




TPCH benchmark里面的许多query都是JOIN+GROUP BY的模式,因此TPCH里有不少的query都能通过GroupJoin优化掉。在论文paper_1里,作者列出Q3/Q5/Q9/Q10/Q13/Q16/Q17/Q20/Q21这些query在使用GroupJoin与不使用GroupJoin两种情况下的性能:
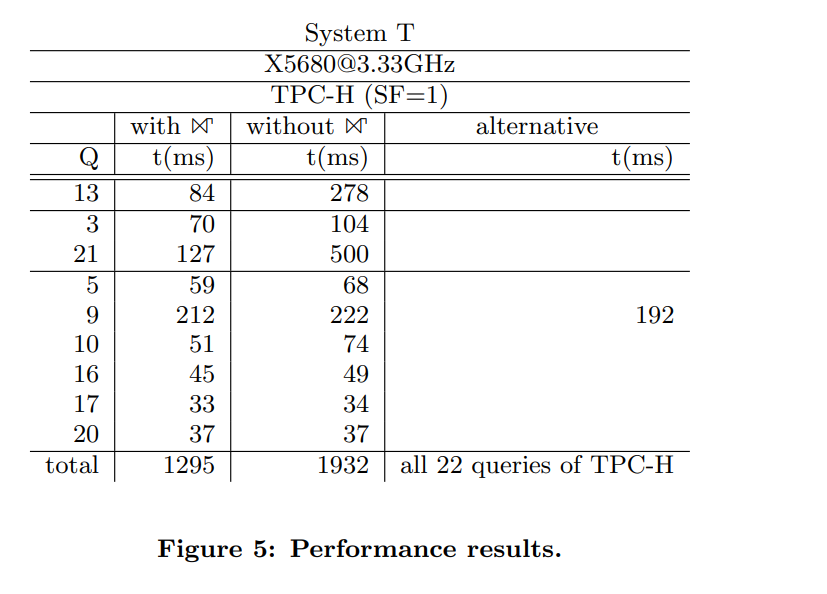
此处使用的是TPCH 1 GB的数据量。可以看出GroupJoin对优化TPCH类型query有一定的作用(总体时延1932ms降到1295ms)。
在论文paper_2中,则是分别列出了Q3/Q13/Q17/Q18这些query在使用GroupJoin与不使用GroupJoin几种情况下的性能(TPCH 10 GB数据量):
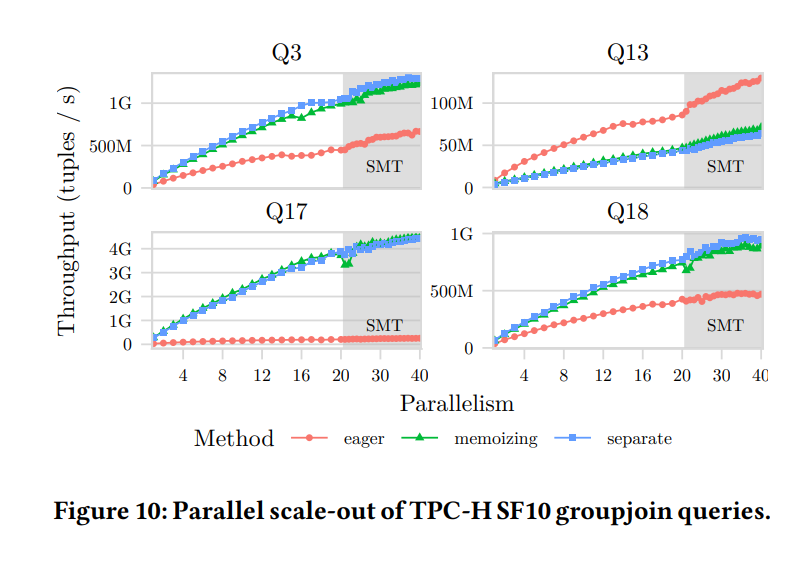
图中的几组线条含义如下:
- 图中 “seperate”这一组线条代表“分别做JOIN和GROUP BY”,也就是不使用GroupJoin;
- 图中“eager”代表上文所说的“eager aggregation”这一优化;
- 图中“memoizing”代表上文所说的“如何处理并发查哈希表做aggr运算时的冲突”这一优化。 可以看到,在 Q3/Q13/Q17/Q18 这4条query中:
- “memoizing” 的方式几乎总是与一般的HASH JOIN+HASH GROUP BY的方式有着类似的性能;
- eaegr aggregation的方式只在Q13这一条query中占有优势,其余都不占优势。
按照图中的数据可得:不同的处理方法,在不同场景中差别很大。因此这个数据呼应了作者提出的 “GroupJoin 的执行方式,需要优化器提供更准确的统计信息,以选择最优的执行方式”这一观点,而不是无差别地选择某一种GroupJoin算法,甚至无差别地选择使用GroupJoin。
虽然如此,对于这个结论,PolarDB有不同的观点:
- 文章中使用tuples per second这个指标来衡量算法的好坏,但是与PolarDB IMCI中得到的结论却不太一样。使用IMCI在并发度=32的情况下测试Q3/Q13/Q18这3条query的GroupJoin算子的throughput(单位tuples/s),结果如下:

Q17在IMCI里暂时无法使用GroupJoin。
这个测试数据与上图中的数据在量级上是相似的,但是每条query都稍有不同。也许是实现方式的不同,从PolarDB的测试数据中可以观察到,除了上文说的right join+groupby right情况外,GroupJoin几乎总是优于HashJoin+HashGroupby的。
- 对于上面3.a的结论,即“memoizing”的方式几乎总是与一般的HASH JOIN+HASH GROUP BY的方式有着类似的性能,根据我们的观察,TPCH的这几条query只有非常少量的contention,因此memoizing的方式所用的local hash table等,在实际运行时基本不会用到,因此在这几条query里面,这个算法得到的性能与HASH JOIN+HASH GROUP BY是类似的;论文里引用这几条query的性能作为对比,其实不说明问题。PolarDB是通过直接加锁的方式来测试运行时的contention的。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
