




某K8S主机集群的node节点xxxxxxx在2023年8月2日13:31分,进程数达1万以上,5分钟平均负载在1600左右。
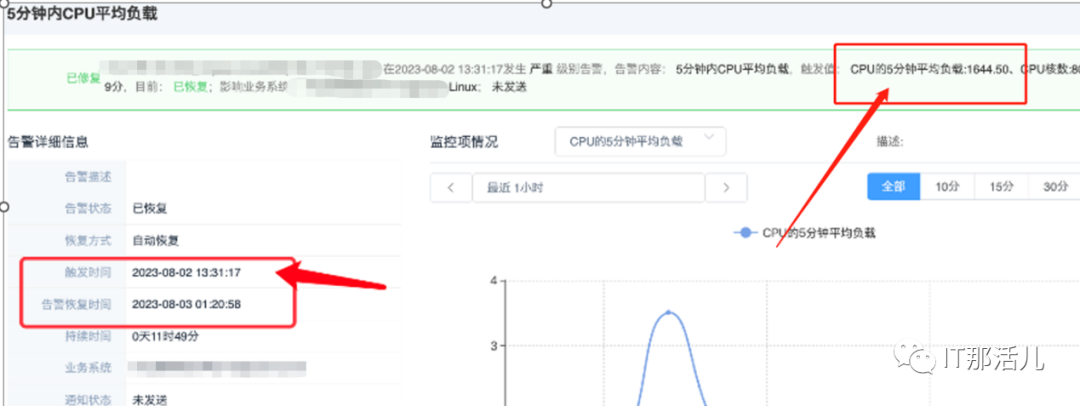
2.1 资源使用情况分析
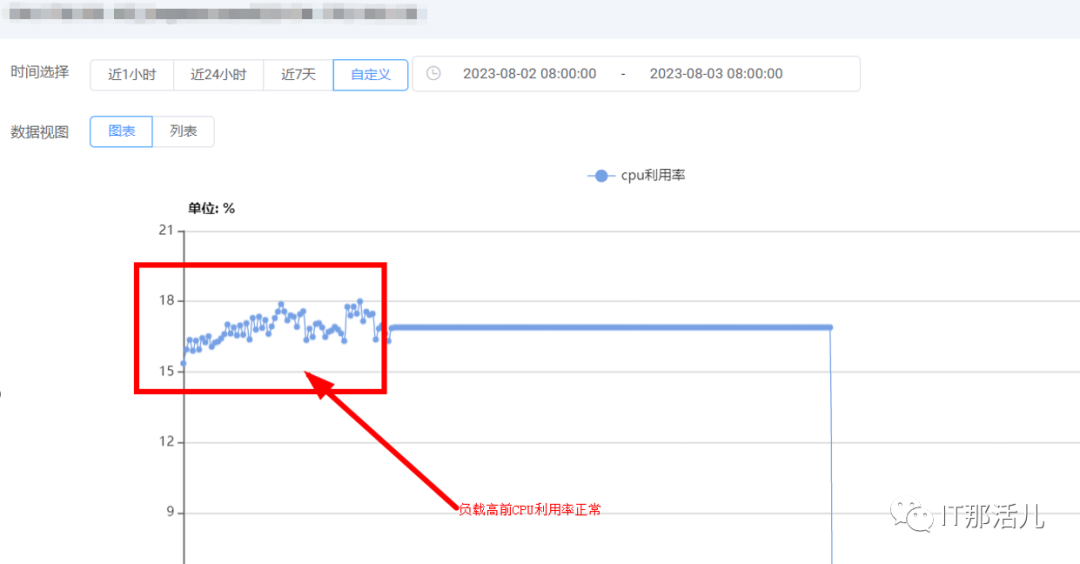
1)负载高前CPU使用率正常
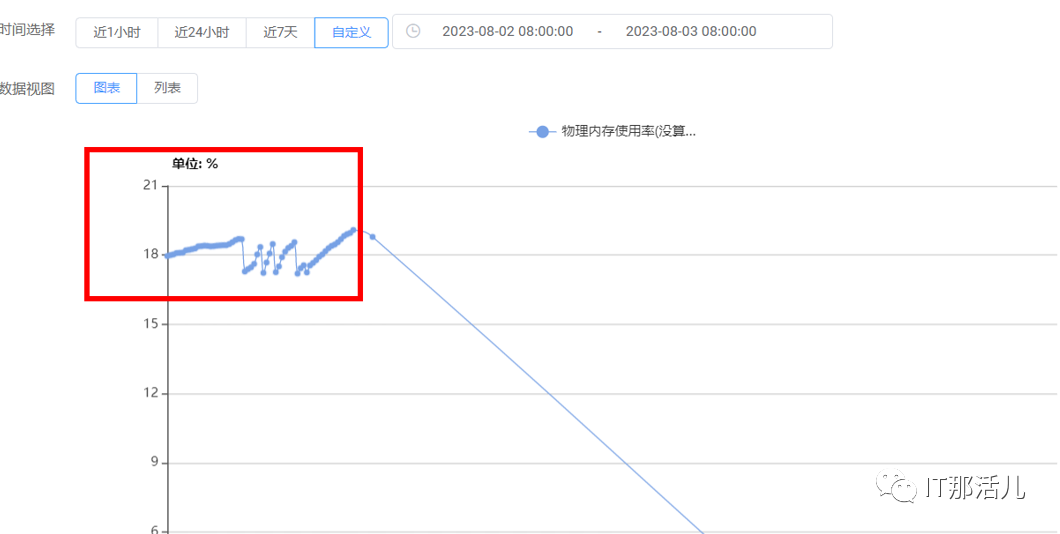
2)负载高前内存使用率正常
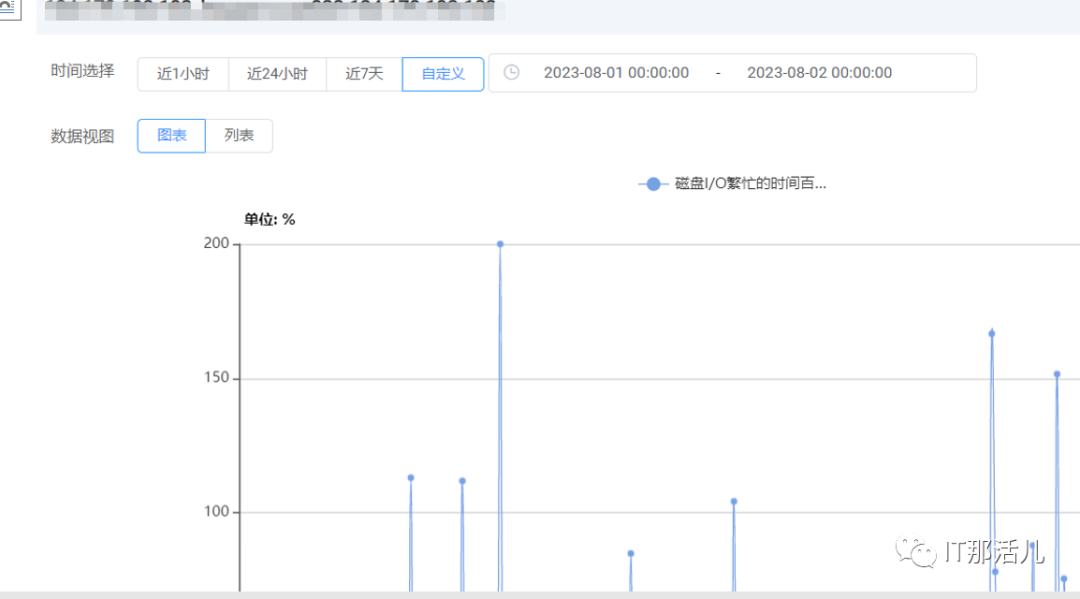
