




NUMA架构下的CPU和内存分布
https://zhuanlan.zhihu.com/p/643610982
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
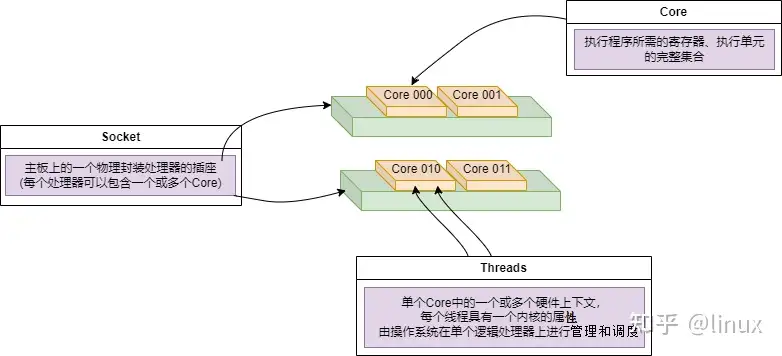
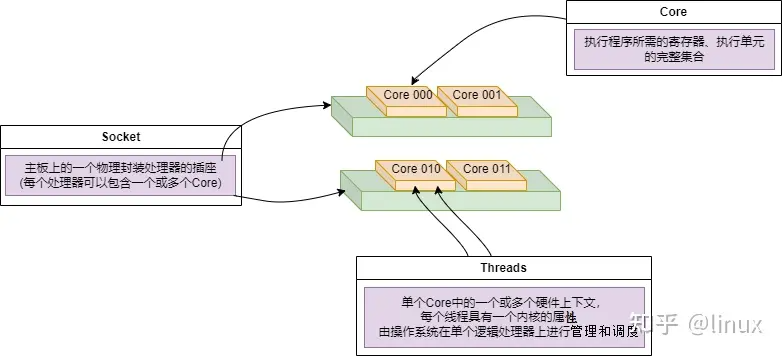
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
- Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
- Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
- Node:即NUMA Node,包含有若干个 CPU Core 的组。
Socket、Core和Threads之间的关系示意如下:
在Linux系统中,可以用lscpu查看NUMA和CPU的对应关系:
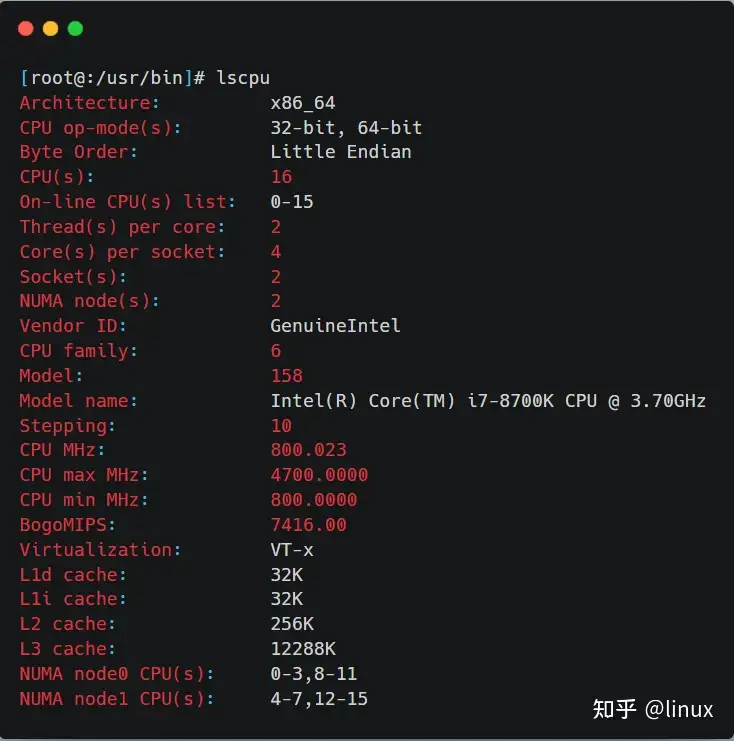
从上图可以看到,这台服务器有两个NUMA node,有两个Socket,每个Socket也就是一个物理CPU,有14个逻辑Core,每个逻辑Core有两个线程(服务器开启了超线程),所以总共的CPU个数(以超线程计数)为:2*14*2 = 56个。
使用numactl -H命令可以看到NUMA下的内存分布:
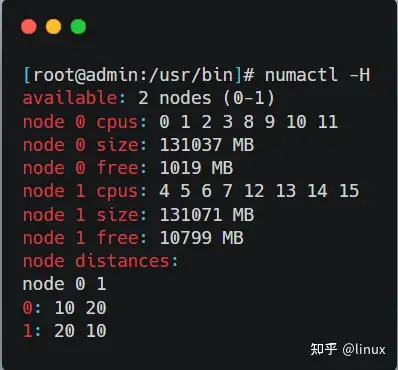
所以这台服务器上CPU和内存在NUMA下的分布如下:
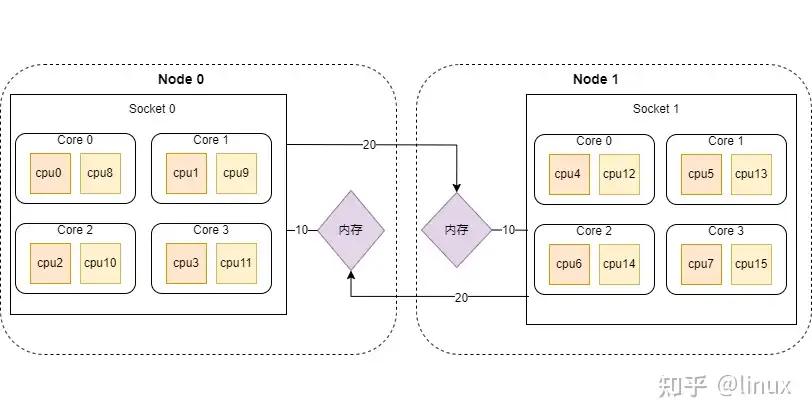
NUMA架构下的CPU,先从逻辑Core开始编号,如果开启了超线程,就从Core总数的后面继续编号,例如上图中从cpu8开始之后的都是开启超线程之后的CPU线程。
另外,在实际编程中,我们还可以通过numastat命令查看NUMA系统下内存的访问命中率:
