




用户与对象管理
目录
1. 用户 5
1.1. 用户的创建和删除 5
1.1.1. 创建 5
1.1.2. 删除Oracle用户: 7
1.2. 权限的授予和回收 8
1.2.1. 授予权限 8
1.2.2. 收回权限 9
1.3. 密码验证函数 10
1.3.1. 查看oracle提供的密码函数脚本 10
1.3.2. 执行脚本 11
1.4. 用户profile 11
1.4.1. 创建profile 11
1.4.2. profile常见参数如下图: 12
1.5. 11G中关于用户密码的新特性 12
1.5.1. 密码大小写敏感性 12
1.5.2. 密码延迟验证(Password Locking and Delay) 13
1.5.3. 密码过期(Password Expiration) 13
1.5.4. 密码复杂性验证(Password Complexity Verification) 13
1.6. 11G中默认角色权限的差异 13
1.6.1. connect角色 13
1.6.2. resource角色 14
1.6.3. DBA角色 14
1.7. 与用户、权限、角色相关的动态性能视图和数据字典 15
1.7.1. DBA_USERS: 15
1.7.2. DBA_ROLES: 16
1.7.3. DBA_ROLE_PRIVS: 17
1.7.4. DBA_TAB_PRIVS: 18
1.7.5. DBA_SYS_PRIVS: 18
2. 对象相关 19
2.1. 表相关 19
2.1.1. 表的类型、创建方式 19
1.1.1. 数据类型 19
2.1.2. 分区表的类型、作用、使用场景 23
2.1.3. 延迟段创建 29
2.1.4. 临时表的分类、创建语句、使用场景 30
2.1.5. 高水位问题 32
2.1.6. 与表相关的动态性能视图和数据字典 33
2.2. 索引相关 35
2.2.1. 索引的类型 35
2.2.2. 作用: 36
2.2.3. 创建语句: 36
2.2.4. 修改 37
2.2.5. 查看 37
2.2.6. 使用场景: 37
2.2.7. 如何监控索引的使用情况 38
2.2.8. 如何重建索引?什么情况下重建索引? 39
2.2.9. 与索引相关的动态性能视图和数据字典 40
2.3. dblink 42
2.3.1. 分类 42
2.3.2. 创建dblink的方法 42
2.4. 分布式事务了解 43
2.4.1. 含义 43
2.4.2. 组成部分 43
2.5. ORA-19706错误和_external_scn_rejection_threshold_hours参数了解 43
2.6. 与dblink相关的动态性能视图和数据字典 44
2.6.1. DBA_DB_LINKS 数据字典视图: 44
2.6.2. V$DBLINK 动态性能视图: 44
2.6.3. ALL_DB_LINKS 数据字典视图: 45
2.7. 物化视图 45
2.7.1. 物化视图的分类 45
2.7.2. 创建 46
2.7.3. 物化视图的维护 46
2.7.4. 查询重写的使用 46
2.7.5. 与物化视图相关的动态性能视图和数据字典 47
3. 表空间 48
3.1. 表空间的类型、作用、创建语句 48
3.1.1. 系统表空间(System Tablespace) 48
3.1.2. 用户表空间(User Tablespace): 48
3.1.3. 临时表空间(Temporary Tablespace): 48
3.1.4. 回滚表空间(Undo Tablespace): 48
3.1.5. 临时回滚表空间(Temporary Undo Tablespace): 49
3.1.6. 恢复目录表空间(Recovery Catalog Tablespace): 49
3.1.7. 创建 49
3.2. undo表空间 49
3.2.1. undo表空间的作用 49
3.2.2. undo表空间相关的参数 50
3.2.3. ORA-01555的由来 50
3.2.4. undo表空间相关的动态性能视图、数据字典 51
3.3. temp表空间 52
3.3.1. temp表空间的作用 52
3.3.2. ORA-1652问题处理 53
3.3.3. temp表空间相关的动态性能视图、数据字典 53
总结 54
用户
用户的创建和删除
创建
IDENTIFIED BY password:指定用户的密码。也可以使用EXTERNALLY来指定用户通过外部身份验证进行认证。
create user user identified {by password | externally}
[ default tablespace tablespace ]
[ temporary tablespace tablespace ]
[ quota {integer [k | m ] | unlimited } on tablespace [ quota {integer [k | m ] | unlimited } on tablespace]...]
[ password expire ]
[ account { lock | unlock }]
[ profile { profile | default }]
ALTER USER user IDENTIFIED BY new_password;
- DEFAULT TABLESPACE tablespace:指定用户的默认表空间,即用户创建的对象(如表、索引等)所使用的表空间。
- TEMPORARY TABLESPACE tablespace:指定用户的临时表空间,用于用户的临时数据和排序操作。
查看默认和临时表空间:
SELECT default_tablespace, temporary_tablespace FROM dba_users WHERE username = 'test_user';
- QUOTA {integer [K | M ] | UNLIMITED } ON tablespace:指定用户在指定表空间上的配额,即用户在该表空间上可以使用的存储空间大小。可以使用整数(单位为KB或MB)或者UNLIMITED表示无限制。
- 修改配额:
ALTER USER user_name QUOTA {integer [K | M ] | UNLIMITED } ON tablespace_name;
- 查看表空间配额:
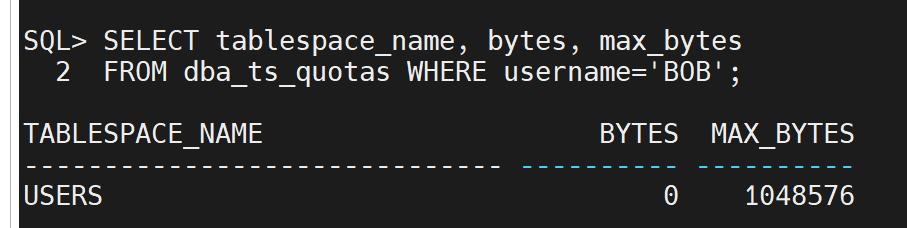
SELECT tablespace_name, max_bytes/1024/1024 AS quota_mb FROM dba_ts_quotas WHERE username = 'test_user';
- PASSWORD EXPIRE:指定用户的密码在创建后立即过期,要求用户在首次登录后修改密码。
- ACCOUNT { LOCK | UNLOCK }:指定用户的账号状态,可以将账号锁定或解锁。
ALTER USER user ACCOUNT { LOCK | UNLOCK }
- PROFILE { profile | DEFAULT }:指定用户使用的配置文件(profile),配置文件中包含了用户的资源限制和密码策略等设置。也可以使用DEFAULT表示使用默认配置文件。
- 练习
1.创建用户 Bob,口令是 CRUSADER,该用户在 USERS 和 INDX 表空间上的配额是 1MB,它的默认表空间是 USERS,临时表空间是 TEMP。
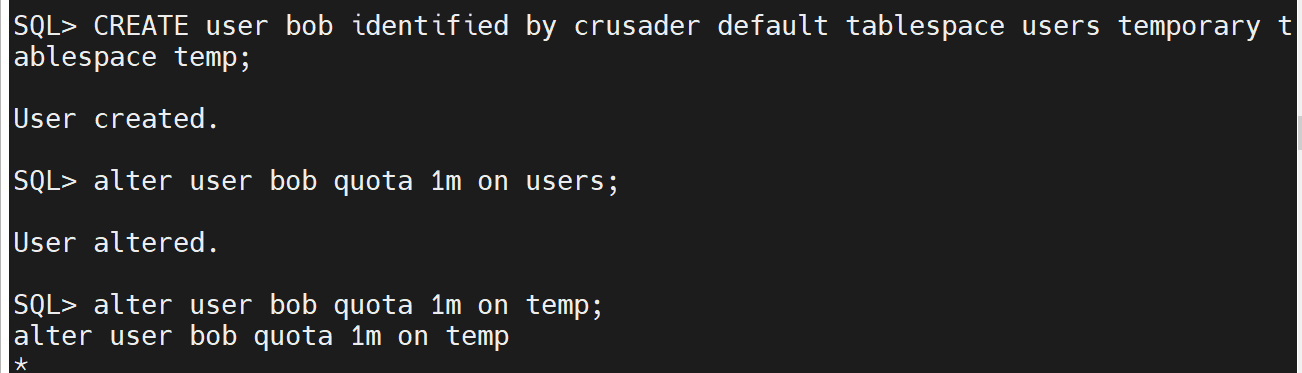
授予 Bob 用户 CREATE SESSION 系统权限

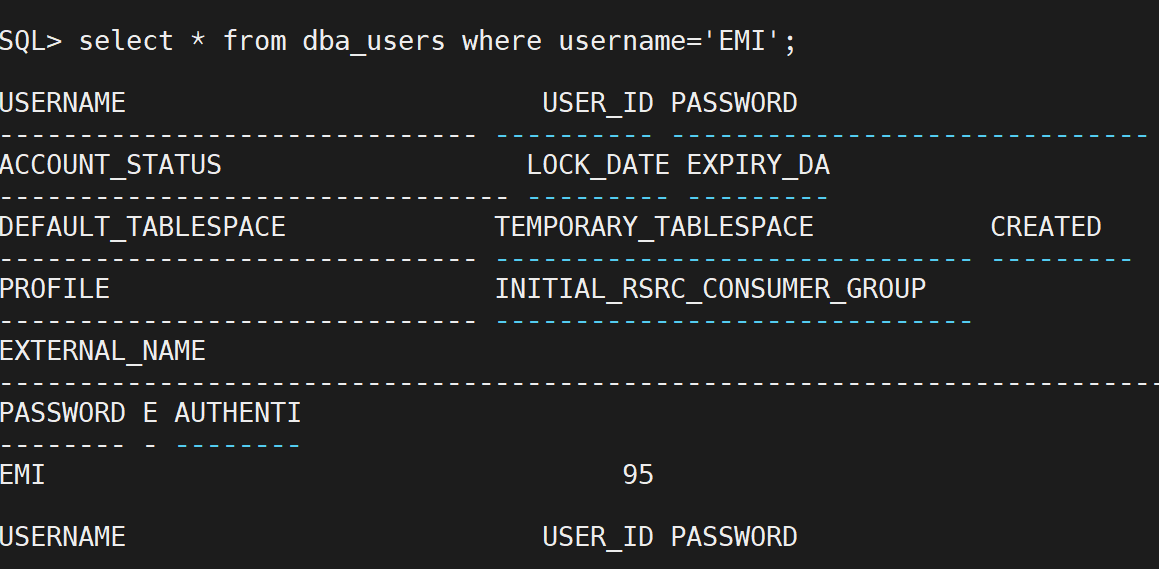
3.创建用户 Emi,口令是 MARY。

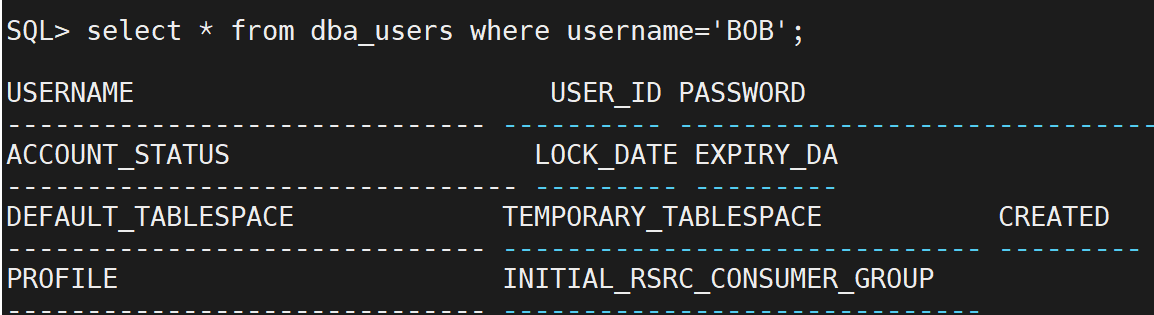
从数据字典视图中显示 Bob 和 Emi 的信息。
在数据字典视图中显示 Bob 的表空间配额。
以用户 Bob 登录,把自己的口令改为 Sam。

