背景
在分布式数据库中,查询优化是一个承上启下的重要模块,它负责将语法分析生成的查询树,进行逻辑上的等价变换,物理执行路径筛选,根据统计信息,数据分布等信息计算每条路径的代价,选择出最优的执行路径,也就是查询优化负责将查询树转换成分布式查询执行计划,这个过程比单机数据库更复杂,计算量更大。而如果一条sql语句重复执行,那查询优化的过程也就被重复执行多次,带来了不必要的性能损耗,假若将生成的分布式查询执行计划(plan)缓存,可以减少查询优化的开销,通常为了提高缓存plan 的命中率,我们缓存参数化的plan, 通过适配不同参数达到复用plan的能力,而常常参数化的分布式plan生成过程中没有参数的参与,导致计划生成阶段无法完成计算下推判断,进而最后生成无法完全下推的计划,执行效率低,而这些方案通常在参数满足一定条件下,可将计算完全下推,polardb 分布式计算中采用根据参数动态下推。
概述
采用生成根据参数动态下推的参数化分布式执行计划方案,在生成原有参数化方案之后,对原有分布式计划中所有下推的子计算,根据计算下推条件判断是否与传入参数相关,如果所有下推的子计算都与参数相关,则生成完全下推plan, 并加入到原有执行计划中,在后续绑定参数时候,根据参数值 判定每个子计算是否都可下推到同一数据节点,如果条件成立,则执行完全下推plan.
详细设计
全局分布式执行计划缓存总体架构:
集群架构
PolarDB-for-PostgreSQL 分布式数据库集群中, 集群中节点类型分为Coordinator(CN),Datanode(DN), CN节点为协调节点,DN为数据节点。
详细设计:
本文讲述原理,分为四个部分介绍,第一部分分布式计划子计划分布统计计算, 第二部分分布式计划完全下推预判定。第三部分完全下推分布式计划生成, 第四部分分布式完全下推参数动态判定。
分布式计划子计划分布统计计算
DN是数据节点,CN是计算节点,CN在生成分布式执行计划时,一个不能完全下推的分布式执行计划,通常通过子计划根据其分布信息从数据节点拉取数据,然后同其他子计划拉取的数据做join, 并将结果作为其他join算子的输入,或者作为结果数据。而不能下推的原因通常是因为每个子计划的分布不同,需要在不同节点上拉取数据,无法完全下推到单一节点执行。尤其是在未提供子计划分布判定输入时候,因为参数化的原因,子计算的分布计算无法得到参数值,无法判定子计算具体在哪个数据节点获取数据,而如果生成各子计划分布不同,最终生成的整个计划则无法完全下推。
分布统计计算负责将各个子计划中的分布信息统计并记录包括如下信息:
分布方式:包括 hash, modulo, replication, roundrobin
hash 对分布列hash 获取32位hash 值,然后对DN总节点数取余
modulo 分布列对DN总节点数取余
replication 复制表,每个DN 节点
roundrobin 按DN顺序依次分布
如果是hash或者 modulo 分布,则保存分布列信息。
记录 分布判定条件中常数值对应的参数序号
参数化的分布式计划中每个参数都对应一个序号,而这个序号同参数绑定顺序一致。序号从1开始,这里假定参数序号变量为paramId.
