





RDMA,估计大部分IT人对其都至少会有过一面之缘。不过在IT历年的发展过程中,大家习惯将注意力集中在计算的变革(如:从unix到linux,从闭源的小型机到通用架构的X86再到国产CPU)、存储的变革(从集中式存储到百家争鸣的分布式存储再到全SSD)。计算与存储之间互联技术,其实也默默地在这个变革的时代不断发展,而且在很多已落地的重要业务场景中,都可以看到他的身影。今天我们把他推到前台来,对他来个360度全身扫描。
要了解它,我们先从这项技术涉及到的业务场景说起。了解过这些场景的玩家,肯定在当时会有不少疑问:
场景一
超算平台——几百台HPC服务器并行计算,或者大量服务器的并行文件存储。

并行计算的特点一个是“算”,另外一个就是“并”。如何把大批量服务器计算完的结果,快速高效的并到一起,给前端返回一个完美的结果?这个互联技术一定得性能强悍且稳定才行吧?
场景二
公有云超高IO硬盘。

我们在公有云上面,购买云主机的硬盘的时候会发现,超高IO硬盘的价格,往往比普通硬盘,或者SSD硬盘都要贵不少。同样都在一朵云,一个AZ下面,性能为什么会有这么大的差距,为什么价格会有这么大的差别?
场景三
人工智能(深度学习、图像识别、自然语言处理等)

一些人工智能在线服务:作业识题、PDF转PPT、图片转文字的APP应用。为什么一个手写的题目,拍照后可以如此快速的在云端识别完成,并推送给你题目和解题答案?
当然,除此之外还有很多场景。当没有用到RDMA这项技术时(当然往往计算、存储能力也不足,),我们往往会发现这项业务的性能、体验总会差那么一点点。比如:
运营商话费月结为什么不是1号当天晚上出结果?一定要差不多半天或者更长时间?(多年前有可能要达到1-3天)
数据库SQL操作为什么要尽量避免全表扫描,或者跨表join?
这些疑问,我们先放在这里,在介绍完RDMA这项技术后,疑问也会随之而解。
我们先明确一个前提,千行百业的IT系统(or云计算平台)在这10年中获得的飞速的提升,计算算力、存储技术、运营商网络、应用技术架构都起到了关键性的作用。而 “计算存储互联技术”相比其他领域而言,重要性当然不可同日而语,它更像一个时代的跟随者,每当我们的计算存储飞速提升,它都能匹配上、且不掉链子。
话说回来,如果匹配不上,会出现什么状况?想象一下,你数据中心的几百台高性能HPC服务器,匹配只是一个个的万兆IP交换机,肯定无法满足诸如制造业仿真设计、生物领域的基因测序等场景的大规模并行计算需求。
那么,什么网络传输互联技术可以满足大规模并行计算、存储?什么场景下应该使用这种更高带宽,更低时延的集群互联网络?与这个技术所配套的相关技术选型、技术路线分支又是怎么样的?
