







日前,在加拿大温哥华召开的数据库领域顶会VLDB 2023上,来自阿里云瑶池数据库团队的论文《Anser: Adaptive Information Sharing Framework of AnalyticDB》,成功入选VLDB Industrial Track。
基于以上挑战,论文提出了一个动态信息传递框架,及一个基于信息流依赖的自适应调度器,来进行执行中长查询的智能优化。
论文设计了一个统一的动态的信息传递框架,能够支持各种自适应优化的应用场景。
整体架构
● 类型:分为primitive和non-primitive。primitive是收集开销可以忽略的基础统计信息,如行数,最大最小值等;non-primitive是需要从基础统计信息推导(如NDV)或有额外收集开销(如BloomFilter)的统计信息;
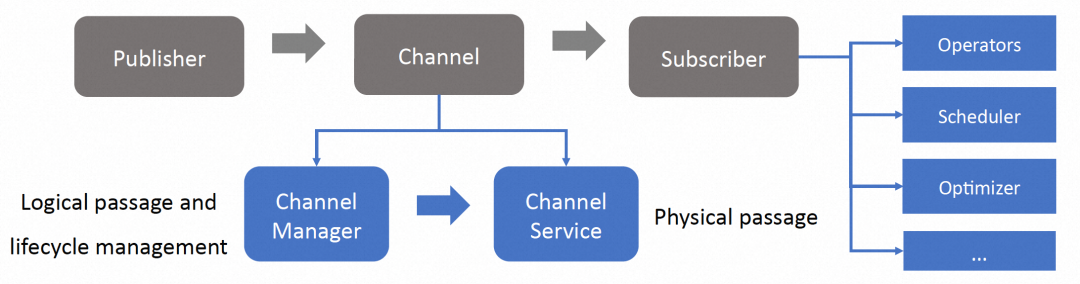
整个信息传递框架是一个发布订阅者模型,具体实现包括:
● 如无算子可以提供需要的non-primitive信息,会在算子链中插入一个PubOperator。
▶︎ 订阅者 Subscriber - 信息消费者:根据应用场景不同,订阅者者可能是算子、调度器、优化器
● 订阅者对发布者弱依赖,SubOperator中会定义一个阻塞事件,收到信息/收到信息被取消(在执行异常情况下或在自适应调度器要求下)时取消阻塞,和订阅者交互,然后开始执行算子本身的逻辑或驱动下游算子。