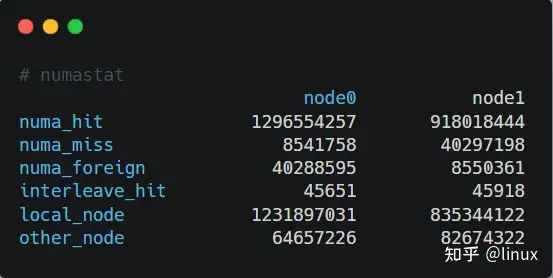
- numa_hit:成功分配给此节点的页面数量。
- numa_miss:由于预期节点上的内存较低,在此节点上分配的页面数量。每个 numa_miss 事件在另一个节点上都有对应的 numa_foreign 事件。
- numa_foreign:最初用于分配给另一节点的页面数量。每个 numa_foreign 事件在另一节点上都有对应的 numa_miss 事件。
- interleave_hit:成功分配给此节点的交集策略页面数量。
- local_node:此节点上的进程在这个节点上成功分配的页面数量。
- other_node:通过另一节点上的进程在这个节点上分配的页面数量。
如果miss值和foreign值越高,就要考虑线程绑定以及内存分配使用的问题。
需要注意的是,NUMA Node和socket并不一定是一对一的关系,在AMD的CPU中,可能更多见于NUMA Node比socket个数多(一般AMD的CPU的NUMA可以在BIOS中进行配置),而Intel的CPU中,NUMA Node可能比socket的个数还少。NUMA架构下的CPU和内存分布
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
- Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
- Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
- Node:即NUMA Node,包含有若干个 CPU Core 的组。
Socket、Core和Threads之间的关系示意如下:
在Linux系统中,可以用lscpu查看NUMA和CPU的对应关系:
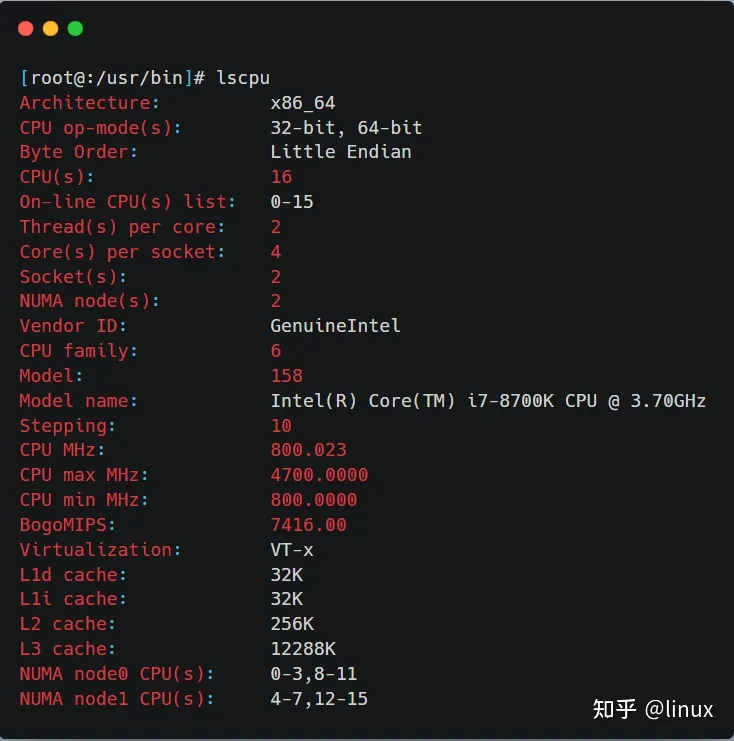
