






云原生数据库在设计之初是为了降低数据库实例自身产生的资源费用和实例的运维成本,基于云计算自身资源池化技术以及云原生技术的快速发展,云数据库实例资源费用相较于传统数据库已经有了大幅下降,高效快捷的自动扩缩容能力也让数据库实例的运维得以简化。但是由于数据库系统本身的复杂性,特别是分布式数据库多机多线程的并行执行模型的特性,再加上基于数据库构建的上层应用的多样性、时变性等特征,使得云数据库实例的问题诊断和性能调优仍然面临着巨大的挑战。
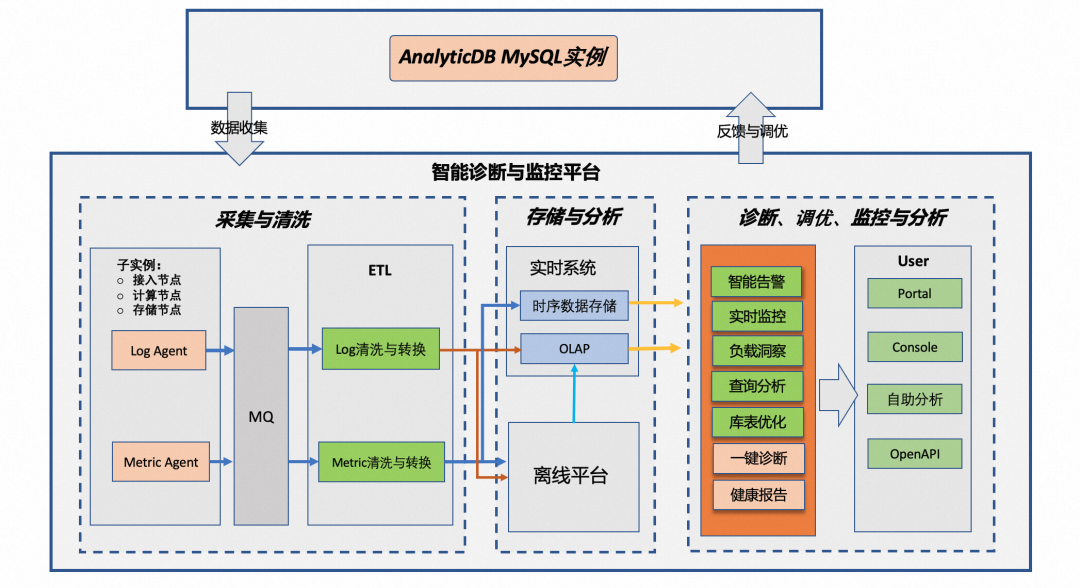
用户业务指标恶化或者资源水位非预期的增高,这时用户往往需要切换到诊断调优页面找到问题时段对应的BadSQL或者BadPattern,找到“嫌疑”SQL后又需要切回到监控页面进行重复验证。
AnalyticDB MySQL目前的查询性能较为依赖用户建表是否合理,涉及表数据是否均匀分布以及分区大小是否合理等,但是用户在业务上线的起步阶段,是很难创建一个最优表结构的,虽然AnalyticDB MySQL也提供了对于建表的诊断,但是随着业务的发展和数据量的增大,用户往往不清楚问题时段哪些“不合理”的表导致了问题的出现,也不清楚这些“不合理”的表产生的影响如何衡量。
用户通过AnalyticDB MySQL提供的单查询执行计划、查询自诊断以及实时Pattern分析,可以深入分析一条或者一类复杂查询的耗时和资源消耗,最终定位出某一个算子出现问题。但是往往是多个不同查询的某一类算子出现问题影响了实例的稳定性,用户往往需要在多个执行计划页面查找问题算子,人工进行比较,诊断过程低效。
针对以上用户痛点问题,AnalyticDB MySQL智能诊断团队设计并研发了一键诊断功能,实现了:
● 跨查询的异常Pattern和异常算子自动检测。
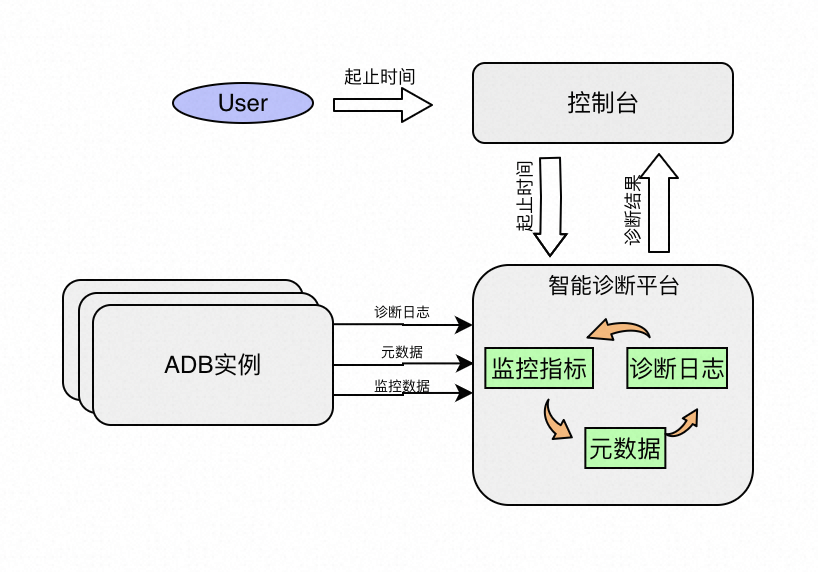
