




小伙伴们大家好,我是阿Q。
中秋国庆假期严重不足,大家还玩儿的好嘛?
阿Q给大家的建议是,好好玩三天,后边五天抓紧时间投入到找工作中,只要足够努力,你一定就会拿到自己满意的offer。
今天给大家分享一位小伙伴在秋招面试美团的面经,信息量还是挺大的,不愧是“开水团”,大家记得认真看一看,有什么模棱两可的内容大家还是需要先看书本来确定的,然后再与我探讨这个问题的准确性,这样既可以提高效率,也让你会有一个更好的习惯,那我也很会感谢你。
来源:
https://www.nowcoder.com/discuss/535880965327949824
一面
生命周期:指在客户端和服务器之间建立一次连接后,多次交换数据的通信模式。这个连接在一段时间内保持打开状态,可以用于多次请求和响应。 应用场景:适用于需要频繁交换数据、维持实时性、或具有持久性通信需求的场景。例如,聊天应用、在线游戏、实时监控系统等通常会使用长链接,以便实时传递数据或事件通知。 实现:(二选一) 基于TCP的持久连接:在TCP通信中,一旦建立连接,客户端和服务器可以通过发送和接收数据来保持连接的活动状态。需要确保定时发送心跳或保持活动,以防止连接超时关闭。 WebSocket:WebSocket是一种在HTTP基础上建立的全双工通信协议,允许客户端和服务器之间建立持久连接,并支持双向实时通信。 使用长轮询(Long Polling):长轮询是一种模拟长连接的技术,其中客户端发送请求并保持打开的连接,服务器在有数据可用时响应请求。虽然不是真正的持久连接,但它可以实现类似的效果。
生命周期:指在每次通信之后立即关闭连接的模式。每次通信都需要重新建立连接和关闭连接。 应用场景:适用于一次性请求和响应的场景,例如,HTTP的标准请求和响应、文件下载等。 实现:短连接的实现通常遵循以下步骤: 客户端向服务器发起连接请求。 服务器响应连接请求,建立连接。 客户端发送请求。 服务器处理请求并发送响应。 连接关闭。
字符串(String): Redis 中的字符串是二进制安全的,可以存储文本、JSON、二进制数据等。 可以执行字符串的增减操作,如追加、截取等。 常用于缓存、计数器、分布式锁等场景。 哈希(Hash): Redis 哈希是一个字段和值的映射表。 用于存储对象,每个对象可以包含多个字段和字段值。 常用于存储和查询具有多个属性的数据。 列表(List): Redis 列表是一个有序的字符串元素集合。 可以在列表的两端执行元素的插入和删除操作。 常用于队列、栈、消息发布和订阅等。 集合(Set): Redis 集合是一个无序的字符串元素集合。 不允许重复的元素存在,且元素是唯一的。 支持集合的交集、并集、差集等操作。 常用于存储唯一值和执行集合操作。 有序集合(Sorted Set): 有序集合是一个有序的字符串元素集合,每个元素都有一个分数(score)。 元素根据分数排序,可以按照分数范围进行检索。 常用于排行榜、范围查询等。 位图(Bitmap): 位图是一个位序列,每个位可以设置为 0 或 1。 支持位操作,如与、或、非等,可以执行高效的位运算。 常用于标记和统计布尔值信息。 超级字符串(HyperLogLog): 超级字符串是一种用于统计唯一元素的数据结构。 通过估算基数(集合中不同元素的数量)来节省内存。 常用于基数统计场景,如统计访问网站的独立访客数量。 地理空间数据(Geospatial Data): Redis 支持地理空间数据的存储和查询,包括点、距离计算等功能。 常用于地理位置服务、位置基础分析等。
Redis 将数据存储在内存中,这使得数据访问非常快速。内存的读写速度比磁盘快得多。 Redis 使用非阻塞的 I/O 操作,充分利用了现代操作系统的异步 I/O 特性。这意味着 Redis 可以在等待磁盘操作完成时继续处理其他请求,而不会被阻塞。 Redis 使用事件驱动的方式来处理客户端请求。它使用单个线程来监听和处理多个客户端连接,而不需要为每个连接创建一个新线程。这降低了线程管理开销,使 Redis 更加高效。 Redis 内置了各种高效的数据结构,如哈希表、有序集合和位图等。这些数据结构经过精心优化,以提高性能和减少内存消耗。 Redis 提供了多种持久化选项,包括快照(snapshot)和追加日志文件(append-only file),这些选项允许用户根据需求权衡性能和数据安全。 Redis 避免了复杂的锁和多线程竞争,因为它在单线程中按顺序执行命令,这减少了竞争条件和锁带来的开销。 Redis 不仅仅是一个键值存储,它支持多种数据结构,如字符串、列表、哈希、集合、有序集合等。这种多样性使 Redis 可以应对不同的数据访问模式。