以管理员身份登录,把 Bob 的默认表空间的配额改为 0。

删除用户 Emi
以管理员身份登录,把 Bob 的口令改为 OLINK,并要求他初次登录后强制改变口令。
删除Oracle用户:
DROP USER username [CASCADE];
CASCADE选项将删除用户及其相关的对象(如表、视图等)。
注:如果用户当前正连接到数据库,则不能删除该用户。必须先用 ALTER SYSTEM KILL SESSION 语句终止它的会话,然后再用 DROP USER 将用户删除。
drop user cwt cascade;
权限的授予和回收
授予权限
语法:
GRANT CONNECT, RESOURCE TO 用户名;
GRANT SELECT ON 表名 TO 用户名;
GRANT SELECT, INSERT, DELETE ON表名 TO 用户名1, 用户名2;
(1)创建session的权限给username(create session就是允许使用这个用户在服务器上创建session。通俗的说,就是允许这个用户登录。)
grant create session to username;

(3)没有限制的表空间;
SQL> grant unlimited tablespace to username;

(4)如果对权限要求不是很严格的话,直接赋予管理员权限;
SQL> grant dba to username;
收回权限
语法如下:
REVOKE CONNECT, RESOURCE FROM 用户名;
REVOKE SELECT ON 表名 FROM 用户名;
REVOKE SELECT, INSERT, DELETE ON表名 FROM 用户名1, 用户名2
--收回查询表的权限
revoke select on demo from username;
revoke all on demo from username;
--查询一个用户拥有的对象权限
select table_name,privilege from dba_tab_privs where grantee='username';
SELECT TABLE_NAME,PRIVILEGE FROM DBA_TAB_PRIVS WHERE GRANTEE='BOB';
- 查询一个用户拥有的系统权限
select * from dba_sys_privs where grantee='username';

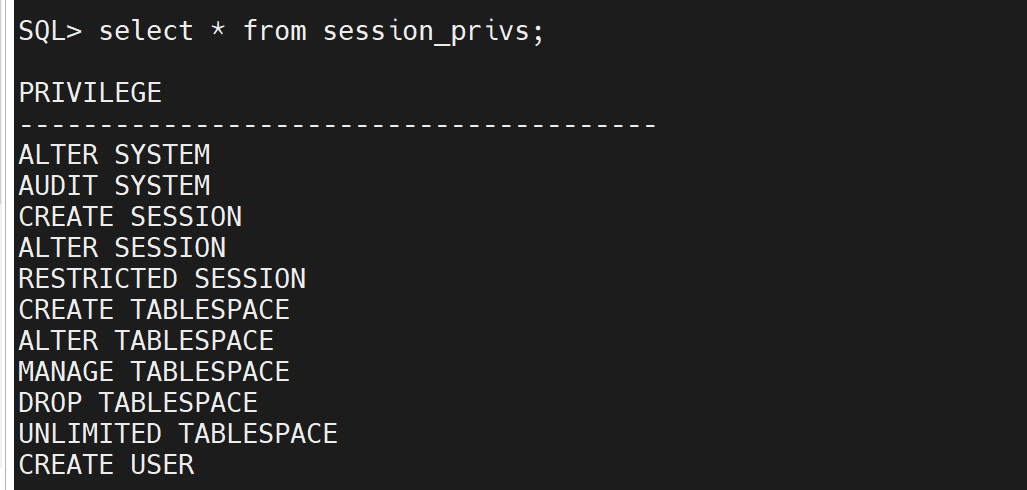
--当前会话有效的系统权限
SQL> select * from session_privs;
密码验证函数
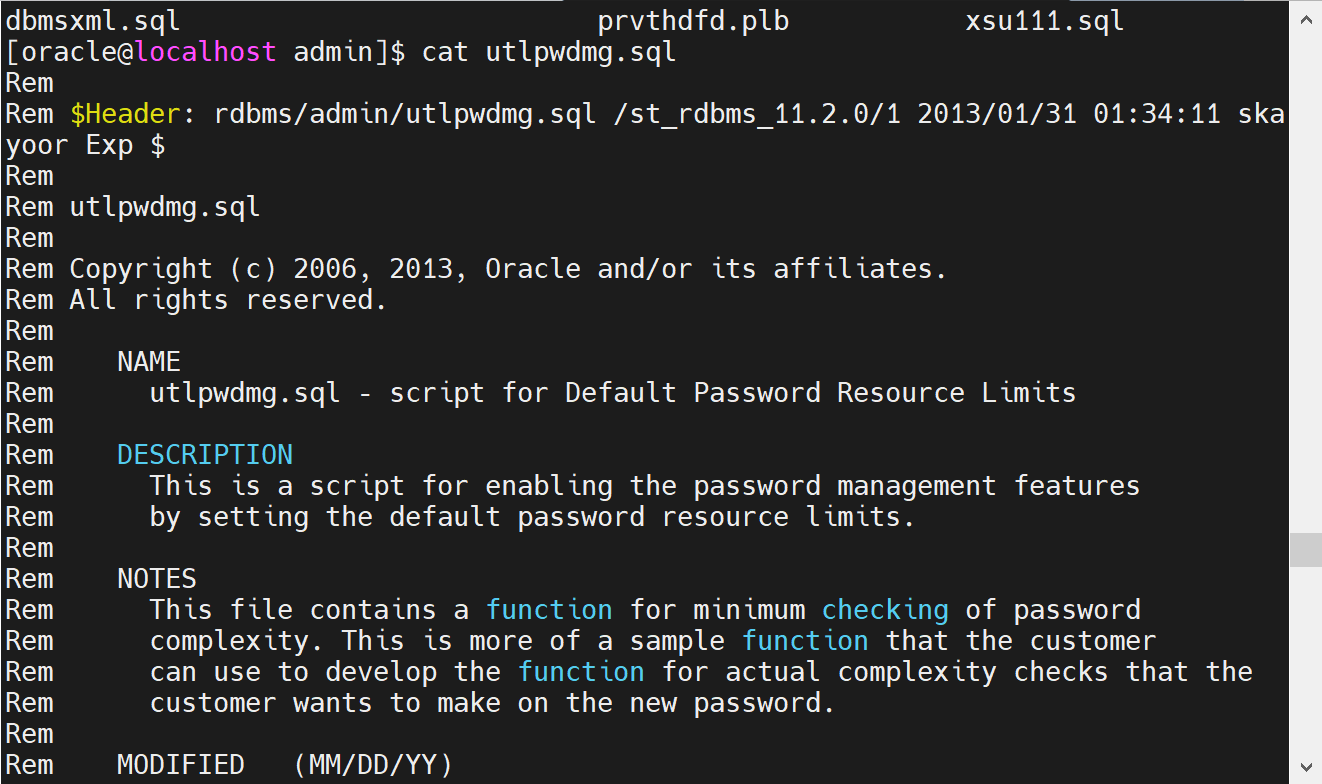
查看oracle提供的密码函数脚本
$ cat utlpwdmg.sql
该脚本用于通过设置默认密码资源限制来启用密码管理特性。
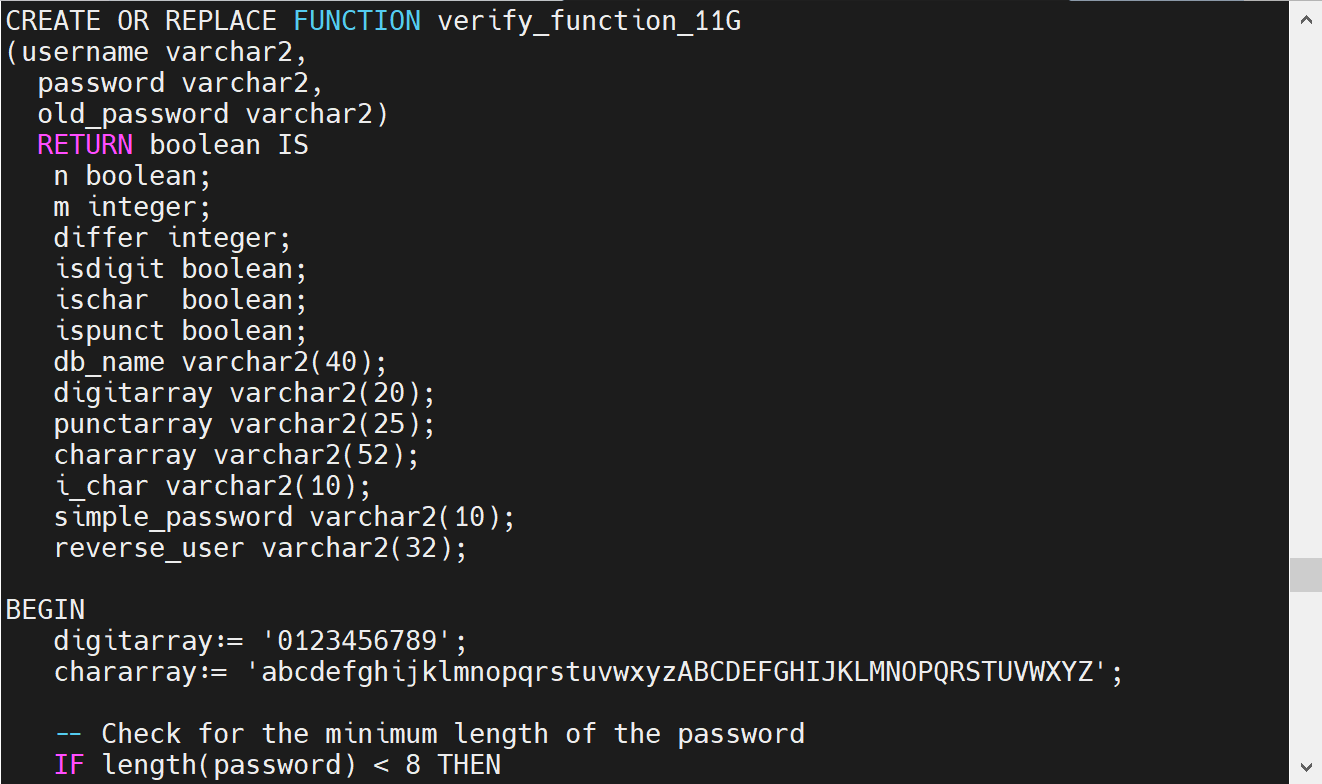
她包含一个最小检查密码复杂度的函数。是一个示例函数。这个脚本的作用是创建和管理用户密码的复杂性验证规则。
- 创建密码复杂性验证函数:脚本会创建一个名为VALIDATE_FUNCTION_11G的密码验证函数。该函数会检查用户密码是否符合一组复杂性规则,例如密码长度、是否包含数字和字母等。
- 创建密码验证策略:脚本会创建一个名为DEFAULT_STRENGTH_POLICY的密码验证策略。该策略定义了密码的最小长度、密码有效期等规则。
- 应用密码验证策略:脚本会将DEFAULT_STRENGTH_POLICY策略应用于所有用户。
- 禁用旧的密码验证功能:脚本会禁用旧的密码验证功能,如PASSWORD_VERIFY_FUNCTION参数和ORA12C_STRONG_VERIFY_FUNCTION参数。
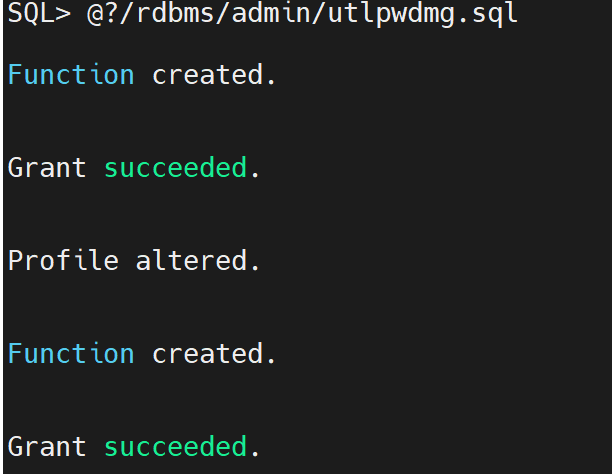
执行脚本
SQL>@?/rdbms/admin/utlpwdmg.sql
用户profile
创建profile
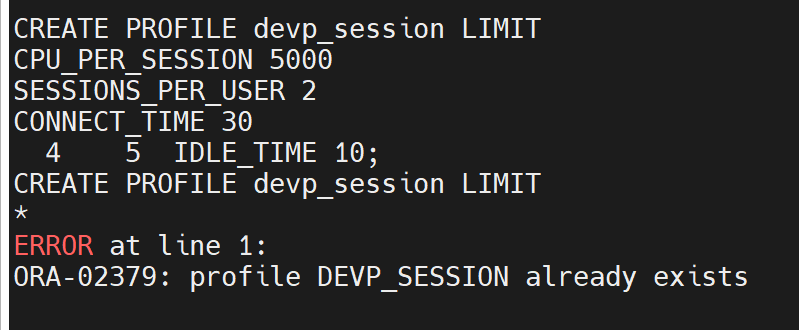
CREATE PROFILE devp_session LIMIT
CPU_PER_SESSION 5000
SESSIONS_PER_USER 2
CONNECT_TIME 30
IDLE_TIME 10;
- 分配概要文件给用户 devp
ALTER USER devp PROFILE devp_session;

