




今年,Apache Kylin 社区正式发布了 Apache Kylin 5, 相较此前版本这一版本在核心能力上得到全方位提升,很多小伙伴开始尝试并使用 Kylin 5。今天来自七猫大数据团队的何家乐同学将分享 Kylin 5 在七猫的实践以及技术原理的解读,欢迎大家和我们多多交流。
01
背景
目前七猫有很多业务固定报表和指标,随着业务发展,报表越来越多。当前七猫的报表和指标有以下几种特点:
查询使用的表、维度、度量相对固定,SQL 变更频率低;
查询时间跨度长,动辄半年或一年数据;
使用的事实表相对固定。
02
痛点
当前公司内部很多报表和指标使用 Trino 和 Starrocks 引擎进行查询,但是存在以下几个问题:
Starrocks 集群独立部署,查询速度极快,其独立的存储、计算资源是单独收费,成本高。
Trino 集群对于小查询响应速度快,大查询响应速度慢且集群负载增加,查询性能不稳定。
03
效果
Kylin 5 通过其预计算能力,优化了部分业务端社区报表,极大提升了查询效率。
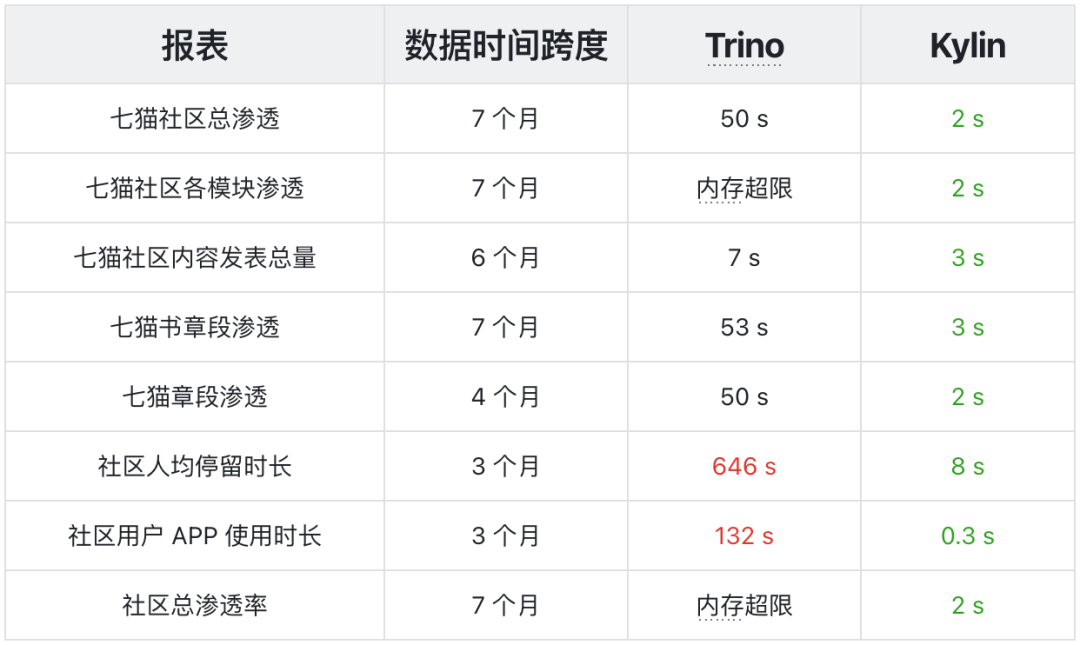
索引加速
Kylin 5 的即席查询能力(查询下压),利用其在 Yarn 上的常驻 Spark 任务,Kylin 将用户提交的 SQL 直接丢给 Spark 进行查询。
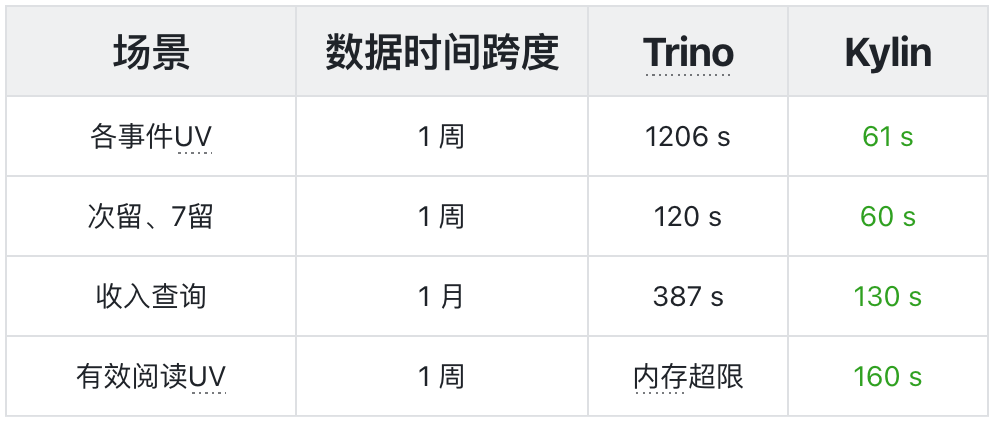
即席查询
04
Kylin 是什么?
Apache Kylin™ 是一个开源的分析型数据仓库,为 Hadoop 等大型分布式分析平台之上的超大规模数据集(PB 级)通过标准 SQL 查询及多维分析 ( OLAP ) 功能,提供亚秒级的交互式分析能力。
Kylin 通过构建引擎和查询引擎来分别生成和查询预计算数据文件,并基于 Apache Spark 来扩展构建引擎和查询引擎的计算能力。对用户,Kylin 提供 HTTP、JDBC、BI、EXCEL 等方式来进行数据分析。
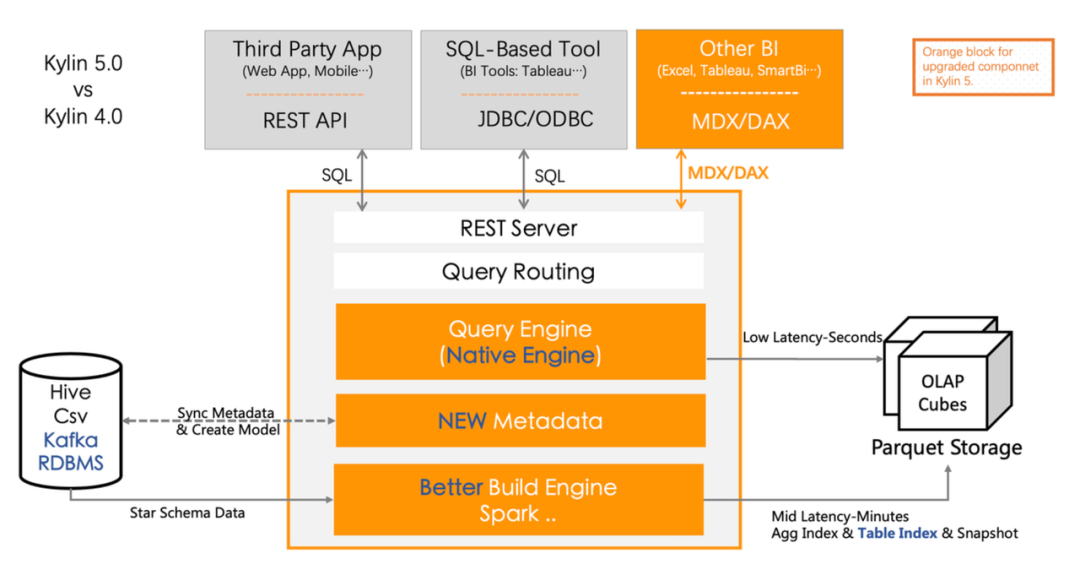
Kylin5 架构
目前已被 eBay、腾讯、美团、滴滴、汽车之家、贝壳找房、OLX 集团、有赞、德邦物流、微软、思科等全球超过 1500 家企业采用。
Kylin 5 的优点:
计算、查询、存储 ,均使用大数据集群的 Yarn 和对象存储;
支持横向扩展;
支持查询缓存(分布式 Redis 缓存、本地缓存);
支持 Spark3,利用其 AQE 的能力加速计算;
支持表、行、列 级别权限控制,精准控制用户访问的数据;(只有 API 接口)
可视化建模极大降低了使用门槛;
支持预计算查询、也支持原生 Spark 查询 Hive 数据(下压查询);
标准 SQL 接口,无缝衔接 BI 工具 Superset、Tableau、PowerBI、Excel;
支持部署在 K8S;
