





行业诉求
首先,传统经代公司的运营效率低下;
其次,传统的代理公司并没有完善的数字化管理系统支持;
最后,运营成本居高不下,保险公司为此需要承担 40%甚至更高的渠道费用。
来自车辆终端所发送过来的数据大多是时序数据,需要数据库具备针对时序数据的高效存储和分析能力;
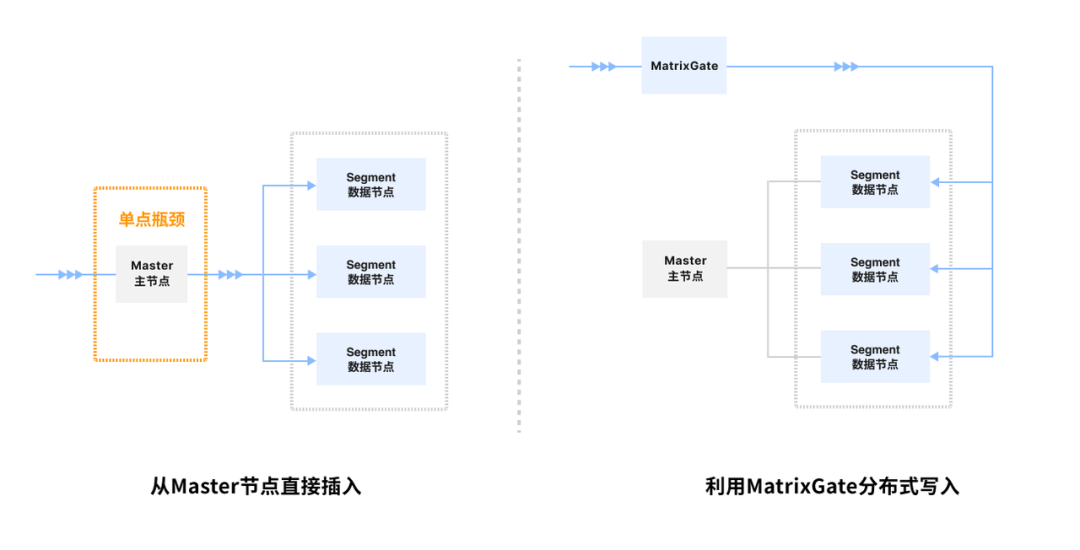
车联网场景下的数据量通常都非常大,只要有车辆处于行驶状态下,相关数据就会源源不断的涌入到数据库当中,因此在写入场景中对数据库的吞吐性能要求很高;
数据库需要具备将已有数据同参保算法结合,并计算出结果的能力,将这些数据直接赋能于业务;
具备一定的系统兼容能力,能够在已有技术栈的基础上进行迁移,不额外增加技术人员的学习成本。

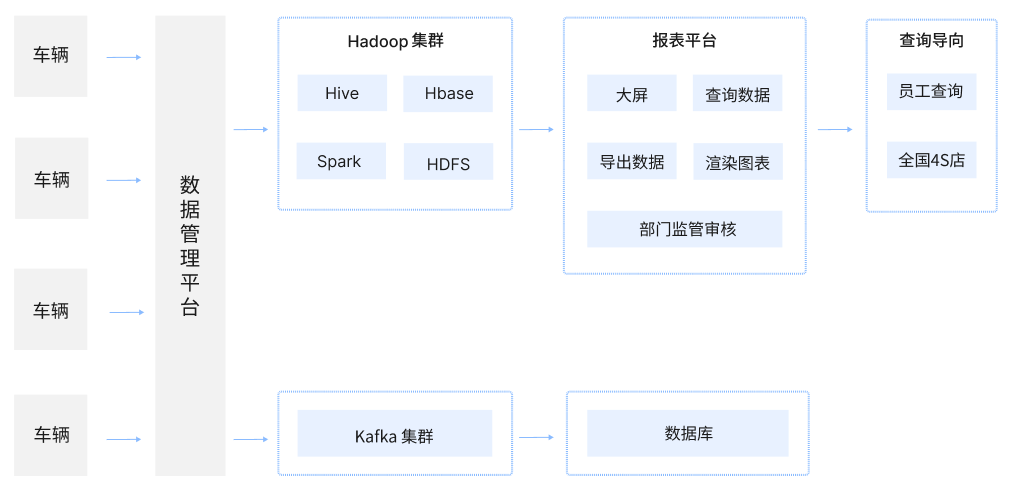
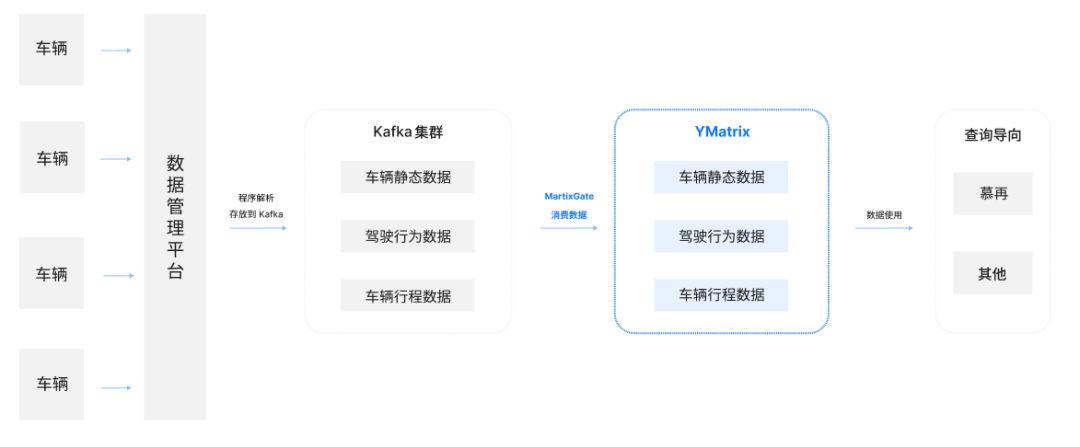
首先,车辆状态的密文数据被上报到管理平台后,解析程序根据密文规则进行解密,得出车辆品牌、运行状态、驾驶时长、刹车次数等静态数据,将这些历史数据合并为报表并存放在 Hadoop 当中,随时供监管部门审核使用;
