




CAAFE介绍
NIPS 2023 Large Language Models for Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering
随着AutoML领域的不断发展,将领域知识纳入这些系统中变得越来越重要。CAAFE方法利用大型语言模型(LLM)的强大能力,针对表格数据集提供了一种特征工程方法,通过迭代生成语义上有意义的附加特征,生成的特征是基于数据集的描述。
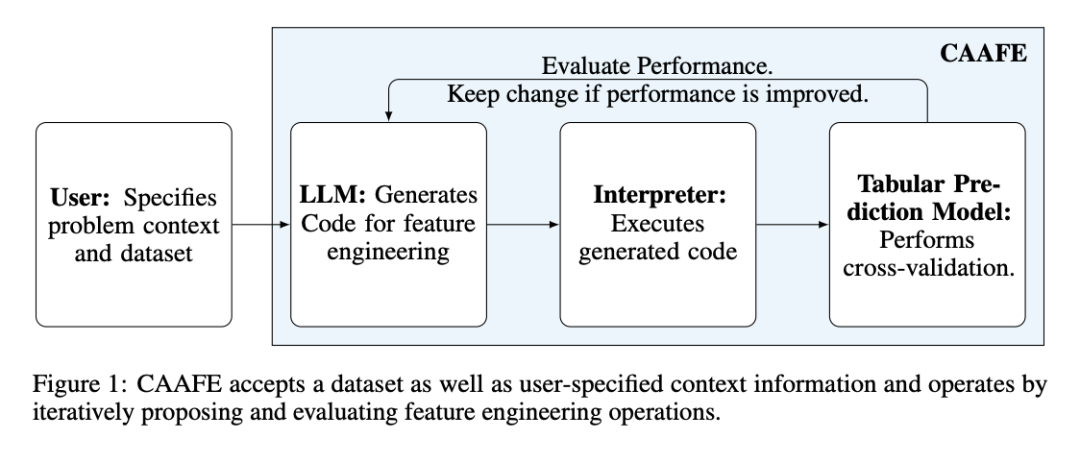
CAAFE方法不仅生成用于创建新特征的Python代码,还提供了解释生成特征的实用性的文本解释。尽管方法在方法学上相对简单,但在14个数据集中的11个中提高了性能,将平均ROC AUC性能从0.798提高到0.822。
- Demo: https://colab.research.google.com/drive/1mCA8xOAJZ4MaB_alZvyARTMjhl6RZf0a
- Python: https://pypi.org/project/caafe/
论文出发点
随着大型语言模型(LLMs)的出现,AutoML可以更广泛地覆盖数据科学领域,从而朝着"自动化数据科学"的方向发展。LLMs包含了大量领域知识,可以用于自动化各种数据科学任务,包括需要上下文信息的任务。然而,LLMs通常缺乏可解释性、可验证性,并且表现不如传统机器学习算法稳定。
作者提出的方法名为"Context-Aware Automated Feature Engineering (CAAFE)",它通过生成Python代码,迭代生成语义有意义的特征,以提高下游预测任务的性能。
CAAFE原理
方法的输入是训练和验证数据集(和),以及有关训练数据集和特征的上下文描述。根据这些信息,CAAFE构建一个提示,即一组指令,用于指导LLMs生成有价值的特征,并提供有关所添加特征实用性的解释。
在每次迭代中,LLMs生成代码,然后在当前的和上执行,生成变换后的数据集和。然后,我们使用来拟合一个传统的ML分类器,并在上评估其性能。如果超过了在上训练并在上评估的性能,则保留该特征。否则,该特征被拒绝。

CAAFE方法构建LLMs的提示以生成特征工程代码。提示包括有关数据集的语义和描述性信息,以及预期生成代码和解释的模板。此外,如果执行代码块引发错误,该错误会传递给LLMs进行下一次代码生成迭代。这有助于处理错误并提高稳定性。
在技术设置方面,数据存储在Pandas中,并预加载到内存中以供代码执行。性能通过多次随机验证分割来度量,并以平均准确度和ROC AUC的变化来决定是否保留代码块的更改。CAAFE使用OpenAI的GPT-4和GPT-3.5作为LLMs,执行十次特征工程迭代。
最后,为确保安全性,方对生成的Python代码的语法进行解析,并使用白名单操作来限制执行的操作。这有助于减少潜在的风险,但并不提供完全的安全性。
实验设置
评估中使用了Logistic Regression、Random Forests和TabPFN作为最终的评估分类器。在评估添加的特征性能时,使用了TabPFN。
对于缺失值,采用了均值、独热编码或有序编码的分类输入来进行填充,以及标准化特征和必要时传递分类特征指示符。同时,评估了常见的上下文不可知特征工程库Deep Feature Synthesis (DFS)和AutoFeat。
实验结果
CAAFE可以显著改善其最强分类器TabPFN的性能,从平均ROC AUC为0.798提高到0.822。作者还指出,CAAFE对11/14个数据集的性能都有所提升。在新的Kaggle数据集上,CAAFE也取得了显著的改进。作者还表明,CAAFE使用GPT-4比使用GPT-3.5获得更好的性能。
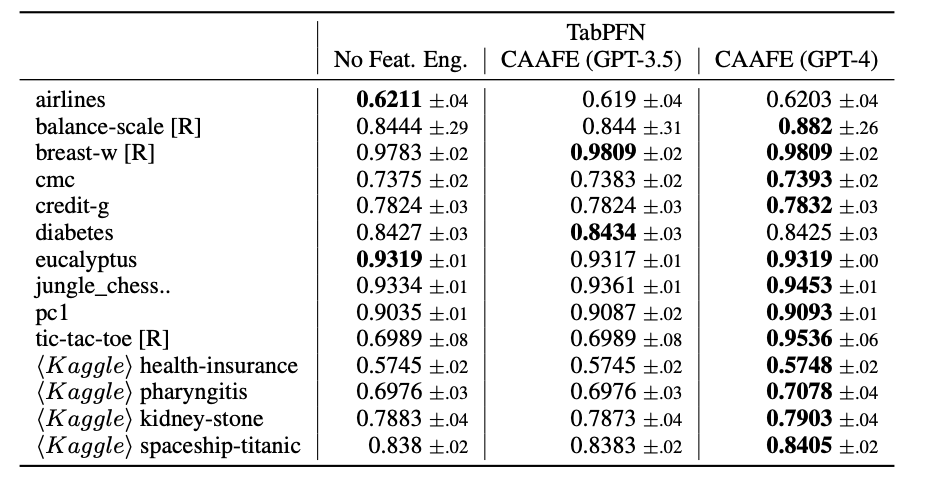
作者发现,传统的自动特征工程方法可以与CAAFE轻松结合使用,CAAFE首先运行,然后使用传统自动特征工程方法找到进一步的特征扩展,特别是对于较弱的下游分类器,如Logistic Regression和Random Forests,CAAFE与传统自动特征工程方法的结合会进一步提高性能。
但CAAFE需要用户提供有关数据集的描述信息,以便生成有意义的特征。CAAFE主要依赖于文本提示和大型语言模型,而不支持数据可视化。CAAFE可能在特征工程过程中生成大量复杂特征,这可能导致过拟合问题。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

