





大家好,今天和大家分享一下工作中mongo 全文检索的一个小的案例。
今天早上收到了开发小伙伴的企业微信: 他的python 脚本里使用了正则表达式进行文本的模糊匹配,
从而触发不了原本的存在索引
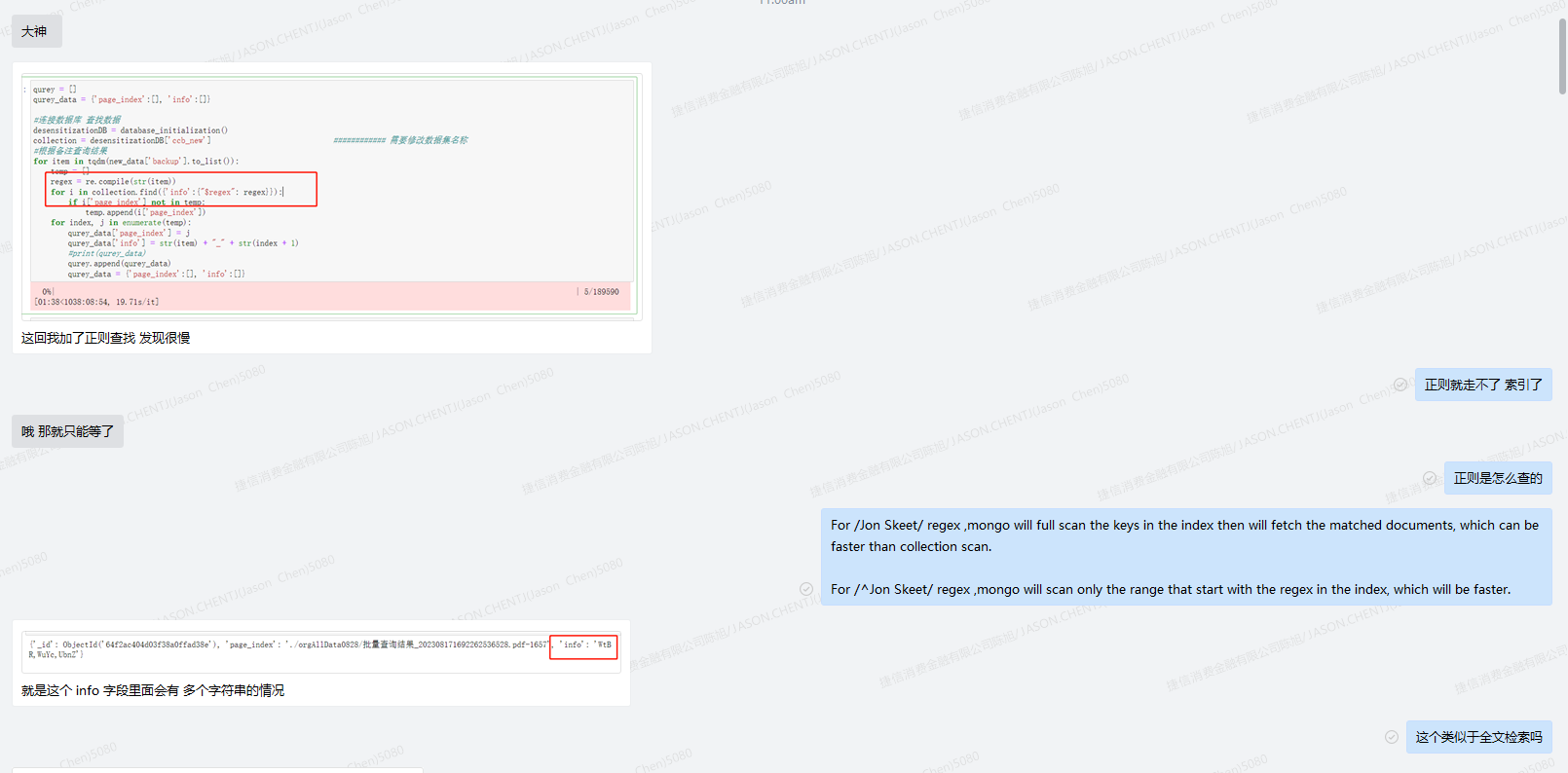
我的印象中是mongo 支持原生的全文索引,我找了找文档上的语法:
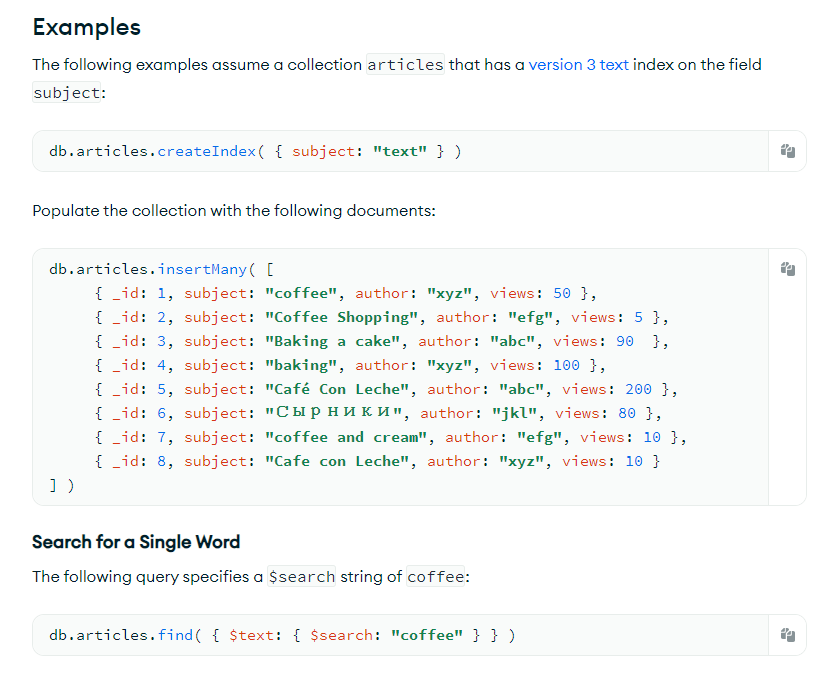
照猫画虎,我也来创建一个 full text index:
(生产环境需要加上 {“background”:“true”} , 在线创建索引,不会block DML)
MongoCapp24004:PRIMARY> db.ccb_new.createIndex( { info: "text" } ); { "createdCollectionAutomatically" : false, "numIndexesBefore" : 2, "numIndexesAfter" : 3, "ok" : 1, "$clusterTime" : { "clusterTime" : Timestamp(1697174421, 1), "signature" : { "hash" : BinData(0,"nuNRCX6hIKrz/JVrvxfFk9KjCSU="), "keyId" : NumberLong("7251148180090257409") } }, "operationTime" : Timestamp(1697174421, 1) }
我们来测试一下 基于全文检索的查询:貌似没有区分大小写
MongoCapp24004:PRIMARY> db.ccb_new.find( ... { ... $text: { $search: "XvJm" } ... } ... ); { "_id" : ObjectId("6511f5d892a4b8d8a6df6831"), "page_index" : "./orgAllData/批量查询结果_202309011693558934864.pdf-962", "info" : "xvJm" } { "_id" : ObjectId("6511c4d592a4b8d8a6d22756"), "page_index" : "./orgAllData/批量查询结果_202309011693557412647.pdf-1856", "info