





导读
随着数据库规模急速扩大,各种类数据库落地运用,传统运维能力逐渐跟不上业务发展,其管理方式难于满足业务方面对数据库系统稳定性、可用性、灵活性的高要求。在用户需求驱动下,新数科技数据库云平台体系经历了从人力运维到工具化、标准化、自助化、自动化的转型之路,不断推动着智能运维在数据库领域的思考和实践。

什么是LangChain?
LangChain框架完全开源,其设计目标是为开发者方便地建立基于LLM的应用。LangChain相当于开源版的GPT插件,简化了大模型的集成流程,提供了一系列简单易用的API和工具包,让开发者可以只关注于应用自身的逻辑实现。同时,该框架能够有效地应对海量数据、高并发需求,并进行个性化的建模与整合,解决一些复杂的问题。
因其上述特点,LangChain在国内外拥有诸多实践案例,通过访问产品知识库提供更准确和个性化对话助推销售业务、为图像生成描述性的标题等,LangChain官网上记录了数百个使用该框架的开源项目。在商业化实践中,AWS集成LangChain的智能搜索解决方案在电商、制造、金融、教育和医疗等行业均有落地。国内部分向量数据库厂商也通过与LangChain的对接为数据查询效率带来一些潜在的提升。
▲图 | 使用LangChain的开源项目(来源:LangChain官网)
LangChain由多个模块组成,主要包括:
(1) LLM:LangChain使用深度学习模型来理解和处理自然语言。这些模型经过训练,可以从输入的文本中提取有意义的信息,并生成机器可以理解的表示形式。通过该框架提供的接口和功能将有助于与LLM的交互,方便开发者集成到本地应用程序中。
(2) Prompt:使用LangChain的提示功能可以将需要改动的部分抽象成变量,在具体情况下替换成需要的内容,实现一次定义、多次使用的效果。LangChain提供了预先设计好的提示模板,可以用于不同任务中,同时,为了满足各种需求,也可以自定义提示模型。
(3) Memory:LLM的有效性在很大程度上取决于其利用历史上下文信息的能力。面对不同的应用需求,需要考虑到历史交互记录等信息的存储问题,即“内存”。LangChain的内存管理通过适当的设计和调整来平衡存储容量和模型性能,并且提供不同的内存类用来管理与LLM的对话上下文,如保存所有上下文的ConversationBufferMemory类、以对话轮数为单位设置最大轮数限制的ConversationBufferWindowMemory类和以token个数为单位设置最大个数限制的ConversationTokenBufferMemory类等;
(4) Chain:链的工作原理是允许将多个组件组合在一起以创建一个单一的、连贯的任务,其基本单元是Chain。落实到开发场景中,通过与LLM和提示词的结合,可以构建出各种结构的链式操作,对文本和数据执行一系列操作。按照输入/输出的不同方式,Chain可分为以下类别:
基础链 LLMChain:LLMChain 是最基本的链。接受一个提示模板,将其与用户输入进行格式化,并返回LLM的响应。
顺序链:将基础链按照顺序前后组合起来,上一个基础链的输出是下一个基础链的输入,顺序链又包括以下两种:
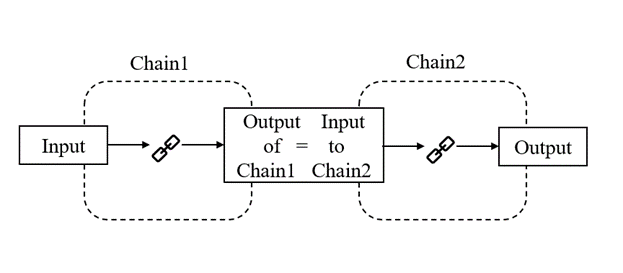
▲图 | SimpleSequentialChain顺序链
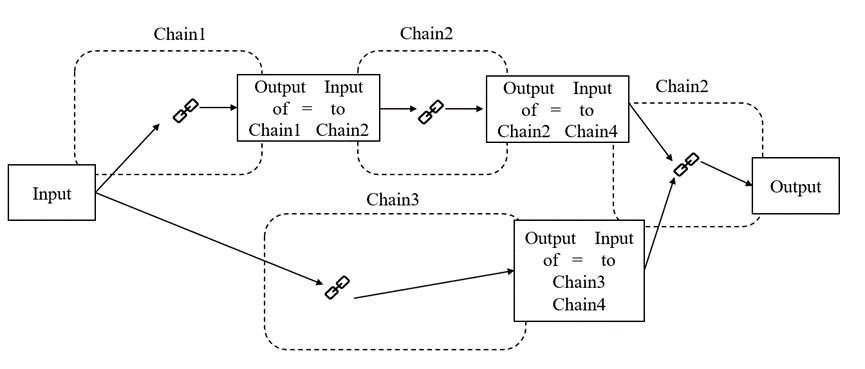
▲图 | SequentialChain顺序链
路由链RouterChain:该方法往往配合下游任务一起使用,根据输入的内容自由路由到最相关的下游Chain,其过程如下图所示。
(5) Agents代理:在LangChain框架中负责决策制定以及工具组的串联,可以根据用户的输入决定具体调用哪个工具,并且利用其掌握的一系列工具去执行这个行动。
将Agents视为LLM的工具,就像人类使用计算器进行数学计算或在 Google 中搜索信息一样,Agents允许LLM做同样的事情。
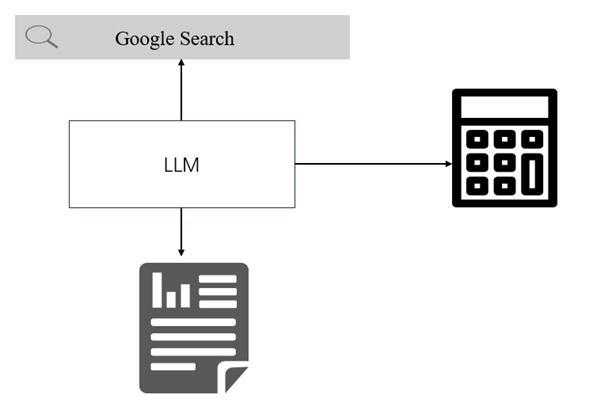
▲图 | Agents代理
LangChain Agent是一个实体,它可以被理解为是一个驱动决策制定的实体。LangChain Agent可以访问一组工具,并且根据用户的输入决定调用哪个工具。Agent帮助用户构建复杂的应用程序,这些应用程序需要自适应和特定于上下文的响应。它们依赖于与用户输入相关的任务和事件以及与其他相关任务和事件相关的上下文。当存在取决于用户输入和其他因素的未知交互链时,代理将非常有用。

