




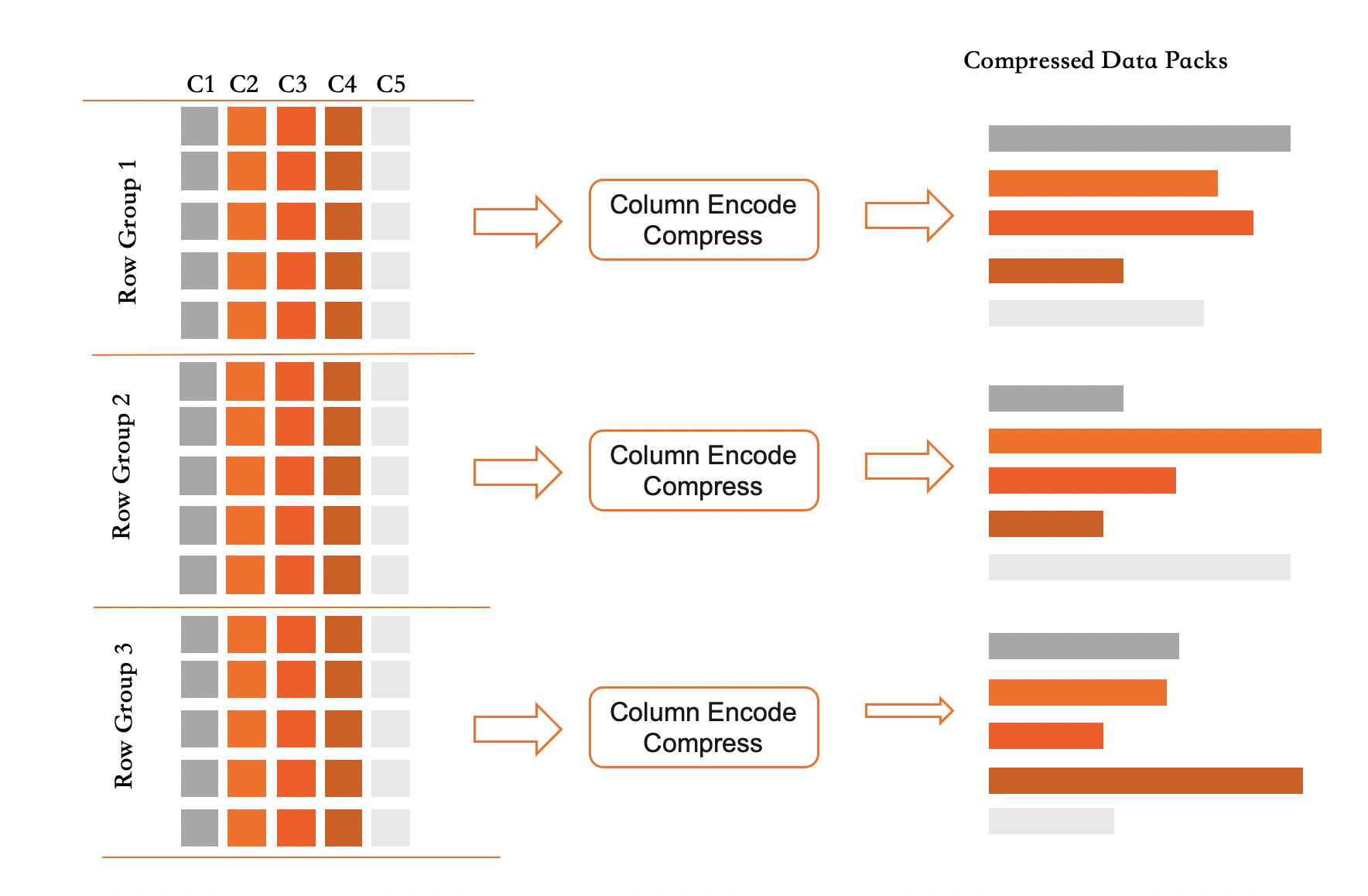
在HTAP场景中,PolarDB IMCI(In Memory Column Index)选择列式Heap Table作为底层主要存储架构来支持实时更新,SQL Server以及Oracle的Column Index也采用了相同的存储架构。然而,Heap Table架构虽然更新速度快,但在小范围的扫描上表现并不理想,很多时候需要进行全表扫描。为了尽量减少全表扫描的问题,SQL Server主要通过Min-Max、分区以及聚簇索引来降低扫描数据量;Oracle是全内存的列索引,其主要通过Min-Max以及metadata dictionary来减少全表扫描。PolarDB IMCI属于列存表的模式,数据支持落盘,实现了更加多样化的方法来优化全表数据扫描。

PolarDB IMCI按RowGroup组织数据,每个RowGroup包含64K行。对于每一列的列索引,其存储都采用的是无序且追加写的格式。