" : "xVJm" } { "_id" : ObjectId("6511649692a4b8d8a6b7313a"), "page_index" : "./orgAllData/批量查询结果_202308311693473757279.pdf-3884", "info" : "Xvjm" } { "_id" : ObjectId("6512015692a4b8d8a6e36c55"), "page_index" : "./orgAllData/批量查询结果_202309011693558370373.pdf-3384", "info" : "XvJm" } { "_id" : ObjectId("6511ce7792a4b8d8a6d44c81"), "page_index" : "./orgAllData/批量查询结果_202308311693473097267.pdf-1514", "info" : "xvJm,y430" } { "_id" : ObjectId("6511649692a4b8d8a6b72870"), "page_index" : "./orgAllData/批量查询结果_202308311693473757279.pdf-3772", "info" : "XvJM,Xz53,Y1sH,Y2wx" } { "_id" : ObjectId("6511649692a4b8d8a6b7160c"), "page_index" : "./orgAllData/批量查询结果_202308311693473757279.pdf-3538", "info" : "XvjM,Y2Vc,Y2nS,Y3CC" } { "_id" : ObjectId("6511239b92a4b8d8a6a49fcd"), "page_index" : "./orgAllData/批量查询结果_202309011693555411022.pdf-3377", "info" : "xJX2,xLTn,xLh6,xVjM" }
继续查文档: 需要添加一个查询的参数

直接反馈给了开发小伙伴:
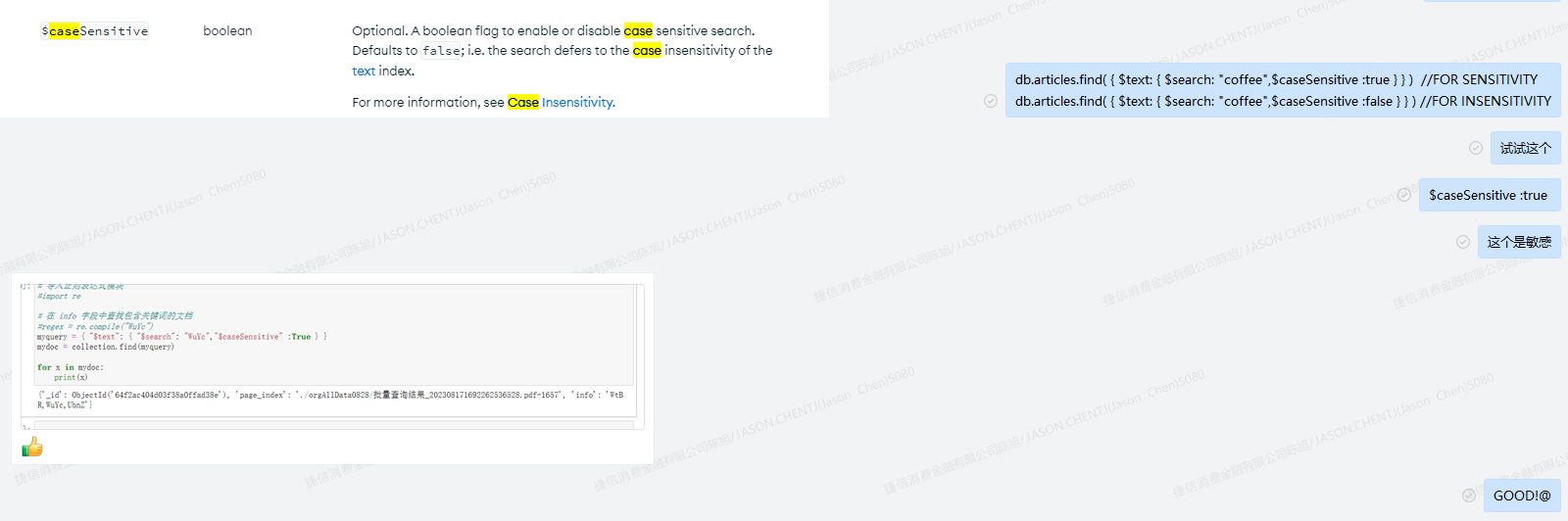
本以为事情就此就解决了。
However,
开发小伙伴经过测试后,发生了诡异的事情,一些全文查询的语句是出现了返回的记录比预期多的情况:
本来是按照 eWdY进行模糊匹配,但是匹配出来了 EWdI,ewDi …
明明是最后一个字母是Y 为什么匹配成了字母 I