profile常见参数如下图:
参数 | 说明 | 默认值 |
failed_login_attempts | 允许的输入错误口令的次数 | 10次 |
PASSWORD_LOCK_TIME | 账户被锁定的天数 | 1 |
PASSWORD_life_TIME | 口令的有效期 | 180天 |
PASSWORD_grace_TIME | 口令失效的宽限期 | 7天 |
PASSWORD_reuse_TIME | 重用口令之前口令需要改变的次数 | UNLIMITED |
PASSWORD_reuse_MAX | 重复使用口令之前必须对口令进行修改的次数 | UNLIMITED |
IDLE_TIME | 允许的最大空闲时间 | UNLIMITED |
CONNECT_TIME | 允许的最大连接时间 | UNLIMITED |
SESSIONS_PER_USER | 允许的最大并发会话数 | UNLIMITED |
CPU_PER_SESSION | 用户每个会话允许使用的CPU时间 | UNLIMITED |
logical_reads_per_session | 用户每个会话允许的逻辑读取次数 | UNLIMITED |
LOGICAL_READS_PER_CALL | 用户每次调用允许的逻辑读取次数 | UNLIMITED |
11G中关于用户密码的新特性
【说明】
密码大小写、密码延迟验证等
可参考的文档:High 'library cache lock' Wait Time Due to Invalid Login Attempts (文档 ID 1309738.1)
密码大小写敏感性
默认情况下,用户密码是大小写不敏感的。但是,通过设置 SEC_CASE_SENSITIVE_LOGON 参数为 TRUE,可以启用密码的大小写敏感性。
密码延迟验证(Password Locking and Delay)
Oracle 11g 引入了一个新的密码验证功能,可以设置密码的延迟验证时间。这样,当用户多次尝试登录但密码错误时,系统会在一段时间内锁定用户账户,防止暴力破解密码。可以通过设置 FAILED_LOGIN_ATTEMPTS 参数来控制允许的失败登录尝试次数,以及 PASSWORD_LOCK_TIME 参数来设置锁定时间。
密码过期(Password Expiration)
在 Oracle 11g 中,可以为用户设置密码的过期时间。一旦密码过期,用户必须在下次登录时更改密码。可以通过设置 PASSWORD_LIFE_TIME 参数来控制密码的有效期限,以及 GRACE_TIME 参数来设置在密码过期前的宽限期。
密码复杂性验证(Password Complexity Verification)
Oracle 11g 引入了密码复杂性验证功能,可以强制要求用户设置复杂的密码。可以通过设置 PASSWORD_VERIFY_FUNCTION 参数来指定一个自定义的密码验证函数,该函数用于验证用户设置的密码是否满足复杂性要求,例如包含大写字母、小写字母、数字和特殊字符等。
11G中默认角色权限的差异
【说明】
一些主要的角色中权限在10g、11g、12c中的差异,如connect角色。
connect角色
- 共有权限
CREATE SESSION:允许用户建立数据库会话。
ALTER SESSION:允许用户更改会话级别的参数。
CREATE TABLE:允许用户创建表。
CREATE VIEW:允许用户创建视图。
CREATE PROCEDURE:允许用户创建存储过程。
CREATE SEQUENCE:允许用户创建序列。
CREATE SYNONYM:允许用户创建同义词。
CREATE DATABASE LINK:允许用户创建数据库链接。
CREATE TYPE:允许用户创建类型。
CREATE OPERATOR:允许用户创建操作符。
- 10g
CREATE CLUSTER:允许用户创建集群。
CREATE TRIGGER:允许用户创建触发器。
- 12c
CREATE INDEXTYPE:允许用户创建索引类型。
CREATE DIMENSION:允许用户创建维度。
CREATE JOB:允许用户创建作业。
CREATE EVALUATION CONTEXT:允许用户创建评估上下文
resource角色
- 共有权限
CREATE TABLE:允许用户创建表。
CREATE VIEW:允许用户创建视图。
CREATE PROCEDURE:允许用户创建存储过程。
CREATE SEQUENCE:允许用户创建序列。
CREATE SYNONYM:允许用户创建同义词。
CREATE DATABASE LINK:允许用户创建数据库链接。
CREATE TYPE:允许用户创建类型。
- 10g
CREATE CLUSTER:允许用户创建集群。
CREATE TRIGGER:允许用户创建触发器。
- 11g和12c
CREATE OPERATOR:允许用户创建操作符。
DBA角色
- 共有权限
CREATE TABLE:允许用户创建表。
CREATE VIEW:允许用户创建视图。
CREATE PROCEDURE:允许用户创建存储过程。
CREATE SEQUENCE:允许用户创建序列。
CREATE SYNONYM:允许用户创建同义词。
CREATE DATABASE LINK:允许用户创建数据库链接。
CREATE TYPE:允许用户创建类型。
CREATE OPERATOR:允许用户创建操作符。
ALTER ANY TABLE:允许用户修改任意表。
DROP ANY TABLE:允许用户删除任意表。
SELECT ANY TABLE:允许用户查询任意表。
- 10g
CREATE CLUSTER:允许用户创建集群。
CREATE TRIGGER:允许用户创建触发器。
- 11g和12c
ADMINISTER DATABASE TRIGGER:允许用户管理数据库触发器。
ALTER DATABASE:允许用户修改数据库级参数。
与用户、权限、角色相关的动态性能视图和数据字典
【说明】
对用户、权限、角色相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
DBA_USERS:
包含有关所有数据库用户的信息,如用户名、默认表空间、临时表空间、账户状态等。
desc DBA_USERS;
SELECT * FROM DBA_USERS;
SELECT username, account_status, default_tablespace FROM dba_users;
select username from dba_users where username='BOB';