支持 HA 高可用部署。
05
Kylin5 在查询性能和成本方面的优势
对于固定报表,Kylin 的查询速度和成本要优于 Starrocks 和 Trino。对于明细、即席查询,绝大部分情况下 Starrocks 要优于 Kylin 和 Trino 。
聚合查询:Kylin > Starrocks > Trino
明细/即席查询:Starrocks > Kylin >= Trino
存储成本:Kylin <= Trino < Starrocks
Trino、ClickHouse、StarRocks 是七猫使用的最多的几种查询引擎。
由于 ClickHouse 多表关联性能差,而大部分的查询都需要事实表和维度表关联,因此下文主要把 Kylin 跟 Trino、StarRocks 进行对比,主要从查询性能、吞吐量、存储成本等方面进行比较。从成本和查询速度两方面考虑:
Kylin 在命中索引和下压查询的情况下,查询速度都优于 Trino(索引查询平均提速 60 倍,下压查询提升约 1-2 倍)。
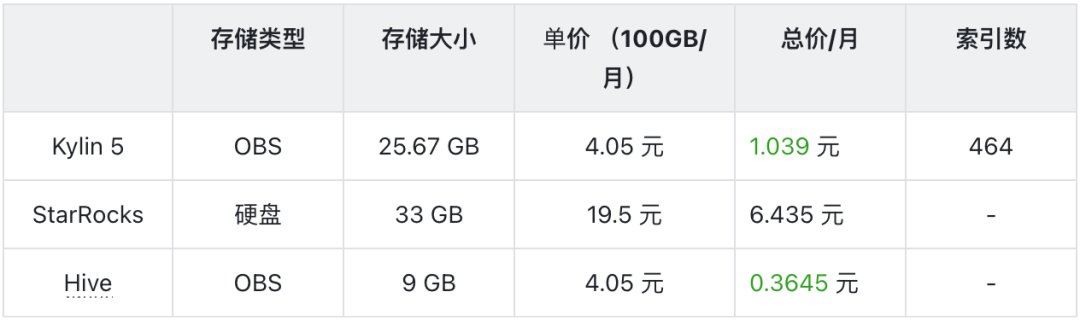
Kylin 存储成本低于 Starrocks(存储成本降低 600%)。
1. 查询 VS Trino
查询 SQL 取自 Superset 业务报表 《社区用户 APP 使用时长》
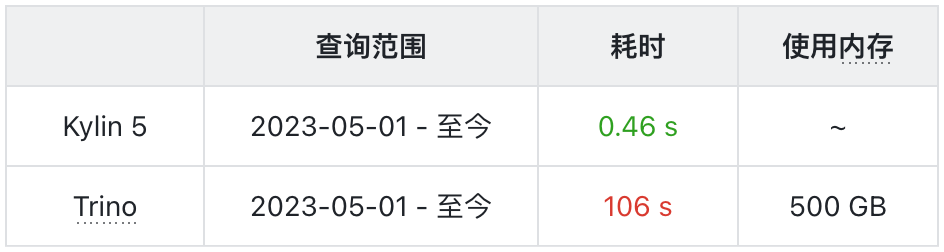
查询耗时
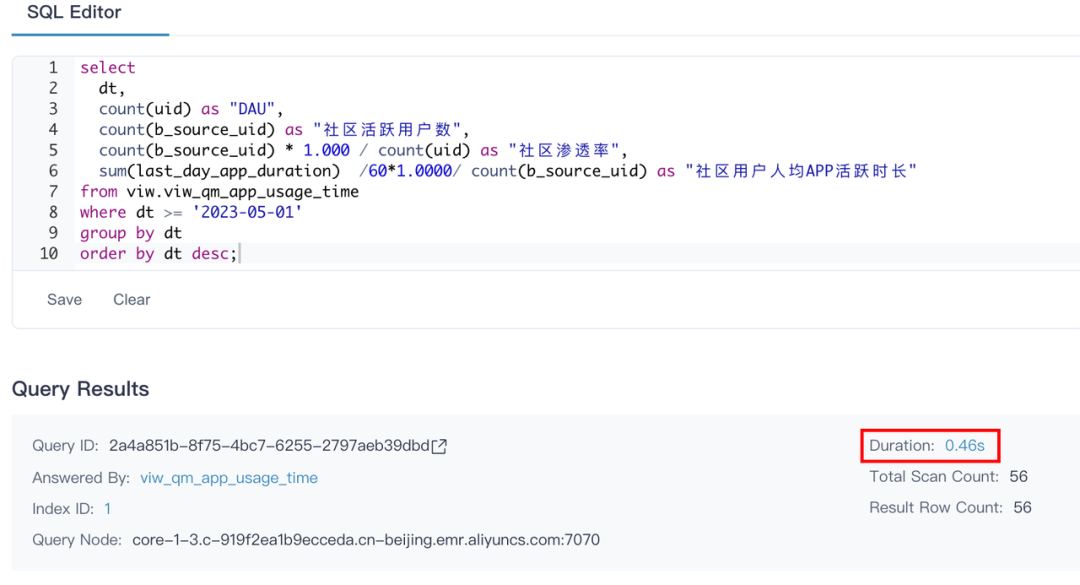
查询 Kylin5

查询 Trino
2. 查询并发压测
模拟 100 人使用 10 条不同 SQL 同时查询,10 条 SQL 分别从不同维度、度量和时间进行查询。
1 台 Kylin 节点
10 条 SQL
100 并发压测
关闭查询缓存
使用 Jmeter 工具进行压测

压测结果
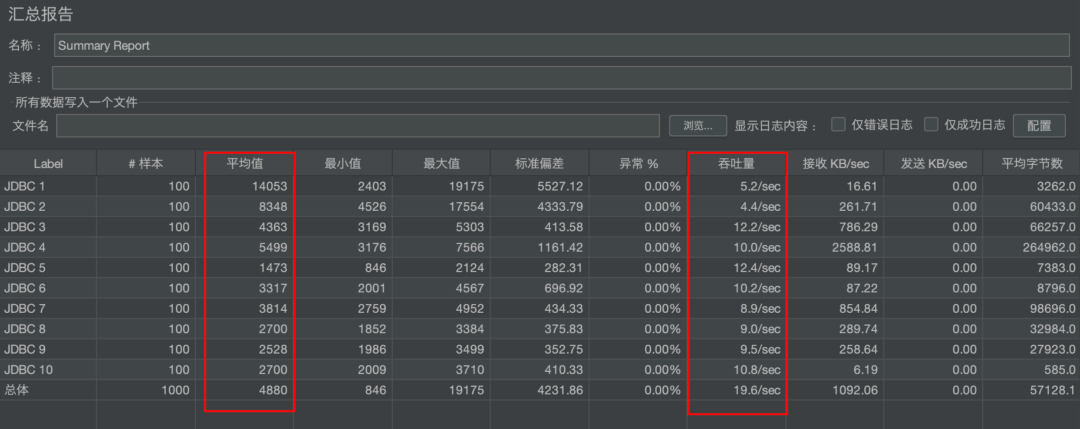
压测结果
3. 存储成本 VS Starrocks
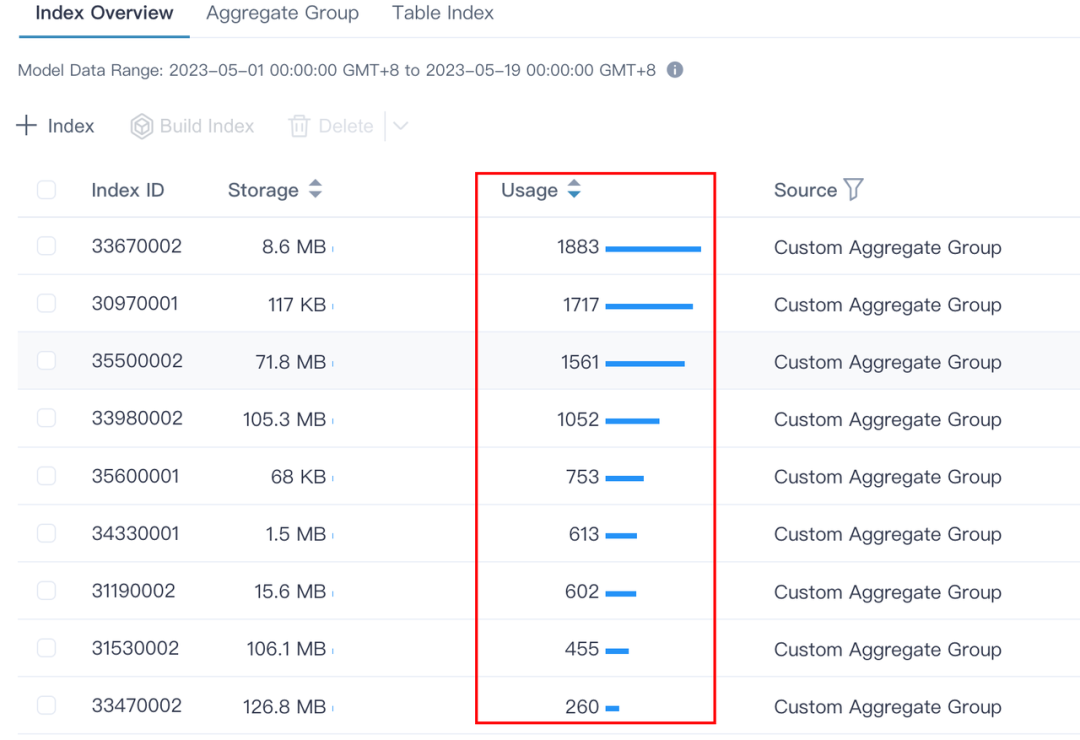
Kylin 的 464 个索引是为了满足各种维度排列组合的查询,随着时间的推进,可以观察到各个索引的使用次数。
后续可以根据索引使用次数,将不访问的索引删除,再次降低存储成本。
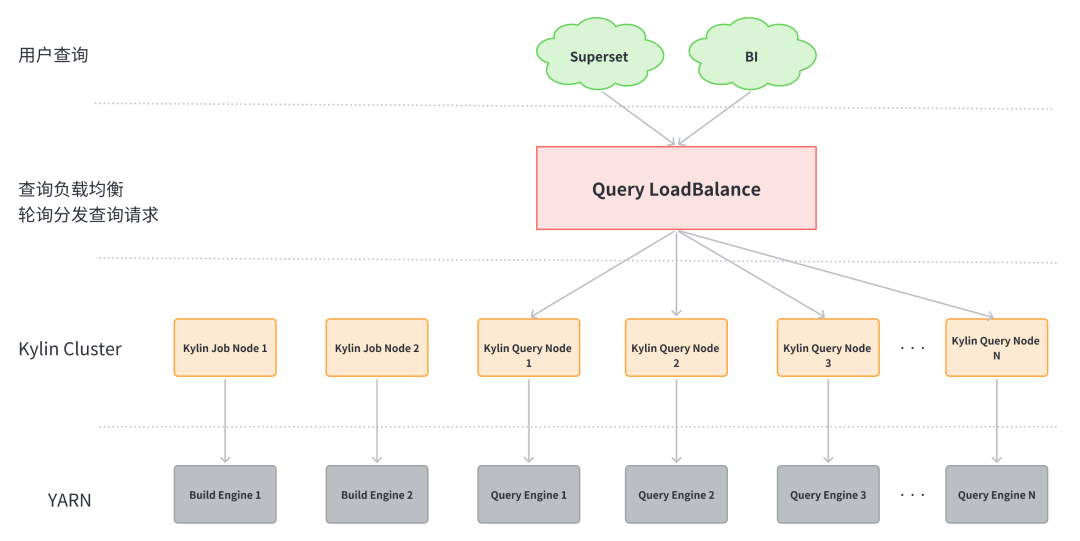
4. 水平扩展性
Kylin 对于查询节点可以水平扩展,即可以部署多台 Kylin 查询节点。在其之上做 LoadBalance。
所有查询入口均访问 LoadBalance 节点,LoadBalance 轮询分发查询到不同 Kylin 查询节点,即可实现查询节点高可用。
06
Kylin 5 进阶
1. Kylin 5 的查询到底在做什么?
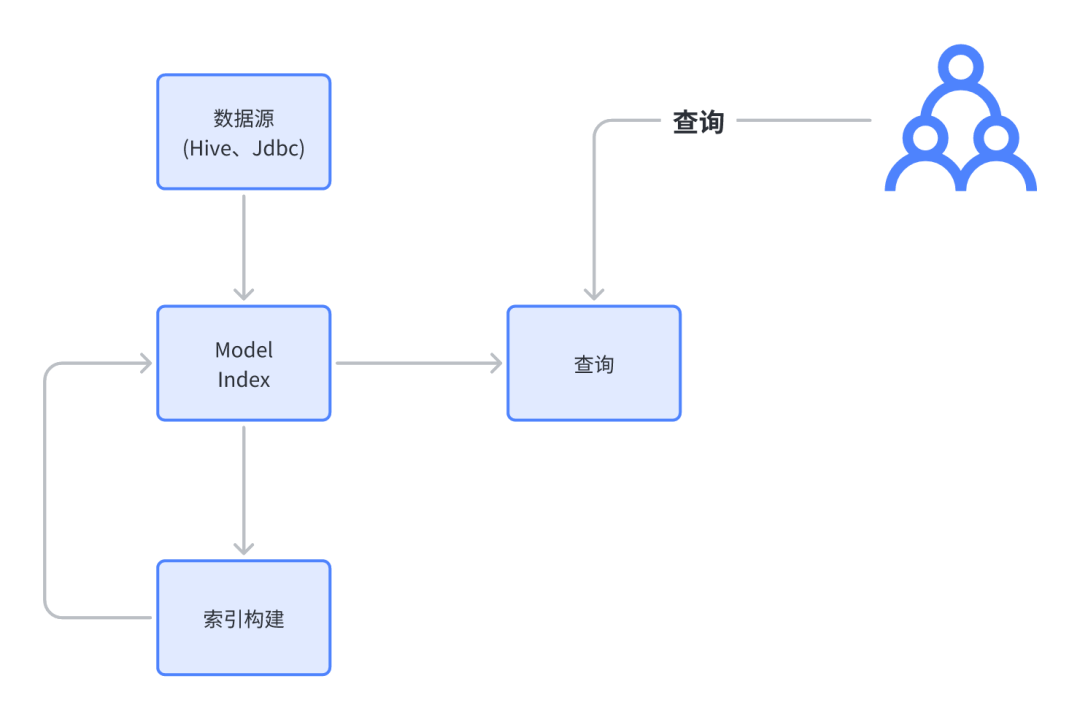