从上图可以看到,这台服务器有两个NUMA node,有两个Socket,每个Socket也就是一个物理CPU,有14个逻辑Core,每个逻辑Core有两个线程(服务器开启了超线程),所以总共的CPU个数(以超线程计数)为:2*14*2 = 56个。
使用numactl -H命令可以看到NUMA下的内存分布:
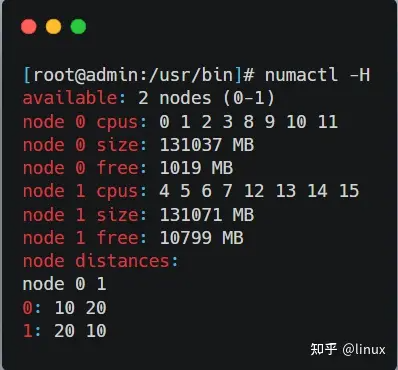
所以这台服务器上CPU和内存在NUMA下的分布如下:
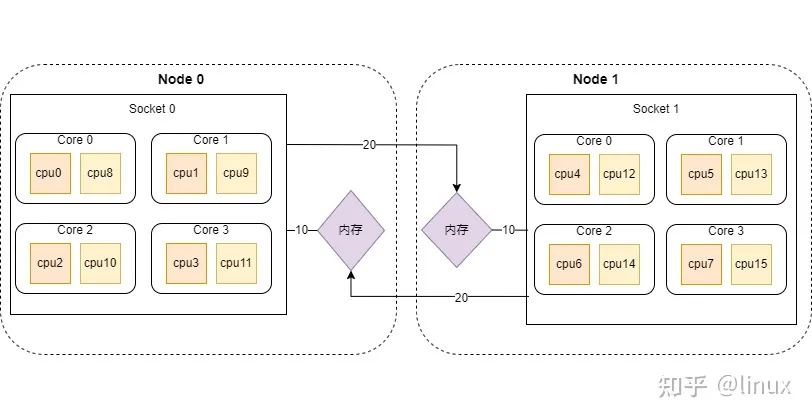
NUMA架构下的CPU,先从逻辑Core开始编号,如果开启了超线程,就从Core总数的后面继续编号,例如上图中从cpu8开始之后的都是开启超线程之后的CPU线程。
另外,在实际编程中,我们还可以通过numastat命令查看NUMA系统下内存的访问命中率:
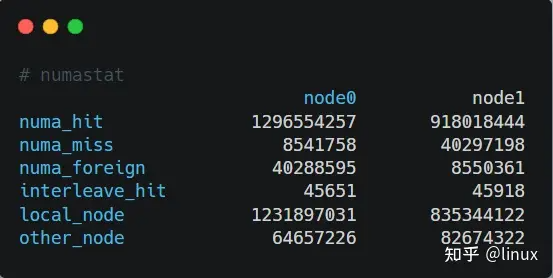
- numa_hit:成功分配给此节点的页面数量。
- numa_miss:由于预期节点上的内存较低,在此节点上分配的页面数量。每个 numa_miss 事件在另一个节点上都有对应的 numa_foreign 事件。
- numa_foreign:最初用于分配给另一节点的页面数量。每个 numa_foreign 事件在另一节点上都有对应的 numa_miss 事件。
- interleave_hit:成功分配给此节点的交集策略页面数量。
- local_node:此节点上的进程在这个节点上成功分配的页面数量。
- other_node:通过另一节点上的进程在这个节点上分配的页面数量。
如果miss值和foreign值越高,就要考虑线程绑定以及内存分配使用的问题。
需要注意的是,NUMA Node和socket并不一定是一对一的关系,在AMD的CPU中,可能更多见于NUMA Node比socket个数多(一般AMD的CPU的NUMA可以在BIOS中进行配置),而Intel的CPU中,NUMA Node可能比socket的个数还少。