一键诊断工具在设计之初,总结分析了线上各类Top问题,并结合AnalyticDB MySQL实例的自身架构特征,提供了四个大项的检测,包括:BadSQL检测、异常Pattern检测、计算节点检测和存储节点检测,每个大的检测项又包含了多个子项,通过一键诊断,可以对问题时段的AnalyticDB MySQL实例做一个自上而下的、从内到外的全面的检查。而用户触发一键诊断的方法,我们做到了极致的简便,即用户只需要在想分析的监控指标上拖动选择问题时段,点击“一键诊断”按钮,即可完成一键诊断。 接下来针对一键诊断的各个功能点来进行详细的功能描述和设计思路的介绍。
3.1 BadSQL检测
BadSQL一直是影响实例稳定运行的一大因素。用户数据库实例遇到BadSQL,一般有如下三种情况:
新业务上线前都会在测试实例进行验证,但是一般在非生产环境只能验证功能的正确性,当新SQL在生成环境执行,可能因为读取的数据量差异较大,导致下游处理消耗资源较大,或者导致执行计划产生变化,都可能产生BadSQL。
针对复杂SQL,AnalyticDB MySQL强依赖统计信息选择最优Join顺序或者决定特定算子的优化方法,如果统计信息过期,可能影响SQL产生最优执行计划,从而导致BadSQL的产生。
用户在进行数据探索时,往往使用临时查询来挖掘数据特征,但是临时查询往往没有经过验证,消耗大量资源,很可能成为BadSQL的来源。
AnalyticDB MySQL诊断分析平台根据影响实例稳定性的6项关键查询指标,在后台根据实例的历史运行情况设定各项指标的阈值,每项重要指标都使用阈值进行过滤,筛选TopN条查询。同时,会对筛选出的SQL在后台完成自诊断,每项自诊断结果都提供了相应的调优方法,用户可以在多个查询的自诊断结果间查看,来确认是否BadSQL都属于同一类问题。用户如果想深入分析当前查询,也可以通过“诊断”按钮跳转到查询的详情页面,查看执行计划,进行自助分析。