数据结构
distributionType // 分布方式
paramId // 参数序列号
distributionExpr //分布列信息
targetNode // 目标节点
具体统计逻辑
如果子计划是单表扫描
记录单表的分布方式
如果是hash或者modulo 分布,记录单表的分布列信息
如果子计划是join,且join是可下推的
记录下推join 的分布方式
如果是hash或者modulo 分布,记录join的分布列信息
计算分布判定条件中参数对应的参数序号
如果分布方式为replication,代表这是一个复制表,可以在任意节点获取数据则设置参数序号paramId = 0, 代表可以是任意节点
遍历所有下推语句中where中的表达式
如果表达式是a = b 模式,并且 其中一侧为分布列,另一次是参数化之后的参数,比如这里a 为分布列, b为参数,则执行步骤2 否则继续判断下一个下推表达式
记录 paramId = b->paramId
如果 paramId 依然未获取,则判断是否当前为join, 如果是join 则遍历 join ON 所有的表达式
如果表达式是a = b 模式,并且 其中一侧为分布列,另一次是参数化之后的参数,比如这里a 为分布列, b为参数,则执行步骤2 否则继续判断下一个下推表达式
记录 paramId = b->paramId
在查询优化阶段,在生成分布式计划中每个子计划的时候按上述过程将所有子计划的分布信息和参数信息进行统计。
分布式计划完全下推预判定
在查询优化阶段,遍历分布式执行计划,如果所有可下推的子计划中统计的paramId 都大于等于0 则认为存在整个分布式执行计划可完全下推的可能则执行完全下推的分布式执行计划。
完全下推分布式计划生成
在查询优化阶段,根据完全下推预判定,存在完全下推的可能,生成完全可下推的执行计划
完全下推代表着整个语句是可下推到DN某一节点执行的。所以需要生成一个完整下推的sql 语句用于在DN中执行的可执行计划。
将当前经过parse, analyze ,rewrite 之后的查询树,通过deparse 的过程,将其还原为 可执行sql.语句, 因查询树中已经包含了当前所有的信息,所以通过deparse 的sql 语句能够满足完全下推的需要。
将 生成的sql 封装成定制计划,并标记完全下推计划的执行节点为空。
将生成的定制计划,保存到原有的参数化的分布式plan中。用于满足完全下推条件时,替换原有的分布式plan。
分布式完全下推参数动态判定
参数绑定时,执行器执行计划之前,根据传入的参数对每个子计划判定并获取其执行节点信息,并实施执行计划替换。
如果每个子计划执行节点唯一, 且相同 则代表整个执行计划是可以完全下推的。
节点计算和选择
子计划如果是replication 分布,随机选取其中一个节点作为执行节点。
子计划如果是hash 或者modulo 分布,则根据分布列和参数值计算执行节点。
如果所有子计划都为replication分布,则以第一个子计划的执行节点作为最终执行节点

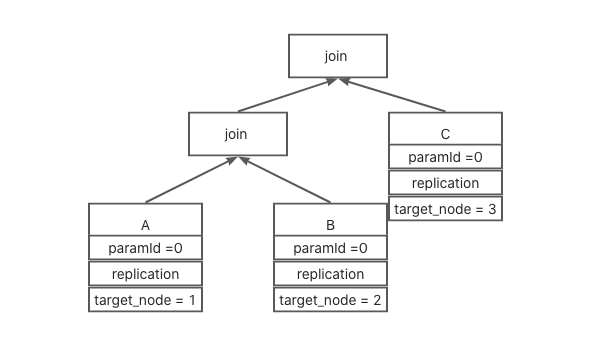
已上图为例
A 子计划为replication 分布, 得到执行节点为1
B 子计划为replication分布, 得到执行节点为2
C 子计划为replication分布, 得到执行节点为3。
最终去遍历时第一个碰到的子计划这里为A, 所以最终执行节点为1。
如果所有子计划都为hash 或者 modulo 分布,则必须所有子计划的执行节点唯一且相同,作为最终执行节点。

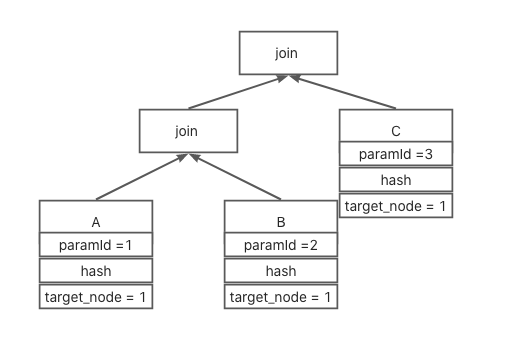
已上图为例
A 子计划为hash 分布,对应参数为第一个参数, 经计算得到执行节点为1.
B 子计划为hash 分布,对应参数为第二个参数, 经计算得到执行节点为1.
C 子计划为hash 分布,对应参数为第三个参数, 经计算得到执行节点为1.
