




本文主要分享 OBCE V3 培训的理论和实验知识第二篇。个人观点,理解不当欢迎指出。(上篇文章标题写了个错别字,囧)
OBCE培训材料和实验官网地址:https://www.oceanbase.com/training/detail?level=OBCE 。
从应用到数据库全链路性能分析,在传统数据库集中式数据库运维场景就有。主要就是网络上链路情况复杂一点,数据库上倒还简单。ORACLE RAC 集群稍微复杂一点,多了 SCAN VIP 和 PUBLIC VIP,虽然有多个计算节点,存储只有一个,整体分析还是很简单。
现在 ORACLE/DB2/MYSQL 替换为分布式数据库 OceanBase,全链路性能分析这个事情还是要做。而 OceanBase 由于是分布式架构,数据库侧的链路情况也变得比以前复杂。本文主要分享从应用到 OceanBase 全链路性能分析背后的知识和实践经验。
应用侧


JDBC URL
需要留心不同版本的 JDBC 驱动的支持的参数,以及参数的默认值 或者参数的逻辑可能会有细节上的区别。有些版本可能会因为默认值就是上面的值从而不需要设置,也有可能因为内部逻辑的变化而不用设置这个参数。
allowMultiQueries : 设置为 true ,允许 JDBC 一次发送多条SQL(分号间隔)。
rewriteBatchedStatements:设置为 true,然后 JAVA 代码使用 addBatch 方法可以将同一张表多笔 INSERT 语句合并为 一条 INSERT 语句多个 VALUES 子句,从而节省网络上请求次数以及跟 OB 内部的 batch insert 功能对接。OceanBase ORACLE 租户也支持 INSERT ... VALUES (),(),(),...,(); 这种语法。
try {connection = JdbcUtils.getConnection();String sql = "insert into test(id,name) values(?,?)";statement = connection.prepareStatement(sql);for (int i = 1; i < 100000; i++) {statement.setInt(1, i);statement.setString(2, "" + i);statement.addBatch();if (i % 1000 == 0) {statement.executeBatch();statement.clearBatch();}}statement.executeBatch();
useLocalSessionState:默认值为 false,建议设置为 true,避免驱动频繁向 数据库发送确认一些 session 变量的查询 SQL。这个参数设置也有风险,网上介绍很多,传统数据库也一样。不过我测试的时候没在 OB 上抓到这种 SQL。不排除 OB 驱动不同版本做了些优化之类。