Redis 的内存有限,当存储的数据量超过可用内存时,会触发性能瓶颈。在这种情况下,Redis 可能会使用虚拟内存,但这会导致性能下降,因为虚拟内存是基于磁盘的。 如果开启了持久化选项(如 RDB 快照或 AOF 日志),在执行持久化操作期间,Redis 的性能可能会受到一定影响,特别是在写入密集型工作负载下。 尽管 Redis 单线程模型可以高效处理并发请求,但如果并发连接数过高,可能会导致竞争条件和性能下降。在这种情况下,需要考虑使用连接池和分片等技术。 在执行复杂的查询操作或大规模的集合操作时,Redis 的性能可能会下降。一些查询操作的时间复杂度可能不是常数级别的,而是与数据集的大小相关。 当 Redis 服务器和客户端之间存在网络延迟时,客户端请求的响应时间可能会增加,从而导致性能下降。
增加服务器的内存和计算资源,以容纳更多数据和连接。 使用 Redis 分片或集群来分散负载,提高并发处理能力。 确保查询操作是高效的,使用合适的数据结构,避免不必要的操作。 定期监控 Redis 的性能指标,识别性能问题并根据需要进行调整。
当字符串类型的键中存储了大量的文本或二进制数据时,会导致读写操作变慢。这通常是因为 Redis 是单线程的,操作一个大字符串会占用较长时间。 当集合、列表或有序集合中包含大量的元素时,操作这些数据结构的复杂度会增加,导致操作耗时增加。 如果哈希类型的键包含大量字段和字段值,对该键执行操作也会变慢。
使用 MEMORY USAGE
命令:可以使用 Redis 的MEMORY USAGE
命令来查看特定键的内存占用情况,从而确定哪些键是大键。
MEMORY USAGE key_name
使用 SCAN
命令遍历键:使用SCAN
命令可以遍历数据库中的所有键,检查是否存在大键。
SCAN 0 COUNT 1000 # 遍历数据库中的前 1000 个键
一旦确定了大键,需要仔细分析它们的用途和是否真的需要存储大量数据。如果不需要,考虑删除或拆分大键。 如果大键问题无法通过删除或拆分解决,可以考虑将大对象存储在分布式存储系统(如对象存储)或专门的数据库中,然后在 Redis 中存储其引用或标识符。 如果大键是必需的,可以尝试优化读写操作。例如,对于大列表或集合,可以使用分页或限制返回的元素数量,而不是一次性读取整个容器。 对于临时性的大键,可以考虑定期清理它们,以释放内存资源。 定期监控 Redis 的内存使用情况,确保不会超出可用内存。
如果某个键包含大量数据,例如一个非常大的字符串或包含大量元素的集合、列表或有序集合,读取或写入该键会占用大量的内存和时间。Redis 是单线程的,操作大键需要花费更长的时间。 当开启持久化选项(如 RDB 快照或 AOF 日志)时,Redis 需要定期将数据写入磁盘,这可能会导致写操作变得耗时高。 当并发连接数较高时,Redis 单线程模型可能会导致请求排队,从而增加读写操作的响应时间。 如果 Redis 服务器和客户端之间存在网络延迟,读写操作的响应时间会受到影响。 Redis 中的键可以设置过期时间。如果过期键的数量过多,Redis 需要定期检查并删除过期键,这会导致性能下降。
选择适合应用场景的数据结构,例如使用集合来存储唯一值,使用有序集合来排序元素,避免不必要的数据转换和操作。 对于需要快速查找的字段,创建合适的索引以加速查询操作。不同数据库系统提供了各种类型的索引,如 B+ 树索引、哈希索引等,根据需要选择。 如果可能的话,尽量合并多个读写请求,减少与 Redis 服务器的通信次数。这可以通过使用 Redis 的事务或管道(pipeline)来实现。 考虑使用 Redis 的批量操作命令来处理多个键或多个元素,以减少单个操作的开销。 使用缓存来存储经常访问的数据,减少对 Redis 的频繁读取请求。这可以减轻 Redis 的负载,提高性能。 如果使用持久化选项,可以优化持久化的策略和频率,以减少对磁盘的写入次数,降低持久化的延迟。 如果 Redis 服务器负载很高,可以考虑使用 Redis 集群或分片技术来分散负载,提高并发能力。 监控和管理 Redis 的内存使用情况,确保 Redis 不会因为内存不足而触发性能下降。可以使用内存碎片整理工具来优化内存使用。 对于需要耗时的操作,考虑使用异步操作来处理,以避免阻塞主线程。这可以通过 Redis 的发布/订阅机制、队列等方式来实现。 对于高负载场景,可以考虑使用分布式缓存系统(如 Redis 集群)和负载均衡器来提高性能和可扩展性。 如果可能的话,避免创建大键,或者将大对象存储在外部存储系统中,并在 Redis 中存储引用或标识符。