从预计算分析引擎的角度,可以发现 Kylin 在做以下事情:
元数据:定义预计算的内容,主要依靠 Model、DataFlow、IndexPlan 来定义我们需要什么表、维度、度量从而定义出最后的 Index。
索引构建:把元数据中定义的 Index 物化(parquet 文件)到 HDFS、OSS、OBS
查询:把用户的查询转化为对 Index 的查询。
可以发现,Kylin 的预计算,很像物化视图。但是对比别的查询引擎(druid),Kylin 的预计算不影响用户的 SQL,druid 则需要改写 SQL。
举个例子:有张表 table1
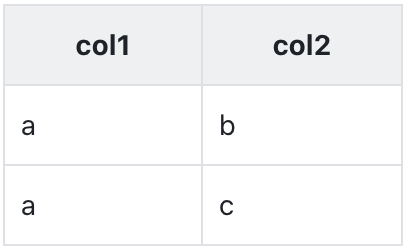
table1
Kylin 和 Druid 都对 table1 创建了索引
维度:col1、col2
度量:count(1) as m1
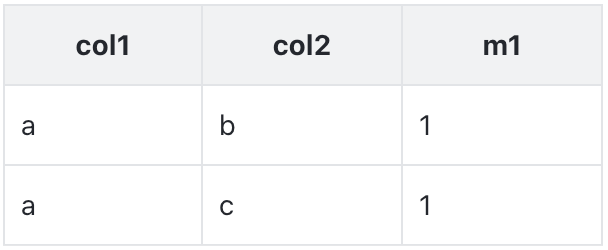
对于 Kylin,这个索引对用户不可见,用户使用原始SQL查询
SELECT col1, count(1) FROM table1 GROUP BY col1;
对于 Druid,这个索引的对外暴露的,用户需要改写 SQL 后查询
SELECT col1, sum(m1) FROM table1_index GROUP BY col1;
所以,Kylin 查询所做的就是
SELECT col1, count(1) FROM table1 GROUP BY col1;变成SELECT col1, sum(m1) FROM table1_index GROUP BY col1;
2. Kylin 5 查询流程
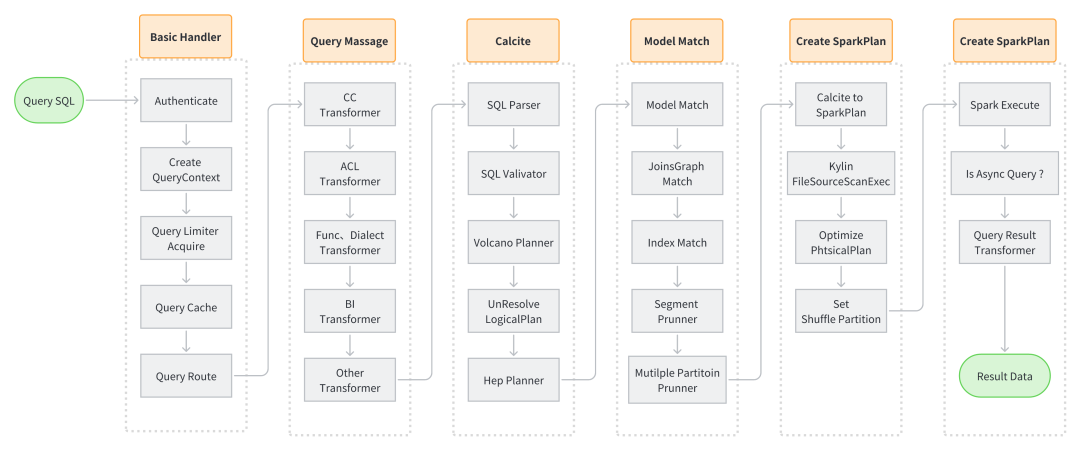
查询流程
1.查询基础信息生成和校验
用户权限
QueryContext 生成
缓存搜索
2.Query Massage 查询 SQL 语句改写
3.Apache Calcite 改写 SQL
解析、校验
CBO (Cost-Based Optimizer ) 基于成本优化
RBO (Rule-Based Optimizer ) 基于规则优化
4.Model Match
OLAPContext 切分
Model、Index 匹配
Segment Pruning (Segment 裁剪)
多级分区裁剪
5.Create Spark Plan
Calcite Plan to Spark Plan (Calcite 执行计划转换 Spark 物理执行计划)
FilePruner (文件裁剪)
优化物理执行计划
6.Spark Execute
Spark 根据物理执行计划读取文件进行计算
将计算结果反序列化后返回给用户
3. 一条 SQL 闯 Kylin
以下面 SQL 举例,简述 SQL 进入 Kylin 后的变化过程。