我们把涉及到的技术进行一一介绍,然后再做总结:
RDMA 技术最早出现在 Infiniband 网络,用于 HPC 高性能计算集群的互联。传统的基于 socket 套接字(TCP/IP 协议栈)的网络通信,需要经过操作系统软件协议栈,数据在系统 DRAM、处理器 CACHE和网卡 buffer 之间来回拷贝搬移,因此占用了大量的 CPU 计算资源和内存总线带宽,也加大了网络延时。
举例来说, 40Gbps 的 TCP 流,能耗尽主流服务器的所有 CPU 资源。RDMA 解决了传统 TCP/IP 通信的技术痛点:40Gbps 场景下, CPU 占用率从 100%下降到 5%,网络延时从 ms 级降低到 10us 以下。RDMA 是一种新的内存访问技术, RDMA 让计算机可以直接存取其他计算机的内存,而不需要经过处理器耗时的处理。RDMA 将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响。RDMA 技术的原理及其与 TCP/IP 架构的对比如下图所示。
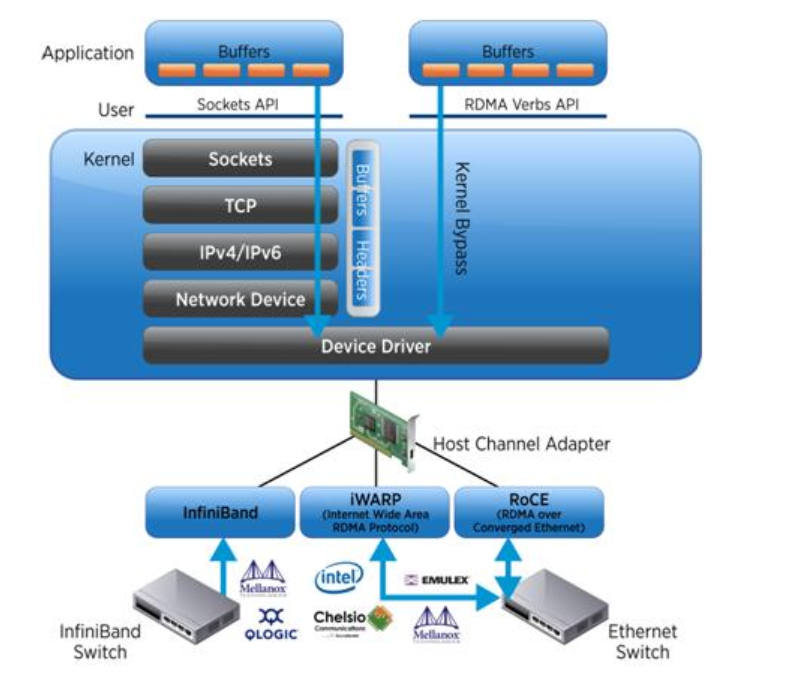
技术优势:
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将RDMA协议固化于硬件(即网卡)上,以及支持Zero-copy和Kernel bypass这两种途径来达到其高性能的远程直接数据存取的目标。使用RDMA的优势如下:
零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
技术的实现方式:
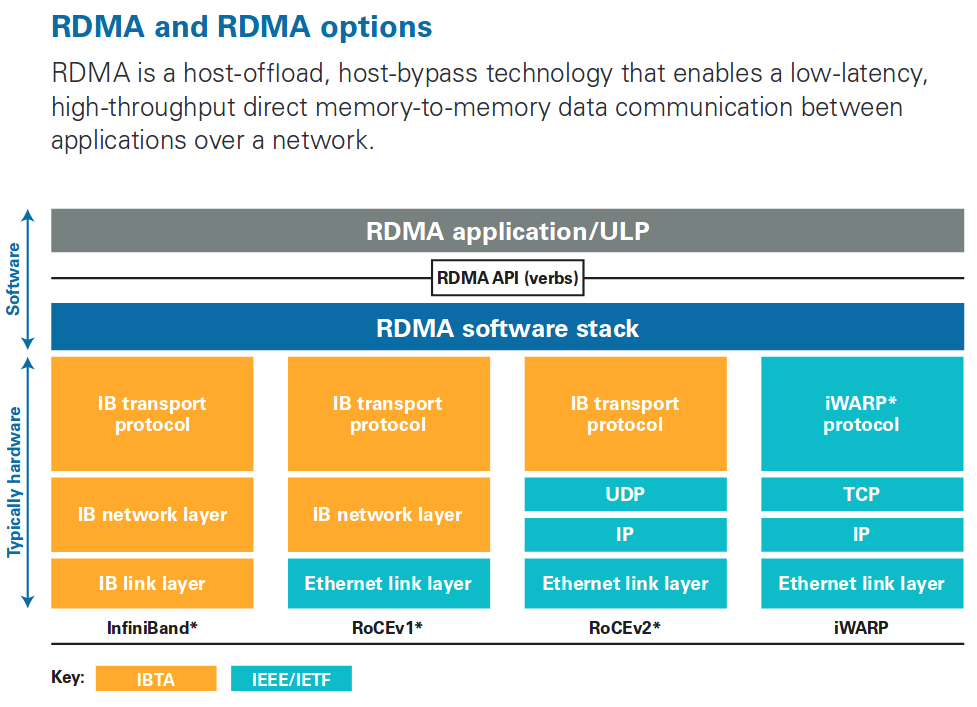
RDMA是一项底层技术,实现他的方式有如下三种:InfiniBand、RoCE、iWARP,如下图:
1999 年开始起草规格及标准规范, 2000年正式发表,但发展速度不及 Rapid I/O、 PCI-X、 PCI-E 和 FC,加上 Ethernet 从 1Gbps进展至 10Gbps。所以直到 2005 年之后,InfiniBand Architecture(IBA)才在集群式超级计算机上广泛应用。