使用多个数据库(DB):Redis 支持多个数据库,默认情况下有 16 个数据库(从 0 到 15),你可以通过 SELECT
命令切换不同的数据库。每个数据库是相互隔离的,可以将不同的数据分别存储在不同的数据库中。使用键前缀:一个更常见的做法是使用键的前缀来模拟分库分表的效果。在键名中添加前缀,可以将数据分组存储,使其逻辑上具有分库分表的结构。 例如,如果要将用户数据分为两个分库,可以使用如下的键前缀方式: 分库 0 的用户数据: user:db0:1
,user:db0:2
, ...分库 1 的用户数据: user:db1:1
,user:db1:2
, ...使用哈希槽(Hash Slot):Redis 集群模式中,数据被分割为 16384 个哈希槽。每个键都会被映射到一个哈希槽上。你可以通过分配不同的哈希槽范围来实现分库分表的效果。这种方式通常用于大规模的 Redis 集群环境。
SELECT 0 # 切换到数据库 0SELECT 1 # 切换到数据库 1
哈希函数(Hash Function):哈希表的核心是哈希函数,它将键映射到一个固定范围的索引位置。一个好的哈希函数应该尽量均匀地分布键,以减少冲突。 数组(Array):哈希表内部通常使用一个数组来存储数据。数组的大小通常是一个质数,例如素数。 冲突处理:当多个键经过哈希函数后映射到同一个索引位置时,会发生冲突。哈希表需要解决冲突,常见的解决冲突方法有以下几种: 链表法(Separate Chaining):每个索引位置上存储一个链表,冲突的键值对通过链表存储在同一个位置。 线性探测法(Linear Probing):如果发生冲突,就线性地检查下一个索引位置,直到找到一个空闲位置。 双重哈希法(Double Hashing):使用两个哈希函数来计算下一个索引位置。
动态扩容:当哈希表中的数据量达到一定阈值时,可以自动扩大数组的大小,以减少冲突的概率。扩容通常会重新计算所有键的哈希值,将它们重新分布到新的数组中。 负载因子控制:可以通过设置负载因子来控制数组的填充程度。负载因子是指存储的键值对数量与数组大小的比值。当负载因子超过一定阈值时,触发扩容操作。 链表长度限制:在链表法中,可以设置一个链表的最大长度。当链表长度达到这个限制时,可以考虑使用其他数据结构,如平衡树或者更高级的哈希表来存储冲突的键值对。 选择合适的哈希函数:哈希函数的选择会影响冲突的概率。选择一个好的哈希函数可以降低冲突的频率。 分桶(Bucketing):将哈希表分成多个小的哈希表,每个哈希表有自己的数组和哈希函数。这种方式可以减少链表长度,但需要额外的内存开销。 二次哈希:对于链表法,可以在链表长度达到一定限制时,将链表分成多个子链表,然后再使用二次哈希法来映射子链表。这样可以更均匀地分散数据。
std::set是一个有序的关联容器,它以红黑树(Red-Black Tree)作为底层数据结构来存储元素,确保元素按照升序排列。在C++中,可以直接使用std::set。
#include <iostream>#include <set>int main() {// 创建一个空的 Set 容器std::set<int> mySet;// 添加元素到 Set 中mySet.insert(3);mySet.insert(1);mySet.insert(5);// 删除元素mySet.erase(1);// 检查元素是否存在if (mySet.count(3) > 0) {std::cout << "3 存在于 Set 中" << std::endl;} else {std::cout << "3 不在 Set 中" << std::endl;}// 获取 Set 的大小std::cout << "Set 的大小:" << mySet.size() << std::endl;// 遍历 Set 中的元素std::cout << "Set 中的元素:";for (const int& element : mySet) {std::cout << element << " ";}std::cout << std::endl;return 0;}
std::set会自动保持元素的有序性,因此元素将按升序排列。