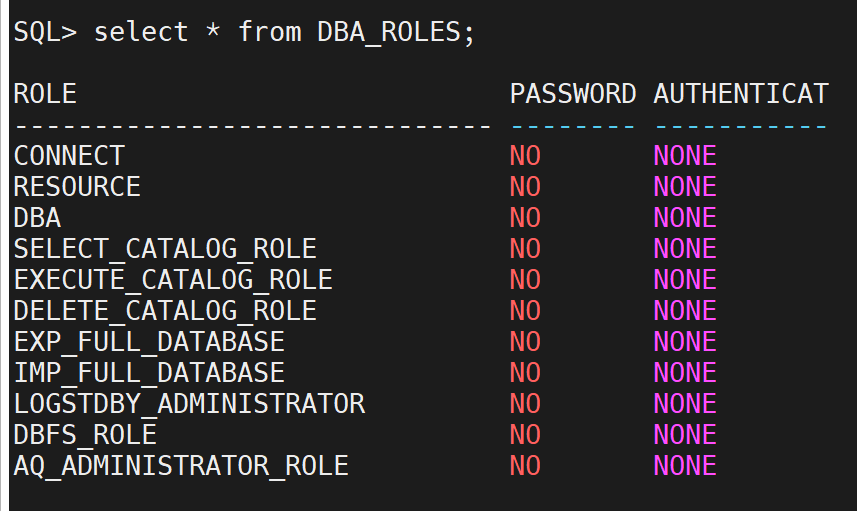
DBA_ROLES:
包含有关所有角色的信息,如角色名、角色类型等。
SELECT * FROM DBA_ROLES;
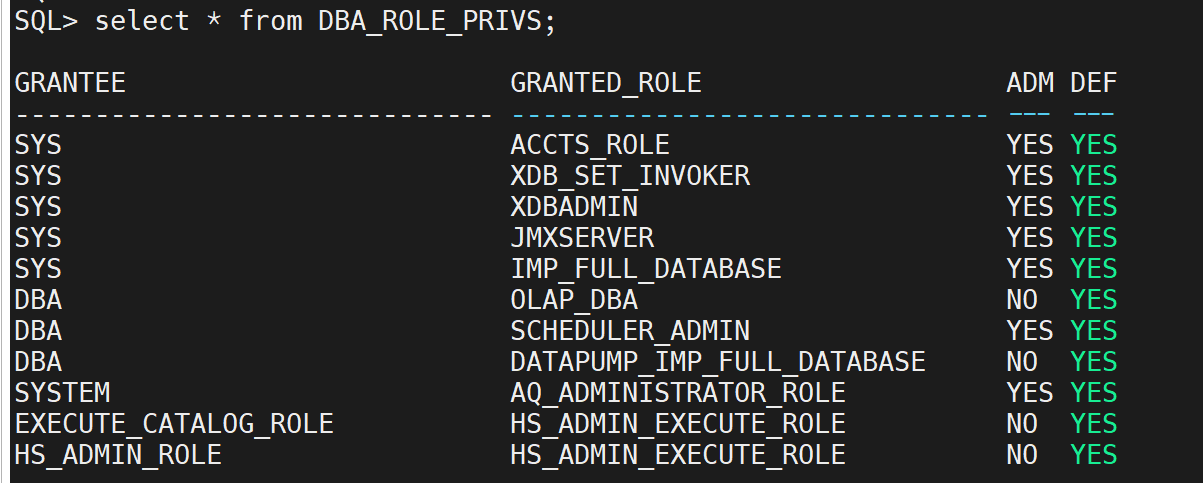
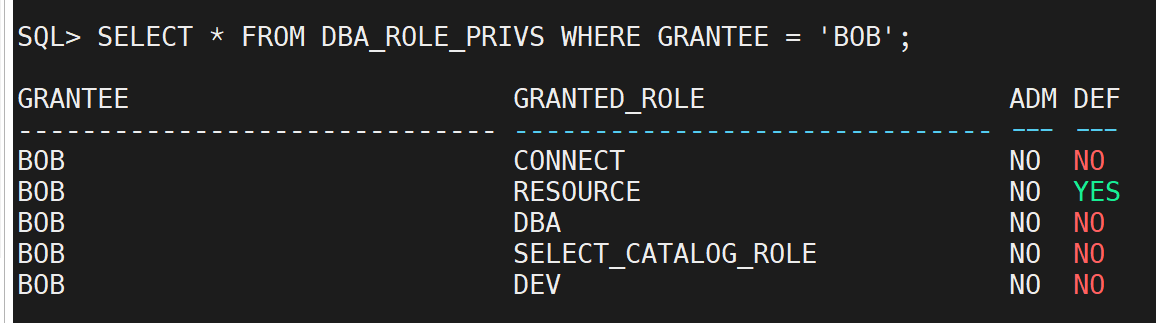
DBA_ROLE_PRIVS:
显示用户与角色之间的关系,即哪些用户被授予了哪些角色。
SELECT * FROM DBA_ROLE_PRIVS WHERE GRANTEE = 'USERNAME';
DBA_TAB_PRIVS:
显示用户对表的权限信息,包括授予的权限类型和授权者。
SELECT * FROM DBA_TAB_PRIVS WHERE GRANTEE = 'USERNAME';
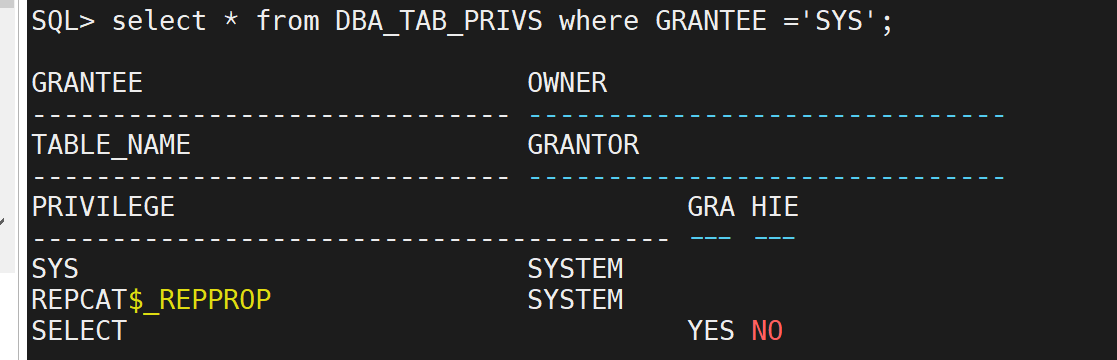
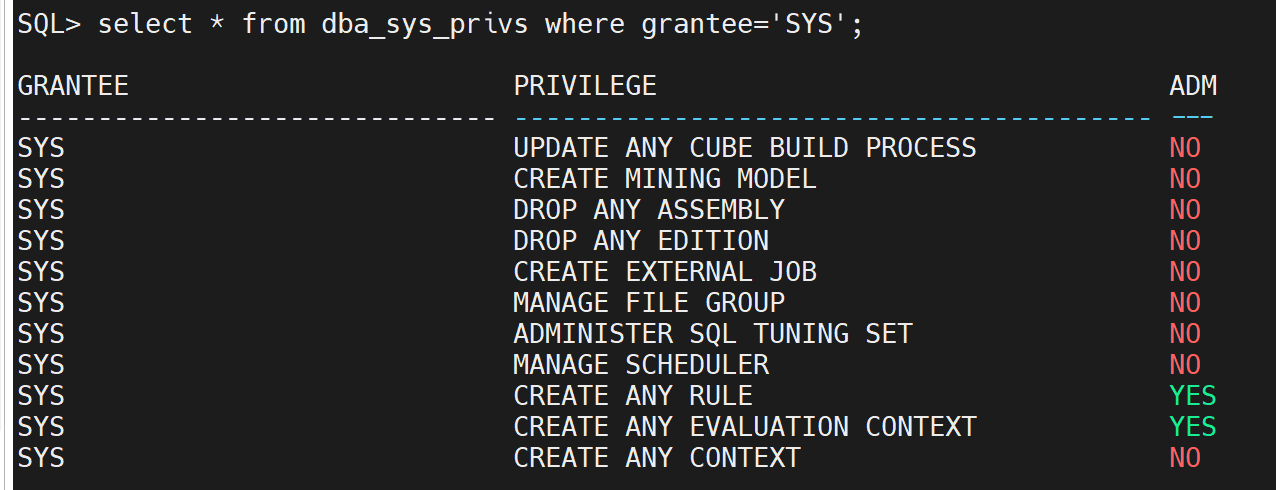
DBA_SYS_PRIVS:
显示用户的系统级权限信息,如SELECT ANY TABLE、CREATE TABLE等。
desc dba_sys_privs;

SELECT * FROM DBA_SYS_PRIVS WHERE GRANTEE = 'USERNAME';
对象相关
表相关
表的类型、创建方式
CHAR:定长字符串,它会用空格填充来达到其最大长度,最多可以存储2000字节的信息
NCHAR:这是一个包含UNICODE格式数据的定长字符串,最多可以存储2000字节的信息
VARCHAR2:变长字符串,它不会用空格填充来达到其最大长度,最多可以存储4000字节的信息
NVARCHAR2:这是一个包含UNICODE格式数据的变长字符串,最多可以存储4000字节的信息
- 数值类型
NUMBER:NUMBER(p,s)是最常见的数字类型,关于NUMBER的有效位§和精确位(s)遵循以下规则:
p:是有效数据总位数,取值范围为【1-38】,默认值是38
s:表示精确到多少位,取值范围为【-84-127】,默认值是0
INTEGER:INTEGER是NUMBER的子类型,它等同于NUMBER(38,0),用来存储整数
FLOAT:Float(n)是NUMBER的子类型,数 n 指示位的精度,n值的范围可以从1到126
- 日期类型
DATE:DATE是最常用的日期数据类型,它可以存储日期和时间信息,虽然可以用字符或数字类型表示日期和时间信息,但是日期数据类型具有特殊关联的属性。Oracle 为每个日期值存储以下信息: 世纪、 年、 月、 日期、 小时、 分钟和秒,一般占用7个字节的存储空间
TIMESTAMP:这是一个7字节或12字节的定宽日期/时间数据类型。它与DATE数据类型不同,因为TIMESTAMP可以包含小数秒,带小数秒的TIMESTAMP在小数点右边最多可以保留9位
- 普通表(Regular Table):这是最常见的表类型,用于存储数据。
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...);
column1, column2, ...:表中的列名。
datatype:列的数据类型。

CREATE TABLE employees ( employee_id NUMBER, first_name VARCHAR2(50), last_name VARCHAR2(50), hire_date DATE, salary NUMBER );
- 分区表(Partitioned Table):分区表将数据分割成多个逻辑分区,每个分区可以独立管理和查询。
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...)partition by partitioning_method (column);
partitioning_method:分区表的分区方法,例如RANGE(按范围分区)、HASH(按哈希值分区)、LIST(按列表分区)等。
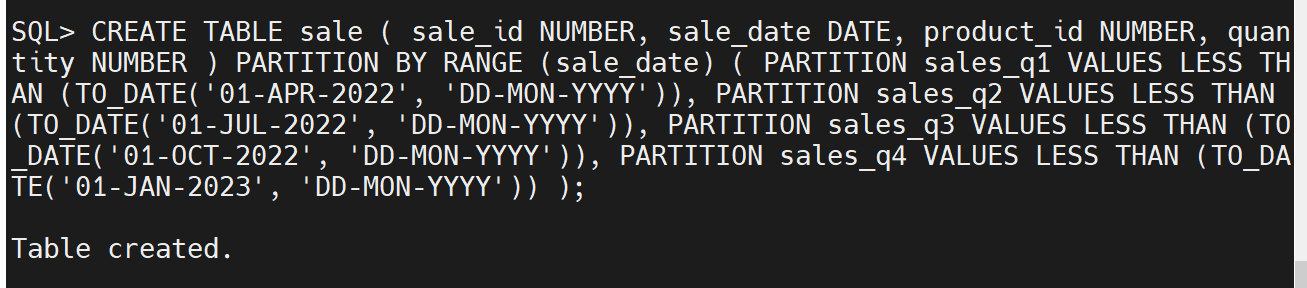
CREATE TABLE sale ( sale_id NUMBER, sale_date DATE, product_id NUMBER, quantity NUMBER )
PARTITION BY RANGE (sale_date) ( PARTITION sales_q1 VALUES LESS THAN (TO_DATE('01-APR-2022', 'DD-MON-YYYY')), PARTITION sales_q2 VALUES LESS THAN (TO_DATE('01-JUL-2022', 'DD-MON-YYYY')), PARTITION sales_q3 VALUES LESS THAN (TO_DATE('01-OCT-2022', 'DD-MON-YYYY')), PARTITION sales_q4 VALUES LESS THAN (TO_DATE('01-JAN-2023', 'DD-MON-YYYY')) );
- 临时表(Temporary Table):临时表用于存储临时数据,通常在会话结束时自动删除。
CREATE GLOBAL TEMPORARY TABLE table_name (
column1 datatype,
column2 datatype,
...) ON COMMIT PRESERVE ROWS;
ON COMMIT PRESERVE/DELETE ROWS:指定在提交事务后保留或删除临时表的行。
- 创建全局临时表
CREATE GLOBAL TEMPORARY TABLE temp_employees ( employee_id NUMBER, first_name VARCHAR2(50), last_name VARCHAR2(50), hire_date DATE, salary NUMBER ) ON COMMIT DELETE ROWS;