MongoCapp24004:PRIMARY> db.ccb_new.find( ... { ... $text: { $search: "eWdY",$caseSensitive :false } ... } ... ); { "_id" : ObjectId("6511e59392a4b8d8a6dafa92"), "page_index" : "./orgAllData/批量查询结果_202309011693557890203.pdf-2825", "info" : "EWdI" } { "_id" : ObjectId("65118e6d92a4b8d8a6c26c31"), "page_index" : "./orgAllData/批量查询结果_202309011693558523115.pdf-1431", "info" : "ewDi" } { "_id" : ObjectId("65118e6d92a4b8d8a6c23935"), "page_index" : "./orgAllData/批量查询结果_202309011693558523115.pdf-769", "info" : "eWdI" } { "_id" : ObjectId("6511718b92a4b8d8a6bac9f0"), "page_index" : "./orgAllData/批量查询结果_202309051693871938903.pdf-3150", "info" : "ewDi" } { "_id" : ObjectId("6511718b92a4b8d8a6bab9af"), "page_index" : "./orgAllData/批量查询结果_202309051693871938903.pdf-2977", "info" : "ewDI" } { "_id" : ObjectId("651131ad92a4b8d8a6a80364"), "page_index" : "./orgAllData/批量查询结果_202309051693872224071.pdf-1168", "info" : "EwdI" } { "_id" : ObjectId("6511718b92a4b8d8a6ba2e73"), "page_index" : "./orgAllData/批量查询结果_202309051693871938903.pdf-1510", "info" : "eWDy" } ... ...