select sum(A.price)from db.Ainner join (select b_id, count(*)from db.Bgroup by b_id) B on A.a_id = B.b_idwhere A.event_id = 1;
3.1 SQL Massage
SQL 在各个不同的 transformer 之间流转,转化成
select sum(A.price)from db.Ainner joinselect b_id, count(*)from db.Bgroup by b_id) B on A.a_id = B.b_idwhere A.event_id = 1limit 500;
没错,其实就加了个 Limit,虽然 transformer 多,但不对所有 SQL 都适用。
3.2 SQL 解析、校验
使用 Apache Calcite 对SQL进行解析和校验
解析:SQL -> SqlNode
校验:校验SQL语法、库、表、字段、数据类型、函数等是否有误
3.3 生成 逻辑/物理 执行计划
逻辑执行计划
LogicalSort(fetch=[500])LogicalAggregate(group=[{}], EXPR$0=[SUM($0)])LogicalProject(price=[$2])LogicalFilter(condition=[=($1, 1)])LogicalJoin(condition=[=($0, $3)], joinType=[inner])LogicalTableScan(table=[[db, A]])LogicalAggregate(group=[{0}], EXPR$1=[COUNT()])LogicalTableScan(table=[[db, B]])
优化后的物理执行计划
EnumerableAggregate(group=[{}], EXPR$0=[SUM($0)])EnumerableCalc(expr#0..4=[{inputs}], price=[$t2])EnumerableHashJoin(condition=[=($0, $3)], joinType=[inner])EnumerableCalc(expr#0..2=[{inputs}], expr#3=[1], expr#4=[=($t1, $t3)], proj#0..2=[{exprs}], $condition=[$t4])EnumerableTableScan(table=[[db, A]]) EnumerableAggregate(group=[{0}], EXPR$1=[COUNT()])EnumerableTableScan(table=[[db, B]])
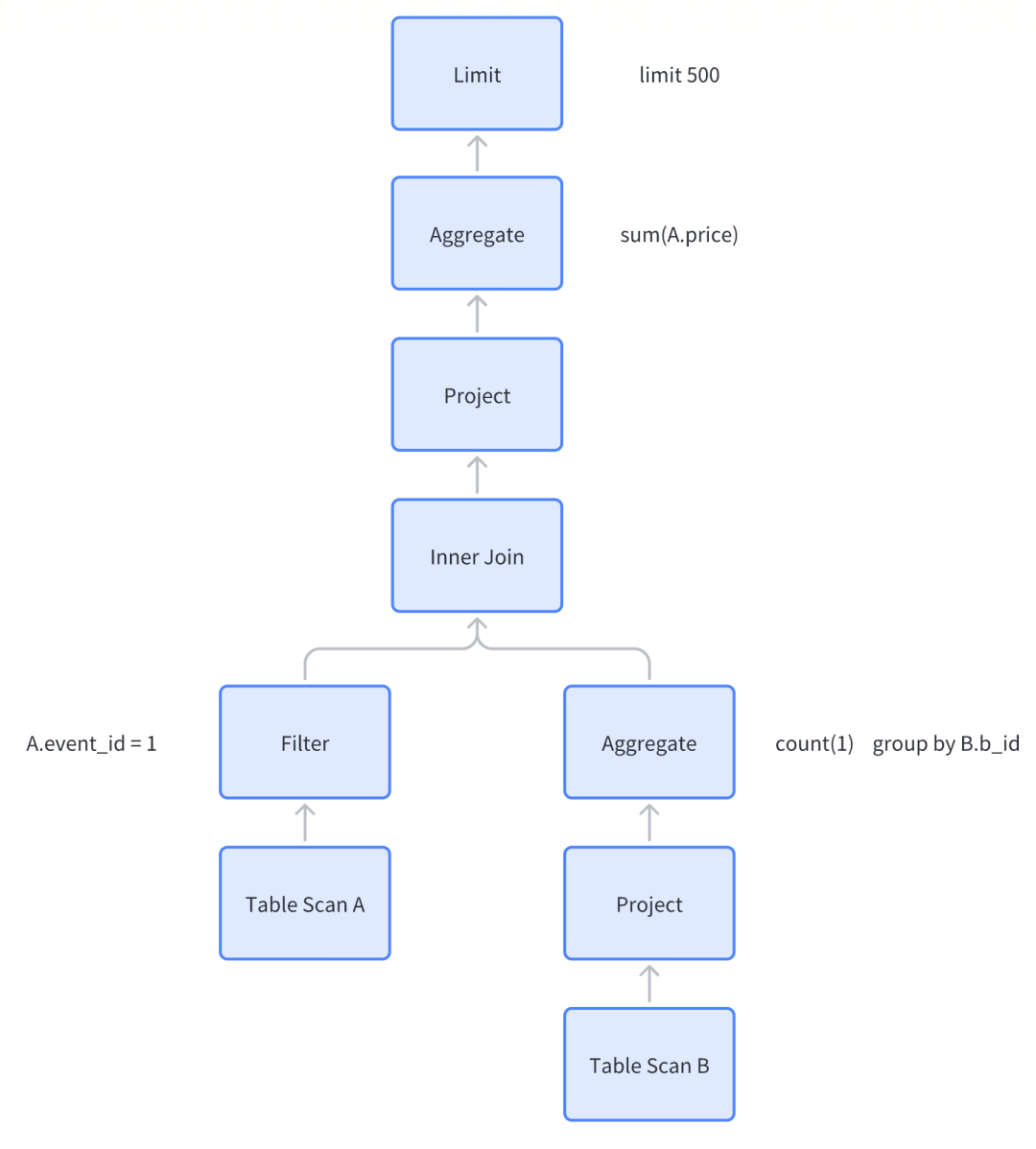
RBO (Rule-Based Optimizer 基于规则的优化器)