颜色属性(Color):每个节点都有颜色,可以是红色(Red)或黑色(Black)。 键(Key):每个节点都包含一个键,它用于进行搜索、插入和删除操作。 左子树(Left Subtree)和右子树(Right Subtree):每个节点都有两个子树,分别是左子树和右子树,它们也是红黑树。 父节点(Parent):每个节点都有一个父节点,指向其父节点。 特性(Properties):红黑树必须满足一组特性,确保树的平衡性。这些特性包括: 每个节点要么是红色,要么是黑色。 根节点是黑色。 每个叶子节点(NIL 节点或空节点)都是黑色。 如果一个节点是红色,那么它的子节点必须是黑色。 从任意节点到其每个叶子节点的路径都包含相同数量的黑色节点(黑高相同)。
平衡性:红黑树通过特性的约束来保持平衡。由于黑高相同的特性,从根节点到任意叶子节点的路径长度是相等的。这确保了树的高度保持在可控制的范围内。 二叉搜索树性质:红黑树本质上是一棵二叉搜索树,因此具有二叉搜索树的性质。根据二叉搜索树性质,左子树的所有节点都小于父节点,右子树的所有节点都大于父节点。这使得在搜索操作中,可以通过比较键值来确定向左子树还是向右子树搜索,从而加速查询过程。 平均深度有限:由于红黑树的平衡性,树的高度是有限的,不会出现极端的情况。因此,平均情况下,查询的深度是对数级别的,时间复杂度为 O(log n),其中 n 是树中节点的数量。
Apache Kafka:Kafka 是一个高吞吐量、分布式的消息队列系统,最初由LinkedIn开发。它主要用于流数据处理和日志聚合。Kafka 使用持久性日志来存储消息,支持多个消费者组,可以处理海量数据流。 RabbitMQ:RabbitMQ 是一个开源的消息队列系统,它实现了高级消息队列协议(AMQP)。RabbitMQ 提供了丰富的特性,包括消息路由、消息持久性、交换机、队列等,适用于各种应用场景。 Apache ActiveMQ:ActiveMQ 是一个开源的消息代理系统,实现了 Java Message Service(JMS)规范。它支持多种协议,包括STOMP、AMQP和MQTT。ActiveMQ 是一种强大的消息中间件,适用于企业级应用。 Amazon SQS:Amazon Simple Queue Service(SQS)是亚马逊提供的托管消息队列服务。它具有高可用性和可伸缩性,可以轻松集成到 AWS 云服务中,适用于构建分布式系统。 Apache Pulsar:Pulsar 是一个开源的分布式消息和事件流平台,最初由Yahoo开发。它具有多租户支持、持久性、扩展性和强大的流式处理功能。 Redis消息队列:Redis 可以用作消息队列,通过发布和订阅功能实现消息的发布和消费。它是一个内存数据库,适用于需要低延迟和高吞吐量的场景。 NATS:NATS 是一个轻量级和高性能的消息系统,特别适用于微服务架构。它支持发布/订阅和请求/响应模式。 RocketMQ:Apache RocketMQ 是一个分布式消息队列系统,最初由阿里巴巴开发。它支持事务消息、延迟消息、有序消息等高级特性,适用于大规模应用。 ZeroMQ:ZeroMQ 是一个消息传递库,提供了轻量级的消息队列功能。它的特点包括低延迟、多语言支持和灵活的模型。 Beanstalkd:Beanstalkd 是一个轻量级的消息队列系统,用于处理任务队列。它非常简单,适用于异步任务处理。
分区:主题(Topic)在 Kafka 中通常被分为多个分区。每个分区是一个有序的日志文件,消息在分区内保持顺序。这意味着同一分区内的消息按照生产的顺序被保存和传递。 消费者组:Kafka 支持多个消费者组,每个消费者组可以有多个消费者。每个消费者组内的消费者共享分区的消息。每个分区只能由一个消费者组内的一个消费者来消费,从而确保消息在消费者组内保持顺序。 偏移量(Offset):Kafka 为每个分区内的消息维护一个消费者的偏移量。偏移量表示消费者在分区中的当前位置。Kafka 使用偏移量来记录已经消费的消息,确保消费者可以从上次停止的地方继续消费,而不会丢失消息或重复消费。