因此,IMCI无法像InnoDB的普通有序索引那样,可以精确地过滤掉不符合要求的数据。在读取DataPack时,需要从磁盘中加载进内存并解压缩,然后遍历DataPack中的所有记录,利用过滤条件筛选出符合条件的记录。对于大表而言,这些扫描任务的代价很大,并会对LRU cache造成一定程度的污染,导致整体查询延迟升高,QPS大幅降低。
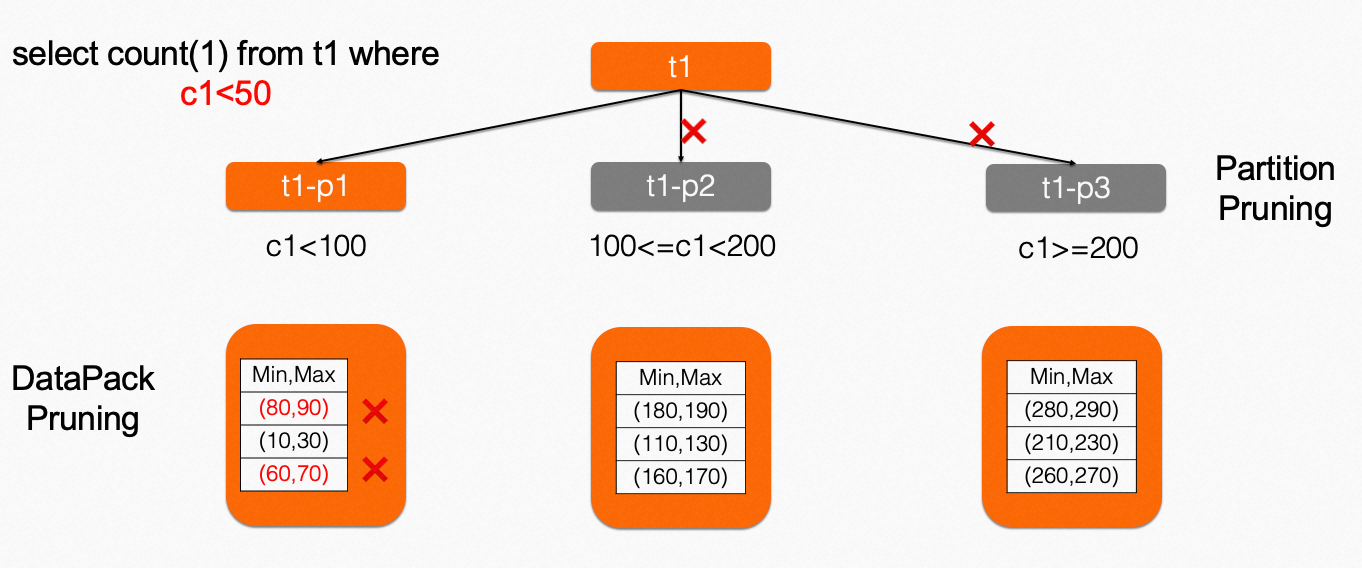
为了解决大表扫描代价过高的问题,PolarDB IMCI引入了查询剪枝技术。该技术可以在过滤数据时,提前过滤掉不需要访问的DataPack,从而减少数据访问量,提高查询效率。具体实现方式是通过访问分区信息和统计信息,结合特定的过滤条件,在查询之前就把不符合条件的数据剪去。这样就可以减少对存储的扫描次数,进而减少数据传输和计算消耗。该技术不仅适用于单表数据的查询,也适用于多表连接查询,并能大幅度提升PolarDB IMCI的查询性能。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