是一种根据SQL的模式和条件生成相应的执行计划的优化器,即根据规则来优化执行计划的过程。RBO 与数据无关,只要 SQL 确定了,经过优化后的执行计划也就确定了。
谓词下推
常量折叠
列裁剪
Join 重排序
等等
CBO (Cost-Based Optimizer 基于代价的优化器)
相比较 RBO,CBO 会根据数据的统计信息(数据量,CPU)和代价模型来进行执行计划的优化。CBO 优化过程中会一遍遍的迭代各种规则,直到找到执行代价最小(Cost 最小)的执行计划。Starrocks 和 Spark 都可以通过开启 CBO 来优化查询的执行计划。
3.4 OLAPContext 切分、模型/索引匹配
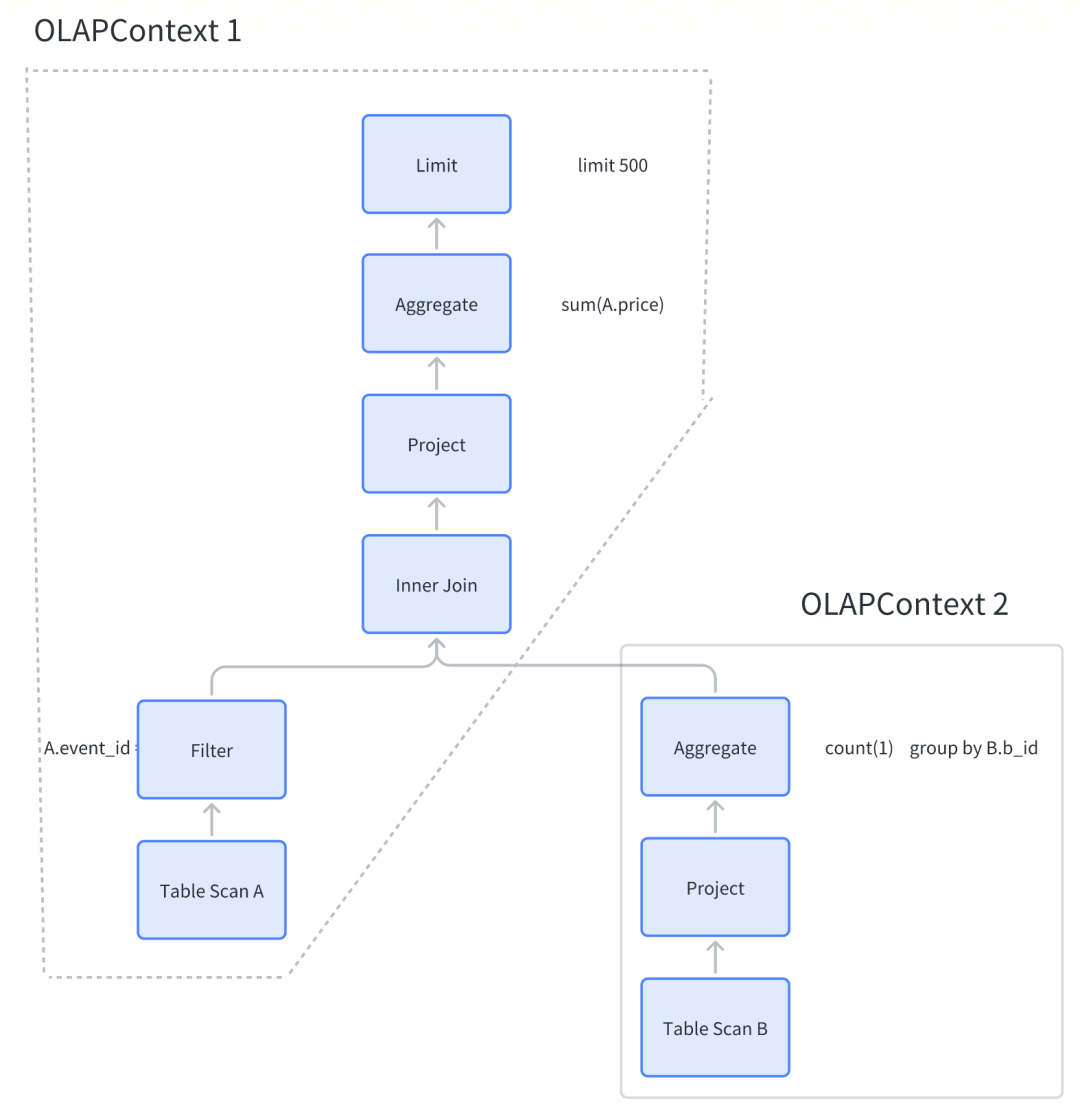
如图,这条 SQL,会被切分成两个 OLAPContext。那么 OLAPContext 到底是什么呢?
上述执行计划在 Calcite 中使用 RelNode 树来表示。此执行计划无法直接用于 Kylin 预计算。因此 Kylin 自定义了一种可以 预计算的数据结构,就是 OLAPContext。OLAPContext 定义了无数属性,主要如下:
aggregations:记录 SQL 中的度量
filterColumns:记录 SQL 中的过滤条件(where ... )
groupByColumns:记录 SQL 的分组信息(group by ... )
joins:记录表之间的 Join 关系
allTableScans:记录所有扫描的表
firstTableScan:OLAPContext 生成时第一张扫描的表(主表)
topNode:OLAPContext 顶端 RelNode 引用
OlAPContext 的切分规则是:用 RelNode Visitor 深度优先访问 RelNode,一旦遇到 Aggregations 就切分一个 OLAPContext。
切出两个 OLAPContext 后,Kylin 会将这俩 OLAPContext 分别拿去做 Model 匹配和 Index 匹配。没匹配到,就换继续切,最终还是没匹配到合适 Model 和 Index,就会把 SQL 丢给 Spark 做下压查询。如果匹配到了合适的 Model 和 Index,就会将 CalcitePlan(逻辑计划) 转化为 SparkPlan(物理执行计划) 后执行。
3.5 Segment Pruner
Segment 是 Kylin 中 每个 Model 已构建不同时间段数据的描述。例如:ModelA 的分区字段是 dt,目前构建了 [2023-06-01, 2023-06-10] 范围内的 Segment
Segment1 -> [2023-06-01, 2023-06-02)
Segment2 -> [2023-06-02, 2023-06-03)
...