- 外部表(External Table):外部表是指与数据库外部存储中的数据进行关联的表,可以通过查询来访问外部数据。
CREATE TABLE table_name (
column1 datatype,
...)
ORGANIZATION EXTERNAL (
TYPE oracle_loader
DEFAULT DIRECTORY directory_name
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE
BADFILE 'file_name.bad'
LOGFILE 'file_name.log'
FIELDS TERMINATED BY ','
... )
LOCATION ('file_name.csv')
);
ORGANIZATION EXTERNAL:创建外部表。
TYPE ORACLE_LOADER:指定外部表的类型为 Oracle Loader。
DEFAULT DIRECTORY directory_name:指定默认的目录,用于存储外部数据文件。
ACCESS PARAMETERS:指定访问外部数据文件的参数,例如记录分隔符、字段分隔符、错误文件名等。
LOCATION ('file_name.csv'):指定外部数据文件的位置。
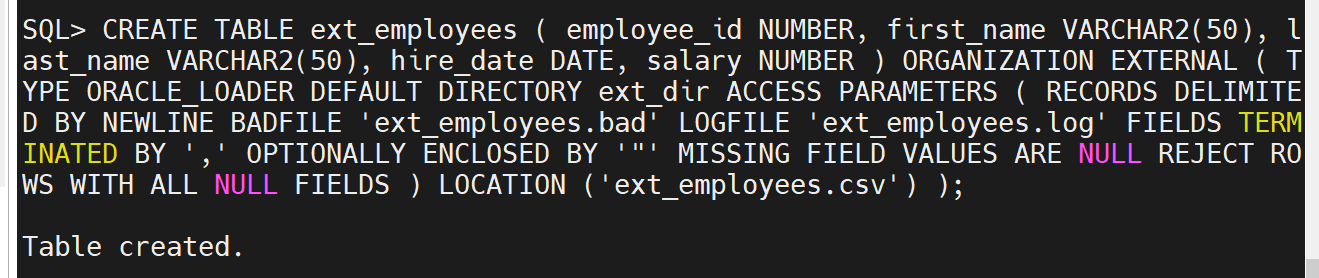
CREATE DIRECTORY ext_dir AS '/path/to/directory';
CREATE TABLE ext_employees ( employee_id NUMBER, first_name VARCHAR2(50), last_name VARCHAR2(50), hire_date DATE, salary NUMBER ) ORGANIZATION EXTERNAL ( TYPE ORACLE_LOADER DEFAULT DIRECTORY ext_dir ACCESS PARAMETERS ( RECORDS DELIMITED BY NEWLINE BADFILE 'ext_employees.bad' LOGFILE 'ext_employees.log' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' MISSING FIELD VALUES ARE NULL REJECT ROWS WITH ALL NULL FIELDS ) LOCATION ('ext_employees.csv') );
- RECORDS DELIMITED BY NEWLINE:指定记录之间使用换行符分隔。
- BADFILE 'ext_employees.bad':指定坏记录的文件名为 ext_employees.bad。这个文件将包含无法加载到表中的记录。
- LOGFILE 'ext_employees.log':指定日志文件的文件名为 ext_employees.log。这个文件将包含加载过程中的日志信息。
- FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"':指定字段之间使用逗号分隔,并且字段可以选择性地由双引号括起来。
- MISSING FIELD VALUES ARE NULL:指定缺失字段值为 NULL。
- REJECT ROWS WITH ALL NULL FIELDS:指定如果一行中所有字段都是 NULL,则拒绝该行。
- LOCATION ('ext_employees.csv'):指定外部表的数据文件位置为 ext_employees.csv。这是包含要加载到表中的数据的文件。
分区表的类型、作用、使用场景
【说明】
对分区表在10g、11g、12c中的变化进行总结,并对每种分区表的使用场景进行总结,最好是以图表的形式。
分区表就是通过使用分区技术,将一张大表,拆分成多个表分区(独立的segment),从而提升数据
访问的性能,以及日常的可维护性。
分区表中,每个分区的逻辑结构必须相同。如:列名、数据类型。
分区表中,每个分区的物理存储参数可以不同。如:各个分区所在的表空间。
版本 | 变化 | 使用场景 |
10g | 引入了本地分区索引(Local Partitioned Index),使索引与分区表的分区对应,提高查询性能。 | - 大型表的分区,可以使用本地分区索引来提高查询性能。<br>- 对分区表进行频繁的DML操作时,本地分区索引可以减少锁冲突。 |
11g | 引入了全局分区索引(Global Partitioned Index),可以在整个分区表上创建索引,而不仅仅是在每个分区上创建索引。 | - 分区表的分区数较少,但需要在整个表上进行索引查询的场景。<br>- 需要在分区表上进行范围查询时,全局分区索引可以提供更好的性能。 |
12c | 引入了增强的分区功能,包括自动区分和自动转换分区。自动区分允许根据新插入的数据自动创建新的分区,而自动转换允许将一个分区转换为另一个分区。 | - 需要动态地添加新分区以容纳不断增长的数据。<br>- 需要对历史数据进行归档,将旧的分区转换为归档分区。 |
注意:各个分区可以存放在不同的表空间中,但这些表空间所使用的块大小 (block_size)必须一致。
1. 创建分区表
1)表空间:
表空间是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间。
2)分区表:
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表,以便加快查询效率。
Oracle的分区表可以包括多个分区,每个分区都是一个独立的段(SEGMENT),可以存放到不同的表空间(tablespace)中。查询时可以通过查询表来访问各个分区中的数据,也可以通过在查询时直接指定分区的方法来进行查询。
3)表分区优点/缺点:
表分区有以下优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己指定的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
表分区有以下缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
2. 分区的类型
(1)范围分区(range)
范围分区将数据基于范围映射到每一个分区,这个范围是在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。
使用范围分区时,需要注意以下几个规则:
1、每一个分区都必须有一个VALUES LESS THAN子句,它指定了一个不包括在该分区中的上限值。分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
2、所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
3、在最高的分区中,MAXVALUE被定义。MAXVALUE代表了一个不确定的值。这个值高于其它分区中的任何分区键的值,也可以理解为高于任何分区中指定的VALUE LESS THAN的值,同时包括空值。
Sample 1:
假设有个Bank Customer information 表,表中有数据1000000行,我们将此表通过CUSTOMER_ID进行分区,每个分区存储500000行,然后将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。
demo 1:
CREATE TABLE TBL_BANK_CUSTOMER_INFO
(
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
CARD_NO VARCHAR2(19) NOT NULL,
CUSTOMER_TYPE_ID VARCHAR2(1) NOT NULL,
CUSTOMER_NAME VARCHAR2(30) NOT NULL,
CUSTOMER_EMAIL VARCHAR2(80)
)
PARTITION BY RANGE (CUSTOMER_ID)
(
PARTITION TP_CUSTOMER_INFO1 VALUES LESS THAN (500000) TABLESPACE TBS_DWH_LARGE1,
PARTITION TP_CUSTOMER_INFO2 VALUES LESS THAN (1000000) TABLESPACE TBS_DWH_LARGE2
);
demo 2:
CREATE TABLE TBL_BANK_CUSTOMER_INFO
(
VERSION_DATE DATE,
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
CARD_NO VARCHAR2(19) NOT NULL,
CUSTOMER_TYPE_ID VARCHAR2(1) NOT NULL,
CUSTOMER_NAME VARCHAR2(30) NOT NULL,
CUSTOMER_EMAIL VARCHAR2(80)
)
PARTITION BY RANGE (VERSION_DATE)
(
PARTITION TP_CUSTOMER_INFO1 VALUES LESS THAN (TO_DATE('2022-02-01','YYYY-MM-DD')) TABLESPACE TBS_DWH_LARGE1,
PARTITION TP_CUSTOMER_INFO2 VALUES LESS THAN (TO_DATE('2022-03-01','YYYY-MM-DD')) TABLESPACE TBS_DWH_LARGE2,
PARTITION TP_CUSTOMER_INFO3 VALUES LESS THAN (TO_DATE('2022-04-01','YYYY-MM-DD')) TABLESPACE TBS_DWH_LARGE3,
);
demo 3:
CREATE TABLE TBL_BANK_CUSTOMER_INFO
(
VERSION_DATE DATE,
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
CARD_NO VARCHAR2(19) NOT NULL,
CUSTOMER_TYPE_ID VARCHAR2(1) NOT NULL,
CUSTOMER_NAME VARCHAR2(30) NOT NULL,
CUSTOMER_EMAIL VARCHAR2(80),
MONEY NUMBER
)
PARTITION BY RANGE (MONEY)
(
PARTITION TP_CUST_INFO1 VALUES LESS THAN (1000000) TABLESPACE TBS_MAPRJ_LARGE1,
PARTITION TP_CUST_INFO2 VALUES LESS THAN (5000000) TABLESPACE TBS_MAPRJ_LARGE2
);
(2)哈希分区(hash)
(3)列表分区(list)
该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。
demo 4:
CREATE TABLE TBL_BANK_CUSTOMER_INFO
(
VERSION_DATE DATE,
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
CUSTOMER_SEX VARCHAR2(1) NOT NULL,
CARD_NO VARCHAR2(19) NOT NULL,
CUSTOMER_TYPE_ID VARCHAR2(1) NOT NULL,
CUSTOMER_NAME VARCHAR2(30) NOT NULL,
CUSTOMER_EMAIL VARCHAR2(80),
MONEY NUMBER
)
PARTITION BY LIST (CUSTOMER_SEX)
(
PARTITION CUST_MALE VALUES ('male') TABLESPACE TBS_CUST_MALE,
PARTITION CUST_FEMALE VALUES ('female') TABLESPACE TBS_CUST_FEMALE
);
(4)范围-哈希复合分区(range-hash)
(5)范围-列表复合分区(range-list)
3. 查询分区、表空间
select * from dba_tab_partitions where table_name = upper('tablename1') order by partition_name desc;
4. 删除分区
alter table tablename1 drop partition partition_name;
5. 分解分区
alter table tablename1 split partition partition_name at (TO_DATE('2022-02-01','YYYY-MM-DD')) into (partition partition_name1, partition_name);
6. 创建分区
alter table tablename add partition partition_name values less than (TO_DATE('2022-02-0','YYYY-MM-DD'));
7. 查询索引表空间、分区
select index_name,partition_name,tablespace_name from dba_ind_partitions where index_name = upper('index_name') order by partition_name desc;
8. 修改表空间
alter table tablename move partition partition_name tablespace tablespacename;
9. 修改索引表空间
alter index indexname rebuild partition partition_name tablespace tablespacename;
10. 查询表占用的表空间
select segment_name, Bytes/1024/1024 || 'M' as 'SIZE', tablespace_name from dba_segments order by Bytes/1024/1024 desc;
11. 查询表有多大
select owner,segment_name, Bytes/1024/1024 || 'M' as 'SIZE', tablespace_name, partition_name from dba_segments where segment_name = 'tablename1' order by Bytes/1024/1024 desc;
12. 查询free space有多大
select tablespace_name, sum(Bytes)/1024/1024 || 'M' as 'SIZE', max(Bytes)/1024/1024 from dba_free_space group by tablespace_name order by 2 desc;
延迟段创建
延迟段允许在表创建时不立即分配存储空间,而是在第一次插入数据时才实际分配存储空间。
使用关键字"SEGMENT CREATION DEFERRED"指定延迟段创建。
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
) SEGMENT CREATION DEFERRED;
在数据库级别启用延迟段创建,默认情况下,它是禁用的。可以通过修改数据库参数来启用延迟段创建。
ALTER DATABASE DEFERRED_SEGMENT_CREATION = TRUE;
- 延迟段创建适用于以下情况:
- 需要创建大量的空表,但不希望立即分配存储空间。
- 对于临时表或短期使用的表,可以减少存储空间的浪费。
- 在表创建时,需要提高创建速度。
- 注:SYS用户下对象是不支持延迟段功能的。
CREATE TABLE employ ( employee_id NUMBER, first_name VARCHAR2(50), last_name VARCHAR2(50), hire_date DATE, salary NUMBER ) SEGMENT CREATION DEFERRED;
找所有的空表(未分配任何区的 表):
SELECT SEGMENT_CREATED,TABLE_NAME FROM USER_TABLES WHERE SEGMENT_CREATED = 'NO';