其次,通过 Spark 计算各种报表指标,例如每季度每个品牌每个类型的销售量、发动机故障状态码等,并把结果数据保存到 Hbase 中,供报表平台查询使用;
最后,程序进行解析后将数据存放在生产 Kafka 集群中并保存 3 天,随后同步至后端数据库。

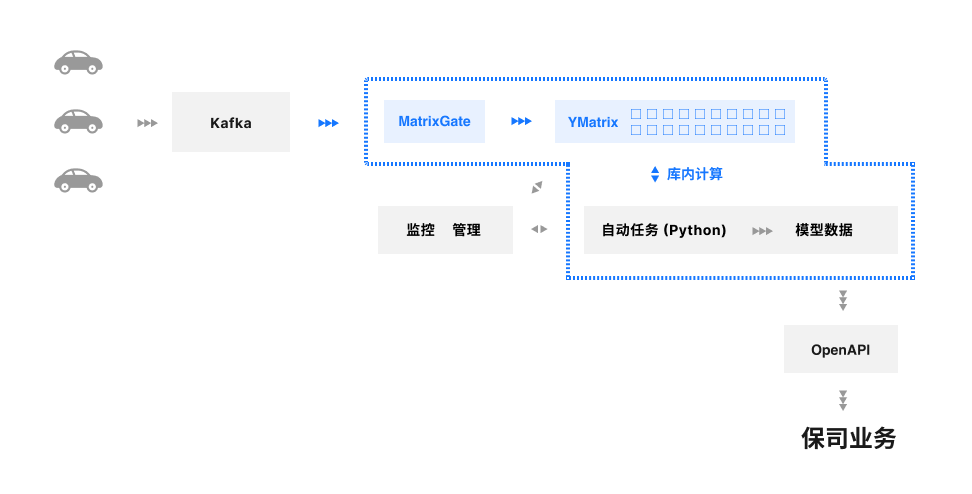
高性能时序能力完美适配车联网场景
YMatrix 高性能时序能力,对存储集群中的静态、驾驶行为、车辆行驶等数据进行整合分析,全方位支撑平台的海量数据存储和复杂分析需求;
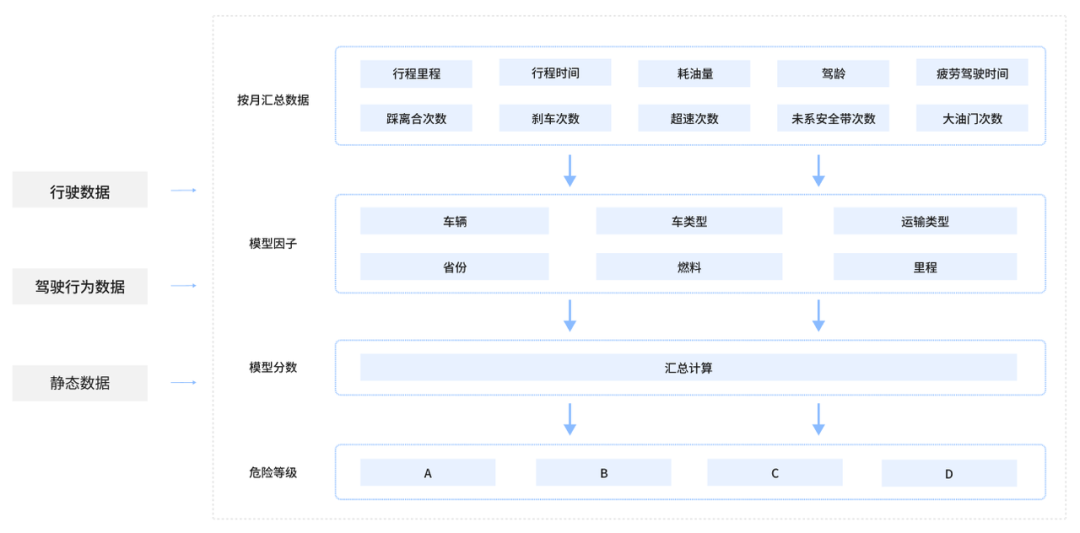
静态数据为车辆基本特征数据,如车轴距、销售日期、购买渠道、车架号等;
驾驶行为数据包含油门开度、是否系安全带、超速级别、刹车时长等,30 秒上报一次数据;
车辆行驶数据包含保安形成编号、刹车累计里程、怠速运行时间、离合的刹车次数等,数据 30s 上报一次。
库内机器学习能力支撑海量时序数据分析
库内机器学习,功能丰富,不仅易用更能充分利用集群算力,可快速计算出参保用户的危险等级,依托数据指标为不同用户提供定制化的参保服务;