Segment Pruner 翻译过来就是 Segment 裁剪。有这个步骤的原因是因为可以根据 SQL 中的过滤条件,选择合适的时间范围内的 Segment 来回答查询,避免扫描大量无用数据(Data Skipping)。
3.6 File Pruner
文件裁剪实现了 Spark 的 FileIndex 接口,其作用为在 Spark 物理执行阶段只读取必要的 Parquet 文件。与 Segment Pruner 一样,也是查询加速的重要手段(Data Skipping)。
4. SQL Massage
SQL Massage 是查询流程中比较重要的一环。SQL Massage 意为 SQL语句转换。其产生的原因是因为 Kylin 为了对接多个 BI 平台,为了兼容 SQL 语法,将部分逻辑提前到 SQL 执行之前。
SQL Massage 是 Kylin 对查询 SQL 在生成执行计划之前的预处理,通过使用正则、Calcite 等语法解析器等手段对 SQL 语句进行重写。
常见有下面几种 Massage 规则:
BI SQL 转换:org.apache.kylin.query.util.PowerBIConverter
关键词转换:org.apache.kylin.query.util.KeywordDefaultDirtyHack
标准化 SQL:org.apache.kylin.query.util.DefaultQueryTransformer
删除注释:org.apache.kylin.query.util.EscapeTransformer
select * 替换:org.apache.kylin.query.security.HackSelectStarWithColumnACL
转大写:org.apache.kylin.source.adhocquery.DoubleQuotePushDownConverter
SQL 方言转换:org.apache.kylin.query.util.SparkSQLFunctionConverter
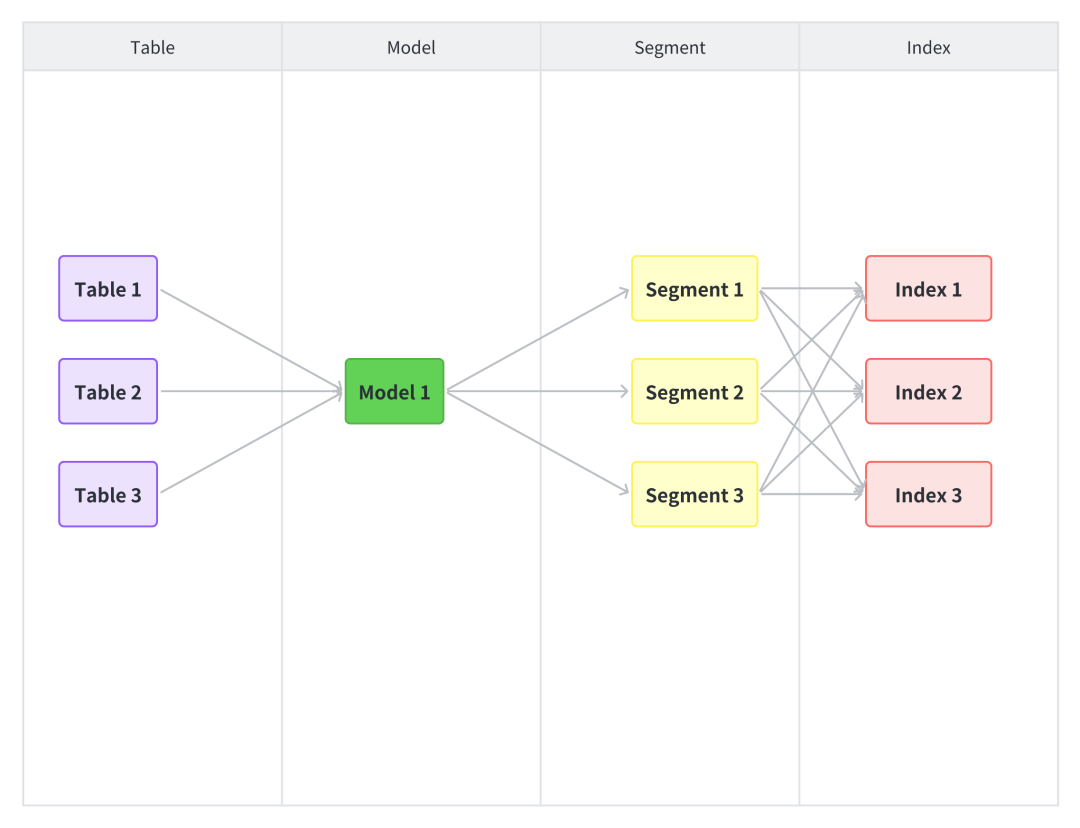
核心元数据简图
07
Kylin 5 新特性
Kylin 5 相比较老版本 Kylin4 , 带来了很多很多新特性。
1. 全新的交互界面
前端交互界面全新升级,通过更直观的可视化建模方式,让用户一目了然,降低使用门槛。
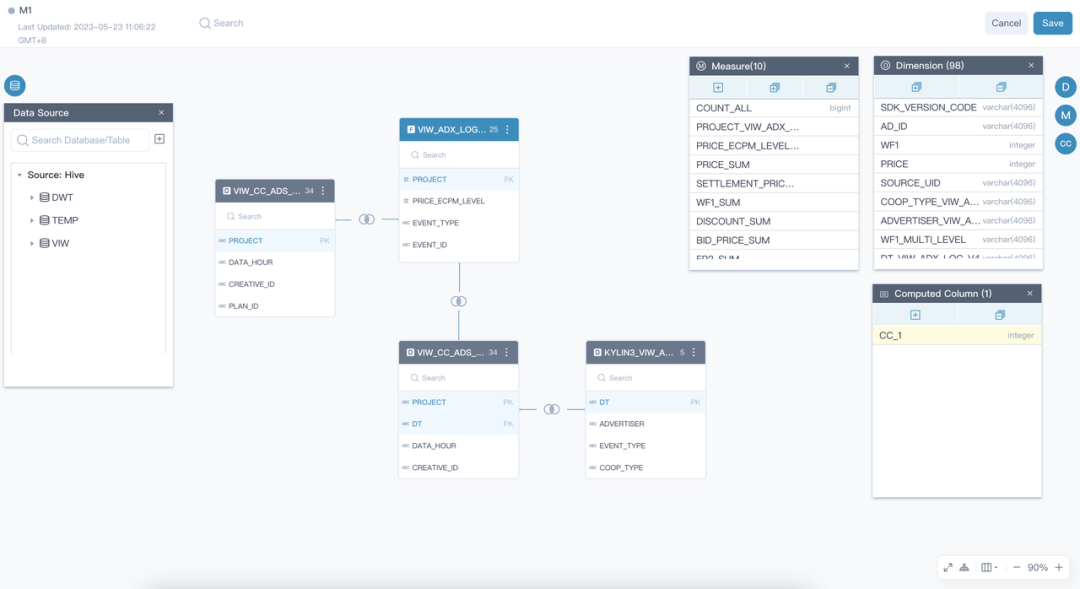
2. 可视化建模
新建模型
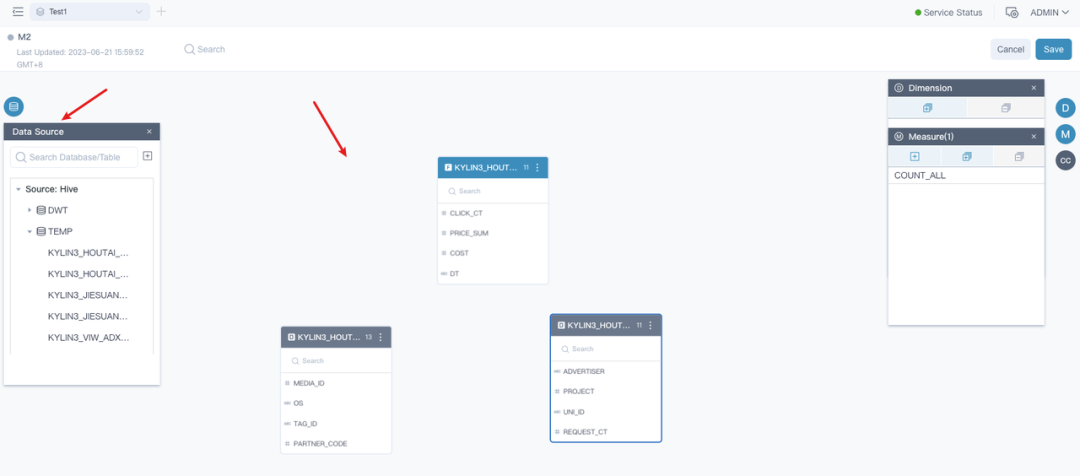
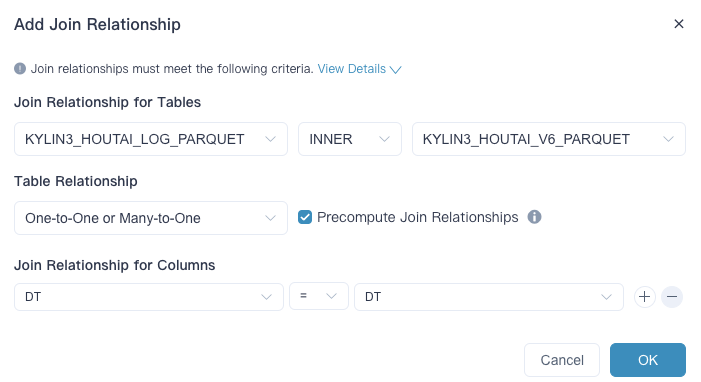
定义事实表,定义表关联关系