所以最终执行节点为1。
如果有子计划为replication分布,亦有hash 或者modulo 分布,则判断 所有hash 或者modulo 分布的子计划执行节点唯一且相同,则忽略replication 分布的执行节点,以hash 或者modulo 分布的执行节点为最终执行节点。

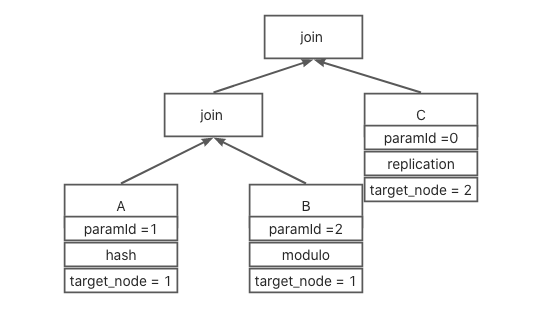
已上图为例
A 子计划 为hash 分布,对应参数为第一个参数, 经计算得到执行节点为1
B 子计划为modulo分布, 对应参数为第二个参数, 经计算得到执行节点为1
C 子计划为replication分布, 得到执行节点为2。
所以最终执行节点为1。
如果第一步操作获取了最终执行节点,则认为分布式执行计划可完全下推
从分布式执行计划中获取完全下推定制计划
将获取的最终执行节点信息,更新到定制计划中。
将完全下推定制计划,替换掉原有分布式执行计划
执行替换好的执行计划。
背景
在分布式数据库中,查询优化是一个承上启下的重要模块,它负责将语法分析生成的查询树,进行逻辑上的等价变换,物理执行路径筛选,根据统计信息,数据分布等信息计算每条路径的代价,选择出最优的执行路径,也就是查询优化负责将查询树转换成分布式查询执行计划,这个过程比单机数据库更复杂,计算量更大。而如果一条sql语句重复执行,那查询优化的过程也就被重复执行多次,带来了不必要的性能损耗,假若将生成的分布式查询执行计划(plan)缓存,可以减少查询优化的开销,通常为了提高缓存plan 的命中率,我们缓存参数化的plan, 通过适配不同参数达到复用plan的能力,而常常参数化的分布式plan生成过程中没有参数的参与,导致计划生成阶段无法完成计算下推判断,进而最后生成无法完全下推的计划,执行效率低,而这些方案通常在参数满足一定条件下,可将计算完全下推,polardb 分布式计算中采用根据参数动态下推。
概述
采用生成根据参数动态下推的参数化分布式执行计划方案,在生成原有参数化方案之后,对原有分布式计划中所有下推的子计算,根据计算下推条件判断是否与传入参数相关,如果所有下推的子计算都与参数相关,则生成完全下推plan, 并加入到原有执行计划中,在后续绑定参数时候,根据参数值 判定每个子计算是否都可下推到同一数据节点,如果条件成立,则执行完全下推plan.
详细设计
- 全局分布式执行计划缓存总体架构:
- 集群架构
PolarDB-for-PostgreSQL 分布式数据库集群中, 集群中节点类型分为Coordinator(CN),Datanode(DN), CN节点为协调节点,DN为数据节点。
- 详细设计:
本文讲述原理,分为四个部分介绍,第一部分分布式计划子计划分布统计计算, 第二部分分布式计划完全下推预判定。第三部分完全下推分布式计划生成, 第四部分分布式完全下推参数动态判定。
- 分布式计划子计划分布统计计算
- DN是数据节点,CN是计算节点,CN在生成分布式执行计划时,一个不能完全下推的分布式执行计划,通常通过子计划根据其分布信息从数据节点拉取数据,然后同其他子计划拉取的数据做join, 并将结果作为其他join算子的输入,或者作为结果数据。而不能下推的原因通常是因为每个子计划的分布不同,需要在不同节点上拉取数据,无法完全下推到单一节点执行。尤其是在未提供子计划分布判定输入时候,因为参数化的原因,子计算的分布计算无法得到参数值,无法判定子计算具体在哪个数据节点获取数据,而如果生成各子计划分布不同,最终生成的整个计划则无法完全下推。
- 分布统计计算负责将各个子计划中的分布信息统计并记录包括如下信息:
- 分布方式:包括 hash, modulo, replication, roundrobin
- hash 对分布列hash 获取32位hash 值,然后对DN总节点数取余
- modulo 分布列对DN总节点数取余
- replication 复制表,每个DN 节点
- roundrobin 按DN顺序依次分布
- 如果是hash或者 modulo 分布,则保存分布列信息。
- 记录 分布判定条件中常数值对应的参数序号
- 参数化的分布式计划中每个参数都对应一个序号,而这个序号同参数绑定顺序一致。序号从1开始,这里假定参数序号变量为paramId.