缓存技术
这条建议主要针对高频查询场景。如果业务场景 QPS 非常高又要求延时很低。当数据库不满足需求或者数据库解决成本太高的时候,应用端可以使用一些缓存产品。这个很好理解。唯一要预防的是缓存崩溃的时候,请求会打到数据库上。很可能出现应用连接池满或者数据库压力大幅增加的情况。
网络环节
定性分析,从应用到数据库的网络链路经过那些环节很好分析。一般都是应用服务器 到 F5或其他负载均衡设备,再到 OBProxy 然后是到 OBServer。定量分析就是把这些环节的延时 SLA 都划分出来。这些 SLA 都是在一定并发下的指标水平。超出并发处理能力时,延时自然会增长。
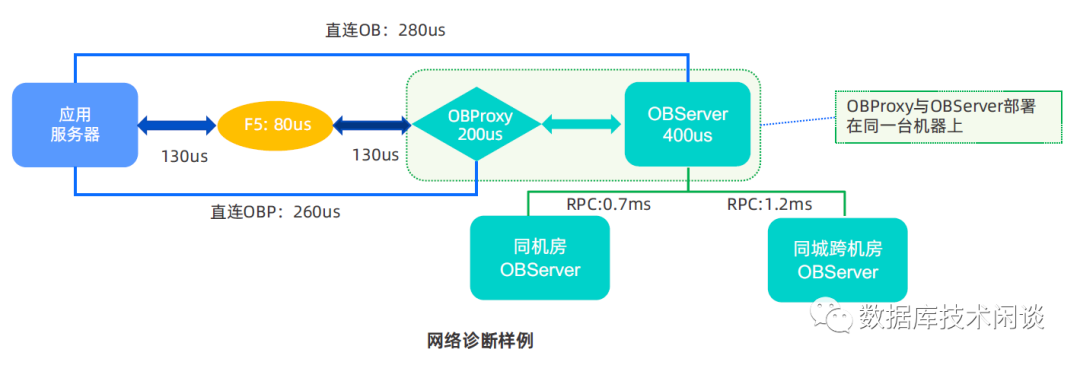
OB 环节
OB 数据库架构是计算和存储不分离,SHARED NOTHING,每个节点起一个 OBSERVER 进程,把数据库的活全干了。节点 OBSERVER 也支持客户端连接(2881端口)并支持 SQL 路由。只是SQL路由有两个问题就并不完美。一是走完整的 SQL 解析执行路径,二是如果节点上没有该租户的数据,是无法通过该节点连接到该租户(报错:tenant not in the observer )。
所以 OB 数据库的使用还需要一个代理角色,这个就是 OBProxy,其核心功能之一就是 SQL 路由。只做 SQL 路由不做 SQL 执行计划解析或执行,所以可以很轻量。一个 OBProxy 进程轻松可以实现 5W 的 QPS。
不完美的是 OBProxy 并不像 ORACLE RAC 里不同节点监听一样有一个集群服务环境。OBProxy 可以部署多个,但是每个都独立工作,彼此不组建集群。所以,OBProxy 集群(OCP 这么称呼)并没有高可用和负载均衡能力,这个能力需要靠外部负载均衡来实现。通常就是 F5 或 A10 这类硬负载设备,或者 LVS 或 SLB 这类软负载产品。小客户还可以用 HAProxy 或 nginx 实现。这时候又引入一个新的问题,就是 JDBC 有个Query 超时杀会话功能,会发起新的会话去杀老的会话,由于F5负载均衡可能会将这个新的会话路由到其他 OBProxy 节点导致 JDBC 的杀会话功能失效。这个在传统数据库里一样存在。在 OB 里可以关闭 JDBC 这个功能,利用 OB 的 Query 超时杀会话机制。

OBProxy 是个有责任的代理,不会主动断开连接,除非应用客户端自己断开连接或者客户端连接被其他因素杀掉。当前端连接断开时,OBProxy 会断开后端连接;如果前端连接没有断开,只是后端连接因为 OBServer 节点故障断开时,OBProxy 会在下次请求来时自动创建新的后端连接(针对 OBServer 故障的高可用,应用客户端可能都感知不到后端 OBServer 节点故障,除非故障的时候刚好有查询语句才执行)。在后端 OBServer 故障的时候,OBProxy 可以重试正在执行中的查询语句。但是如果查询语句在事务中,OBProxy 会选择断开前端连接以及其他后端连接。OBProxy 目前并不能做事务保持(可能也不想做,因为负担太重吃力不讨好)。此时需要应用端捕获事务异常并做处理。
