




优化器,SQL引擎的核心组成部分,是数据库中用于把关系表达式转换成最优执行计划的核心组件,影响数据库系统执行性能的关键组件之一。
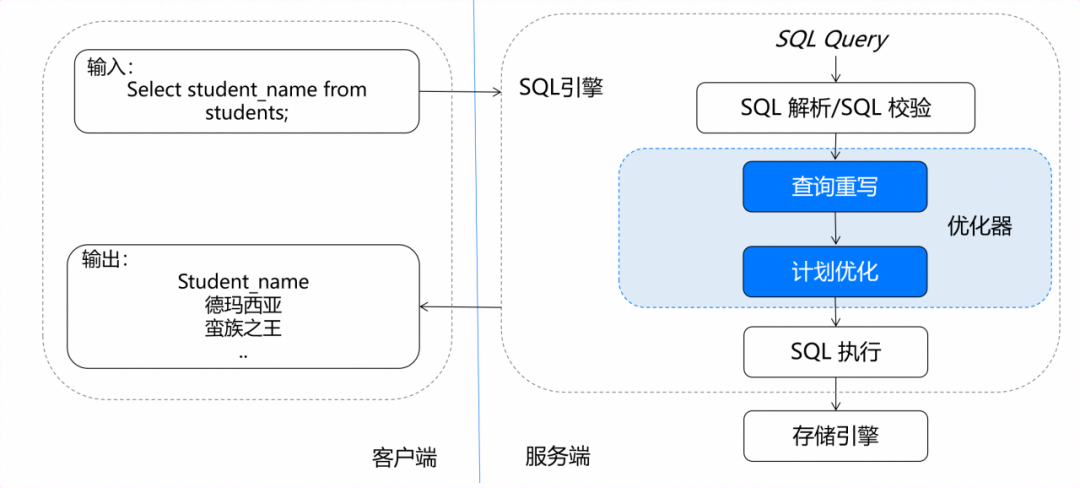
图1 SQL语句处理过程
A:1 3 8 5 6 4 2 7 10 9
B:1 2 3 4 5 6 7 8 9 10
A1:6 3 8 5 1 4 2 7 10 9A2:9 3 8 5 1 4 2 7 10 6
B:1 2 3 4 5 6 7 8 9 10
识别不同的客户请求(SQL语句决定)。 理解数据特征(主要由存储和统计信息承载)。 探索在当前数据特征下,实现客户请求的所有可能路径(通过重写变换和实现丰富的物理算子的方式)。 选择最佳的执行路径(Cost模型计算决定)。
冗余操作的简化,比如Filter的相关的优化,Filter的合并,a > 1 and a > 5,将优化为a > 5。 实现了简单且有益的改写规则,改写不会丢失任何更优的执行路径,产生更加优化的执行路径。
a left outer join b on a.id= b.id where b.name= const
可以直接将Outer join改写为Inner join。
随后将重写后的Query表示输入到动态优化阶段,包括如下几个模块:
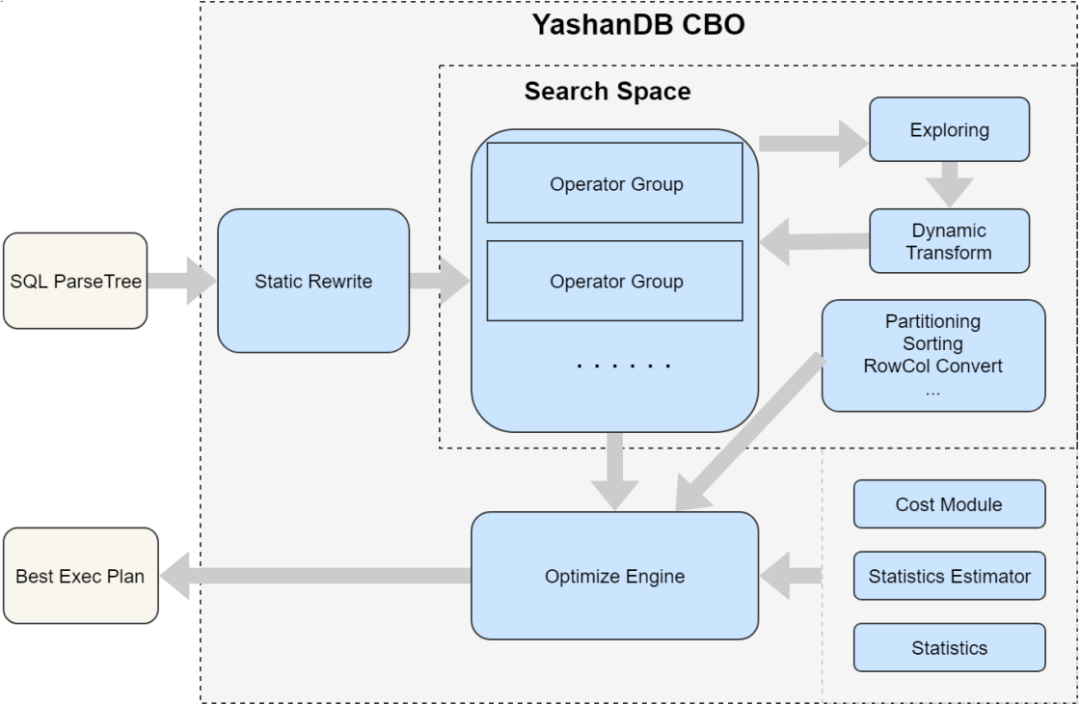
图2 YashanDB优化器模块
转换模块
主要实现逻辑动态重写和逻辑计划到物理计划的转换,根据原始语句的特点,生成更多的扩展访问路径。比如子查询的改写,将子查询的执行方式,扩展出子查询和父查询Join的执行方式。
根据Join表的个数,通过动态规划或者贪心算法,扩展生成各不同等价Join Order等。
而在逻辑到物理阶段的转换中,实现一个逻辑算子对应的多个等价物理算子的扩展,比如Join将生成Nestedloop Join,Merge Sorted Join,Hash Join等。如上图中的Exploring阶段和Dynamic Transform阶段,实现该部分的逻辑。
统计信息模块
Cost计算模块
搜索最优计划
在上图的Optimize Engine中,嵌入了计划的遍历和和最优计划的搜索能力。