全球 Top 500 大效能的超级计算机中有相当多套系统都使用上 IBA。随着越来越多的大厂商正在加入或者重返到它的阵营中来,包括 Cisco、 IBM、 HP、 Sun、 NEC、 Intel、 LSI 等。InfiniBand 已经成为目前主流的高性能计算机互连技术之一。为了满足 HPC、企业数据中心和云计算环境中的高 I/O 吞吐需求,新一代高速率 56Gbps 的FDR (Fourteen Data Rate) 和 EDR InfiniBand 技术已经大幅应用了,到如今已经Mellanox已可以做到NDR 400G InfiniBand。当然,目前常用的设备会是支持100Gbps的居多。
技术优势:
Infiniband 大量用于 FC/IP SAN、 NAS 和服务器之间的连接,作为 iSCSI RDMA 的存储协议 iSER 已被 IETF 标准化。相比 FC 的优势主要体现在性能是 FC 的 3.5 倍,Infiniband交换机的延迟是 FC 交换机的 1/10,支持 SAN 和 NAS。存储系统已不能满足于传统的 FC SAN 所提供的服务器与裸存储的网络连接架构。HP SFS 和 IBM GPFS 是在 Infiniband fabric连接起来的服务器和 iSER Infiniband 存储构建的并行文件系统,完全突破系统的性能瓶颈。Infiniband 采用 PCI 串行高速带宽链接,从 SDR、DDR、QDR、FDR 到 EDR NDR HCA 连接,可以做到 1 微妙、甚至纳米级别极低的时延,基于链路层的流控机制实现先进的拥塞控制。InfiniBand 采用虚通道(VL 即 Virtual Lanes)方式来实现QoS,虚通道是一些共享一条物理链接的相互分立的逻辑通信链路,每条物理链接可支持多达 15 条的标准虚通道和一条管理通道(VL15)。
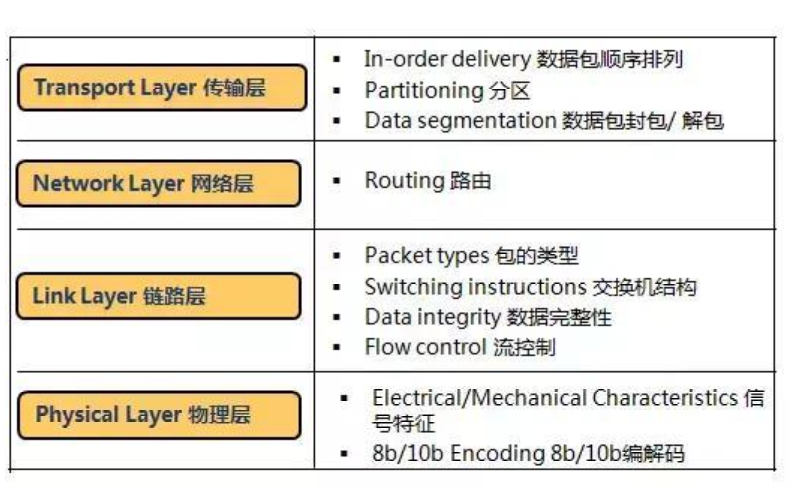
Infiniband的协议采用分层结构,各个层次之间相互独立,下层为上层提供服务。其中,物理层定义了在线路上如何将比特信号组成符号,然后再组成帧、数据符号以及包之间的数据填 充等,详细说明了构建有效包的信令协议等;链路层定义了数据包的格式以及数据包操作的协议,如流控、 路由选择、 编码、解码等;网络层通过在数据包上添加一个40字节的全局的路由报头(Global Route Header,GRH)来进行路由的选择,对数据进行转发。
在转发的过程中,路由 器仅仅进行可变的CRC校验,这样就保证了端到端的数据传输的完整性;传输层再将数据包传送到某个指定 的队列偶(QueuePair,QP)中,并指示QP如何处理该数据 包以及当信息的数据净核部分大于通道的最大传输单 元MTU时,对数据进行分段和重组。