3.2 异常Pattern检测
selectcount(*), idfrom userwherecreate_time > '2023-09-08 00:00:00'and id>200group by id;
selectcount(*), idfrom userwherecreate_time > ?and id>?group by id;
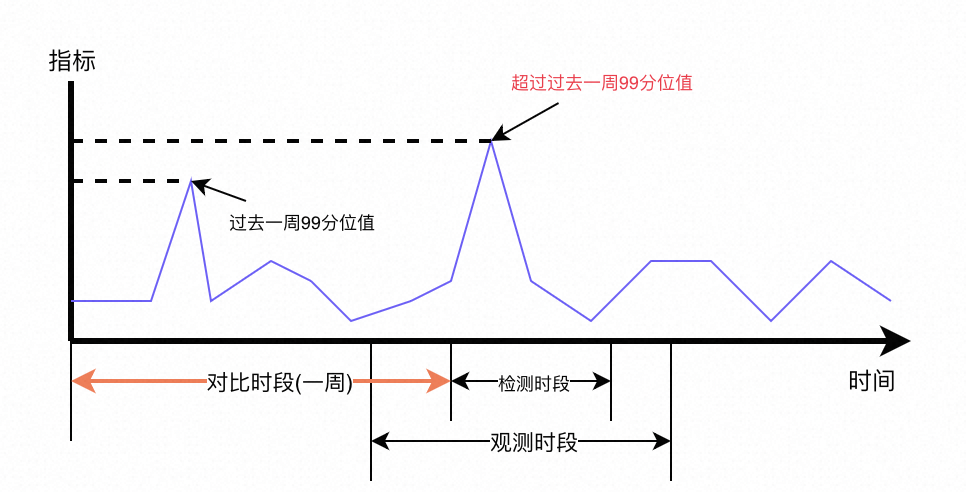

异常Pattern检测从5个维度完成对用户选定时段的所有Pattern进行检测:峰值内存、查询耗时、算子Cost、输出数据量以及提交次数。通过这些关键维度的自动检测,用户可以更加快捷的寻找到异常Pattern,通过WLM限流功能,拦截这类Pattern,快速恢复实例正常运行。
3.3 组件异常检测
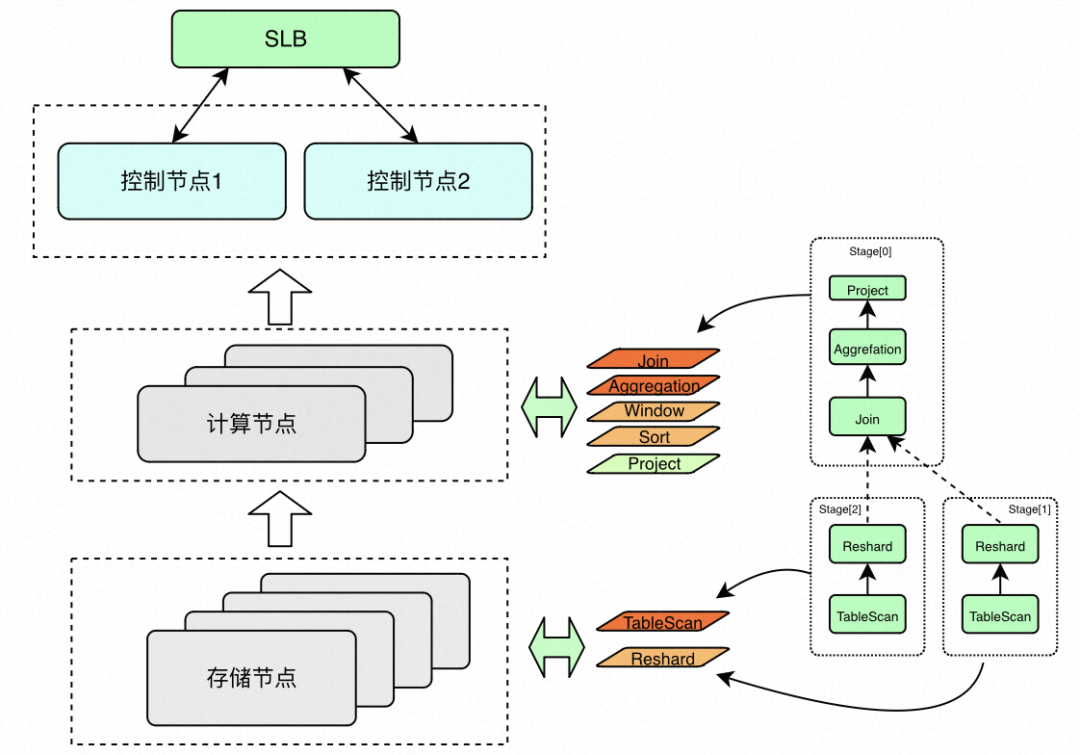
AnalyticDB MySQL实例由多个组件组成,多个组件之间相互协调工作来完成一条SQL的执行。当用户提交查询后,会把查询分发到实例的某一个控制节点,由控制节点完成SQL语句的解析、语法分析、执行计划生成等任务。生成的执行计划,由多个Stage组成,如下图所示,Stage[1]和Stage[2]主要完成表数据读取工作,所以这两个Stage内部的算子在存储节点内部并行执行。数据经过Reshard算子分发到下游Stage[0]后,有计算节点完成后续的计算逻辑,例如Join、Aggregation或者Project。每个算子在实际执行时,算子属性差异和算子消耗的资源差异,都会对相关组件造成不同的影响,主要包括:
● 算子输入输出输出量、算子消耗内存以及算子消耗CPU等(算子指标和资源消耗)