工程实现
考虑到增加运行时的信息传递有一定的开销,我们希望通过开销and/or收益评估,将生效场景限制在有正收益的场景。业界一般有两种做法。一种是在计划阶段、基于估算的、局部生效的规则;另一种是在执行阶段、基于运行信息的、全局生效的规则。
论文提出贪婪算法,一种在计划阶段生成等价关系、基于运行信息判断是否生效的、全局的规则。首先,在计划阶段,基于全局等价关系推导,针对不同应用场景,rule-based找到发布和订阅者并通过管道进行匹配,这里除了插入发布node外,不对执行计划进行改变;在执行阶段,基于运行时信息计算发布订阅的开销,对有收益的管道,才进行信息的收集和传递。
1. 共享:支持一个信息被多个订阅者共享,这个信息只需要产生并传递一次到对应节点;
2. 合并:多个信息如果同时产生,通过信息合并,在节点间传递时只发送一次请求,从而减少网络连接;
3. 短路:当信息粒度为分片时,直接在节点内部传递给对应订阅者,短路信息合并和节点间传递的开销;
4. 兜底:通过限制信息内存使用等兜底逻辑保证开销可控。
算法实现
1. 整个执行计划可以按序执行,不出现查询死锁;
2. 具备分批调度的能力,从而保证执行任务有动态调整的能力;
3. 感知Anser定义的弱依赖关系,尽量先调度发布者,后调度订阅者;
4. 平衡单批次执行资源利用率低导致RT上升,和每次执行批次个数过多导致重优化机会变少的问题。