Producer(生产者):生产者负责将消息发布到 Kafka 主题。消息可以分配到不同的分区,也可以指定特定的分区。 Broker(代理):Kafka 集群由多个代理组成,每个代理是一个 Kafka 服务器节点。代理负责存储和传递消息。代理之间可以形成一个分布式集群,实现数据的冗余备份和负载均衡。 Topic(主题):主题是消息的逻辑容器,消息被发布到主题。主题可以有多个分区,以便支持并行处理和分布式消费。 Partition(分区):分区是主题的物理分片,用于水平分布消息存储和处理。每个分区都有一个唯一的标识符,并且可以独立地存储和管理消息。 Consumer Group(消费者组):消费者组是一组消费者的集合,共同消费主题中的消息。Kafka 允许多个消费者组并行订阅同一个主题,每个消费者组内的消费者共享分区。 Zookeeper(可选):Zookeeper 用于管理和协调 Kafka 集群中的代理。不过,新版本的 Kafka 也引入了一些不再依赖于 Zookeeper 的特性。
特点:栈是一种线性数据结构,遵循后进先出(Last-In-First-Out,LIFO)原则。这意味着最后进栈的元素将是第一个出栈的元素,而最早进栈的元素将是最后出栈的元素。 操作:栈支持两个基本操作: push
:将元素压入栈顶。pop
:从栈顶弹出元素。应用:栈常用于需要回溯或撤销操作的情况,如函数调用栈、表达式求值、括号匹配等。
特点:队列是一种线性数据结构,遵循先进先出(First-In-First-Out,FIFO)原则。这意味着最早入队的元素将是最早出队的元素,而最晚入队的元素将是最晚出队的元素。 操作:队列支持两个基本操作: enqueue
:将元素添加到队列的末尾。dequeue
:从队列的头部移除元素。应用:队列常用于任务调度、广度优先搜索(BFS)、缓冲数据、消息传递等需要按顺序处理的情况。
pop
操作:pop
是栈的基本操作之一,用于移除并返回栈顶的元素。它会将栈顶元素出栈,同时修改栈的结构。remove
操作:remove
不是栈的标准操作,而是一个通用的数据结构操作。它用于从数据结构中删除指定元素,而不仅仅是栈。在栈中,remove
通常不是一个常见的操作,因为栈的主要操作是push
和pop
,而不是删除特定元素。
list(双向链表):
特点: list
是一个双向链表,可以容纳重复元素。每个元素包含了一个值以及指向前一个元素和后一个元素的指针。因为是链表,插入和删除元素的操作是高效的,但随机访问元素的效率较低。常见操作: list
通常支持以下操作:
push_back():在列表末尾添加元素。push_front():在列表开头添加元素。insert():在指定位置插入元素。erase():删除指定位置的元素。size():获取列表大小。迭代器遍历等操作。
map(关联数组):
特点: map
是一种关联数组,也被称为字典或键值对容器。它存储键值对,其中每个键关联一个唯一的值。map
使用红黑树作为底层数据结构,确保了键的唯一性和自动排序。常见操作: map
通常支持以下操作:
insert():插入键值对。find():查找指定键对应的值。erase():删除指定键值对。size():获取 map 大小。迭代器遍历等操作。
set(集合):
特点: set
是一种集合容器,存储唯一的元素,不允许重复。它使用红黑树作为底层数据结构,确保了元素的唯一性和自动排序。常见操作: set
通常支持以下操作:
insert():插入元素。find():查找指定元素。erase():删除指定元素。size():获取集合大小。迭代器遍历等操作。
二面
凸函数(Convex Function): 函数 f(x) 被称为凸函数,如果对于任意两个点 x1 和 x2 以及任意 0 <= t <= 1,都有以下不等式成立:f(tx1 + (1-t)x2) <= tf(x1) + (1-t)f(x2)。 换句话说,对于函数上的任意两点 x1 和 x2,函数图像位于这两点连线之上。 凸函数可以是一维或多维函数,凸性在整个定义域上成立。 凸函数的局部最小值也是全局最小值。 凹函数(Concave Function): 函数 f(x) 被称为凹函数,如果对于任意两个点 x1 和 x2 以及任意 0 <= t <= 1,都有以下不等式成立:f(tx1 + (1-t)x2) >= tf(x1) + (1-t)f(x2)。 换句话说,对于函数上的任意两点 x1 和 x2,函数图像位于这两点连线之下。 凹函数也可以是一维或多维函数,凹性在整个定义域上成立。 凹函数的局部最大值也是全局最大值。
凸函数的图像在任意两点之间都位于这两点之上,而凹函数的图像则位于两点之下。 凸函数的不等式是 "≤",而凹函数的不等式是 "≥"。 凸函数的局部最小值也是全局最小值,凹函数的局部最大值也是全局最大值。
head和
grep命令