在 OBProxy的管理界-u面( -h127.0.0.1 -uroot@proxysys -P2883 -pOBProxy管理密码) 里,可以查看 OBProxy支持的连接。具体可以参考以前直播视频里操作:https://mp.weixin.qq.com/s/jkNGF2SrnqyktC04UX4-bA 。
show proxysession 命令查看当前 OBProxy 所有会话(前端连接)。
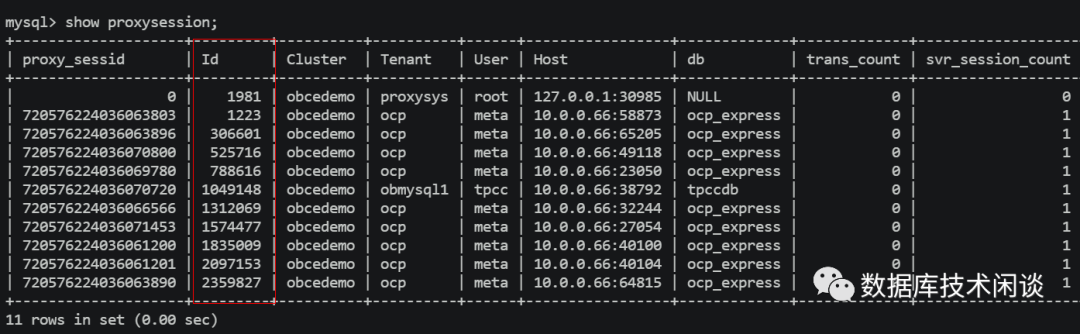
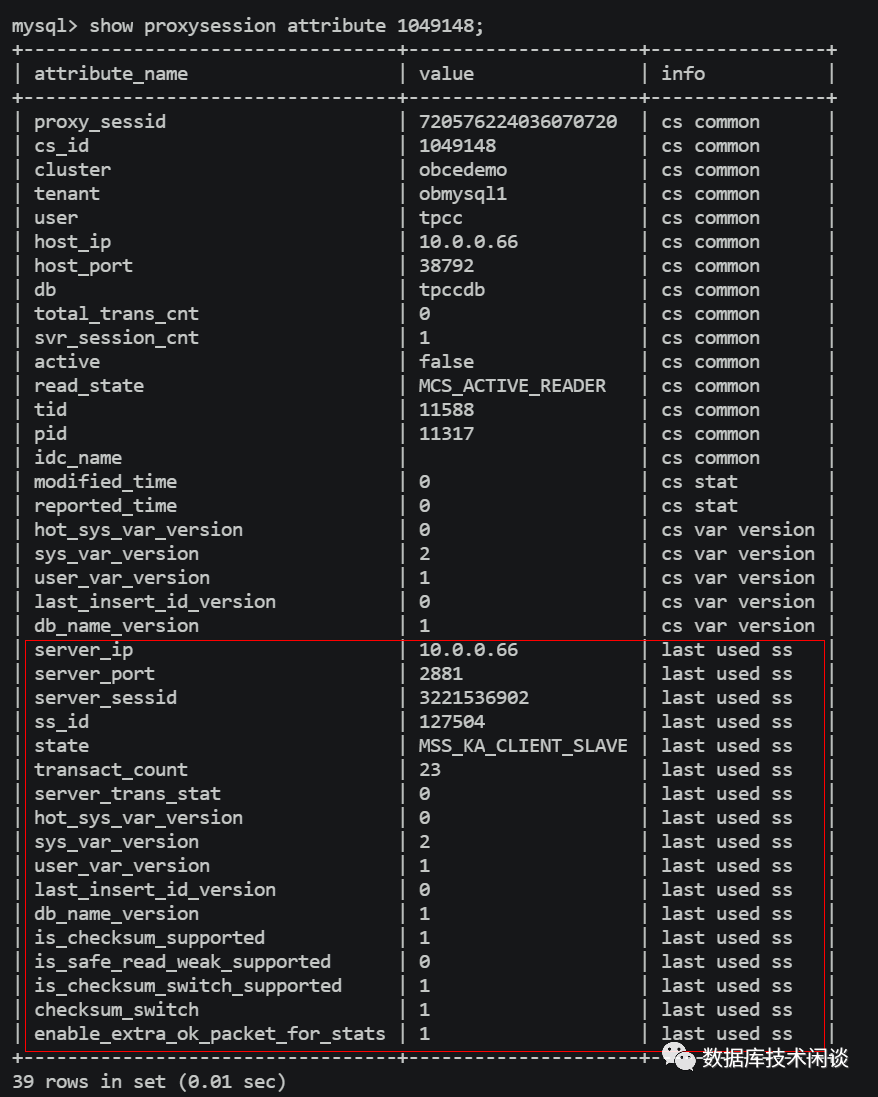
以上是 OBProxy 的 连接原理。接着说 OBProxy 的路由。这个路由策略就更加复杂了。
SQL 路由首先看 SQL 的。一些SELECT @@系统变量命令、 SHOW 命令、SET 命令、ALTER SYSTEM|SESSION 命令等 SQL 随便路由到后端 OBServer 节点都没有关系。当然该节点必须是连接的目标租户所在的节点。这类 SQL 也是租户 QPS 的一部分,占总 SQL 比例应该很小(如果很大,问题就有点严重,说明业务 SQL 很少,应用的 JDBC 驱动或者应用底层框架或 OBProxy 自身的SQL 太多)。我们关注的是 SELECT/INSERT/UPDATE/DELETE/REPLACE 等常用的查询和修改语句的路由。
路由策略最容易接受的就是发往 SQL 访问数据的主副本。当 SQL 里访问到多个表的时候就选择第一个表;当这个表是分区表时就看过滤条件能不能简单计算是哪个分区,否则随机发往某个分区的主副本所在节点。问题是 OB 里不同表或者分区表的不同分区数据主副本可能在不同的 OBServer节点,在事务里的 DML SQL。如果每个 DML SQL 发往了不同的 OBServer 节点,这个事务就成为分布式事务了。但是 OBProxy 的职责是 SQL 路由,并不是分布式事务中间件,没有协调处理分布式事务的能力。所以 OBProxy 对事务的 SQL 就一个原则,事务里所有 SQL 都发往开启事务的那条 SQL 被路由到的节点上去,至于后面的事就全部交给那个节点 的 OBServer 上的 SQL 引擎去处理了。
然后问题又来了,开启事务的第一条 SQL 怎么判定,业务层面事务的第一条 SQL 可能是个查询语句。OBProxy 这个老6 也不自己判断是否开启事务,而是先路由给 OBServer 判断,看 OBServer 的回包里是否表明这条 SQL 在事务中了。OBServer 针对这种情况有参数 ob_proxy_readonly_transaction_routing_policy 来决定只读查询 SQL 是否开启事务。默认是 True,建议设置为 False。当 SQL 开启事务后,OBProxy 就自觉地将该会话后续 SQL 都标记为在事务中,并统一路由到开启事务的 SQL 被路由到的那个 OBServer 节点上。注意,这个是 OBServer 集群参数,跟 OBProxy 设置无关。

