




概述
PolarDB-X是一款阿里云自研的云原生分布式数据库,在云原生数据库的基础上,通过水平扩展、分布式查询、强一致分布式事务等核心技术,使得用户能够享受到云原生、分布式带来的技术红利。
其中一项核心技术,就是分布式事务。之前的文章已经讨论过,PolarDB-X在InnoDB基础上实现了基于时间戳的多版本并发控制,并结合全局时间戳服务,实现了全局一致的分布式事务。但众所周知,TSO是一个单点,无法应用于跨地域的场景,否则每个事务都需要从单个TSO获取时间戳,严重影响性能。
针对这一问题,PolarDB-X设计了跨地域的事务算法,能够不牺牲单Region的事务性能,同时支持跨地域的全局事务隔离。
因此,本文着重探讨PolarDB-X如何在TSO事务的基础上,实现跨地域的事务。
业务场景

在之前文章所描述的异地多活场景下,PolarDB-X主要通过单元化的方式解决异地多活问题,数据和业务切分成单元,每个单元会有Primary Unit的概念,即对于单个Partition来说只有一个Primary Unit可以写入,其他Unit通过CDC进行异步复制。这种模式下,大部分业务都只会访问本单元(本地域)的数据,因此不存在跨地域事务的问题;但仍然存在一部分业务,可能会访问跨单元的数据,即存在跨地域事务的需求。
我们用游戏业务来举例讨论下。在游戏业务中通常有分区分服的概念,一个用户在注册时选择某个服务器,而服务器通常和地域具有相关性,例如浙江的游戏玩家选择就近的浙江服务器,从而保证较低的游戏延迟。这种模式下,相当于对所有用户数据按照地域属性进行了切分,得到多个Partition,并且Partition会绑定到某个Primary Unit,实现了单元化。对于在线游戏来说,大部分业务只需要访问当前地域的数据,因此数据库事务延迟相对较低。在此基础上,还会存在一些跨单元的业务,例如用户在服务器之间的迁移,从浙江服务器迁移到北京服务器,或者全局的数据订正,给所有玩家发一套皮肤,这时候我们就需要用跨单元事务来查询/修改多个地域的数据。
实际除了游戏业务之外,还有很多业务具有这样的地域属性,例如饿了么的外卖业务,盒马鲜生的生鲜电商业务等。