head命令查看日志文件的前五十行,然后将结果通过管道传递给
grep命令,以查找包含"error"关键字的行。这样可以找到第五十行之后包含"error"的错误日志。
head -n 50 logfile.log | grep "error"
head命令查看前五十行,然后使用
grep命令查找包含"error"的行。
more或
less命令来查看,这些命令允许你逐页浏览输出。
head -n 50 logfile.log | grep "error" | more
head -n 50 logfile.log | grep "error" | less
find和
tail命令
find命令查找文件,然后使用
tail命令查看最后五十行的内容,并在其中搜索错误信息。
find path/to/logs -type f -name "logfile.log" -exec tail -n +50 {} \; | grep "error"
find查找日志文件,然后使用
tail命令查看从第五十行开始的内容,并使用
grep查找包含"error"的行。
class Match {public:Match(const std::string& name, const std::string& date, const std::string& location);virtual ~Match();void setTeams(const std::string& team1, const std::string& team2);virtual void play() = 0; // 纯虚函数,子类需要实现比赛规则virtual void displayResult() const;protected:std::string matchName;std::string matchDate;std::string matchLocation;std::string teamA;std::string teamB;bool matchPlayed;std::string matchResult;};
class FootballMatch : public Match {public:FootballMatch(const std::string& name, const std::string& date, const std::string& location);void play() override; // 实现足球比赛规则};class BasketballMatch : public Match {public:BasketballMatch(const std::string& name, const std::string& date, const std::string& location);void play() override; // 实现篮球比赛规则};
play方法来模拟比赛,最后使用
displayResult方法来显示比赛结果。
独立性:进程是操作系统中的独立执行单元,每个进程都有自己独立的内存空间,进程之间互相隔离。这意味着一个进程的崩溃通常不会影响其他进程的稳定性。 资源分配:进程拥有独立的系统资源,如内存、文件描述符、寄存器等。因此,进程需要占用较多的系统资源。 创建和销毁:创建和销毁进程通常比较复杂和耗时,因为需要为每个进程分配独立的资源和执行环境。
共享内存:线程是进程内的执行单元,它们共享同一进程的内存空间。这意味着线程之间可以轻松地共享数据,但也需要谨慎处理数据同步和互斥。 轻量级:与进程相比,线程通常更轻量级,因为它们共享进程的资源。线程的创建和销毁比进程更快速,因为不需要分配独立的资源。 相互影响:由于线程共享内存,一个线程的错误或异常操作可能会影响同一进程内的其他线程,因此需要更加谨慎的编程来避免数据竞争和死锁等问题。
进程通信: 进程通信(Inter-Process Communication,IPC)是不同进程之间传递数据的方式。 由于进程之间拥有独立的内存空间,因此进行进程间通信时需要使用特定的IPC机制,如管道、消息队列、共享内存、套接字等。这些机制允许进程之间交换数据,但需要额外的开销和复杂的实现。 进程间通信通常用于不同程序之间的通信,如客户端和服务器之间的通信。 线程通信: 线程通信通常更为直接,因为线程共享相同的内存空间,可以通过共享内存或临界区等方式来轻松地进行通信。 通常,线程之间的通信更高效,因为它们不需要像进程间通信那样复制数据或通过内核进行交互。 线程通信通常用于同一进程内部的不同线程之间的协作,如多线程编程中的线程同步和数据共享。
