




赛题名称:Bengali.AI Speech Recognition 赛题类型:语音识别 赛题任务:从未发行的录音中识别孟加拉语语音 赛题链接👇:
https://www.kaggle.com/competitions/bengaliai-speech
比赛背景
比赛的目标是开发一个用于孟加拉语的语音识别模型,可以识别来自不同领域的语音,这些领域在训练数据中并不存在。参赛者将使用名为“Massively Crowdsourced (MaCro) Bengali speech dataset”的数据集,其中包含了来自印度和孟加拉国约24,000人提供的1,200小时的语音数据作为训练数据。
这个比赛的独特之处在于测试集包含了17个不同领域的样本,这些样本是有意在训练数据中排除的。这意味着模型对于新领域和多样性的泛化能力,也就是所谓的“out-of-distribution generalization”,在比赛中非常关键。
通过参与这个比赛,选手可以为提高孟加拉语的语音识别水平做出贡献,并解决该语言中多样化方言和韵律特征的挑战。孟加拉语是全球使用人数约为3.4亿的语言,改进的语音识别可以产生重大影响。
比赛任务
在比赛中,你需要构建一个能够处理孟加拉语音的模型,该模型要在训练集之外的多样化领域中进行泛化。这意味着你的模型需要具备较强的out-of-distribution generalization能力,以便在测试集中表现良好。
这是一个代码竞赛,比赛数据集包含大约1200小时的孟加拉语音记录。你的目标是对在训练集方面是“out-of-distribution”(即不在训练集中的样本)的语音录音进行转录。
关于数据集的详细信息可以在数据集的论文中找到:https://arxiv.org/abs/2305.09688
评估指标
提交的结果将通过计算平均词错误率来进行评估,具体步骤如下:
首先,计算测试集中每个实例的词错误率(Word Error Rate,简称WER)。 接着,在每个领域内对词错误率进行平均,使用句子中的词数进行加权。 最后,计算各个领域平均值的无权平均值,作为最终得分。
词错误率是衡量语音识别性能的重要指标,它表示系统识别结果与参考文本之间的差异程度。比赛中使用这个指标来衡量参赛者的语音识别模型在测试集上的表现。在计算词错误率时,参考文本是测试集中的真实标签,系统识别结果是模型预测的文本。
赛题时间轴
2023年10月10日 - 参赛截止日期。 2023年10月10日 - 团队合并截止日期。 2023年10月17日 - 最终提交截止日期。
赛题数据集
**train/**:训练集,包含数千个MP3格式的录音文件。 **test/**:测试集,包含来自18个不同领域的自发语音录音,其中17个领域与训练集不同。私有测试集中可能还包含公共测试集中不存在的领域。 **examples/**:每个测试集领域的示例录音。这些示例录音可能有助于构建对领域变化具有鲁棒性的模型。这些示例录音是代表性的,且不会出现在测试集中。 train.csv:训练集的句子标签。 id
:每个实例的唯一标识符。对应于**train/**目录中的文件{id}.mp3
。sentence
:录音的纯文本转录。你的目标是为测试集中的每个录音预测这些句子。split
:标识该实例属于train
还是valid
。valid
中的注释已经进行了人工审核和纠正,因此比train
中的注释质量更高,但两者都属于相同的分布。sample_submission.csv:一个样本提交文件,格式正确。详情请参阅Evaluation页面。
优胜方案
第1名
https://www.kaggle.com/competitions/bengaliai-speech/discussion/447961
STT 模型:
