




背景
CurveFS (共享文件存储系统) 在不同应用场景落地使用时,不可避免的涉及到将原系统数据迁移到 CurveFS,特别是大数据和 AI 相关业务,他们数据量巨大(包括海量小文件),如何做到高效、可靠的数据迁移是一切的开始。在当今大数据和人工智能领域的快速发展中,随着数据量的爆炸式增长,对分布式文件系统的存储可扩展性、成本和性能提出了更高的要求。因此,我们开发了 CurveFS 来解决这些问题。
本地磁盘目录
集中式存储或分布式存储:NAS 存储、NFS、ceph、glusterfs、minio等
云存储:包括各类公有云文件存储和对象存储等。
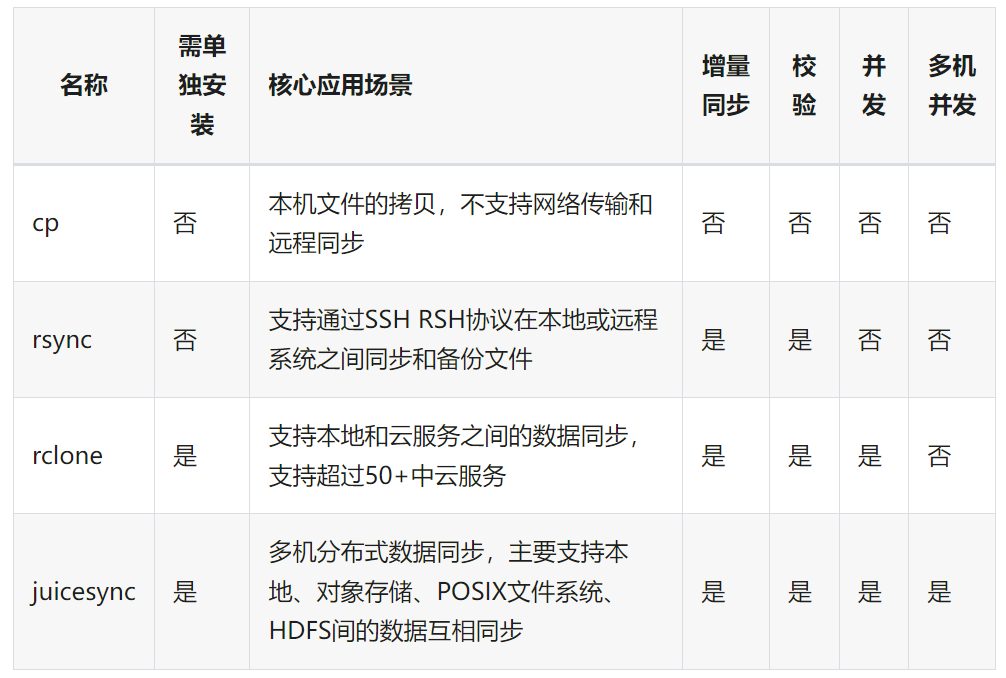
我们调研了几种常见的数据迁移工具,同时也在相同场景下测试他们在 CurveFS 上的表现:
测试数据集使用测试工具 mdtest 生成,命令为:mdtest -z 10 -b 2 -I 1000 -w 131072 -C -F -d curvefs/data ,共 2047000 个 128KB 文件:


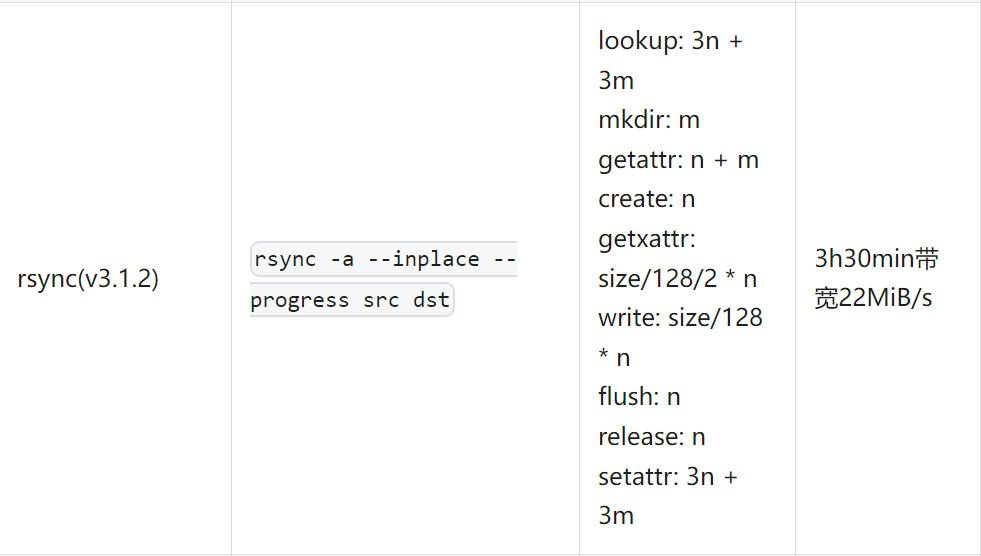
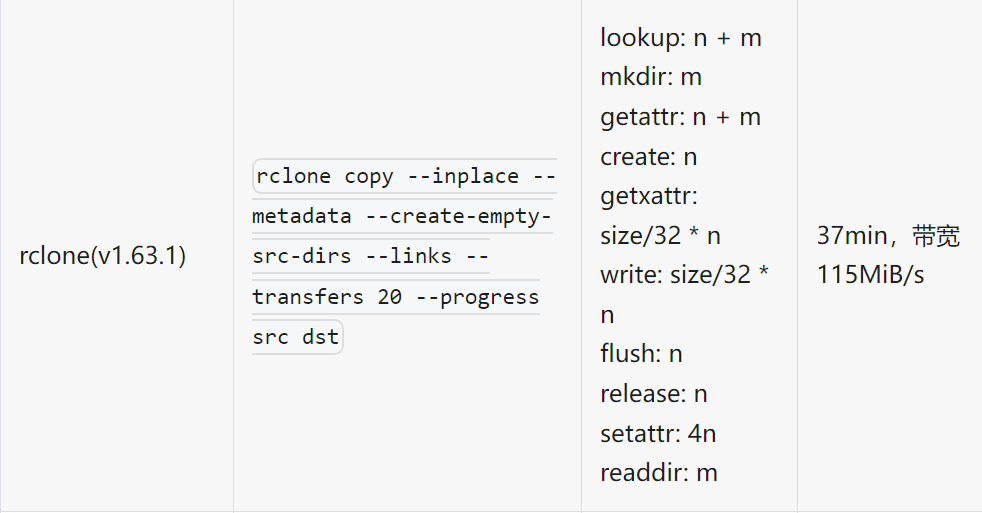
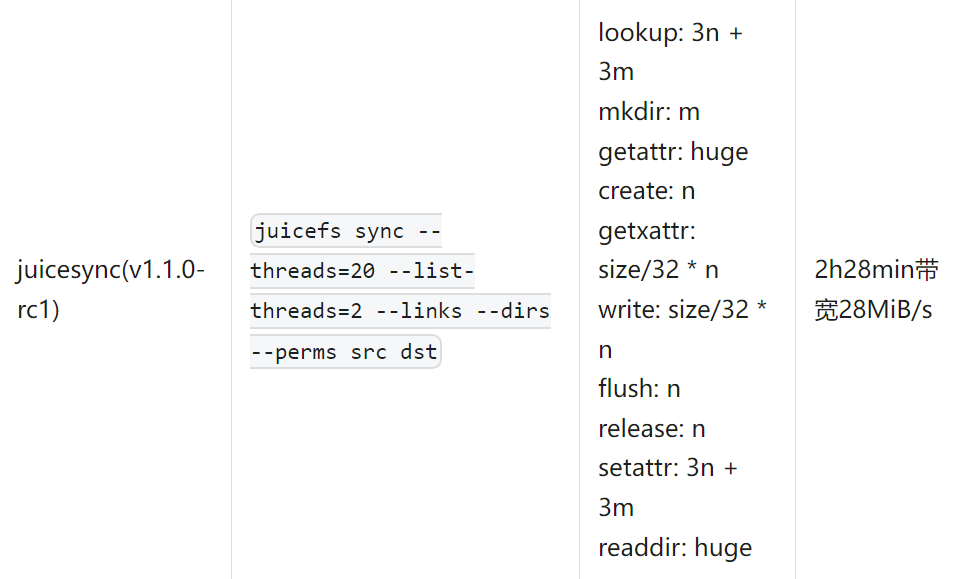
(注:上述命令中 src 为迁移数据的源目录,dst 为迁移的目标目录,这里是 CurveFS 挂载点,下同。)