YashanDB动态优化部分基于Cascades框架设计构建,该框架可以较好的实现器各模块解耦,例如路径搜索与统计信息和Cost模型的解耦、查询重写规则与逻辑算子和物理算子的解耦等,路径扩展与最佳路径搜索的解耦等,通过各个模块的解耦,实现在任何模块都可以快速的增加开发一些新的功能的能力,比如可以快速增加一个物理算子,可以快速的增加一个查询重写的规则。
下面我们用一条简单的sql语句示例,来说明一下优化器的实现过程。
select count(*) from t1 join t2 on t1.id = t2.idgroup by t1.id;
扩展可选计划
SQL语句经过Parse后生成抽象表达树,在进入到CBO后,根据SQL的语义,生成一个初始的逻辑执行树。从而初始化搜索空间,语句在CBO框架中的表示如图一。 接着进行逻辑转换,根据重写规则,扩展出更多的等价形式。该语句group by t1.id命中Group By下推的重写条件,所以根据动态重写规则,会生成一个额外的路径,将Group By下推到Join下面,t1表的Scan之后,表示如图二。 在该语句中,由于存在Join条件t1.id = t2.id, 所以Group By t1.id也可以等价表示为Group By t2.id,所以还会额外的产生一个Group By下推到join下面t2的Scan之后的计划。所以就有了Group By下推到t1表,Group By下推到t2表下面的额外路径产生。 逻辑转换阶段结束后,进入物理转化阶段,根据逻辑算子,产生相关的物理执行算子。在YashanDB数据库中,Group By的物理算子实现了Hash Group,Sorted Group和Sdt group,这样在每个阶段的Group操作,都会产生3个物理Group的路径,表示如图三。 Scan会根据表和表上的索引,产生相关的Table Scan,Index Scan等物理执行计划。
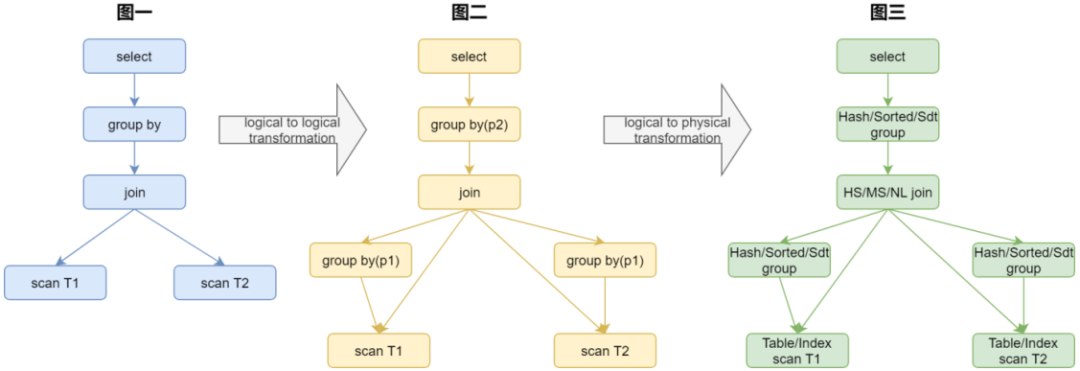
选择最佳计划




文章转载自YashanDB,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