STT模型采用的是OpenAI Whisper-medium。 使用Huggingface训练器来进行模型的训练。 模型在8块48GB的RTX A6000上进行了训练。 训练过程中,batch size(bs)设置为8,学习率(lr)为1e-5,总训练步数为50,000。 数据增强方面采用了声谱图抖动(Spectrogram dithering)以及声谱图的时间和频率掩蔽(Spectrogram time and frequency masking)。 为了进行数据增强,对音频进行了重新采样,从16kHz到8kHz再到16kHz。 推理(Inference)过程中,使用了max_length=260,num_beams=4以及chunk_length_s=20.1秒。 采用Libsonic进行基于速度和音高的数据增强。 使用的数据集包括OpenSLR 37、OpenSLR 53、MadASR、Shrutilipi、Macro、Kathbath,还有通过GoogleTTS生成的音频以及伪标记的YouTube视频。
标点模型:
标点模型采用AutoModelForTokenClassification,使用的是google/muril-base-cased。 同样使用Huggingface训练器进行训练。 标点模型的任务是对文本进行标点(period、comma和question mark)。 batch size(bs)设置为64,学习率(lr)为2e-4,最大序列长度(max_seq_length)为512。 采用了4个模型的集成,这4个模型使用google/muril-base-cased的6、8、11和12层。 使用了IndicCorp v2的孟加拉语数据集进行训练。
第一名在日常工作中从事对资源有限的中亚语言进行语音识别的工作。根据经验,OpenAI Whisper非常适用于处理非官方数据(OOD audios),甚至能够转录歌词。但它对标注噪声非常敏感,所以竞赛的核心在于解决标注噪声的问题。
由于竞赛数据集没有经过验证,初始模型是在OpenSLR数据集上进行训练的。对文本进行了规范化,并过滤掉包含孟加拉数字的文本,并且去掉了所有标点符号。此外,从IndicCorp中抽样了42万个文本,然后使用GoogleTTS合成了音频,这些音频用于训练。
在对OpenSLR和GoogleTTS上的初始Whisper-medium模型进行训练后,进行了对MadASR、Shrutilipi、Macro和Kathbath的推理。在下一个训练阶段中,包含了WER小于15%的音频。经过三轮的训练,该模型在Macro验证数据集上达到了8%的WER,并在公共排行榜上获得了约0.380的分数。
由于大部分训练集中的音频都比较短,一些短音频被合并以创建大约7万个较长的音频。随后,公共排行榜上的分数提高到约0.370。
原始标点模型在孟加拉语音频上运行速度较慢。因此,他们训练了一个具有12k词汇的孟加拉语文本的Whisper标记生成器。使用这个标记生成器,他们能够在不到7小时内进行推理,使用了最多8个num_beam和20.1秒的chunk_length_s。
接下来,他们对一些YouTube视频应用了伪标记,使他们能够在公共排行榜上获得约0.360的分数。当他们结合了四个标点模型的预测时,公共排行榜上的分数提高到了约0.325。
第2名
https://www.kaggle.com/competitions/bengaliai-speech/discussion/447957 https://github.com/espritmirai/bengali-punctuation-model
这个解决方案包括三个主要组成部分:
1. ASR 模型
使用了预训练模型 ai4bharat/indicwav2vec_v1_bengali
。
数据集:
语音数据:竞赛数据、Shrutilipi、MADASR、ULCA(对于ULCA数据,大部分链接已失效,但仍然可以下载一些样本,尽管数量较少)。 噪声数据:来自MUSAN的音乐数据和来自DNS Challenge 2020的噪声数据。 所有数据都经过标准化处理,标点符号已被移除,但点号( .