采用的迁移方案
这次迁移是将某业务方存储在 CephFS 中的文件全量迁移至 CurveFS 中,数据特点是大文件极少,几百字节到数十 kB 的小文件巨多,单目录文件数量多达 5 千万个,文件总数量近百亿。
目前 CurveFS rename 操作是原子操作,耗时相对较长,所以工具需要支持直写(--inplace)。
需要支持并发,在海量小文件时效果更加明显。
支持校验,数据迁移过程保证文件的完整性尤为重要。
选择迁移工具:rclone v1.63.1
迁移命令:rclone copy --inplace --metadata --create-empty-src-dirs --links --transfers 500 --progress --fast-list --checkers 16 src dst
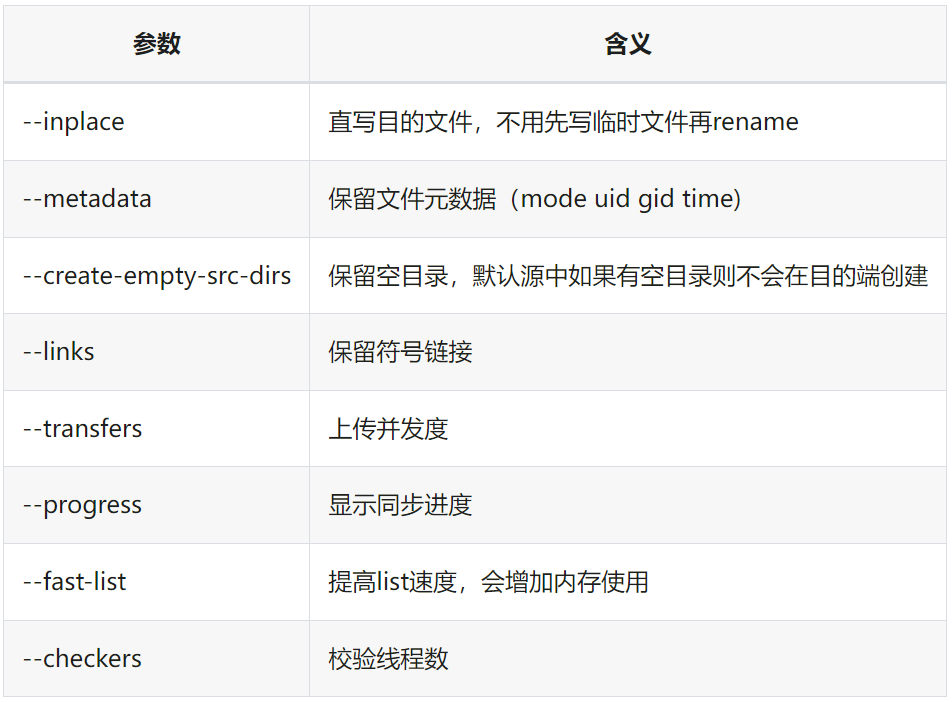
rclone copy 不会同步最上层目录,只会同步其内容,例如(src: A/file,dest: B) rclone copy A B,结果是/B/file,而不是/B/A/file。
单 rclone 并发度不建议设置太高,自身竞争可能会比较大,但可以分多个目录跑多个 rclone 进程,我们本次迁移采用 100-500,具体需要关注 client 节点负载和源&目的系统的集群压力。
rclone 目前不支持保留目录的元数据,即使指定了--metadata。我们基于 rclone 最新稳定版(v1.63.1)进行了修改,使得其支持在本地后端同步时对目录元数据进行保留(https://github.com/opencurve/curve-rclone/tree/v1.63.1-dir-metadata)。
rclone 默认使用 size 和 mod time 行校验,如果对完整性要求更强,可以在命令中指定 --checksum,这样会基于文件 size 和 checksum 进行校验。
最后关于迁移时间的预估,除了考虑数据 size 的大小还要考虑文件数量,如果是大文件居多可根据带宽进行评估,如果小文件居多需要根据 qps 进行初步评估,同时需要结合源端和目的端系统的系统压力、网络带宽等综合评估迁移所需时间。具体的迁移方案需要根据业务特点综合考虑,保证数据的平滑、高效、可靠的迁移。
后续规划
后续我们将会把 rclone 整合到 CurveAdm 运维工具中,方便用户一键启动数据迁移操作,欢迎感兴趣的小伙伴参与开发设计。
<原创作者,王海,Curve maintainer>


关于 Curve
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve 官网:https://opencurve.io/ 用户论坛:https://ask.opencurve.io/ 微信群:搜索群助手微信号 OpenCurve_bot