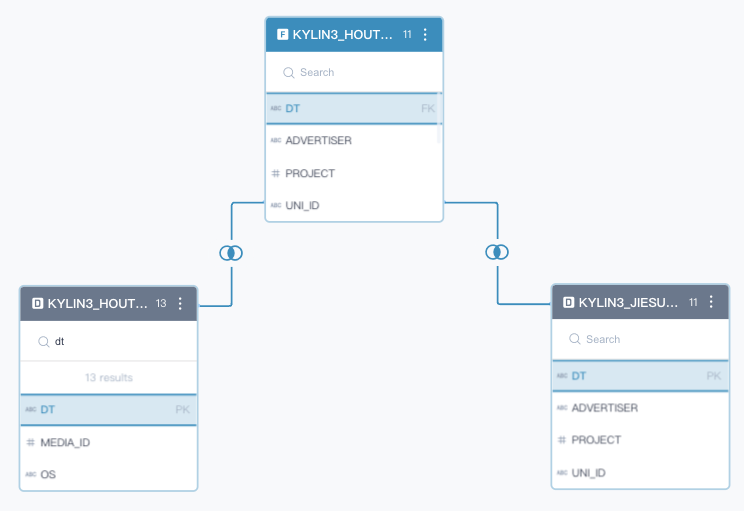
维度、度量、可计算列
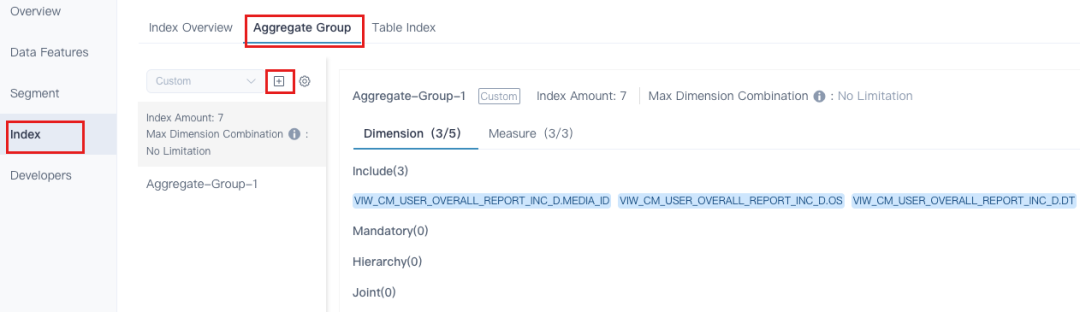
聚合组、索引
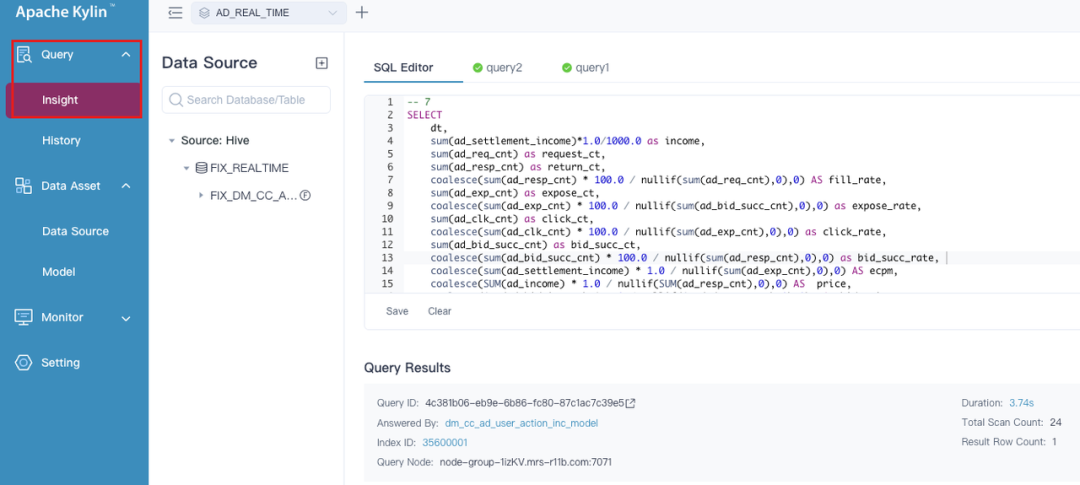
索引构建、查询

3. 元数据 Schema 升级
将 Model 和 Cube 合二为一成为新的 Model,不再有 Cube 的概念。在 Kylin5 中不需要先创建 Model (Join Relationship),再定义 Cube(维度和度量)。而是将两者合一,简化流程。
新增 Index 和 Layout 元数据,可以提升 Kylin 的扩展性。新增了明细索引,用于回答非聚合查询行的 Index 没有 63 个维度上限。
引入 IndexPlan 元数据,IndexPlan 根据用户的模型设计和静态规则生成索引(RuleBaseIndex)这些 IndexPlan 可以灵活适配 Index 的增减减少 Model 元数据的复杂度。
4. 灵活的索引管理
对比之前的版本,Kylin 5 提供了灵活的索引管理,支持对部分索引在部分时间内进行构建和删除。
痛点一:随着时间的推进和数据分析师分析方向的更改,用户大量新增查询无法被 Excatly Match,导致查询时间越来越长。所以用户希望手动增加或减少一些索引,来适配新的查询。
在 Kylin 4 中,用户只能克隆一个新的 Cube,然后在新的 Cube 上编辑后触发任务重头构建。
在 Kylin 5 中,用户可以在现有的 Model 上直接创建新的索引,Append 追加构建到 Segment 中。
痛点二:随着数据分析师关注的业务方式的变化,用户要求在 Cube 上新增维度和度量。
在 Kylin 4 中,用户同样需要克隆新的 Cube 之后进行一系列操作和构建。
在 Kylin 5 中,用户可以在 Model 上直接增删维度和度量,任何新增的索引可以通过一键提交任务构建出来。
5. 明细查询
Kylin 的优势是聚合查询,明细查询相较而言不具优势。
Kylin 5 通过物化(部分)平表来加速明细查询,同时可以根据数据特征来设置 ShardKey 和 SortKey 来提升高基列数据的过滤性能。这个功能叫做 TableIndex。
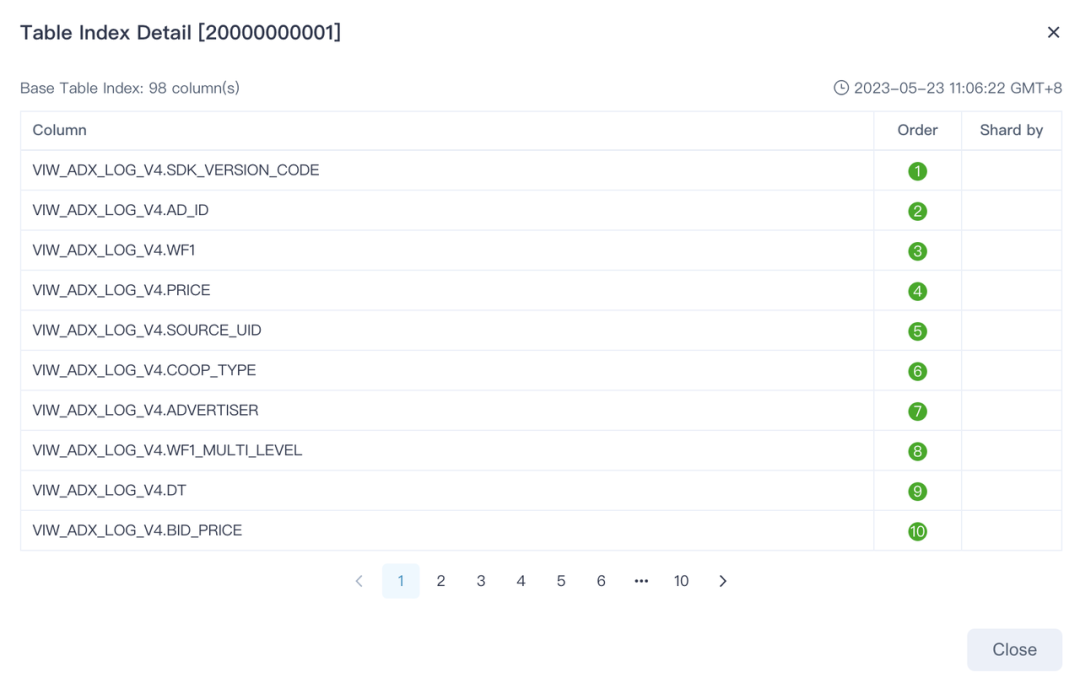
明细索引
6. 可计算列
Kylin 5 支持在模型上定义 SQL 表达式,变相拥有了轻量级 ETL 能力。用户可以把新定义的表达式当成一个普通的列,基于他定义新的维度和度量,从而使得这部分表达式也被预计算引擎加速。
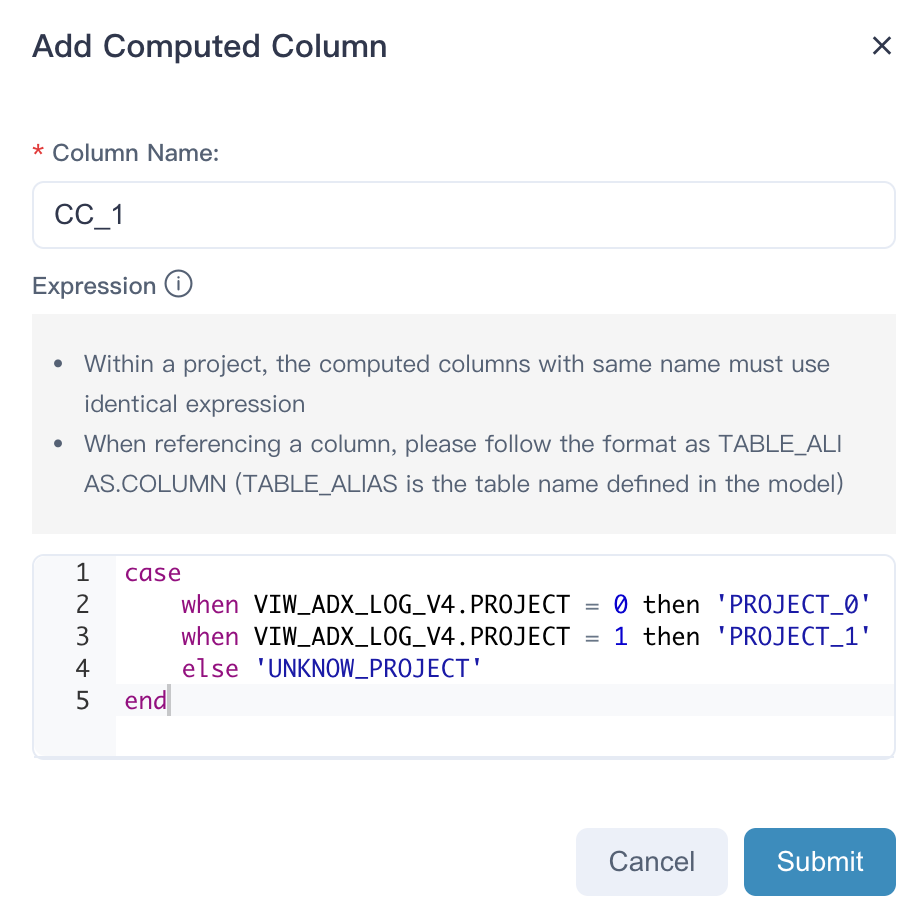
