流处理的思想扩展性更好。
作者:「苝花向暖丨楠枝向寒」
大数据工程师,欢迎大家关注呀!
猜你喜欢:
Spark性能调优指北:性能优化
一张图解释清楚大数据技术架构
Hive文件存储格式和Hive数据压缩总结
字节跳动,5面,终于拿下!
详解Hive 排序和开窗函数
数据库
文章转载自
BAT大数据架构
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