InfiniBand互联网络:
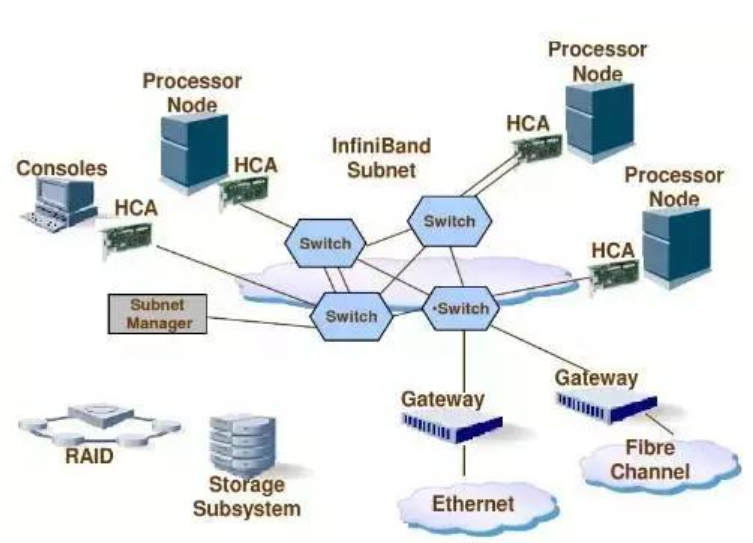
谈到InfiniBand,就不得不说到主导这项技术的公司:Mellanox 。成立于 1999 年,总部设在美国加州和以色列,Mellanox 公司是服务器和存储端到端连接 InfiniBand 解决方案的领先供应商。2010 年底 Mellanox 完成了对著名 Infiniband 交换机厂商 Voltaire 公司的收购工作,使得 Mellanox 在 HPC、云计算、数据中心、企业计算及存储市场上获得了更为全面的能力。
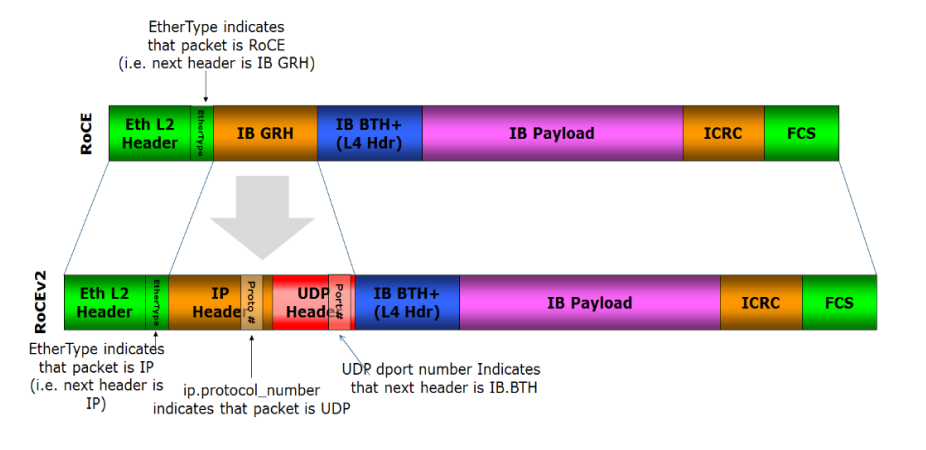
RDMA over Converged Ethernet (RoCE)是一种网络协议,允许应用通过以太网实现远程内存访问。目前 RoCE 有两个协议版本, v1和 v2。其中 RoCE v1 是一种链路层协议,允许在同一个广播域下的任意两台主机直接访问。而 RoCE v2 是一种 Internet 层协议,即可以实现路由功能。虽然 RoCE 协议这些好处都是基于融合以太网的特性,但是 RoCE 协议也可以使用在传统以太网网络或者非融合以太网络中。
网络密集型应用,例如存储或者集群计算等,需要网络支持大带宽和低时延特性。RoCE 可以比他的前任 iWARP 协议要实现更低的时延。目前 RoCE HCAs(Host ChannelAdapter)最低时延为 1.3 微秒,而 iWARP HCA 的最低时延为 3 微秒(2011 年数据)。RoCE v1 协议属于 ETH 链路层协议,协议类型为 0x8915,这意味着其报文长度最大不超过 1500 字节,在支持超大帧的情况下不超过9000 字节。另外,交换机需要支持PFC等流控技术,在物理层保证可靠传输。
RoCE v2 协议使用的是 UDP/IPv4 或者 UDP/IPv6。UDP 目的端口号 4791 就是给 RoCE v2 预留的。由于 RoCE v2 报文能够支持路由功能,因此有时候也称他为可路由的 RoCE 或者 RRoCE。尽管在通常情况下 UDP 报文的传输顺序是没有保证,但是 RoCE v2 规范要求了有相同 UDP 源端口和目的地址的报文必须顺序传送。另外, RoCE v2 定义了拥塞控制机制,即使用 IP ECN 位来进行标记,同时用 CNP 帧来进行确认。
相比较而言,RoCEv2在实用场景,仅需使用特殊的网卡就可以,对交换机的要求较低。