)和连字符(-
)除外。
数据增强:
使用 audiomentations
进行数据增强,对于阅读语音(竞赛数据、MADASR)应用强烈的增强,对于自发语音(Shrutilipi、ULCA)应用较轻的增强。例如,对于阅读语音的增强:
augments = Compose([
TimeStretch(min_rate=0.8, max_rate=2.0, p=0.5, leave_length_unchanged=False),
RoomSimulator(p=0.3),
OneOf([
AddBackgroundNoise(
sounds_path=[
'/path_to_DNS_Challenge_noise',
],
min_snr_in_db=5.0,
max_snr_in_db=30.0,
noise_transform=PolarityInversion(),
p=1.0
),
AddBackgroundNoise(
sounds_path=[
'/path_to_MUSAN_music'
],
min_snr_in_db=5.0,
max_snr_in_db=30.0,
noise_transform=PolarityInversion(),
p=1.0
),
AddGaussianNoise(min_amplitude=0.005, max_amplitude=0.015, p=1.0),
], p=0.7),
Gain(min_gain_in_db=-6, max_gain_in_db=6, p=0.2),
])
对于自发语音,增强的概率较小,TimeStretch
的幅度也较小。
随机连接增强:随机将短样本连接在一起,使训练集的长度分布更接近OOD测试集。 SpecAugment: mask_time_prob = 0.1
,mask_feature_prob = 0.05
。
训练:
首先在所有训练数据上拟合,然后从训练集中删除WER最高的约10%。 不冻结特征编码器。 使用余弦学习率调度与热身和重启:第一周期5个周期,峰值学习率4e-5,第二周期3个周期,峰值学习率3e-5,第三周期3个周期,峰值学习率2e-5。
推理:使用 transformers
中的 AutomaticSpeechRecognitionPipeline
进行推理,并应用了分块和步进:
text = pipe(w, chunk_length_s=14, stride_length_s=(6, 3))["text"]
2. 语言模型
使用多个外部孟加拉语语料库训练的6-gram kenlm模型,包括IndicCorp V1+V2、Bharat Parallel Corpus Collection、Samanantar、孟加拉诗歌数据集、WMT News Crawl以及来自 这里 的仇恨言论语料库。
3. 标点模型
训练令牌分类模型以添加以下标点符号集合: ।,?!
。使用 ai4bharat/IndicBERTv2-MLM-Sam-TLM
作为基础模型。添加LSTM头部。 在竞赛数据和IndicCorp子集上训练6个周期,使用余弦学习率调度,学习率为3e-5。 在训练时,对15%的标记进行蒙版操作作为数据增强。 集成了3个模型的3个不同子集的三重折叠模型。 用于推理的是梁搜索解码(beam search decoding)。
模型架构:
CTC:使用了 "ai4bharat/indicwav2vec_v1_bengali" 模型,对竞赛数据(CD)进行了微调。首先,使用仅针对 split=”valid” CD 进行微调的模型进行预测,然后在 split=”train” CD 上微调。此外,还将高质量的 split=’train’ CD(WER<0.75)合并到 split=’valid’ CD 中,并从头开始微调 "ai4bharat/indicwav2vec_v1_bengali" 模型,将公共基线提高至 LB=0.405。
kenlm:由于OOD数据中有很多词汇外的词汇,因此认为使用大量外部文本数据进行强大的语言模型(LM)训练是重要的。下载了ASR数据集的文本数据和脚本(CD, indicCorp v2, common voice, fleurs, openslr, openslr37, and oscar),并训练了5-gram LM。与 "arijitx/wav2vec2-xls-r-300m-bengali" 相比,这个LM将LB分数提高了约0.01。