临时表的分类、创建语句、使用场景
临时表是在数据库中临时存储数据的表,它们在会话结束时自动删除。临时表可以用于存储临时数据、中间结果或者辅助计算。
根据其创建方式和使用范围,临时表分为以下两种类型:
全局临时表(Global Temporary Table):
- 创建语句:使用CREATE GLOBAL TEMPORARY TABLE语句创建。
- 特点:
在整个数据库会话期间都可见。
表的结构在会话之间共享,但数据是私有的。每个会话都可以独立插入、更新和删除数据。
当会话结束时,数据会自动删除。
- 使用场景:
在多个会话之间共享临时数据。
在复杂的查询中存储中间结果。
在数据加载过程中存储临时数据。
会话临时表(Private Temporary Table):
- 创建语句:使用CREATE PRIVATE TEMPORARY TABLE语句创建。
- 特点:
仅在创建它的会话中可见。
表的结构和数据都是私有的,只能在创建它的会话中访问。
当会话结束时,表和数据都会自动删除。
- 使用场景:
在单个会话中需要存储临时数据,但不希望与其他会话共享。
注:Oracle数据库并不直接支持创建本地临时表。
示例:
- 创建全局临时表:
注:ON COMMIT PRESERVE ROWS表示在提交事务时保留行数据。如果使用ON COMMIT DELETE ROWS,则在提交事务时删除行数据。
CREATE GLOBAL TEMPORARY TABLE temp_table ( column1 NUMBER, column2 VARCHAR2(50), column3 DATE ) ON COMMIT PRESERVE ROWS;

高水位问题
【说明】
对表高水位处理的方式进行研究,并对每种方式进行总结,最好是以图表的形式,下表只是参考,可以根据自己的理解进行修改。
表的高水位问题是指表中的数据已经被删除或更新,但是由于数据库的实现机制,表的物理存储空间并未被释放或回收,导致表占用的存储空间变大,而实际上已经没有数据占用这些空间。这种情况下,表的高水位会导致存储空间的浪费,影响数据库性能和查询速度。
高水位问题的原因可以是表中的数据被频繁删除或更新,但是数据库并不会立即回收被删除或更新的数据所占用的存储空间。这是因为数据库为了提高性能,在删除或更新数据时,通常只是将数据标记为已删除或已更新,而不是立即释放存储空间。这样做可以减少频繁的存储空间分配和释放操作,提高数据库的性能。
然而,当表中的删除或更新操作频繁发生时,高水位问题就会越来越严重,导致存储空间的浪费。
方式 | 方法说明 | 是否打开row movement | 是否需要重建索引 | 是否需要多余的空间 | 是否会导致业务中断 | 消耗时间 |
TRUNCATE | 删除表中的所有数据,但保留表结构 | No | No | No | Yes | 快 |
DELETE | 逐行删除表中的数据 | Yes | Yes | No | Yes | 慢 |
DROP | 删除整个表,包括表结构和数据 | N/A | N/A | N/A | Yes | 快 |
TRUNCATE + INSERT | 先使用TRUNCATE删除数据,再使用INSERT重新插入数据 | No | Yes | 需要额外的空间 | Yes | 中等 |
CREATE TABLE AS SELECT | 创建一个新表,将原表的数据插入到新表中 | No | Yes | 需要额外的空间 | Yes | 慢 |
与表相关的动态性能视图和数据字典
【说明】
对表相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
- DBA_TABLES视图:显示数据库中所有表的信息。
SELECT table_name, owner, num_rows, tablespace_name FROM dba_tables;
- DBA_TAB_COLUMNS视图:显示数据库中所有表的列信息。
SELECT table_name, column_name, data_type, data_length FROM dba_tab_columns;
- DBA_INDEXES视图:显示数据库中所有索引的信息。
SELECT index_name, table_name, uniqueness FROM dba_indexes;
- DBA_CONSTRAINTS视图:显示数据库中所有约束的信息。
SELECT constraint_name, constraint_type, table_name FROM dba_constraints;
- DBA_TAB_STATISTICS视图:显示数据库中所有表的统计信息。
SELECT table_name, num_rows, blocks, avg_row_len FROM dba_tab_statistics;
- V$SQL视图:显示数据库中正在执行的SQL语句的信息。
SELECT sql_id, sql_text, executions, buffer_gets FROM v$sql;
- V$SESSION视图:显示数据库中当前会话的信息。
SELECT sid, serial#, username, status FROM v$session;
索引相关
索引的类型
索引是数据库中用于提高查询性能的重要工具。它们是基于表的列或表达式的数据结构,可以加速数据的查找和访问。供服务器在表中快速查找一个行的数据库结构,是建立在表的一列或者多列上的辅助对象,
- B树索引:最常见的索引类型,适用于大多数查询场景。
适合与大量的增、删、改(OLTP);
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
- 唯一索引:确保索引列的值是唯一的。
- 聚簇索引:将数据物理上组织成与索引的顺序相匹配,常用于频繁按照范围进行查询的列。
- 位图索引:适用于低基数(取值较少)的列,如性别、状态等。
适合与决策支持系统;
做UPDATE代价非常高;
非常适合OR操作符的查询;
基数比较少的时候才能建位图索引;
- 函数索引:基于表达式的索引,可以对表达式的结果进行索引。
作用:
- 提高查询性能:通过减少数据访问的次数,加速查询操作。
- 加速排序和分组操作:对于需要排序或分组的查询,索引可以提供更快的执行速度。
- 强制唯一性:唯一索引可以确保索引列的值是唯一的,避免重复数据的插入。
创建语句:
创建B树索引:
CREATE INDEX index_name ON table_name(column_name);
CREATE INDEX idx_name_btree ON test(name);

创建唯一索引:
CREATE UNIQUE INDEX index_name ON table_name(column_name);
CREATE UNIQUE INDEX idx_name_unique ON test(name);

创建聚簇索引:
CREATE CLUSTER INDEX index_name ON table_name(column_name);
CREATE CLUSTER INDEX idx_name_cluster ON test(name);
创建位图索引:
CREATE BITMAP INDEX index_name ON table_name(column_name);

创建函数索引:
CREATE INDEX index_name ON table_name(function(column_name));

修改
1)重命名索引
alter index idx_name_btree rename to btree_index;
2)合并索引(表使用一段时间后在索引中会产生碎片,此时索引效率会降低,可以选择重建索引或者合并索引,
合并索引方式更好些,无需额外存储空间,代价较低)
alter index index_name coalesce;
3)重建索引
方式一:删除原来的索引,重新建立索引
方式二:alter index index_name rebuild;
- 删除
drop index index_sno;
查看
select index_name,index‐type, tablespace_name, uniqueness from all_indexes where
table_name ='tablename';
使用场景:
- 频繁进行等值查询的列适合创建索引,如主键、外键等。
- 经常用于连接操作的列可以创建索引,提高连接的性能。
- 需要排序或分组的列可以创建索引,加速排序和分组操作。
- 需要强制唯一性的列可以创建唯一索引,确保数据的唯一性。
- 低基数的列可以创建位图索引,提高查询速度。
注:过多的索引可能会增加写操作的成本,并占用额外的存储空间。因此,在创建索引时需要权衡查询性能和写操作的成本,并根据具体的查询需求和数据特征选择适当的索引类型和创建策略。
如何监控索引的使用情况
- ALTER INDEX MONITORING USAGE
ORACLE其实提供了监控索引使用情况的功能。可以监控包括索引的逻辑读取次数、物理读取次数、更新次数等。
ALTER INDEX <index_name> MONITORING USAGE;
注:启用索引的监控功能会带来一定的性能开销

- 使用AWR报告:
运行AWR报告,可以使用以下命令:@?/rdbms/admin/awrrpt.sql
在AWR报告中,查看"SQL Statistics"部分,可以找到索引相关的统计信息,如索引的读取次数、大小等。
- 使用SQL语句查询性能视图:
查询V$SEGMENT_STATISTICS视图,可以获取索引的逻辑读取和物理读取次数。
查询V$SQL视图,可以获取SQL语句的执行次数。
查询V$SQL_PLAN视图,可以获取SQL语句的执行计划,判断是否使用了索引。
- 监控慢查询日志:
配置慢查询日志,可以通过ALTER SESSION SET SQL_TRACE = TRUE;命令启用慢查询跟踪。
使用TKPROF工具分析慢查询跟踪文件,可以找出没有使用索引的查询语句。
- 使用Oracle Enterprise Manager(OEM):
在OEM中,可以查看数据库实例的性能指标,如物理读取次数、逻辑读取次数等,从而了解索引的使用情况。
在OEM的查询监控部分,可以查看执行计划,判断是否使用了索引。
- 使用第三方性能监控工具:
使用第三方性能监控工具,如Oracle Performance Analyzer(Statspack)、Oracle SQL Developer等,这些工具提供了更详细的性能分析和监控功能。
如何重建索引?什么情况下重建索引?
重建索引
重建索引是指删除现有索引并重新创建它,以修复或优化索引的性能
1. 确定需要重建的索引:通过监控索引的使用情况、性能问题或数据库优化需求,确定需要重建的索引。
2. 检查索引状态和依赖:使用以下查询语句检查索引的状态和依赖关系:
SELECT index_name, status, uniqueness, tablespace_name
FROM all_indexes
WHERE table_owner = '<owner>'
AND table_name = '<table_name>';