3)负载高前IO等待及队列一直存在突增的情况
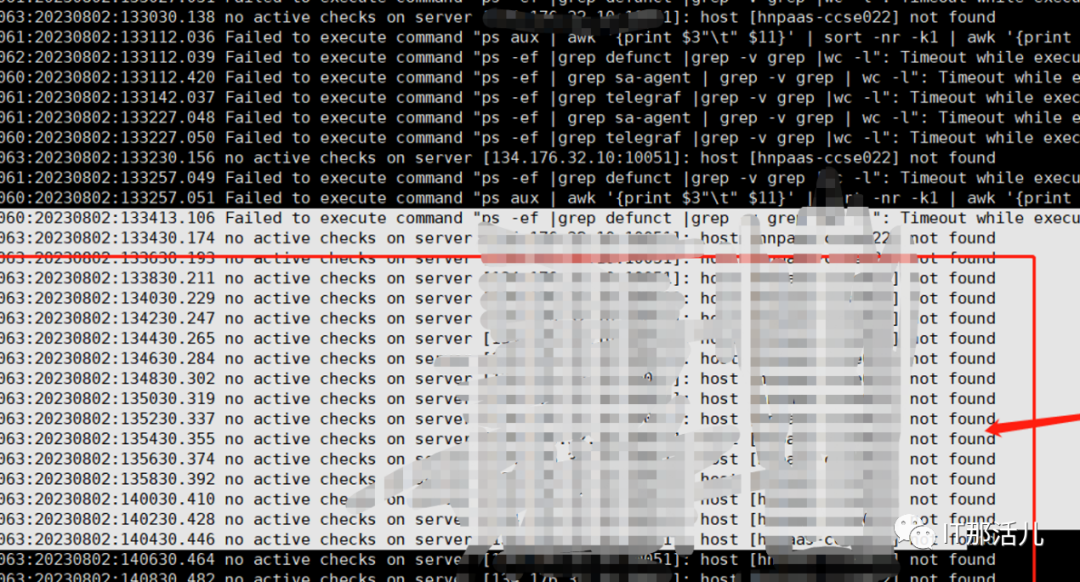
2.2 Zabbix代理进程无法采集日志分析
1)Zabbix agent代理日志分析
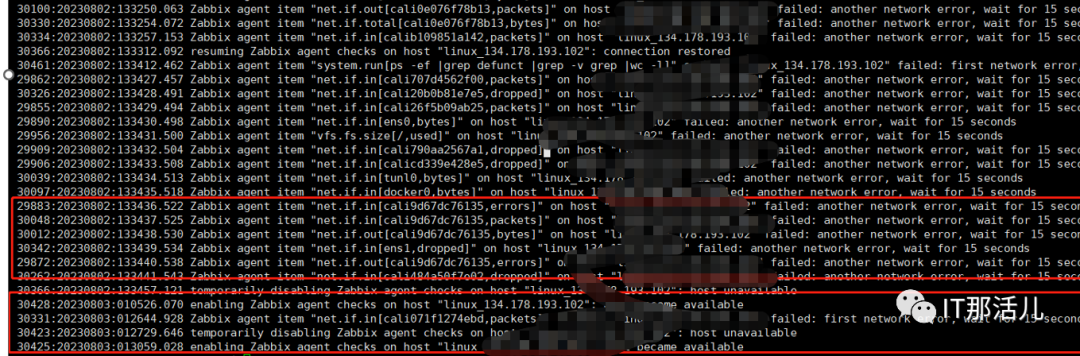
2)Zabbix proxy日志分析
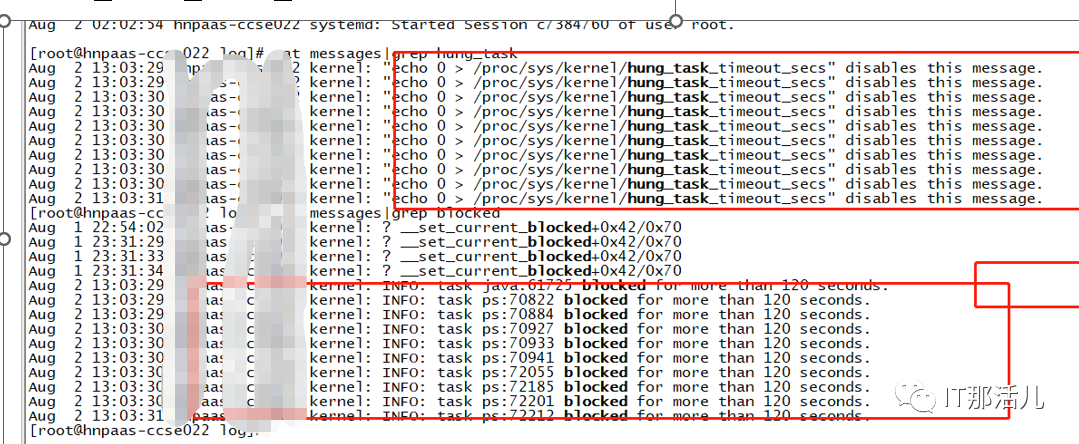
2.3 操作系统messages日志分析
1)触发缓存脏页数量全量从内存写入磁盘