路由的挑战还不仅如此。OBProxy 路由判断时会取 SQL 访问的表的分区的三副本信息并缓存起来,后面就直接访问路由缓存了。所以大部分时间OBProxy是能够准确路由的。但不排除缓存失效或者数据陈旧了(OBServer 端已经发起分区主备切换了),OBProxy 可能将 SQL 发往一个错误的节点上。这个节点 OBServer 并不去判断 SQL 路由是否正确,而是正常解析生成执行计划。只是发现执行计划要访问的数据主副本在其他节点上,就把这个执行计划标记为远程执行计划(plan_type=2,remote plan)。说到 SQL 执行计划类型 还有本地执行计划(plan_type=1,local plan)和分布式执行计划(plan_type=3,distributed plan)。SQL 执行计划属于 OBServer 上 SQL 引擎的职责。分布式执行计划产生的原因主要是 SQL访问的数据的分区分布在多个节点了。除此之外,远程执行计划产生的原因就是 OBProxy 路由带来的。大部分是事务路由特点导致,少数是路由错误。有关这三类执行计划在后面 SQL 优化章节介绍。
上面路由错误的处理是默认行为,OBProxy 还有个参数 enable_reroute 设置是否开启二次路由。即在路由错误的时候,通知 OBServer 告诉 OBProxy 正确的节点然后 OBProxy 重新路由。这个时候在 GV$OB_SQL_AUDIT 是能看到一条路由错误的记录(ret_code=-错误码 )。

OBProxy 的路由策略还包括弱一致性读路由策略、LDC 路由策略等,这个在 OBCP 的材料里介绍的比较多,这里就不重复了。一般在两地三中心或三地五中心架构里要做双机房的双活以及读写分离这种方案时,就需要研究和运用 OBProxy的路由策略。
OBProxy 的责任分析完了,接下来就是 OBServer 的了。首先说前面三类 SQL 执行计划的影响。很显然,本地执行计划的 SQL 性能最好,不会有网络请求延时;而远程执行计划和分布式执行计划就相对要差一些。当然优化方案也有。分布式执行计划的 SQL 里可以适当发挥并行处理能力,也能一定程度提升性能。此外,就是利用表分组功能,将业务上有密切联系的相关表的分区聚合在一个 OBServer 节点上。还加上复制表功能(让表在所有节点都有一个强同步的备副本,即全同步),都能减少分布式执行计划和远程执行计划的比例。这两个功能 OB 的用户基本上耳熟能详了。