3. 创建索引备份:在重建索引之前,可以根据需要创建索引的备份,以防止意外情况发生。
CREATE INDEX <backup_index_name> ON <table_name> (<column_name>);

4. 删除现有索引:使用以下命令删除现有索引:
DROP INDEX <index_name>;

5. 重新创建索引:使用以下命令重新创建索引:
CREATE INDEX <index_name> ON <table_name> (<column_name>);
6. 检查索引状态:使用步骤2中的查询语句,再次检查索引的状态,确保索引已成功重建。
重建索引情况:
1. 索引碎片化:当索引碎片化严重时,重建索引可以提高查询性能。可以通过监控索引的碎片化程度或使用Oracle提供的索引维护工具来判断是否需要重建索引。
SELECT index_name, blevel, leaf_blocks, distinct_keys, clustering_factor FROM all_indexes WHERE table_owner = '<owner>' AND table_name = '<table_name>' AND index_name = '<index_name>';
2. 索引过度使用:当某个索引被频繁使用,但没有提供明显的性能提升时,可能需要重新评估并重建该索引。
3. 数据量变化:当表中的数据量发生较大变化时,索引可能需要重新构建以适应新的数据分布。
4. 索引设计优化:当索引的设计不合理或不满足查询需求时,可以通过重建索引来优化查询性能。
与索引相关的动态性能视图和数据字典
【说明】
对索引相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
- `DBA_INDEXES`:显示数据库中所有索引的信息。
SELECT index_name, table_name, index_type FROM dba_indexes;
- `DBA_IND_COLUMNS`:显示所有索引列的信息。
SELECT index_name, table_name, column_name FROM dba_ind_columns;
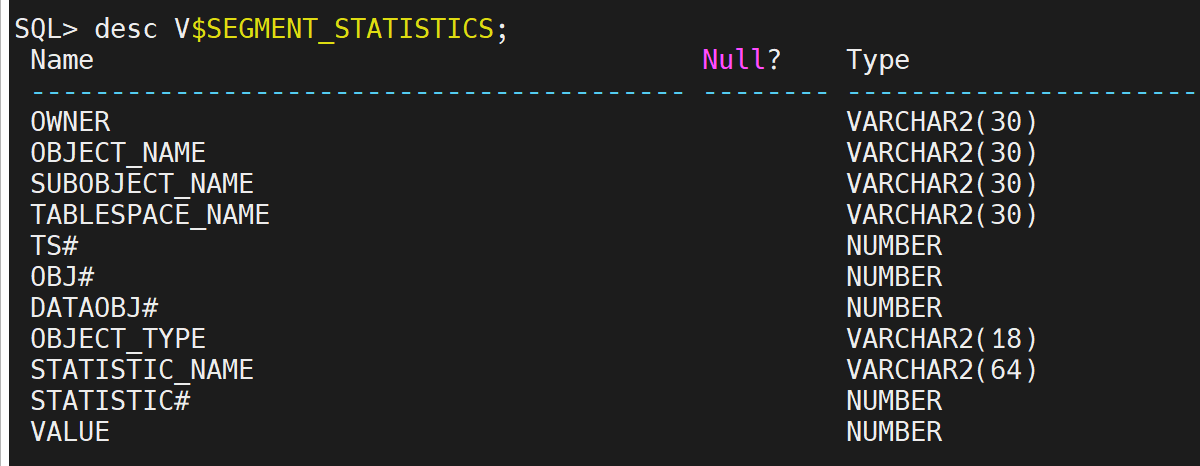
- `V$SEGMENT_STATISTICS`:显示索引段的统计信息。
- `ALL_INDEXES`:显示当前用户可访问的所有索引的信息。
SELECT index_name, table_name, uniqueness FROM all_indexes;
dblink
DBLink是Oracle数据库中的一个功能,用于在不同的数据库实例之间建立连接,以便在这些实例之间进行跨数据库的查询和操作。通过DBLink,可以在当前数据库中访问远程数据库的表、视图和存储过程,就像访问本地数据库一样。
分类
- private:创建的是用户级别的dblink,只有创建该dblink的用户才可以使用这个dblink来访问远程的数据库,同时也只有该用户可以删除这个dblink。
- public:创建的是数据库级别的dblink,本地数据库中所有的用户数据库访问权限的用户或者pl/sql程序都能使用这个dblink。
- global:创建的是网络级别的dblink,这是对于oracle network而言的。
创建dblink的方法
- 给予用户权限
grant CREATE PUBLIC DATABASE LINK,DROP PUBLIC DATABASE LINK to test;
查询权限
select * from user_sys_privs where privilege like upper('%DATABASE LINK%') AND USERNAME='test';
授予创建dblink的权限
grant create public database link to test;
- 创建
create public database link TESTLINK connect to test identified by "123456" USING 'ORCL'
- 删除
删除public类型的dblink
DROP PUBLIC DATABASE LINK dblink_name;
分布式事务了解
含义
分布式事务是指涉及多个数据库实例的事务操作。在分布式事务中,一个事务可以涉及多个数据库,并且必须保证事务的原子性、一致性、隔离性和持久性(ACID属性)。Oracle数据库提供了分布式事务管理的功能,可以通过DBLink实现跨数据库的事务操作。
组成部分
1. Client:调用其它数据库信息的节点
2. Database:接受来自其它节点请求的节点
3. Global Coordinator (GC):发起分布式事务的节点
4. Local Coordinator (LC):处理本地事务,并和其它节点通信的节点
5. Commit Point Site (CPS):被Global
6. Coordinator指定首先提交或回滚事务的节点
ORA-19706错误和_external_scn_rejection_threshold_hours参数了解

A库通过dblink访问B库数据,由于B库scn号增长过快,(dblink两段式提交,A库需要同步B库的scn),A库拒绝同步B库scn号,出现此提示。
- _external_scn_rejection_threshold_hours参数
是Oracle数据库中的一个参数,用于控制在备份过程中拒绝外部SCN的阈值时间。该参数指定了在多长时间内的外部SCN将被拒绝。默认情况下,该参数的值为24小时。如果备份过程中的外部SCN超过了阈值时间,则会引发ORA-19706错误。
- 查询_external_scn_rejection_threshold_hours参数的值
SELECT name, value FROM v$parameter WHERE name = '_external_scn_rejection_threshold_hours';
- 更改_external_scn_rejection_threshold_hours参数的值
ALTER SYSTEM SET "_external_scn_rejection_threshold_hours" = <new_value> SCOPE=BOTH;

与dblink相关的动态性能视图和数据字典
【说明】
对dblink相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
DBA_DB_LINKS 数据字典视图:
该数据字典视图包含了当前数据库中定义的所有数据库链接的信息。
SELECT * FROM DBA_DB_LINKS;
V$DBLINK 动态性能视图:
该动态性能视图提供了当前会话中使用的数据库链接的信息。

ALL_DB_LINKS 数据字典视图:
该数据字典视图包含了当前用户有权限访问的所有数据库链接的信息。
SELECT * FROM ALL_DB_LINKS;
物化视图
物化视图是包括一个查询结果的数据库对像,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照。
通常情况下,物化视图被称为主表(在复制期间)或明细表(在数据仓库中)。
物化视图的分类
主键物化视图和ROWID物化视图
创建
- 主键物化视图
主键物化视图是默认的物化视图。在复制环境下,如果主键物化视图是作为物化视图组的一部分建立 的,如果指定了FOR UPDATE语句,那么这个物化视图是可更新的,且这个物化视图组必须和主站点 中复制组的同名。
create materialized view log on emp;
- ROWID物化视图
ROWID物化视图基于主表对象中行记录的物理标识ROWID。在复制环境,ROWID物化视图只被用在基于Oracle7版本的主对象的物化视图,它不能被用于建立基于Oracle8或更高版本主站点的物化视图。
物化视图的维护
物化视图使用时基本等同于数据库表,主键、索引均可创建,如使用增量刷新,可能导致基表进行 DML时效率降低。在子查询关联逻辑复杂,查询非常慢时,可将子查询单独拿出来,建一个物化视图,再由原查询关联此物化视图提升效率,不建议使用物化视图完全替代普通视图。
- 刷新
手动刷新:可以使用 DBMS_MVIEW.REFRESH 过程来手动刷新物化视图。
EXEC DBMS_MVIEW.REFRESH('materialized_view_name');
自动刷新:创建定时任务或使用调度程序来自动刷新物化视图。
create procedure REFRESH_TEST_MVIEW as
begin
dbms_mview.refresh('test_mview');
end;
查询重写的使用
查询重写(Query Rewriting)是一种优化技术,它可以将复杂的查询转换为等效但更高效的查询。查询重写可以通过改变查询的结构、表达式或连接方式来提高查询性能。
- 使用内联视图(Inline Views): 内联视图是将子查询嵌入到主查询中的一种方式,可以将复杂的查询转换为更简单的查询。内联视图可以提供更好的查询性能,因为它可以减少查询的复杂度和执行时间。
示例:
SELECT *FROM (SELECT column1, column2 FROM table1 WHERE condition) AS inline_viewWHERE inline_view.column1 = value;
- 使用物化视图(Materialized Views): 物化视图是预先计算和存储的查询结果集,可以提供快速的查询性能。通过使用物化视图,可以将复杂的查询转换为简单的查询,并利用物化视图的索引和分区等优化功能。
示例:
SELECT *FROM materialized_viewWHERE condition;
- 使用子查询优化(Subquery Optimization): 子查询是嵌套在主查询中的查询语句,可以通过优化子查询来提高查询性能。可以使用连接、内联视图或物化视图等方法来优化子查询。
示例:
SELECT *FROM table1WHERE column IN (SELECT column FROM table2 WHERE condition);
与物化视图相关的动态性能视图和数据字典
【说明】
对物化视图相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
- DBA_MVIEWS:该视图列出了数据库中的所有物化视图的信息。
SELECT mview_name, owner, refresh_method, refresh_modeFROM dba_mviews;