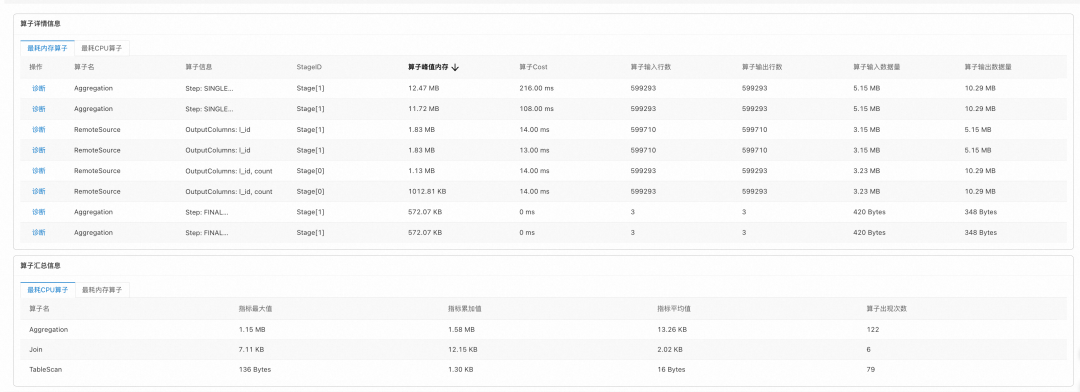
▶︎ 资源检测
● 资源组间水位不均评估;
● 资源组内水位不均评估;
● 整体水位评估。

▶︎ 不健康节点个数检测
当存储节点或者计算节点压力较大时,或者内部状态异常时,可能会导致这类节点状态不健康,无法提供正常的服务,导致查询失败或者查询变慢,不健康节点个数,会自动会检测时段的节点不健康个数进行检测,从而协助用户判断检测时段的异常原因。
AnalyticDB MySQL已经提供了实例级别的库表诊断功能,但是在实际的线上支持过程中我们发现,实例级别的库表检测结果,往往很难促使用户进行建表语句的调整,最终导致问题堆积,实例长期运行在崩溃的边沿。通过与用户的沟通我们总结出实例级别库表诊断的效果不佳主要存在以下问题:
● 用户存在忽视库表诊断结果的现象;
● 表倾斜检测
● 表分布不合理检测
● 表访问检测
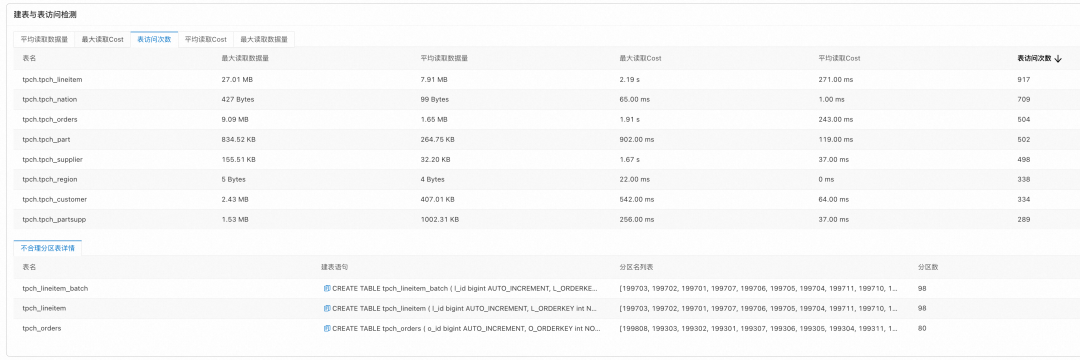
表访问检测会自动对检测时段内访问的表进行多项主要指标的检索,并对这些指标进行降序排列。包括数据读取量、数据读取累积耗时、表访问次数等。如果用户对原查询需要进行进一步分析,也可以点击原查询的“诊断”链接进行原始查询详细信息的查看。
AnalyticDB MySQL的分布式表需要用户选择一个分布比较均匀的字段来作为分布字段,AnalyticDB MySQL在数据写入时会根据这个分布字段进行数据的打散处理,写入到不同的存储节点上。当用户选择的分布字段不均匀时,就会存在表倾斜的情况出现。表倾斜检测功能共首先找到数据量最大的N个表,然后检测这些表是否存在数据倾斜。用户需要首选对这些倾斜的表进行优化,优化后不但可以提升查询性能,而且可以均衡磁盘空间的数据量,降低磁盘被锁定的风险。