远程执行计划和分布式执行计划的 SQL 带来的最大问题还是分布式事务问题。OceanBase 租户呈现给用户的只有一个事务,跟传统数据库体验一样,应用客户端完全感知不到分布式事务。OceanBase 的分布式事务处理也是两阶段提交,不过做了很多优化,实际是三阶段提交。用第一个参与者取代了单独的协调者,同时协调者不写日志(故障时的状态根据参与者的报文反推协调者的状态),加上提前释放行锁的技术。OceanBase 的分布式事务性能的关键部分事务日志落盘的等待次数相比传统的两阶段事务提交要少很多。
在分布式数据库 OceanBase 里,远程执行计划和分布式执行计划,以及分布式事务是很常见的。DBA 只能尽量的优化这类 SQL 和事务占总的 QPS 和 TPS 的比例。需要应用研发的配合;光靠运维,推动优化的难度很大。
最后,看官方总结的 OB 数据库优化设计思路也是三点:
数据分区,充分利用分布式并行处理能力。 数据聚集,减少 SQL 远程执行。 读写分离,最大化利用资源

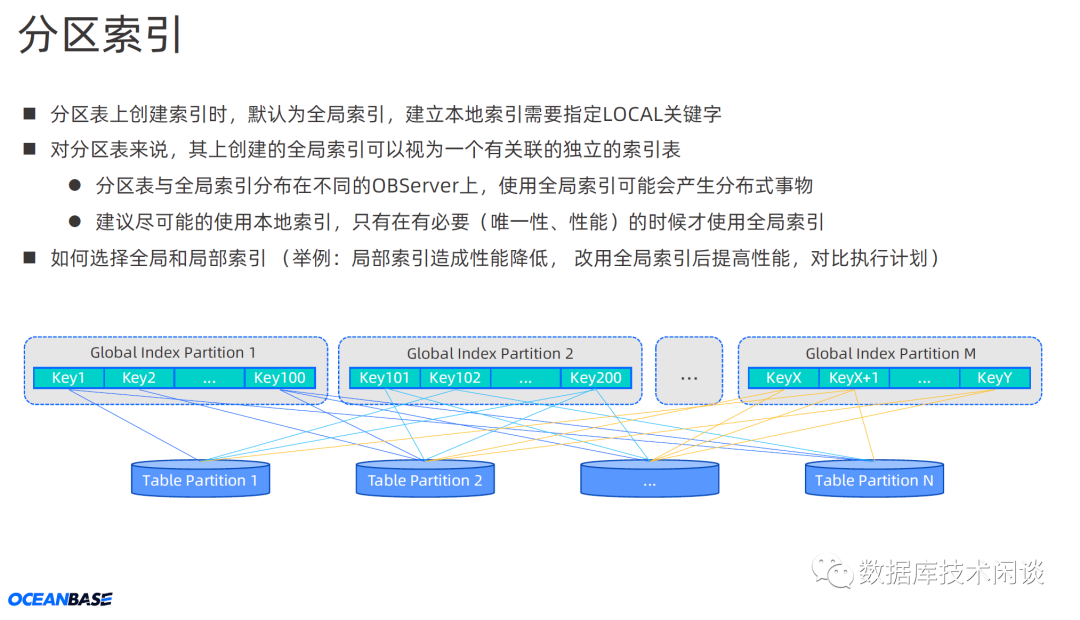
除了上面,还要了解 OB 分区表的几个硬限制。如分区数有个上限,HASH分区不能重分区(就算将来能,数据量大的时候那个也是个大变更,肯定不能随便搞),分区表主键和唯一约束必须包含分区键。分区表的全局索引或全局分区索引可能给表的更新带来更多分布式事务等。
最后再说一下,远程执行计划和分布式执行计划带来的另外一个影响,就是OBServer 节点间的网络流量传输非常大。所以 OB 机器基本要求都是万兆网卡。节点间的网络流量还包括事务日志Clog的传输。目前 OB 事务日志记录采取的是FULL LOGGING 机制,虽然增量写使用 LSM-Tree 是省了不少磁盘读写流量,反而突出了事务日志的容量比数据修改带来的容量要高出很多。不过 OB 也支持网络上事务日志传输压缩,能压缩一半吧。这个将来还是能优化的,只要将来不用类似 OMS 等解析 OB CLOG 日志的产品的话,OB 记录事务日志完全可以节省一些空间。就像 ORACLE 默认就是这么干的。这个是定量分析。定性分析就是分析 OBServer 节点之间的网络传输流量、RPC 请求数和延时、RPC 线程的 CPU 耗时和内存占用等等。此外就是主机层面要将网卡的软中断打散到多个CPU上,提升网卡软中断处理能力。
有关理论部分就总结到这里,后面实验部分篇幅也很大,就放到下一篇文章再分享。实验部分主要是根据理论去观察并理解 OBProxy 和 OBServer 的日志,并反过来验证理论的正确性和不足之处。
关于实践,个人观点是从应用诊断,到数据库SQL层面的诊断,到数据库进程日志诊断,到主机网络诊断(抓包),越是底层技术,其汇总的信息量就越大。从中识别问题相关的日志就越难。OB跟其他分布式产品特点一样,日志量异常的丰富,发展到 4.2 现在支持多达 7 种日志级别。日志级别越低,日志量就越大。分析诊断的难度就越大。通常在应用层和 SQL 层分析能解决大部分问题,剩下的就是疑难杂症。比如说网络连接异常中断问题、内存报错问题、合并超时或失败问题、重启起不来问题等等。
其他参考