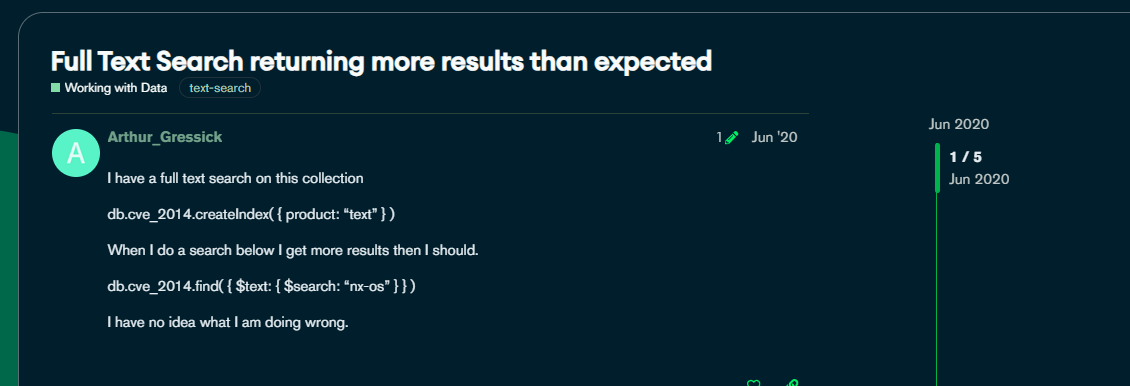
带着好奇我们科学上网一下看看: https://www.mongodb.com/community/forums/t/full-text-search-returning-more-results-than-expected/6070
(MONGO这块国内的文章都是入门介绍的比较多,深入的比较少)
貌似一名国外的网友也遇到了这种情况:
MONGO 论坛上的大神给出的分析是:查看执行执行计划中的 queryPlanner.winningPlan.parsedTextQuery
目的是看看 我们传入的查询文本被mongo解析成了的真正的文本是什么?
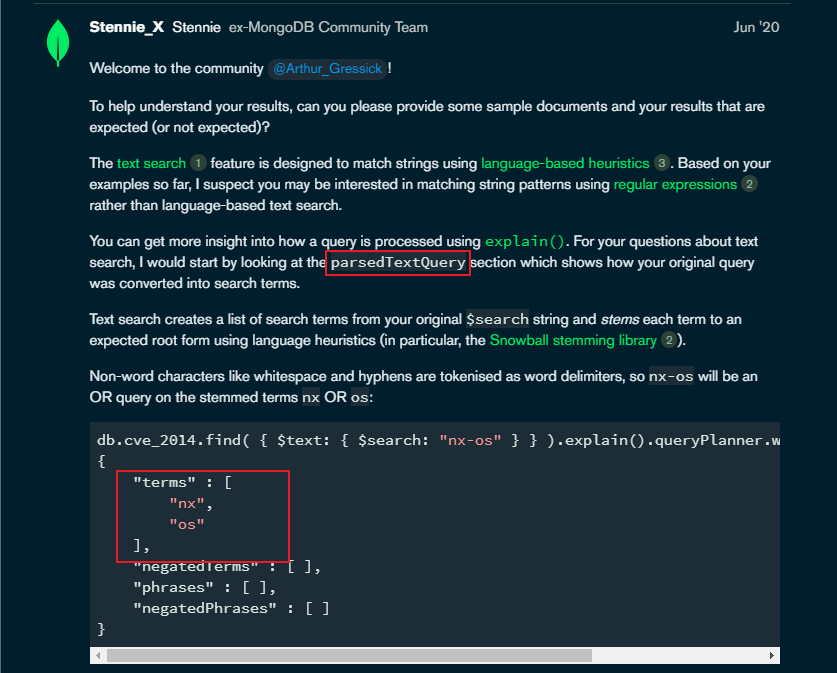
我们来看一下这个的执行计划中的parsedTextQuery: 我的天, 果然是解析成了 eWdi
MongoCapp24004:PRIMARY> db.ccb_new.find( ... { ... $text: { $search: "eWdy",$caseSensitive :true } ... } ... ).explain().queryPlanner.winningPlan.parsedTextQuery { "terms" : [ "eWdi" ], "negatedTerms" : [ ], "phrases" : [ ], "negatedPhrases" : [ ] }
具体为什么要进行转换呢?