- DBA_MVIEW_ANALYSIS:该视图列出了物化视图的分析信息。
SELECT mview_name, last_analyzed, next_analyzed, analyze_duration FROM dba_mview_analysis;
- DBA_MVIEW_LOGS:该视图列出了物化视图的日志信息。
SELECT mview_name, log_table, log_owner, log_rows FROM dba_mview_logs;
表空间
表空间的类型、作用、创建语句
系统表空间(System Tablespace)
系统表空间是 Oracle 数据库中最重要的表空间之一,它包含了系统元数据和数据字典信息。系统表空间在数据库创建时自动创建,用于存储数据库的核心组件和系统对象。
- SYSTEM :用于存放表空间名称、数据文件等管理数据库自身需要的信息
- SYSAUX:SYSTEM表空间的辅助空间,用以减少SYSTEM表空间的负荷
- 特性:不能脱机 offline; 不能置为只读 read only; 不能重命名; 不能删除
用户表空间(User Tablespace):
用户表空间用于存储用户创建的表、索引、视图和其他数据库对象。每个用户都可以有一个或多个用户表空间,用于存储其数据和对象。用户表空间可以通过创建和管理用户来分配给特定的用户。
临时表空间(Temporary Tablespace):
临时表空间用于存储临时数据,例如排序和临时表的数据。临时表空间的数据在会话结束时被自动删除,用于支持临时操作的临时表空间通常被多个用户共享。
回滚表空间(Undo Tablespace):
回滚表空间用于存储事务的回滚信息。回滚表空间用于支持数据库的事务一致性和回滚操作,以及提供读一致性的能力。每个数据库至少需要一个回滚表空间。
临时回滚表空间(Temporary Undo Tablespace):
临时回滚表空间是 Oracle 12c 新引入的概念,用于存储临时表空间的回滚信息。它可以提供更好的性能和可管理性,特别是在使用大型临时表时。
恢复目录表空间(Recovery Catalog Tablespace):
恢复目录表空间是用于备份和恢复的特殊表空间。它用于存储 RMAN(Recovery Manager)备份和恢复操作的元数据信息。
创建
CREATE smallfile/bigfile/temporary/undo TABLESPACE name
DATAFILE '/path/to/small_ts.dbf' SIZE 100M [DATAFILE 'file_path' SIZE file_size] [AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED]
extent management local/dictionary;
name:表空间名称。/path/to/small_ts.dbf:数据文件路径和名称。SIZE 100M:初始数据文件大小为100MB。
AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED:允许自动扩展,每次增加100MB,最大大小无限制。
extent management local/dictionary:本地管理/字典管理扩展。

undo表空间
undo表空间的作用
用于存储事务的回滚信息。当一个事务执行时,数据库会将事务所做的修改操作记录在 Undo 表空间中的回滚段中。如果事务需要回滚或者其他事务需要读取一致性视图,Oracle 可以使用 Undo 表空间中的回滚信息来提供读一致性和回滚操作。
undo表空间相关的参数
【说明】
对undo_retention、_undo_autotune等与undo表空间参数的说明、作用进行说明
undo_retention:这个参数用于指定事务的回滚信息在 Undo 表空间中的保留时间(以秒为单位)。当事务提交后,它的回滚信息将在 Undo 表空间中保留一段时间,以支持读一致性和长时间的回滚操作。较长的保留时间可以提供更长的读一致性,但会增加 Undo 表空间的使用量。
_undo_autotune:这个参数用于启用或禁用 Undo 自动调整功能。当该参数设置为 TRUE 时,Oracle 会自动调整 Undo 表空间的大小,以满足 undo_retention 参数指定的保留时间。自动调整功能可以根据系统的负载情况和 Undo 表空间的使用情况来动态调整 Undo 表空间的大小。
ORA-01555的由来

- 由于回滚段是循环使用的,当事务提交以后,该事务占用的回滚段事务会被标记为非活动,回滚段空间可以被覆盖重用。那么一个问题就出现了,如果一个查询需要使用被覆盖的回滚段构造前镜像实现一致性读,那么此时就会出现Oracle的ORA-01555错误。
解决:增加UNDO表空间大小,优化出错的SQL,或者避免频繁地提交。
- ORA-01555错误的另外一个原因是因为延迟块清除(Delayed Block Cleanout)。当一个查询触发延迟块清除时,Oracle需要去查询回滚段获得该事务的提交SCN,如果事务的前镜像信息已经被覆盖,并且查询SCN也小于回滚段中记录的最小提交SCN,那么Oracle将无从判断查询SCN和事务提交SCN的大小,此时出现延迟块清除导致的ORA-01555错误。
- 另外一种导致ORA-01555错误的情况出现在使用sqlldr直接方式加载(direct=true)数据时。当通过sqlldr direct=true 方式加载数据时,由于不产生重做和回滚信息,Oracle直接指定Cached Commit SCN 给加载数据,在访问这些数据时,有时会产生ORA-01555错误。
undo表空间相关的动态性能视图、数据字典
【说明】
对undo表空间相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
- V$UNDOSTAT视图:提供有关undo表空间的统计信息,如回滚段的活动和性能。
SELECT * FROM V$UNDOSTAT;
- DBA_TABLESPACES数据字典视图:提供有关数据库中所有表空间的信息,包括undo表空间。
SELECT * FROM DBA_TABLESPACES WHERE CONTENTS = 'UNDO';
- DBA_ROLLBACK_SEGS数据字典视图:提供有关数据库中所有回滚段的信息,包括undo表空间中的回滚段。
SELECT * FROM DBA_ROLLBACK_SEGS;
- V$ROLLSTAT视图:提供有关回滚段的统计信息,包括undo表空间中的回滚段。
SELECT * FROM V$ROLLSTAT;
- DBA_UNDO_EXTENTS数据字典视图:提供有关undo表空间中的undo段扩展的信息。
SELECT * FROM DBA_UNDO_EXTENTS;
temp表空间
temp表空间的作用
用于存储临时数据和临时结果集
- 排序操作:当执行需要对大量数据进行排序的查询时,Oracle会使用Temp表空间来存储排序操作的中间结果。排序操作通常涉及将数据按照特定的列或表达式进行排序,然后返回有序的结果集。
- 连接操作:当执行需要对多个表进行连接的查询时,Oracle会使用Temp表空间来存储连接操作的中间结果。连接操作通常涉及将多个表中的数据按照特定的关联条件进行连接,然后返回连接后的结果集。
- 临时表的创建:当创建临时表时,Oracle会使用Temp表空间来存储这些临时表的数据。临时表是在会话级别上存在的临时表,用于存储中间结果或临时数据,通常用于辅助查询和计算。
ORA-1652问题处理
ORA-1652: unable to extend temp segment by 128 in tablespace
- 检查Alert Log
- 检查当前数据库的临时表空间的大小,状态和是否开启自动扩展如下
select file_name,file_id,bytes/1024/1024/1024,status,autoextensible TABLESPACE_NAME from DBA_TEMP_FILES;
如果确认已开启自动扩展且已知表空间大小,则判断当时数据库的动作有无超过TEMP最大空间,即可定位至异常的原因
目前tablespace='TEMP'总大小为32*2=64GB
- 错误定位
根据配置可知,数据库单次获取的数据量应该小于64GB,否则就会出现TEMP表空间不足的情况,查询在异常时间段内,占用资源超过60GB的SQL
可以从awr文件中查看引起物理读的前几名SQL
查看对应sql_id的SQL
- 优先确认相关的SQL具体的功能,判断是否为系统异常操作
如果是异常操作导致,则忽略不计
如果为系统正常操作导致,则判断是否需要新增TEMP表空间
- 如果表空间太小的话,可以通过语句增加:
ALTER TABLESPACE TEMP ADD TEMPFILE '/u01/app/oracle/oradata/orcl/temp02.dbf' SIZE 10240M AUTOEXTEND OFF;
temp表空间相关的动态性能视图、数据字典
【说明】
对temp表空间相关的动态性能视图和数据字典进行了解、说明、编写相对应的查询语句
- v$tempfile:该视图显示了数据库中所有临时表空间的临时数据文件的信息。
SELECT *FROM v$tempfile;
- dba_temp_files:该数据字典视图显示了数据库中所有临时表空间的临时数据文件的信息。
SELECT *FROM dba_temp_files;
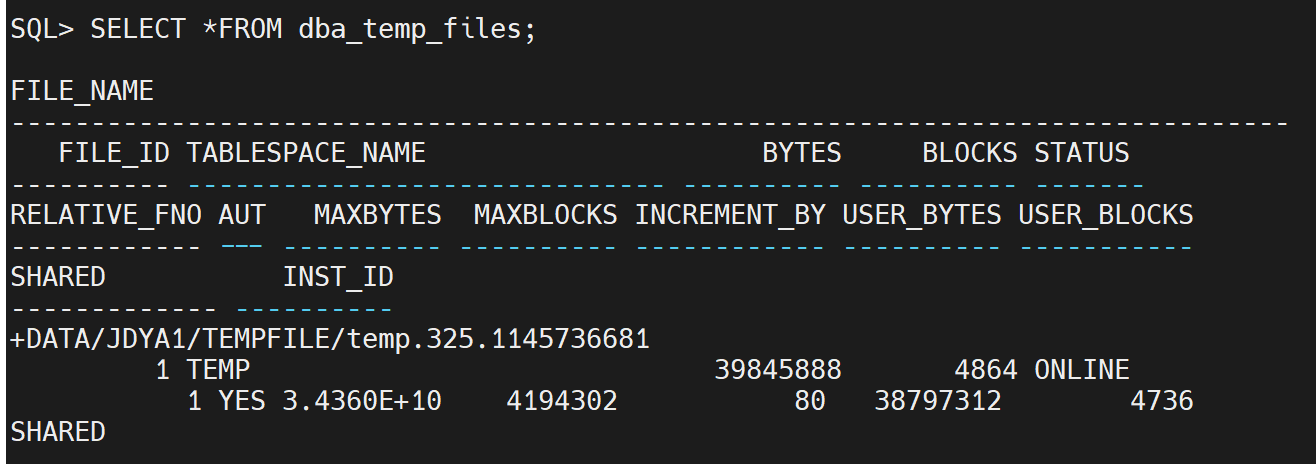
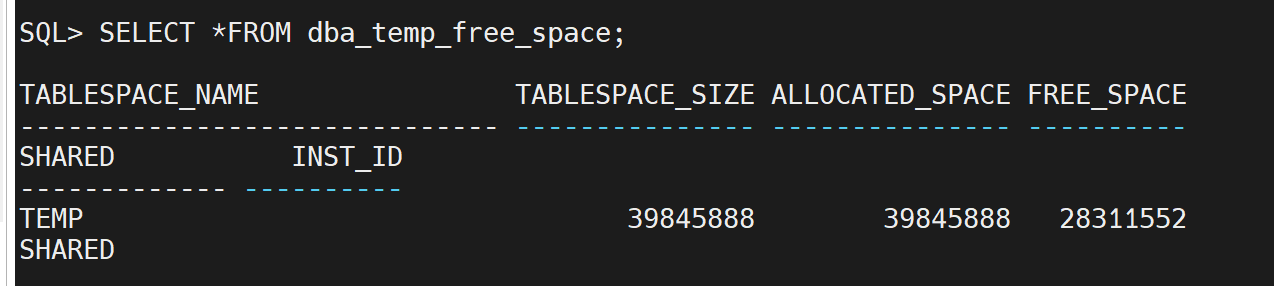
- dba_temp_free_space:该数据字典视图显示了临时表空间中的可用空间的信息。
SELECT * FROM dba_temp_free_space;
总结
很多内容还没有理解,后面需要多花时间去了解,然后一些测试没有完成,只是编写了命令,也不够规范,只测试了命令,没有进行系统的测试,后面会慢慢完善。