随后,某保险集团车险部门将 20 万条车辆数据通过 web 平台解析后同步至 YMatrix 中,其中数据的三个字段分别为 vin 码、保费以及保额。通过 YMatrix 数据库内强大的机器学习能力,YMatrix 能够对已被写入的数据进行计算与分析,并与某保险集团车险部门的 vin 码进行关联并得出最终结果。
另一方面,Python 作为全球流行的开发语言之一,其被广泛应用于数据挖掘领域,对于此次车险数字化运营平台建设而言同样如此。YMatrix 支持 PL/Python、PL/R,使用 Python、R、C 等语言实现存储过程,并支持常用的 Python/R 函数库,在数据库内实现高效数据处理和机器学习。用不但保障了原有业务计算逻辑能够平滑迁移至YMatrix,后续新业务、新算法的开发仍然能够继续使用原有的Python技术栈,进一步降低了用户使用 YMatrix 的技术门槛。

此外,在我们将视野放大到整个金融生态当中,可以发现金融产业中正在涌现出各式各样的细分业务场景。面对不同业务场景的不同需求,企业往往需要将更多的时间花费在数据库选型、功能取舍等前期工作上,这样所带来的结果往往是底层部署有许多不同的数据库,在后续运维管理上造成了相当复杂的局面。加之来自信创、数字化方面的压力逐渐增大,企业需要一套能够统一运行在各类场景下并优秀完成各项任务的融合型数据库。
一条有爱的分割线
感谢你的阅读,YMatrix 期待与志同道合的你一起同行。