全文检索的设置的语言有关,简单的理解为根据每个国家的不同的语言,生成不同的语言的词典。
这个有官方的名词叫做 stemming algorithm(词干提取): https://en.wikipedia.org/wiki/Stemming
https://snowballstem.org/demo.html 通过这个网站可以测试一下语言的转换; 
接下来,我们目的明确了我们要检索的是一个字符串,而不是基于某种自然语言(NLP)下的查询:
MongoDB 默认的 full text index 是english的:同时发现了我可以指定语言为 none, 这样就可以跳过了 steemming.
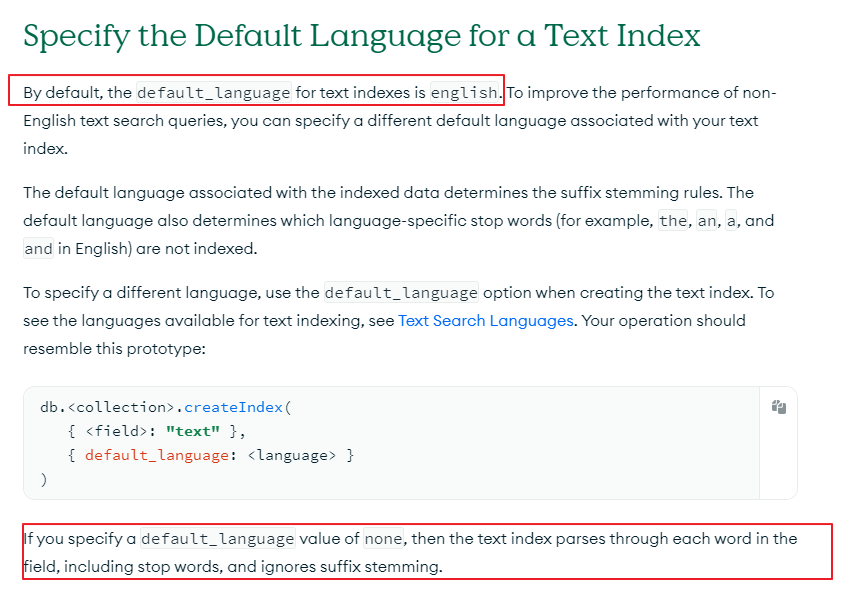
我们删除索引,来重建并指定为 default_language 为none:
MongoCapp24004:PRIMARY> db.ccb_new.createIndex( { info: "text" },{default_language:"none"} ); { "createdCollectionAutomatically" : false, "numIndexesBefore" : 2, "numIndexesAfter" : 3, "ok" : 1, "$clusterTime" : { "clusterTime" : Timestamp(1697179317, 1), "signature" : { "hash" : BinData(0,"z4TT2Q+3/4jmHVKUWNdDoDpxUFs="), "keyId" : NumberLong("7251148180090257409") } }, "operationTime" : Timestamp(1697179317, 1) }
再次查询测试: 这会完美符合我们的预期了
MongoCapp24004:PRIMARY> db.ccb_new.find( ... { ... $text: { $search: "eWdy",$caseSensitive :true,$language:"none"} ... } ... ); { "_id" : ObjectId("6511718b92a4b8d8a6ba418e"), "page_index" : "./orgAllData/批量查询结果_202309051693871938903.pdf-1715", "info" : "eVI5,eWdy,eXDb" } { "_id" : ObjectId("6512829a87401b1b56aff71d"), "page_index" : "./tempOrgData/批量查询结果_202309251695621419111.pdf-341", "info" : "eJZI,eUL1,eWdy,eXSB" }
我们再次验证执行计划中的parsedTextQuery: 这次看是正常的eWdy
MongoCapp24004:PRIMARY> db.ccb_new.find( ... { ... $text: { $search: "eWdy",$caseSensitive :true,$language:"none"} ... } ... ).explain().queryPlanner.winningPlan.parsedTextQuery; { "terms" : [ "eWdy" ], "negatedTerms" : [ ], "phrases" : [ ], "negatedPhrases" : [ ] }
最后我们总结一下:
1.在创建全文检索的时候要确定这个mongo查询的目的是真实的语言检索(NLP),还是只是为了规避正则表达式的性能问题从而选择了全文检索的方式。
2.如果是真的基于某种语言的检索(查询生活中的单词和短语),那么创建full text index的时候需要指定default_language,默认是english. (目前还不支持中文,可能是过于复杂的原因)
支持的语言参考: https://www.mongodb.com/docs/manual/reference/text-search-languages/#std-label-text-search-languages
3.如果像处理字符串一样(类似于编码什么的,并不是实际的英文单词),只是为了替代正则表达式,通过 full text index 来提高性能,那么 创建的时候需要指定 default_language 为none.
Have a fun 🙂 !