数据库智能问答,借助LangChain与AI对话
相比于复杂的软件交互,自然语言对话是一种效率更高的智能交互方式。数据库智能问答系统是数据库可以根据输入自动选择或生成相应的答案,从而达到帮助人们解决数据库领域的相关问题。
完整的智能问答系统具体思路是,通过提供一些数据库领域相关文档,LangChain根据文档内容提取关键信息,系统借助LLM根据关键信息提供深入的分析和推测,从而能够回答与文档内容相关的各种问题。
其中,Embedding和向量存储是数据库智能问答系统的核心技术。Embedding将数据库相关文本转化为能够表征文本语义的向量,向量存储技术则将文本分解成块并存储于向量数据库中。具体流程如下图所示:
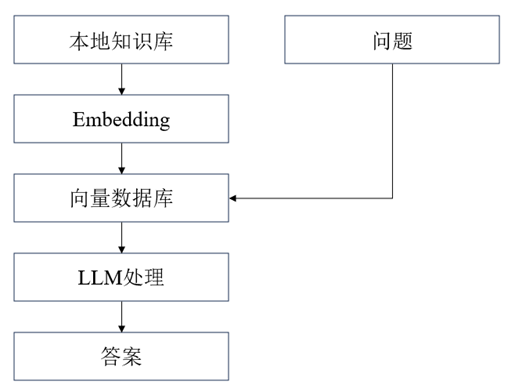
▲图 | 流程图
embedding技术能够将文本表示为一系列向量,这些向量通过神经网络模型进行训练,从而捕捉词汇之间的语义和上下文关系。通过这种方法,数据库领域相关文档可以被转化为一系列向量,如下图所示。
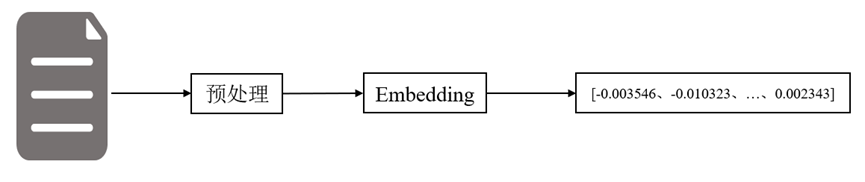
▲图 | 相关文档可以被转化为一系列向量
向量存储技术将文本细分为不同的块,并将其以向量形式存储于向量数据库之中。这些块可以是单词、短语或其他的语义单位。借助向量数据库,能够迅速查找和搜索与查询相关的文本块,提高处理速度和效率。
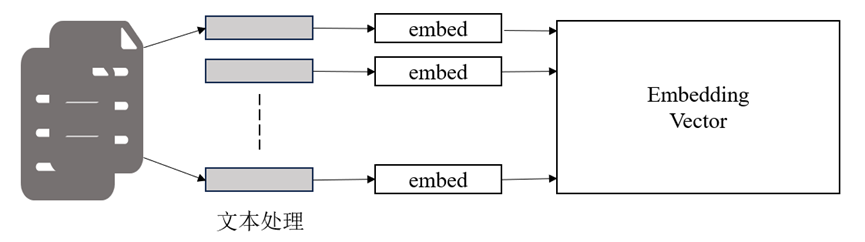
▲图 | 向量存储技术
在使用基于数据库智能问答系统时,可以提出与本地知识库相关的问题,这些问题会转换为向量查询。LangChain使用这些查询来搜索向量数据库,找到与问题相关的文本块。
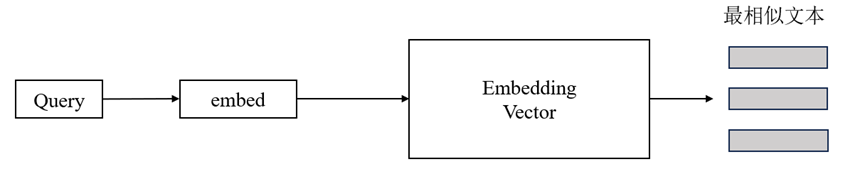
▲图 | 相似文本查询
LLM在处理文本时,可使用神经网络和自然语言处理技术,对文本进行分析和推理,以帮助大模型处理和回答与数据库相关的问题,从而进一步提高数据库管理平台的智能运维能力。