另外,谈到RoCE就不得不说一个国产化的问题。从整体的数据通信市场来看,目前国内的交换机市场,国产设备已经逐渐占领主流,而支持RoCE的交换机也有不同国产厂商的好几款。计算存储互联的市场本来就不大,想要通过企业的力量,在InfiniBand这个赛道超车难度较大,而RoCE恰恰给出了一个可行的路径。
这项技术我们就简单讲讲,因为他的应用确实不多。其实各位看官也能感受到,市场对技术流派的演进的确很强。
RDMA over TCP(iWARP)协议能够工作在标准的基于TCP/IP协议的网络,如目前在各个数据中心广泛使用的以太网。iWARP并没有指定物理层信息,所以能够工作在任何使用TCP/IP协议的网络上层。iWARP允许很多传输类型来共享相同的物理连接,如网络、I/O、文件系统、块存储和处理器之间的消息通讯。
InfiniBand采用Cut-Through转发模式,减少转发时延,基于Credit流控机制,保证无丢包。RoCE性能与IB网络相当,DCB特性保证无丢包,需要网络支持DCB特性,但时延比IB交换机时延稍高一些。iWARP则是利用成熟IP网络,继承RDMA优点,但如果采用传统IP网络丢包对性能影响大。
IB | RoCE | iWARP | |
标准组织 | IBTA | IETF | IBTA |
性能 | 好 | 较好 | 好 |
稳定性 | 好 | 较好 | 差 |
成本 | 高 | 中 | 低 |
iWARP技术的主要问题在于稳定性,一旦网络有丢包,性能会奇差,而iWARP就是基于以太网协议实现的,以太网协议不可能没有丢包,这使得iWARP技术没有了应用空间。
IB性能更好,RoCE则用得更多,RoCE是伴随着RDMA技术才普及起来的,相比于IB技术,RoCE技术仍基于以太网实现,但是增加了丢包控制机制,确保以太网处于一个无丢包的状态,虽然延时比IB差些,但部署成本要低得多。
Intel收购了Qlogic的InfiniBand业务的Intel又另辟新径,推出了一整套叫做“True Scale Fabric”的高性能计算架构的解决方案(包括IB和Omni-Path),独立提出了一套Omni-Path Host Fabric Interface接口和对应的交换机产品。每个端口支持 100G 速率,直接叫板InfiniBand EDR。提供Verbs和PSM(性能扩展消息库)两个编程接口,PSM是专门面向 MPI 通信设计的接口。