独立的调用栈:每个进程或线程都有其自己的独立调用栈。这是因为进程和线程是独立的执行单元,它们拥有独立的寄存器、内存空间和栈。一个进程或线程的栈不会直接影响其他进程或线程的栈。 函数调用的管理:栈帧用于存储函数的局部变量、参数、返回地址和其他相关信息。当一个函数被调用时,一个新的栈帧被创建并压入调用栈的顶部,用于跟踪该函数的执行状态。当函数执行完毕时,其栈帧会被弹出栈,控制流返回到调用该函数的位置。 栈的分离:不同的栈帧是相互独立的,它们在内存中是分离的。这种分离性保证了函数调用的局部性和隔离性,使得不同函数的局部变量不会相互干扰。同样,不同线程的栈也是分离的,从而确保线程之间的局部状态隔离。 并发执行:当多个线程并发执行时,每个线程都会有自己的调用栈和栈帧。这是线程独立性的重要体现,它允许线程同时执行不同的函数,并在需要时进行函数调用和返回。
struct:
没有访问控制:在C中, struct
中的数据成员默认是公有的,即所有数据成员可以在结构体外部访问。C中没有访问控制关键字(如private
、protected
、public
),因此无法限制对结构体成员的访问权限。没有构造函数和析构函数:C中的 struct
没有构造函数和析构函数的概念。结构体的创建和销毁通常由程序员手动管理。无法继承:在C中, struct
不能被继承,因为C中没有类的概念。结构体只是一组数据成员的集合。无法拥有成员函数:C中的 struct
不能包含成员函数(或方法),只包含数据成员。
struct:
有访问控制:在C++中, struct
和class
的主要区别是默认的访问控制。在struct
中,成员默认是公有的,而在class
中,成员默认是私有的。这意味着在struct
中的成员可以直接访问,而在class
中的成员需要通过公有成员函数进行访问控制。可以拥有构造函数和析构函数:在C++中, struct
可以拥有构造函数和析构函数,用于初始化和清理对象的状态。这使得struct
可以像类一样具有更多的行为。可以继承:在C++中, struct
可以像class
一样进行继承,可以通过派生类继承并扩展基类的成员。可以拥有成员函数:C++中的 struct
可以包含成员函数,使其更接近于类的概念。这意味着struct
可以具有数据成员和成员函数,可以实现更复杂的行为。
A
\
B C
\
D
D继承自两个类
B和
C,而这两个类都继承自类
A。这种情况下,类
D继承了来自类
A的成员两次,可能会导致二义性和问题。
虚继承(Virtual Inheritance):虚继承是C++中解决菱形继承问题的一种方法。通过在继承声明中使用 virtual
关键字,可以告诉编译器在继承链中只创建一个基类对象。这样,类D
只继承一份类A
的内容,避免了二义性。
class A {public:int value;};class B : public virtual A { /* ... */ };class C : public virtual A { /* ... */ };class D : public B, public C { /* ... */ };
重写和范围解析运算符:如果不能使用虚继承,或者需要更精细的控制,可以在派生类中重写具有二义性的成员函数,并使用范围解析运算符 ::
来指定调用的是哪个基类的成员函数。
class A {public:int value;};class B : public A { /* ... */ };class C : public A { /* ... */ };class D : public B, public C {public:int getValue() {// 使用范围解析运算符指定调用的是类 A 的成员return A::value;}};
重新设计继承结构:如果可能的话,考虑重新设计继承结构,避免菱形继承问题。这可能包括使用单一继承,或者使用组合代替继承,以减少继承关系的复杂性。
传统 I/O 模型通常使用阻塞 I/O,这意味着当应用程序尝试读取或写入数据时,如果没有数据可用或缓冲区已满,它将被阻塞,直到数据可用或空间可用。 阻塞 I/O 需要为每个连接创建一个线程或进程,这会导致线程或进程数量的增加,造成系统资源的浪费。 在高并发情况下,传统 I/O 模型的性能可能会受到限制,因为每个连接都需要独立的线程或进程,管理这些线程或进程会消耗大量的 CPU 和内存。