论文分3步划分出Stage Group为调度的最小粒度,前两步保证能力1,第三步保证能力2:
1. 定义Stage间的强依赖:图a中箭头的指向 A -> B 表示A需要消费B的数据,A强依赖于B,否则会出现查询死锁;
2. 找出强连通分量:找到图a中的强连通分量,一次性调度每个强连通分量里的所有Stage;
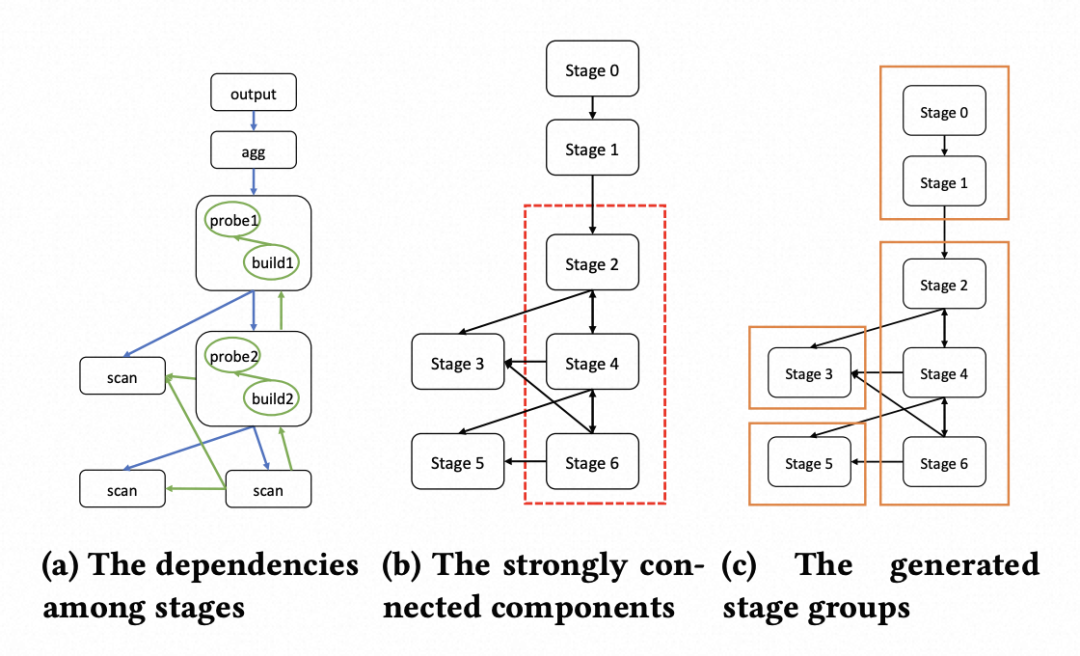
为满足能力3,根据Anser定义的订阅者对发布者弱依赖关系,和DAG定义的强依赖关系,给每个批次定义了一个优先级priority score。优先级的取值范围在0-5之间,0包括没有任何强依赖的批次,会首先被调度。有强依赖的批次,通过动态规划,按以下优先级决定调度的先后顺序:包含订阅者且对应的发布者已完成 > 只包含发布者 > 既没有发布者也没有订阅者 > 包含订阅者且对应发布者执行中 > 包含订阅者且对应发布者未执行。目标是在尽可能先调度发布者后调度订阅者的同时,减少订阅者的等待时间。
1. 划分批次并定义优先级;
2. 构建优先级队列:维护两个优先级队列,队列1为非阻塞队列,包含priority score=0的批次,由批次树的叶子节点向根节点调度;队列2为阻塞队列,包含其他批次,调度器会对批次执行状态进行监控,实时更新priority score或将批次挪到非阻塞队列;
3. 并行调度因子N:随资源规格自适应调整N的具体值,同时跑N个批次,保证并行度优先;