Intel在CPU上集成了Omni-Path相关功能,这也意味着Omni-Path通信效率上更加高效,但会让自己的网络依赖于CPU,至少在处理器上开放性还是做的比较有局限性。

从测试数据来看,在顺序读写 IO 模型下, Omni-Path的时延优势并不明显;但是在随机IO模型和项目条件下, Omni-Path具有比较大的优势。
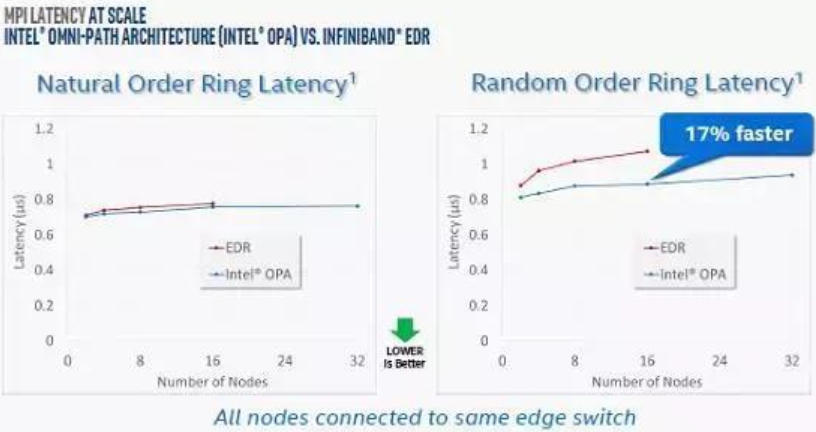
从技术角度看,Omni-Path 在技术和协议架构上并没有太多突破性的变化,Intel 通过Intel Fabric Builders Program 构建自己强大的生态环境,当前有多大型超算中心正在使用 Omni-Path 网络。不过从我们国内的具体实践上来看,应用案例并不算多。
讲了这么多网络,下面来说存储。高效的网络传输+高效的存储,才能保证高性能的计算下的数据,读写飞起来。而各大企业迅速的应用RDMA技术,有一个很重要的因素,就是NVMe技术的落地,和SSD盘成本的大幅降低。可以说,NVMe over Fabric + RDMA,他们俩CP一组合,大大加速了“高速计算存储互联技术”的广泛应用。
NVMe,Non-Volatile Memory Express,非易失性存储器标准,是跑在PCIE接口上的标准协议,是一种Host与SSD之间通信的协议。我们把NVMe 与SATA接口做对比:PCIe接口要比SATA接口快的多,SATA3最大带宽是6Gb/s,而基于4X PCIe的M.2接口最大可以达到32Gb/s
那为什么NVMe如此之快(注意:这里说的快是基于SSD设备的,如果是机械硬盘则不然)。由于SSD本身的物理特性,其数据的访问已经非常快了,性能的瓶颈就是出在计算机与设备连接的接口和协议上面。
我们举一个简单的例子。比如我们有一个仓库会不断的生产出产品来,我们可以机械手将产品从仓库拿到其它地方(如图5所示)。对于SATA的SSD,类似于一个单臂的机器人,仓库生产的很快,但机器人每次只能拿一个,搬移的速度就比较慢。

然而对于基于NVMe的SSD呢?相当于这个机器人长了数百只手,这样速度显然就比前者快的多了。

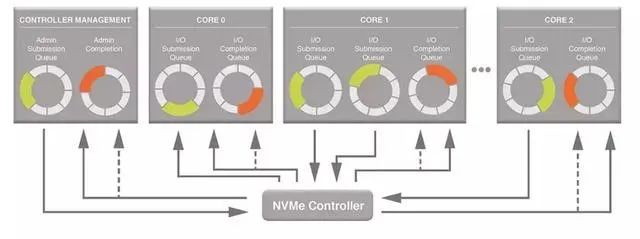
NVMe协议的原理也是如此,它本质是上建立了多个计算机与存储设备的通路,这样搬运数据的速度自然就提高了。在NVMe协议中,多个通路其实就是多个队列。在SATA中计算机与存储设备只能有一个队列,即使是多CPU情况下,所有请求只能经过这样一个狭窄的道路。而NVMe协议可以最多有64K个队列,每个CPU或者核心都可以有一个队列,这样并发程度大大提升,性能也自然更高了。