select
使用一个文件描述符集合,允许应用程序监视多个文件描述符的状态变化,包括可读、可写、异常等。select
允许单个线程同时管理多个连接,而不需要为每个连接创建一个独立的线程。但 select
有一个性能限制,它的时间复杂度为 O(n),当监视的文件描述符数量变大时,性能下降明显。
poll
与select
类似,允许应用程序监视多个文件描述符的状态变化,但在某些情况下更加高效。poll
不会像select
那样受到文件描述符数量的限制,因此在一定程度上可以处理更多的并发连接。但 poll
仍然需要遍历整个文件描述符集合,导致性能随着连接数量的增加而下降。
epoll
是 Linux 下的多路复用机制,相对于select
和poll
具有更高的性能。epoll
使用了回调机制,只通知应用程序活跃的连接,而不需要遍历整个文件描述符集合。epoll
支持边缘触发(Edge-Triggered,ET)模式,这意味着只在状态发生变化时通知应用程序,而不是像传统模式那样持续通知。
性能更高: epoll
在高并发场景下性能更好,因为它只通知活跃的连接,避免了不必要的遍历。可扩展性: epoll
对连接数量的增加具有更好的可扩展性,不会受到文件描述符数量的限制。资源消耗更低:相比于传统 I/O 模型, epoll
使用更少的线程或进程来管理连接,因此资源消耗更低。更精细的控制: epoll
支持边缘触发模式,使得应用程序可以更精细地控制和处理事件。
nums,其中的元素按升序排序,并在某个位置上进行了旋转。例如,
[0, 1, 2, 4, 5, 6, 7]可以通过旋转操作变成
[4, 5, 6, 7, 0, 1, 2]。
初始化两个指针 left
和right
分别指向数组的首尾元素。在每一步中,计算中间元素的索引 mid
,即:mid = (left + right) / 2比较中间元素 nums[mid]
与目标值target
:如果 nums[mid] == target
,则找到了目标,返回mid
。否则,分两种情况讨论: 重复步骤 2 和 3,直到 left > right
。如果没有找到目标值,返回-1
。
nums[left] <= nums[mid],说明左半段是有序的。这时可以判断
target是否在左半段,如果在,则更新
right = mid - 1,否则更新
left = mid + 1。
nums[mid] < nums[left],说明右半段是有序的。这时可以判断
target是否在右半段,如果在,则更新
left = mid + 1,否则更新
right = mid - 1。
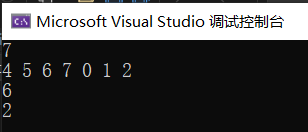
#include <iostream>#include <vector>using namespace std;int search(vector<int>& nums, int target) {int left = 0, right = nums.size() - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;}if (nums[left] <= nums[mid]) {if (nums[left] <= target && target < nums[mid]) {right = mid - 1;} else {left = mid + 1;}} else {if (nums[mid] < target && target <= nums[right]) {left = mid + 1;} else {right = mid - 1;}}}return -1;}int main() {int n;cin >> n;vector<int> nums(n);for (int i = 0; i < n; i++) {cin >> nums[i];}int target;cin >> target;int result = search(nums, target);cout << result << endl;return 0;}
最后,阿Q最近刚刚建立了一个学习交流群,人虽然不多,但都是想努力上进的小伙伴,感兴趣可私我免费进,我们一起进步和成长!!

文章转载自阿Q正砖,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