Demo例程介绍
query: str,
prompt_template: str = PROMPT_TEMPLATE, ) -> str:
context = "\n".join([doc.page_content for doc in related_docs])
prompt = prompt_template.replace("{question}", query).replace("{context}", context)
return prompt
测试输出
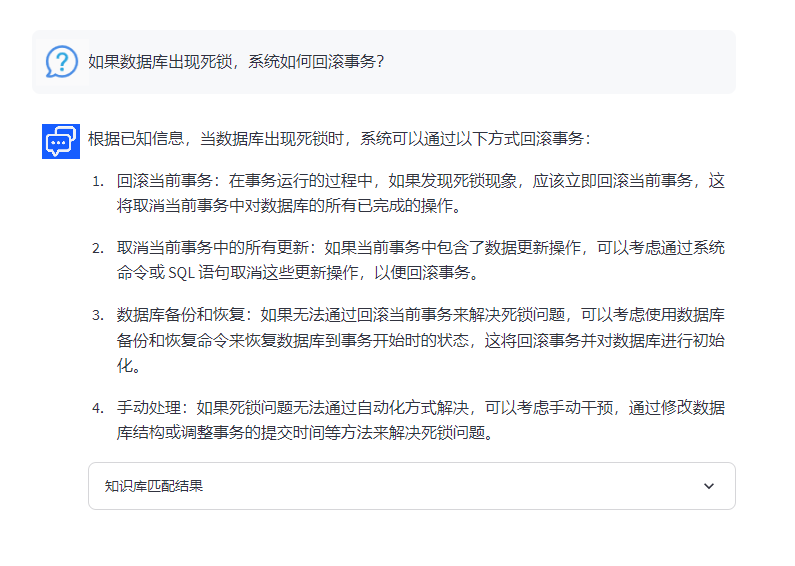
Q:如果数据库出现死锁,系统如何回滚事务?
A:当数据库检测到死锁时,系统通常会回滚其中一个事务来解决死锁。具体来说,大多数数据库系统都有内置的死锁检测机制,当检测到死锁时,它们会自动回滚其中一个事务,以解除死锁状态。
在回滚事务时,系统会撤销该事务的所有更新操作,并释放被占用的资源。这样其他事务就能继续执行,不会受到死锁的影响。
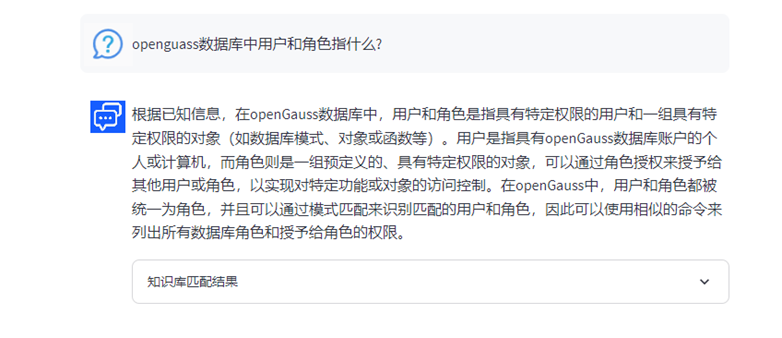
Q:openGauss数据库中用户和角色指什么?
A:在openGauss中,用户和角色是数据库系统的两个重要概念。
用户是指可以连接到数据库并执行操作的实体。用户通常通过用户名和密码进行身份认证。在openGauss中,用户可以执行诸如使用工具连接数据库、访问数据库对象以及执行SQL语句等操作。
角色则是一种特殊的用户,可以包含其他用户或角色,并且可以被授予权限。角色用于简化权限管理和控制。在openGauss中,角色是一种权限集合的载体,代表了一个或一组数据库用户的行为约束。与用户相比,角色不能具有登录数据库并执行SQL的能力。

https://python.langchain.com.cn/docs/modules/model_io/prompts/prompt_templates
https://arxiv.org/pdf/2308.05481.pdf

关于新数

推荐阅读