rwsem_down_read_failed+0x139/0x1c0
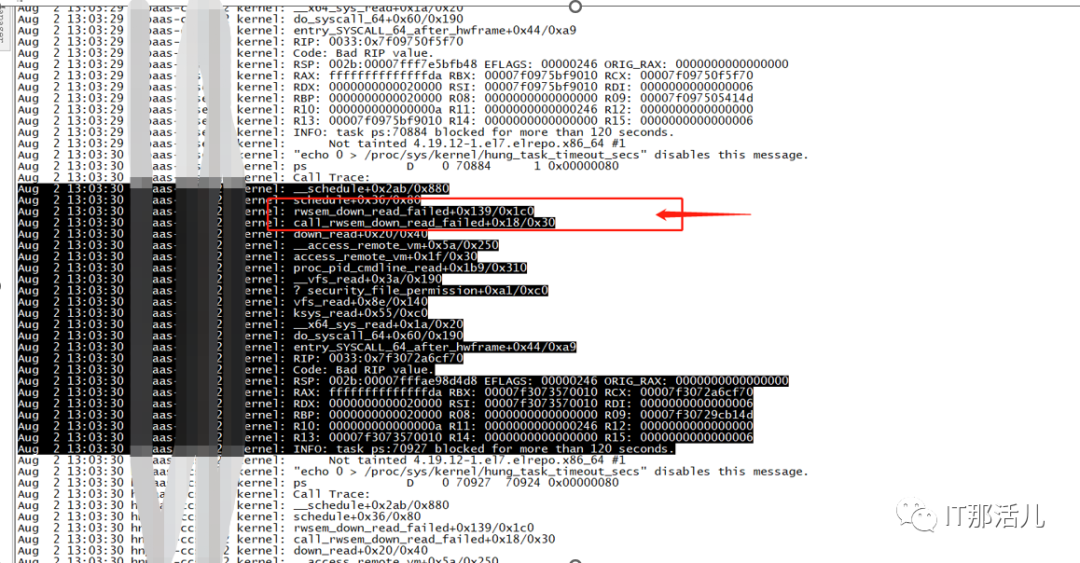
2)K8S集群所属主机分析 Master节点IO等待相对高。
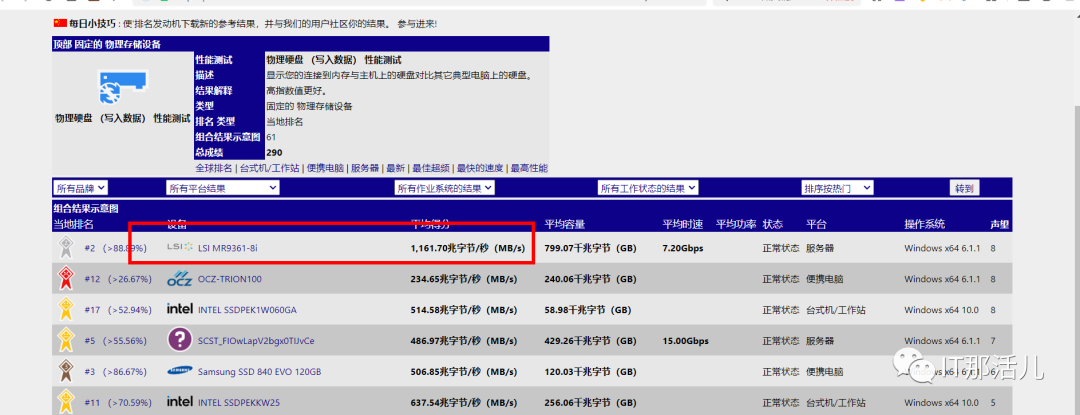
备注:生产环境当前配置 vm.dirty_background_ratio = 10(当文件系统缓存脏页数量达到系统内存的10%时,触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存); vm.dirty_ratio = 20 当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞;。
4)CCSE集群IO压力不均衡,Master节点除了承载集群管理压力还要承载业务压力。
4.1 写缓存触发问题通常出现在大内存的主机,调整内核参数
vm.dirty_ratio 由 20% 修改为10%; vm.dirty_background_ratio 由10% 修改为5%。
本文作者:唐田寿(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