因此,异地多活我们可以分为两个场景来理解:
单元化:对数据进行切分,将数据和业务聚合成一个业务单元
跨地域:在单元化的基础上,如何进行跨单元的数据查询/修改
单元化的场景在前面的文章已经做过介绍,本文主要介绍跨地域事务的场景以及相关技术实现。
技术背景
基于TSO的事务
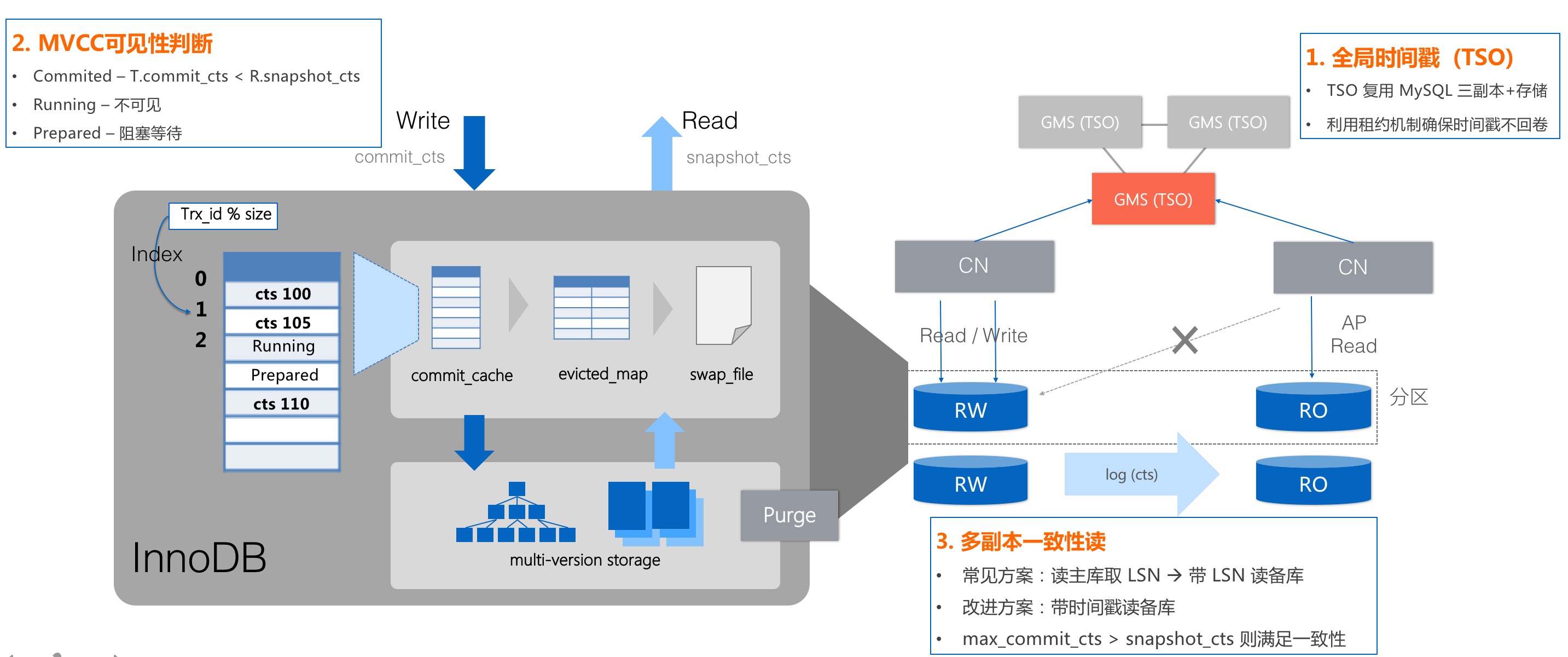
PolarDB-X在InnoDB的事务引擎基础上,实现了强一致的分布式事务。
InnoDB本身使用快照列表的技术实现事务隔离,PolarDB-X将其修改成基于时间戳的事务隔离;在此基础上,结合全局时间戳服务,以及全局的并发控制算法,实现了全局事务隔离;除此之外,又借助时间戳,完善了满足一致性快照的备库读能力,为HTAP能力奠定基础。
Hybrid Logical Clock
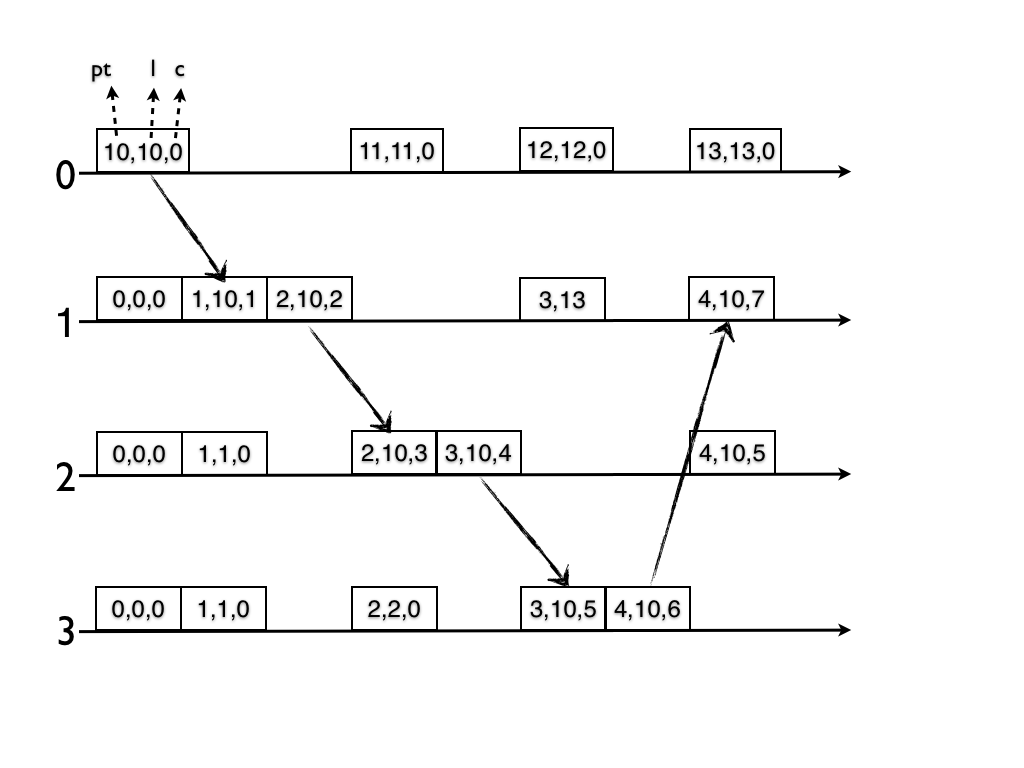
Hybrid Logical Clock是《Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases》提出的一种快照技术,通过逻辑时间戳来捕获事件之间的 Happens-Before 关系,通过物理时间戳来进行节点间的同步,以及两者的结合,得到事件的Snapshot。