7. 更详细的查询历史
Kylin 5 记录了更加详细的查询历史信息。对于单个查询的耗时明细,记录了每个 Step 的耗时。对于慢查询根据此图可以快速定位性能瓶颈。
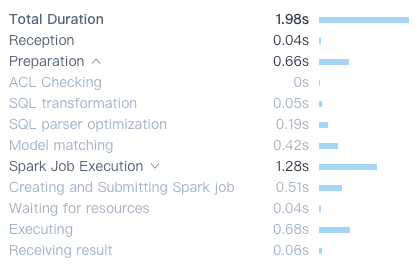
8. 索引命中频率更新
此功能在开源版之前有 BUG,目前七猫已经修复 bug 并贡献到 Kylin 中。
Kylin 会记录任何命中索引的查询,异步更新到索引的 Usage 属性中。用户可以根据 Usage 属性判断索引使用的频率,从而适当的裁剪或新增索引,提高查询效率或节省存储成本。
9. 查询缓存
Kylin5 支持两种缓存机制:
本地缓存:数据缓存在查询 Kylin 节点的本地内存中,节点之间不互通。
分布式缓存:数据缓存在 Redis 中,当部署了多台 Kylin 节点时,一台节点的缓存对另一台节点可见。使用分布式缓存可以避免大多数重复计算,节省资源,提高查询速度。
Kylin5 支持多 Query 节点部署,使用查询分布式缓存时可以参考下图
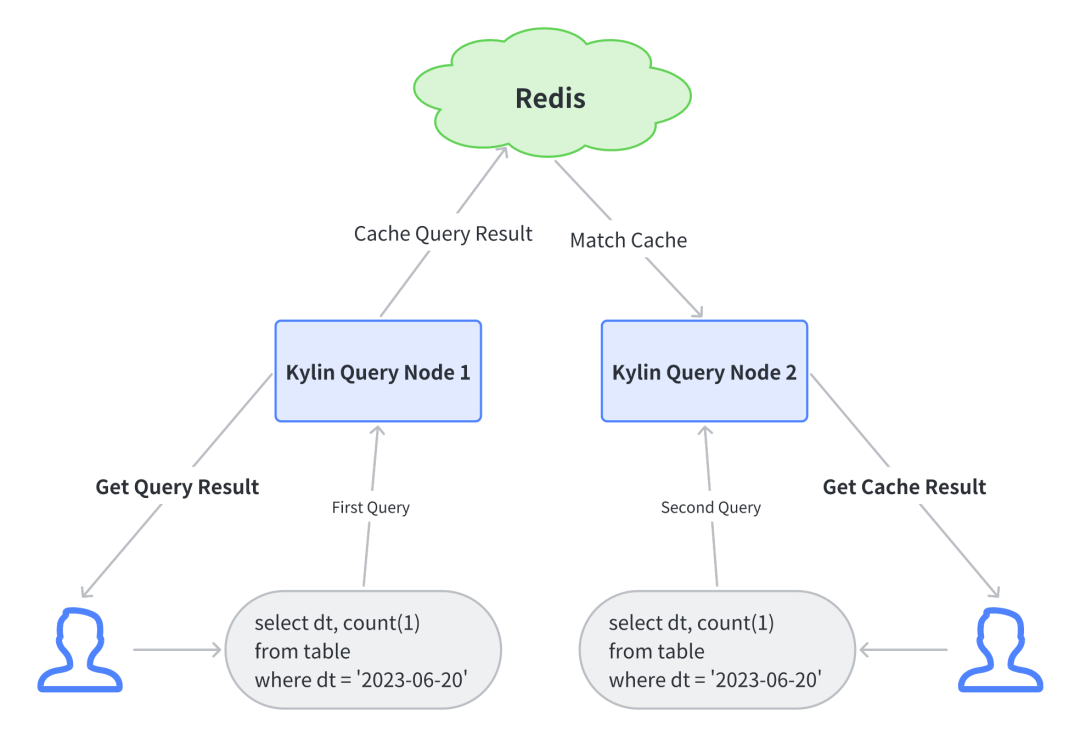
分布式查询缓存
10. 表行列级权限
此功能暂无前端,只能通过 API 调用。Kylin5 支持用户的 表、行、列 权限控制。
举个例子,有下面一张表 TableA
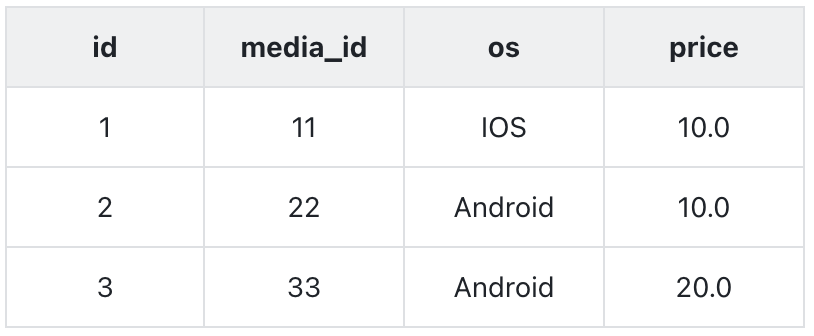
有用户 A(分析师)、B(研发)可以做到:
Table A 表权限:用户 A 可以查询表,用户 B 无法查询;
price 列权限:用户 A 可以查询所有列,用户 B 只能查到除 price 外的所有列;
行权限:用户 A 可以查询所有数据(3 行),用户 B 只能查询 os=IOS 的数据;
11. 其他
Kylin 5 还引入并增强了很多功能,如:
Spark2 升级 Spark3
查询、构建火焰图。
构建自适应任务提交。
构建任务拆分子步骤。
实时功能
等等 ...
08
正在做的
Kylin4 升级 Kylin5 进行中。
Kylin5 正在业务端推广 Kylin5 的使用,以及将部分报表从 Trino 中迁移到 Kylin5。
09
未来计划
完成 Kylin4 升级 Kylin5。
继续在业务端发力,优化其报表查询速度,提升影响面。
Kylin 5 拉新进行中。
10
总结
总的来说,Kylin 5 运维简单,成本低,用的越久越深,成本越低。它既可以使用预计算来加速查询,也可以使用下压查询来满足日常 AdHoc 需要。Kylin 的可视化建模极大方便了建模人员,降低了使用门槛。
欢迎感兴趣的小伙伴来和我们一起来研究和打磨 Kylin 5 性能和稳定性,和我们多多交流。
推荐阅读
👇 点击「阅读原文」访问官网