NVMe Express工作组是一个由约90家公司组成的联盟,于2012年开发了NVMe规范。该工作组发布了NVMe规范1.3版,增加了安全性,资源共享和SSD耐久性管理问题的功能。
说到存储协议,其实RDMA很早就有了,没有NVMe的时候,iSER (iSCSI Extensions for RDMA)和 NFSoRDMA (NFS over RDMA), SRP (SCSI RDMA Protocol)是用的最多的。
如果NVMe替代设备连接中的存储协议,则不难看出NVMe也可以用iSCSI和光纤通道协议替代SCSI。这正是NVMe over Fabric标准的发展情况,该标准始于2014年。关于NVMe over Fabric,有两种类型的传输方式。一是使用远程直接内存访问(RDMA)的NVMe over Fabric,二是使用光纤通道(FC-NVMe)的面向NVMe over Fabric。
RDMA支持在不涉及处理器的情况下将数据传输到两台计算机的应用程序内存,并提供低延迟和快速数据传输。RDMA实施包括融合以太网上的Infiniband,iWARP和RDMA,或RoCE(发音为“rocky”)。像Mellanox这样的供应商提供适用于Infiniband和以太网的速度可达100 Gbps及以上的适配卡,其中包括NVMe over Fabrics卸载。
NVMe允许对SSD设备进行大规模并行访问,从而充分利用SSD性能。
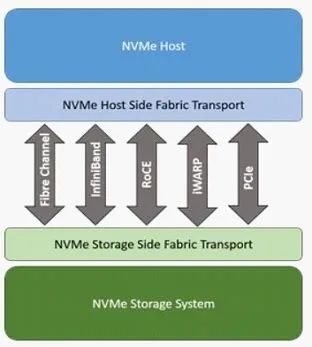
在存储领域,支持RDMA的技术早就存在,比如SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)。如今兴起的NVMe over Fabrics如果使用的不是FC网络的话,本质上就是NVMe over RDMA。换句话说,NVMe over InfiniBand, NVMe over RoCE和NVMe over iWARP都是NVMe over RDMA。
全身扫描完,我们可以对RDMA输出一个检查报告了。


这样,其实文章开头的几个疑问也就迎刃而解了。
首先要说,这项技术还专门有个国际联盟组织在维护,就说明要深化的技术问题还很多,有很多事情可做。技术,总是需要通过具体的手段进行场景落地的,那么天玑科技又做了什么事情呢?