- 数据结构
- distributionType // 分布方式
- paramId // 参数序列号
- distributionExpr //分布列信息
- targetNode // 目标节点
- 具体统计逻辑
- 如果子计划是单表扫描
- 记录单表的分布方式
- 如果是hash或者modulo 分布,记录单表的分布列信息
- 如果子计划是join,且join是可下推的
- 记录下推join 的分布方式
- 如果是hash或者modulo 分布,记录join的分布列信息
- 计算分布判定条件中参数对应的参数序号
- 如果分布方式为replication,代表这是一个复制表,可以在任意节点获取数据则设置参数序号paramId = 0, 代表可以是任意节点
- 遍历所有下推语句中where中的表达式
- 如果表达式是a = b 模式,并且 其中一侧为分布列,另一次是参数化之后的参数,比如这里a 为分布列, b为参数,则执行步骤2 否则继续判断下一个下推表达式
- 记录 paramId = b->paramId
- 如果 paramId 依然未获取,则判断是否当前为join, 如果是join 则遍历 join ON 所有的表达式
- 如果表达式是a = b 模式,并且 其中一侧为分布列,另一次是参数化之后的参数,比如这里a 为分布列, b为参数,则执行步骤2 否则继续判断下一个下推表达式
- 记录 paramId = b->paramId
- 在查询优化阶段,在生成分布式计划中每个子计划的时候按上述过程将所有子计划的分布信息和参数信息进行统计。
- 分布式计划完全下推预判定
- 在查询优化阶段,遍历分布式执行计划,如果所有可下推的子计划中统计的paramId 都大于等于0 则认为存在整个分布式执行计划可完全下推的可能则执行完全下推的分布式执行计划。
- 完全下推分布式计划生成
- 在查询优化阶段,根据完全下推预判定,存在完全下推的可能,生成完全可下推的执行计划
- 完全下推代表着整个语句是可下推到DN某一节点执行的。所以需要生成一个完整下推的sql 语句用于在DN中执行的可执行计划。
- 将当前经过parse, analyze ,rewrite 之后的查询树,通过deparse 的过程,将其还原为 可执行sql.语句, 因查询树中已经包含了当前所有的信息,所以通过deparse 的sql 语句能够满足完全下推的需要。
- 将 生成的sql 封装成定制计划,并标记完全下推计划的执行节点为空。
- 将生成的定制计划,保存到原有的参数化的分布式plan中。用于满足完全下推条件时,替换原有的分布式plan。
- 分布式完全下推参数动态判定
- 参数绑定时,执行器执行计划之前,根据传入的参数对每个子计划判定并获取其执行节点信息,并实施执行计划替换。
- 如果每个子计划执行节点唯一, 且相同 则代表整个执行计划是可以完全下推的。
- 节点计算和选择
- 子计划如果是replication 分布,随机选取其中一个节点作为执行节点。
- 子计划如果是hash 或者modulo 分布,则根据分布列和参数值计算执行节点。
- 如果所有子计划都为replication分布,则以第一个子计划的执行节点作为最终执行节点
- 已上图为例
- A 子计划为replication 分布, 得到执行节点为1
- B 子计划为replication分布, 得到执行节点为2
- C 子计划为replication分布, 得到执行节点为3。
- 最终去遍历时第一个碰到的子计划这里为A, 所以最终执行节点为1。
- 如果所有子计划都为hash 或者 modulo 分布,则必须所有子计划的执行节点唯一且相同,作为最终执行节点。
- 已上图为例
- A 子计划为hash 分布,对应参数为第一个参数, 经计算得到执行节点为1.
- B 子计划为hash 分布,对应参数为第二个参数, 经计算得到执行节点为1.
- C 子计划为hash 分布,对应参数为第三个参数, 经计算得到执行节点为1.
- 所以最终执行节点为1。
- 如果有子计划为replication分布,亦有hash 或者modulo 分布,则判断 所有hash 或者modulo 分布的子计划执行节点唯一且相同,则忽略replication 分布的执行节点,以hash 或者modulo 分布的执行节点为最终执行节点。
- 已上图为例
- A 子计划 为hash 分布,对应参数为第一个参数, 经计算得到执行节点为1
- B 子计划为modulo分布, 对应参数为第二个参数, 经计算得到执行节点为1
- C 子计划为replication分布, 得到执行节点为2。
- 所以最终执行节点为1。
- 如果第一步操作获取了最终执行节点,则认为分布式执行计划可完全下推
- 从分布式执行计划中获取完全下推定制计划
- 将获取的最终执行节点信息,更新到定制计划中。
- 将完全下推定制计划,替换掉原有分布式执行计划
- 执行替换好的执行计划。