数据:
音频数据:仅使用了CD。在“模型架构”部分提到,进行了类似对抗验证的操作,使用 split=’valid’ 训练的CTC模型,并使用了大约70%的CD。
文本数据:使用了ASR数据集的文本数据和脚本(CD, indicCorp v2, common voice, fleurs, openslr, openslr37, and oscar)。在预处理中,使用了bnUnicodeNormalizer对文本进行规范化,并删除了一些特殊字符('[,?.!-;:"\।\—]')。
推理:
按音频长度排序数据:在音频的末尾进行填充会对CTC产生负面影响,因此数据根据音频长度进行排序,并对每个批次进行动态填充。这提高了预测速度和性能。
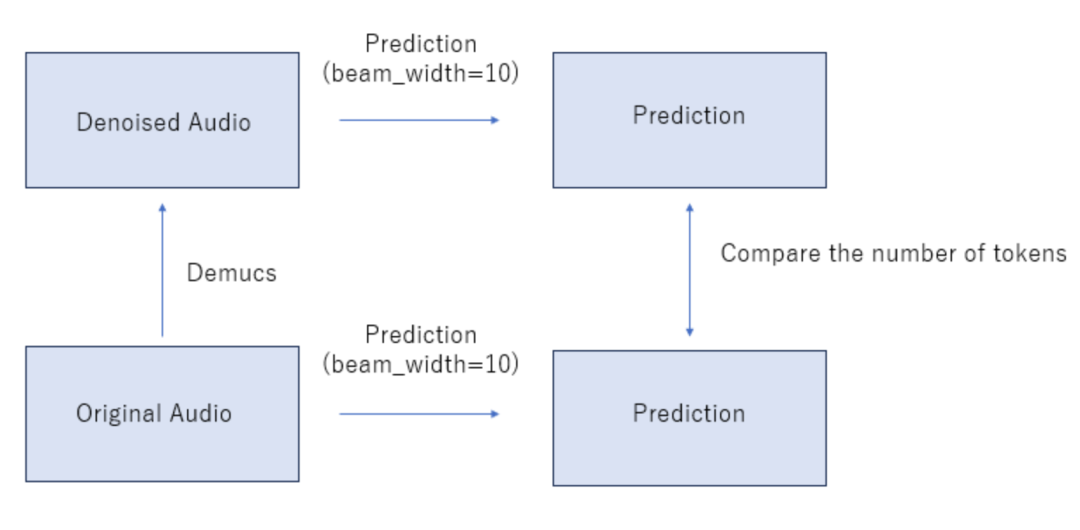
使用Demucs进行降噪:利用Demucs对音频进行降噪。这将LB分数提高了约0.003。
判断是否使用Demucs:由于Demucs有时会使音频质量下降,因此评估音频质量,然后切换用于预测的音频。这将LB分数提高了约0.001。判断过程如下:
进行两次预测:使用Demucs和不使用Demucs进行预测。为了加快这一过程,设置LM参数的beam_width=10。 比较两次预测中的标记数。如果使用Demucs的预测中的标记数少于另一次预测,那么不使用Demucs。否则使用Demucs。
后处理:
标点模型:构建了可以预测单词之间的标点符号的模型。这些模型将LB提高了0.030以上。对于训练的技巧,通过将“PAD”的损失权重设置为0.0,可以更好地改善CV分数。使用的基础模型为xlm-roberta-large和xlm-roberta-base,训练器为XLMRobertaForTokenClassification,数据集为train.csv和indicCorp v2。标点符号包括[ ,।?-]。
第3名
https://www.kaggle.com/code/takuji/3rd-place-solution
1. CTC 模型
使用 "ai4bharat/indicwav2vec_v1_bengali" 作为预训练模型。 对竞赛数据(CD)进行微调。首先,只使用“valid” CD进行微调以改善模型性能,然后使用该模型对“train” CD进行预测。接下来,将高质量的“train” CD(WER<0.75)包含到“valid” CD中,从头开始微调 "ai4bharat/indicwav2vec_v1_bengali"。 这些步骤将公共基线提高到 LB=0.405。
2. KenLM 语言模型
由于OOD数据中存在许多不在词汇表中的词汇,因此认为使用大量外部文本数据进行强大的语言模型(LM)训练很重要。下载了ASR数据集的文本数据和脚本(CD、indicCorp v2、common voice、fleurs、openslr、openslr37和oscar)并训练了一个5-gram语言模型。 与 "arijitx/wav2vec2-xls-r-300m-bengali" 相比,这个LM将 LB 得分提高了约0.01。
3. 数据
音频数据:只使用了 CD。在“模型架构”部分提到,使用了类似对抗验证的方法,使用了在“valid” CD上训练的CTC模型,约占所有CD的70%。
文本数据:使用了ASR数据集的文本数据和脚本(CD、indicCorp v2、common voice、fleurs、openslr、openslr37和oscar)。在预处理过程中,使用 bnUnicodeNormalizer 对文本进行了规范化,并删除了一些字符('[\,\?.!-\;:\\"।\—]')。
4. 推理
根据音频长度对数据进行排序:在音频末尾填充会对CTC产生负面影响,因此对数据进行了基于音频长度的排序,并动态对每个批次进行了填充。这提高了预测速度和性能。
使用 Demucs 进行降噪:使用 Demucs 进行音频降噪,这提高了 LB 得分约0.003。