遗憾的是,HLC并不能直接应用于数据库,文章中所说的Snapshot并非数据库中所讨论的Snapshot。
Clock-SI
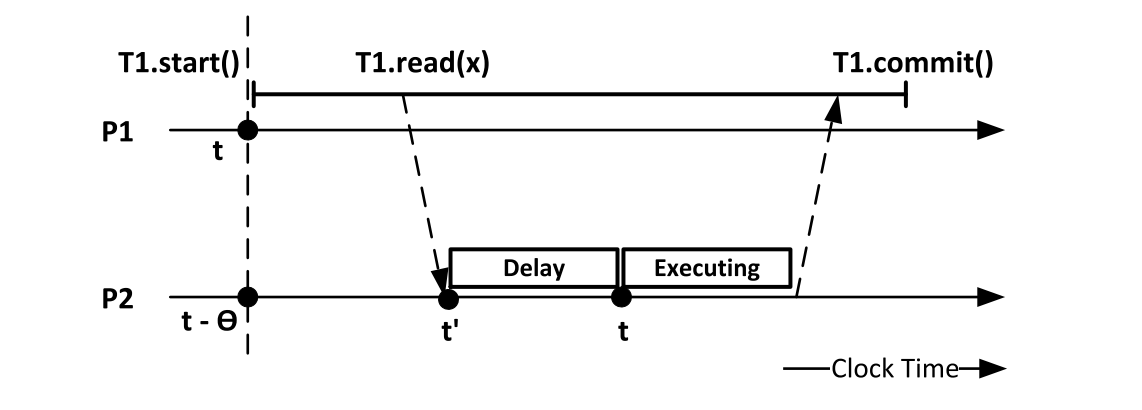
Clock-SI提出了一种用物理时钟实现分布式事务的方法,能够不依赖于中心时钟或者原子钟之类的硬件解决方案。
在事务快照读流程中,使用物理时间作为事务快照时间戳;当这个事务进行跨分区读时,可能会遇到快照时间戳大于远程分区物理时钟的情况,Clock-SI采用了Delay的方式,即等待物理时钟推进到快照时间戳。
在事务提交流程中,分布式事务通过2PC实现原子性提交,并在 2PC Prepare 时通过物理时钟生成 prepare_ts ,汇总所有参与者得到 commit_ts=Max{prepare_ts} ,然后执行 2PC CommitPrepared 。一个事务在 prepared 与 committed状态之间,遇到其他事务的读需要进行等待。
Clock-SI的局限性在于,完全基于物理时钟实现,当物理节点之间的时钟出现偏移时,会影响到事务的性能,例如上图的Read Delay会增加。
正文
系统架构