AnalyticDB MySQL支持分区表,合理的分区不但可以提升查询性能,也可以降低存储节点压力,提升系统稳定性,但是用户往往存在分区粒度过大或者过小的问题,或者干脆创建一个不分区的大表。表分区不合理检测,会首先找到数据量最大的N个表,然后检测这些表是否存在分区不合理的情况,让用户在数据量维度进行调整优先级的划分。
诊断和监控并不是两个割裂的、独立的功能,二者没有主次之分和先后顺序之分,诊断结果需要监控数据验证,监控数据需要诊断结果修正,二者相辅相成。实例元数据也为诊断分析提供了重要的数据。但是在实例监控、查询诊断以及实例元数据等信息彼此割裂的时代,用户只能通过使用一个个独立的工具来进行问题分析,很多问题都需要有一定的实例维护经验才能完成离散信息的有效整合和综合分析。AnalyticDB MySQL的一键诊断功能正是在这个背景下研发的,我们在后台联合多种数据源进行实例级别的自动问题检测和发现,把低效的、手动的、单条SQL、指标的问题诊断向自动化、精准的问题诊断演进,对实例运行状态进行特征提取,抽取关键画像信息,希望能进一步降低云数据库的使用成本。目前该功能已经在各大region逐步开始灰度,配套使用文档也即将上线,我们会对收到的线上反馈第一时间进行修复和优化。
由于数据库自身的复杂性和其上层业务的复杂性,人工的问题发现和调优必然会带来巨大的成本,这和云计算降低用户成本的目标是相悖的。支持自治化是诊断监控系统发展的最终方向,也是云数据库的最终发展形态。因为可以进行统一的实例数据收集和分析,云数据库又天然的具备向自治化方向演进的能力,AnalyticDB MySQL诊断监控平台从无到有、从手动到自动、从自动到自治,让AnalyticDB MySQL在向自治化演进的道路上迈出坚实有力的步伐。
云原生数据仓库AnalyticDB MySQL免费试用



 点击 阅读原文 开启 AnalyticDB MySQL免费试用
点击 阅读原文 开启 AnalyticDB MySQL免费试用