收益分析
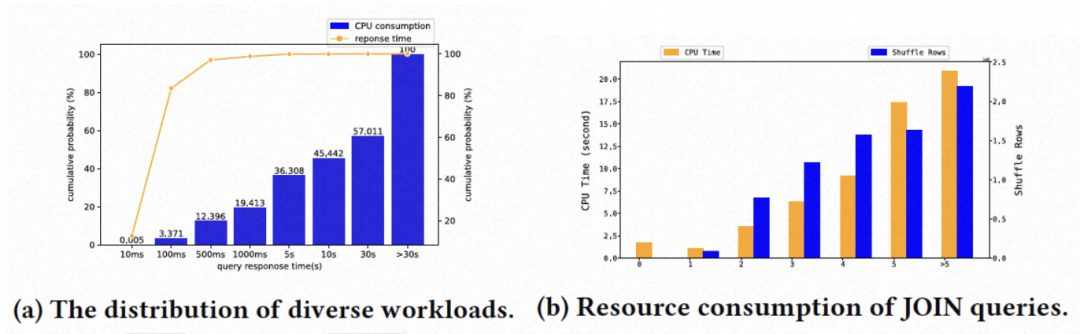
论文是用一套算法来调度在线和离线的场景。对于响应时间敏感的在线场景,定义Stage个数小于等于5个的查询为短查询,会短路Anser并跳过批次的划分,整个查询作为一个批次进行下发,也即AllAtOnce地执行。
自适应调度器还能降低系统的整体压力,减少不必要的资源竞争和等待开销。
● 减少分布式开销和资源等待开销:AllAtOnce一次性下发后,会开始申请计算资源并在有数据交换的地方建立网络连接。但由于本身下游就需要上游有数据输出后才开始计算,下游申请好了资源也需要等待,就会造成资源的竞争和浪费。在生产环境中,使用自适应调度器跑复杂查询的大集群中,对比AllAtOnce,网络连接减少了50%-95%,峰值内存使用减少了50%,等待task个数最多减少99%
论文分别在Benchmark测试集TPC-DS和线上生产环境进行了实验验证。
Benchmark测试对比了AnalyticDB MySQL打开和关闭Anser的整体收益,并和Spark进行了对比。打开Anser,AnalyticDB MySQL整体有60%+的提升。
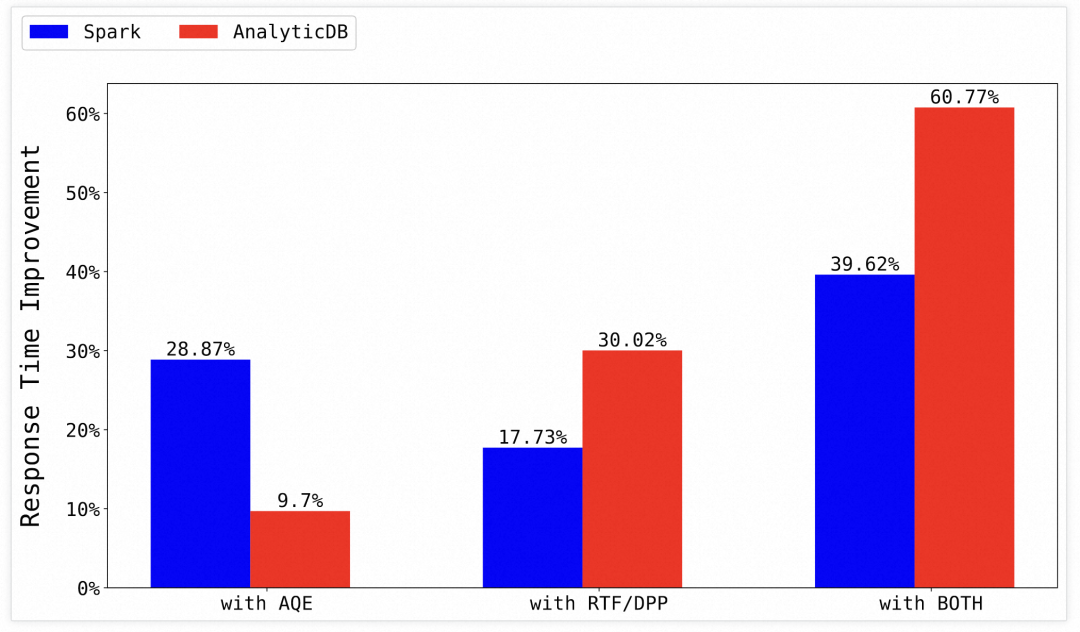
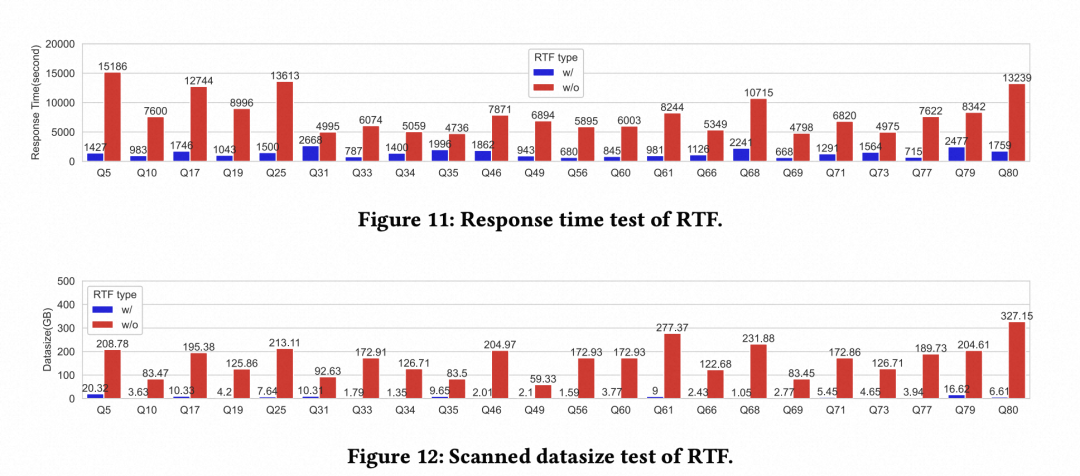