跨地域的数据库系统架构如图所示:
PolarDB-X集群会在每个Region进行部署,保证完整的管控和运维能力
计算节点和存储节点在每个Region部署,尽量保证计算存储的亲和性
TSO组件在每个Region独立部署,保证每个Region就近访问本地的TSO,优化网络延迟
在这样的架构下,每个Region内部的业务只访问本Region的PolarDB-X节点,而PolarDB-X的计算节点可以访问所有Region的存储节点,具备跨地域事务的能力。因此用户对数据库的使用分为两种方式:
数据单元化:大部分业务只访问本Region的数据
数据跨单元:少部分业务会进行跨Region的数据修改、数据查询
这样的架构看起来很美好,但背后却会面临一个问题,原本TSO能够保证分配全局单调递增的时间戳,当每个Region都有本地的TSO之后,还如何保证事务的全局一致性?
事务算法
单地域事务
对于单地域事务来说,算法和原来保持一致,访问本地Region的TSO获得 snapshot_ts 和 commit_ts 。
跨地域快照读

在跨地域读的场景下,一个Region的事务需要读其他Region的数据,此时需要事务的一致性快照。流程如下:
snapshot_ts : 在Region1的TSO获取时间戳作为 snapshot_ts
跨Region读:读其他Region数据时,需要传递 snapshot_ts
TSOUpdate : snapshot_ts 传播到其他Region时,需要更新相应的TSO,才能执行事务
按照这个流程,每个Region内的事务只需要访问本地的TSO,不需要从中心节点获取时间戳;当事务需要跨Region读时,仅需要多一次TSO访问,增加一次Region内部的网络RT。
跨地域事务提交
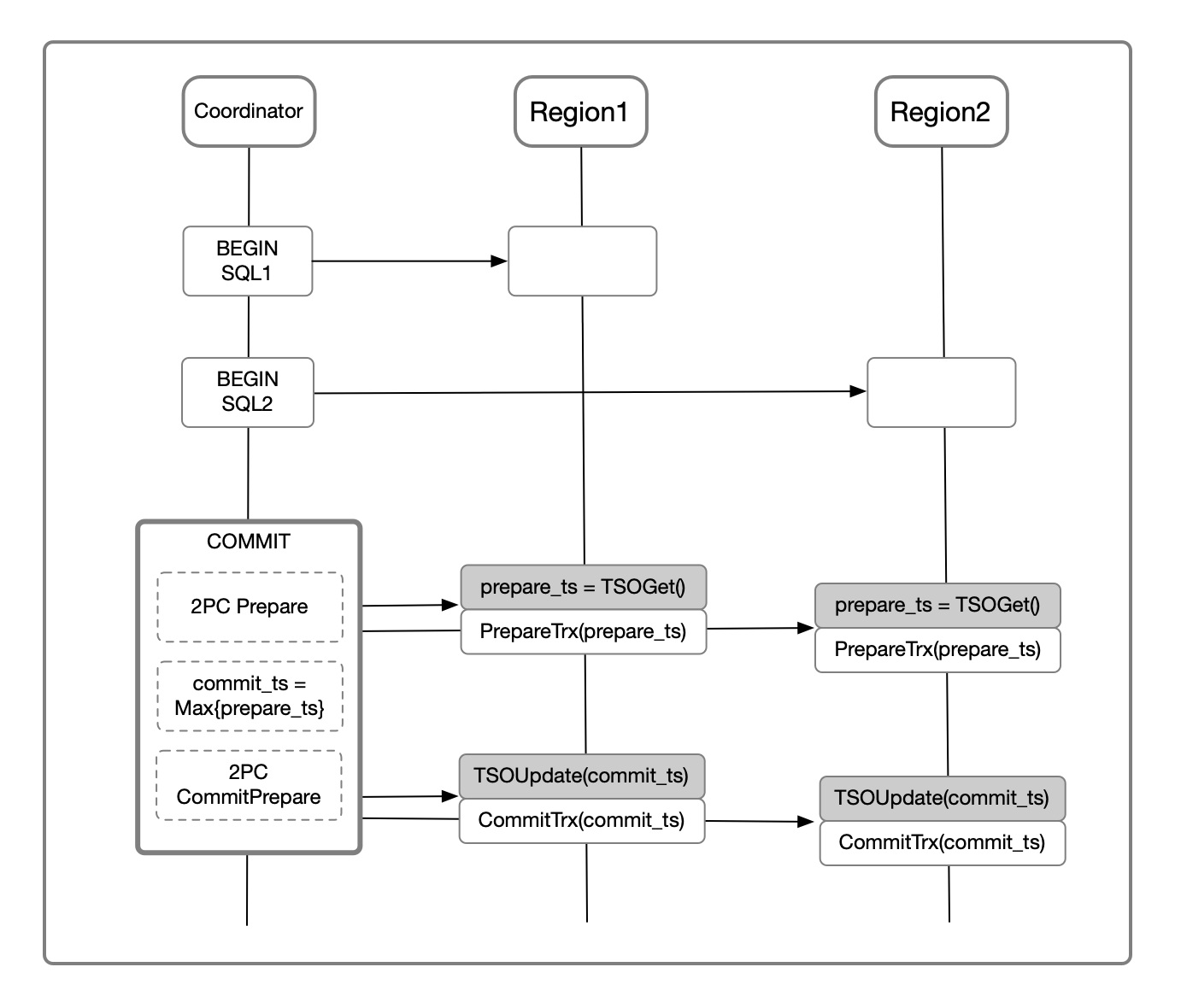
对于跨地域事务的分布式提交,单Region时只需要从TSO获取时间戳作为 commit_ts ,而跨Region时需要按照以下流程执行:
prepare_ts : 从事务参与的所有Region的TSO生成 prepare_ts ,随着 2PC Prepare 返回给Coordinator
commit_ts : 事务Coordinator计算 commit_ts=Max{prepare_ts} ,并与 2PC CommitRecord 一起持久化