RDMA的复杂性和缺乏在线教程(比TCP/IP协议更高效,但复杂性更高),需要对该技术进行有效的上层优化封装和场景落地。天玑聚焦细分场景,将其进行完善,在数据库、分布式存储领域进行场景优化,与使用标准传输协议相比,自研的SmartSCSI在高可靠的基础上实现了20%的延时降低和50%的吞吐量提升。该模块以内核态运行,完全兼容NVMe,File IO、Block IO、SCSI Passthrough等各种工作方式。
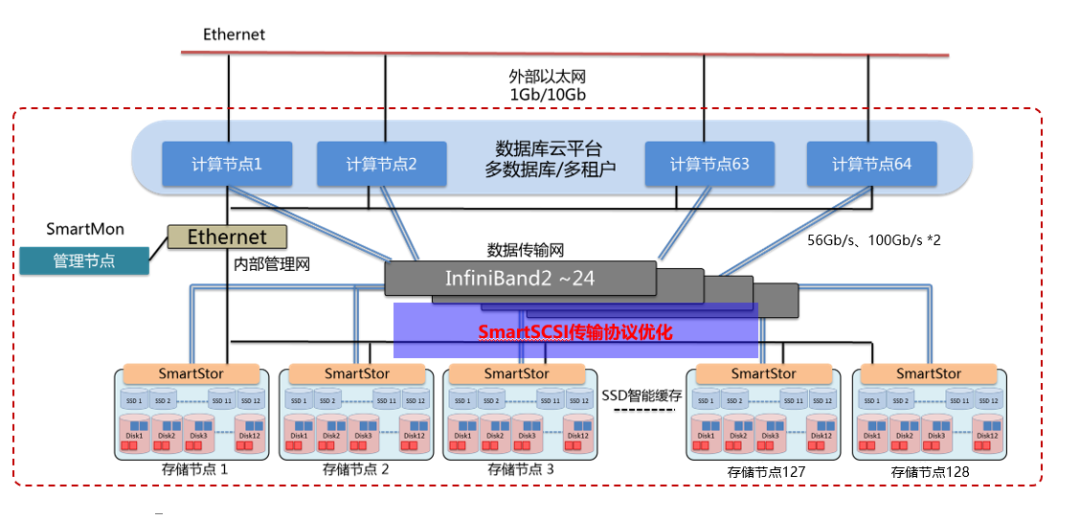
通过多年的项目经验积累,不断对其优化和完善。对一体机软件传输协议持续优化,对Intel OPA等独家技术的支持,都是这几年不断在做的事情。
积极拥抱国产化。基于国产RoCE交换技术,选择国产化技术栈,适配数据库典型场景。RoCE技术虽然实力与IB更接近,但是他仍然是基于IP的技术,数据传输本身是不可靠的(传输过程中数据可能丢失或者失序)。从底层协议上的差距,就只能从上层技术上进行调优。而这也是天玑科技在不断努力的地方。
可以看到,基于InfiniBand的RDMA技术是目前使用场景较多的、较成熟的解决方案。但是,最大的问题,目前可以生产IB交换机,与IB网卡的厂商,只有Mellanox一家。在现在芯片紧缺、中美对抗的档口,自主可控也是势在必行。
天玑目前在国产化上,已完成全栈国产化验证,以后也会在行业落地的场景加速完善:

到这里相信各位看官对RDMA这位低调而有实力的技术有一定了解了。不过仔细想想疑问也随之而来:
基于IB or RoCE的RDMA的确这技术很牛,但是成本是否比传统架构高很多?不会有很多人用到吧?
还是基于国外的技术啊,国内厂商还能做些啥?改改开源代码而已吧?
在这里我们表达几个观点:
RDMA很早就有,且技术路线不断在发展,也逐渐在优化。在这一路中,不断有国际的、国内的IT大厂加入这个阵营。实际案例中,很多地方我们可能见到了,但是比例不大,原因其实很简单:市场决定人们总会花最少的钱办最多的事情,用不到说明需求还达不到。
商用产品研发最大的特点是:用户花钱买的产品,只要出现问题,就需要及时的处理、更新。所以对于一个ToB的商用产品来说,客户很看重实践经验(案例),而且是越靠近核心生产环境,越有价值。
天玑数据库云平台PBData产品系列始于2014年的去“IOE”元年,至今,在基础硬件架构产品的高性能与稳定性上,有着多年的研发积累和实践经验,包括核心生产环境验证的经验。
PBData不只是这一种技术,自研分布式存储软件、数据备份等都是完全自主掌握知识产权的技术(后续介绍)。天玑是一家做服务起家的公司,公司的产品也是秉承最佳服务客户的态度去研发设计的,聚焦技术的落地,为客户创造实际价值。

上海天玑数据技术有限公司是以大数据、云计算为核心的高科技创新企业。公司紧扣国家未来信息化战略和行业信息化发展需求,坚持专业化和产业化的发展方向,以“创新推动发展”为用户提供专业化解决方案。
业务联系电话:400-822-5030
网址:http://www.dnt.com.cn
地址:上海市闵行区田林路1016号科技绿洲三期6号楼