消融实验选取了TPC-DS 99条查询中的22条在实验1中执行时间超过2s的长查询,单看这些长查询,并且只打开Runtime Filter,有平均81%的性能提升。接下来通过控制变量,实验了一些关键设计的有效性。
● 对比了全局推导生效(greedy)vs 仅在同一个Join生效(baseline)的有效应用场景:计划阶段生成Runtime Filter个数,baseline下61个,greedy下 170个;在greedy中生成的170个Filter中,104个在执行中有效。
● 对比了基于执行前推导 vs 基于执行中推导,减少的数据扫描量:在实验场景中,基于执行前推导的信息应用于源头数据扫描,可以提前过滤掉超过96%的数据,极大的减少网络和I/O的开销;而基于执行中推导的实现,无法用到执行中的信息下推到存储提前过滤数据。
● 对比了自适应调度器 vs AllAtOnce调度器,对查询响应时间的影响:设置了集群资源空闲/较满/打满三种测试场景,并在订阅端算子设置了等待时间。自适应调度器的响应时间在不同资源配置、不同等待时间下都比AllAtOnce的不同等待时间的性能更优。
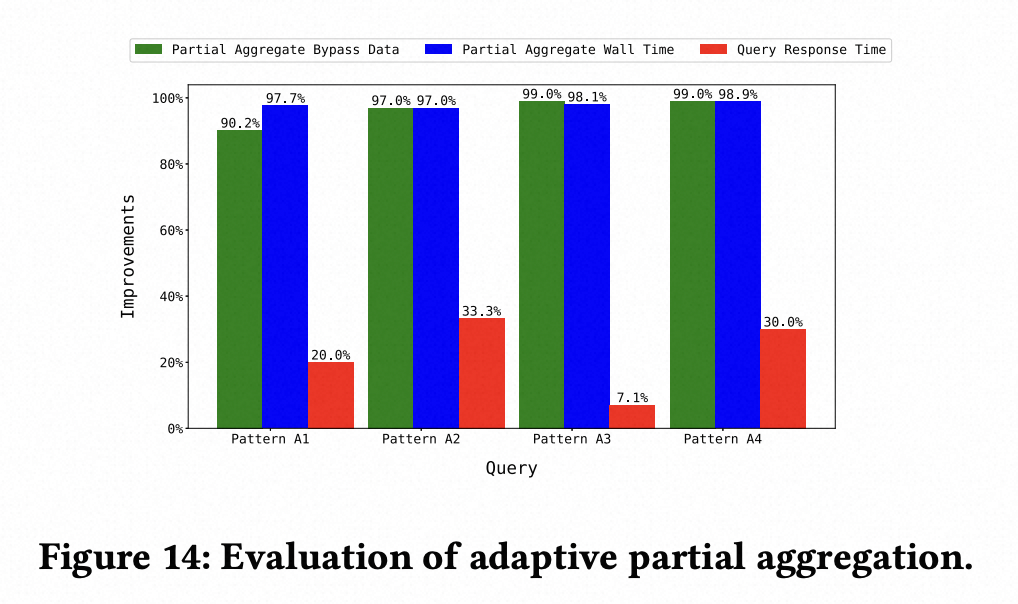
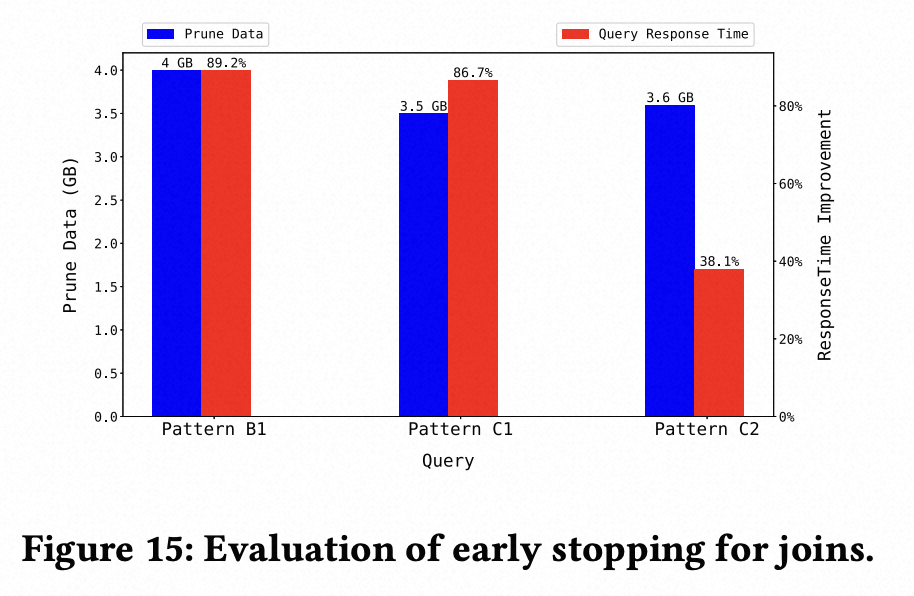
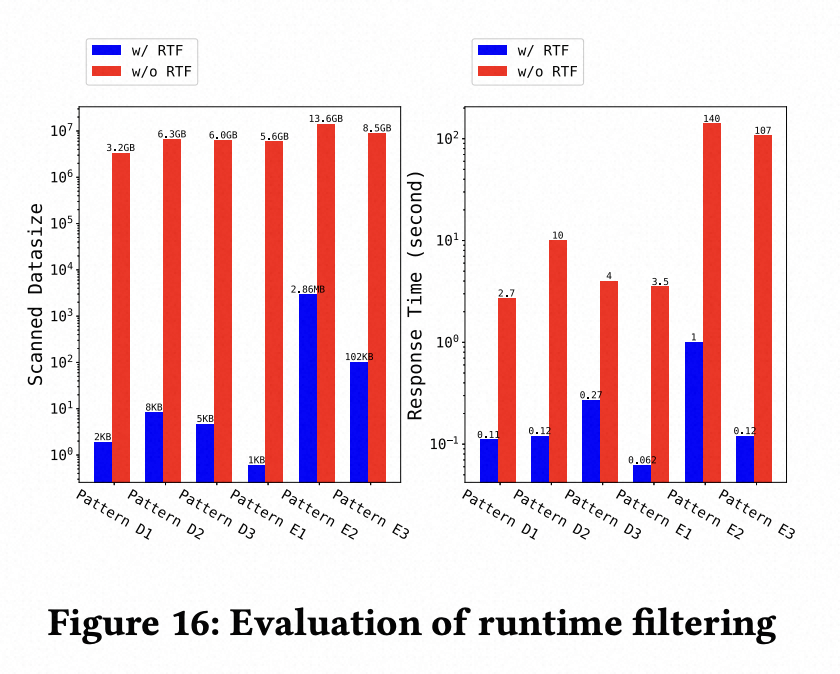
3. 其他应用场景在生产集群上的效果验证



⇩ 点击 阅读原文 即可 下载论文原文