TSOUpdate :在 2PC CommitPrepared流程中,需要用 commit_ts 推高TSO
由于事务的2PC只需要等到 2PC CommitRecord 持久化即可返回,第二个提交阶段异步执行。因此,整体事务提交流程仅仅增加了一次Region内部的TSO 网络RT,整体网络延迟基本不变。
性能分析
对于性能,需要分成几种事务类型进行分析。
第一种是单Region事务,这是最为常见的场景,因此其性能最为重要。按照以上算法,事务的读流程、SQL执行流程、事务分布式提交流程完全在单Region内完成,因此其性能与原来保持不变,不需要为跨地域事务付出额外的代价。
第二种是多Region只读事务:
快照时间戳传递:当快照时间戳从一个Region传递到其他Region时,需要更新这个Region的TSO,增加一次Region的网络RT
事务SQL执行:每条SQL都需要经过跨Region的网络,增加的网络RT与SQL数量成正比
由于Region之间的网络延迟远大于Region内的网络延迟,因此认为事务的RT主要受到Region之间的网络延迟限制,本方案增加的开销较小。
第三种是多Region的读写事务:
快照时间戳传递:快照时间戳跨Region传递时,增加一次Region内的网络RT
事务SQL执行:增加的网络RT与SQL数量成正比
事务提交:在 2PC Prepare 流程中增加一次Region内部的网络RT,其他延迟不变
综上所述,本方案仅仅增加了两次Region内部的网络RT,没有增加Region之间的网络RT,因此增加的额外开销较小。且对于原本的单Region事务算法没有改动,性能和原来保持一致。
正确性分析
对于事务的正确性,这里主要讨论以上算法能否保证事务的Snapshot Isolation,而Snapshot Isolation的正确性从三个维度展开:
Consistent Snapshot
Write-Write Conflict
Total Order Commit
Consistent Snapshot,即当且仅当事务  ,则T1对T2可见。(注:以下证明中 → 表示事件的先于关系)
,则T1对T2可见。(注:以下证明中 → 表示事件的先于关系)
证1:当  ,T1对T2可见
,T1对T2可见
事务T2进行时间戳传递时,需要更新相应Region的TSO,故存在事件