判断是否使用 Demucs:由于 Demucs 有时会使音频质量下降,因此进行了评估,判断音频是否变差,并在预测中切换使用的音频。这将 LB 得分提高约0.001。
过程如下: 进行两次预测:一次使用 Demucs 进行预测,一次不使用 Demucs 进行预测。为了加速预测,设置 LM 参数的 beam_width=10。 比较两次预测中的标记数量。如果使用 Demucs 进行预测的标记数量较少,那么就不使用 Demucs 进行预测。否则,使用 Demucs 进行预测。
5. 后处理
标点模型:构建了可以预测用于单词之间的标点的模型。这将 LB 得分提高了超过0.030。
提示:在训练中,通过将“PAD”的损失权重设置为0.0,可以改善CV得分。
基础模型:xlm-roberta-large、xlm-roberta-base
训练器:XLMRobertaForTokenClassification
数据集:train.csv(提供)、indicCorp v2
标点符号:[ ,।?-]
第4名
https://www.kaggle.com/competitions/bengaliai-speech/discussion/447995
1. ASR 模型
使用
facebook/wav2vec2-xls-r-1b
作为预训练模型。模型训练分为三个阶段,每个阶段使用不同的随机种子,并保持每个阶段中的数据增强和参数一致。
优化器:AdamW(weight_decay: 0.05;betas: (0.9, 0.999))
调度器:Modified linear_warmup_cosine scheduler(init_lr: 1e-5;min_lr: 5e-6;warmup_start_lr: 1e-6;warmup_steps: 1000;max_epoch: 120;iters_per_epoch: 1000)
基础数据增强(称为
base_aug
):TimeStretch:时间拉伸(min_rate=0.9,max_rate=1.1,p=0.2,leave_length_unchanged=False) Gain:音量增益(min_gain_in_db=-6,max_gain_in_db=6,p=0.1) PitchShift:音高变化(min_semitones=-4,max_semitones=4,p=0.2) AddBackgroundNoise:添加背景噪声,可选使用Musane音乐或DNS Challenge噪声数据(min_snr_in_db=3.0,max_snr_in_db=30.0,noise_transform=PolarityInversion(),p=1.0) AddGaussianNoise:添加高斯噪声(min_amplitude=0.005,max_amplitude=0.015,p=1.0) 复合数据增强(称为
comp_aug
):使用三种复合数据增强方法,包括将音频波形均匀分为3个段落并对每个段落进行base_aug
,随机选择两个语音样本并分别对它们进行base_aug
,然后将它们连接在一起,以及组合上述两种数据增强方法。数据集:在Wav2Vec2ForCTC训练中,没有使用外部数据,而是对竞赛数据集进行了筛选,步骤如下:
使用 arijitx/wav2vec2-xls-r-300m-bengali 模型进行训练。 使用上述模型对整个数据集进行推理,对所有样本的分数进行排序,保留得分最高的70%的数据。
2. KenLM 语言模型训练
数据集:使用IndicCorpv1和IndicCorpv2作为语料库。清理后,将这两个语料库合并,去除重复。 语料库清理:对语料库中的每个句子进行清理,去除标点和多余的空格。 训练6-gram语言模型。
3. 已尝试但不起作用的方法
使用外部数据,如openslr、shrutilipi。 使用DeepFilterNet对音频进行降噪。 使用更大的模型(wav2vec2-xls-r-2b)。 使用Whisper-small。 使用更多的语料库训练语言模型(BanglaLM)。 训练拼写错误校正模型。 训练第四阶段模型。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