若

根据TSO的单调递增性,

根据因果性,

根据 TSOUpdate 规则,

根据传递性,

与假定相违背,故不存在这种可能性
若

根据2PC流程,

根据时间戳传递规则,

根据传递性,

根据事务可见性规则,T2看到T1处于 prepared 状态时需要进行等待,直到事务提交,故T1对T2可见
证2:当  ,T1对T2不可见
,T1对T2不可见
根据事务可见性规则,当T1处于 committed 状态且
 ,T1才对T2可见
,T1才对T2可见因此,得证
由证1和证2可得, 当且仅当  ,T1对T2可见,即满足Consistent Snapshot性质。
,T1对T2可见,即满足Consistent Snapshot性质。
对于Write-Write Conflict来说,在事务写入时会检查已提交事务的 commit_ts 是否大于更新事务的 snapshot_ts ,如果存在冲突则回滚事务。对于Total Order Commit来说,事务的CommitOrder由 commit_ts 定义,存在全序关系。
综上所述,以上的算法能够满足Consistent Snapshot、Write-Write Conflict、Total Order Commit性质,故满足Snapshot Isolation性质。
外部一致性

按照以上的算法,如果两个事务都在同一个Region内执行,通过TSO全局排序能够保证外部一致;如果两个事务在不同的Region发起,则没有外部一致性的保证;退而求其次,仅保证Session Consistency。
举例来说,事务A在地域1写入数据,其提交时间戳为 ts1 , 紧接着事务B在地域2读取数据,其快照时间戳为 ts2 ,由于这两个地域的TSO并没有做同步,因此获取到的时间戳可能会发生 ts1 > ts2 ,因此事务T2无法读到事务T1写入的数据。
但考虑到实际的业务场景,在跨Region的场景下对外部一致性的需求较低,通常业务需要的仅仅是是单元内部的外部一致。因此我们认为在跨Region的场景下可以放松对外部一致性的要求,换来更好的性能。
虽然理论的天花板难以突破,但工程上我们仍然可以通过一些优化来尽量降低这个问题的影响。例如通过TSO之间的时钟同步,可以将其时钟漂移缩小到很小的范围;通过ReadWait机制,检查事务的提交时间戳是否在时钟漂移范围内,避免因果反转;通过引入额外的全局TSO机制,牺牲性能而保证外部一致。总之,根据实际业务需求,这个问题在工程上可以进一步优化。
相关工作
纵观工业界在跨地域事务这个方向的工作,大致如下:
数据库 | 时钟方案 | 外部一致性 | 跨地域事务时延 |
Spanner | TrueTime | 保证 | TrueTime Skew |
CockroachDB | HLC | 不严格保证 | 不增加额外RT |
TiDB 5.0 | Global TSO | 保证 | GlobalTSO增加2次RT |
OceanBase 2.0 | TSO | 保证 | - |
PolarDB-X | Hybrid TSO | 本地事务保证 | 不增加额外RT |
总结
本文分析了PolarDB-X如何在TSO事务架构的基础上,通过结合HLC事务算法,将系统架构扩展到跨地域场景,使得Region内事务没有性能损失,同时又使得跨Region事务性能得到保证。
实际在跨地域的场景下,除了分布式事务的问题之外,还存在诸多问题需要进行优化,例如高可用问题、数据分区问题、网络带宽问题。在后续的文章中我们会对这些问题进行进一步的解析,同时也会围绕跨地域的场景开展更多的工作。
参考
Berenson H, Bernstein P, Gray J, et al. A critique of ANSI SQL isolation levels[C]//ACM SIGMOD Record. ACM, 1995, 24(2): 1-10.
Du J, Elnikety S, Zwaenepoel W. Clock-SI: Snapshot isolation for partitioned data stores using loosely synchronized clocks[C]//Reliable Distributed Systems (SRDS), 2013 IEEE 32nd International Symposium on. IEEE, 2013: 173-184.
