




一、关系型数据库MVCC实现对比
多版本并发控制(MVCC),这个特性就是为了提高数据库并发而设计的,但是不同的数据库实现MVCC的使用了不同的方法:
1、Oracle、MySQL
这两种数据库是通过undo日志来实现MVCC。
1.1 Oracle
Oracle的多版本并发控制是基于块级的,利用Oracle UNDO/回滚段机制。在回滚段中保存了某个数据被修改之前的前映像的数据。
在数据中查询之前版本的数据时,Oracle是这样做的:首先查询的过程会在undo段中查找该数据块的前映像后,然后把前映像和current块合并形成了一个CR block,通过查询CR block就可以满足数据的一致性了。
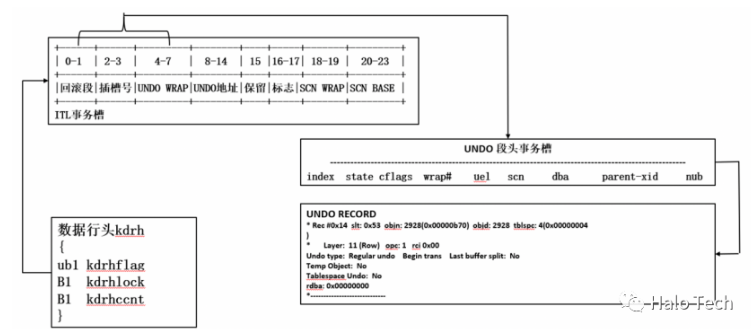
正因为数据的前映像通过在DB BUFFER中的CR BLOCK来实现,所以数据无论修改多少次,都不会对存储数据的数据段产生负面的影响。而且一个CR BLOCK生成后,可以在缓冲区中较长时间内存在,供相关的事务使用。这个功能对于大并发的读操作来说,是十分有用的,可以大大提高相关操作的性能。
1.2 MySQL
MySQL InnoDB引擎的MVCC也是通过undo段来实现的,但是和Oracle不同的是:MySQL的多版本并发控制是基于记录级的,MySQL中通过undo来形成行的版本链。
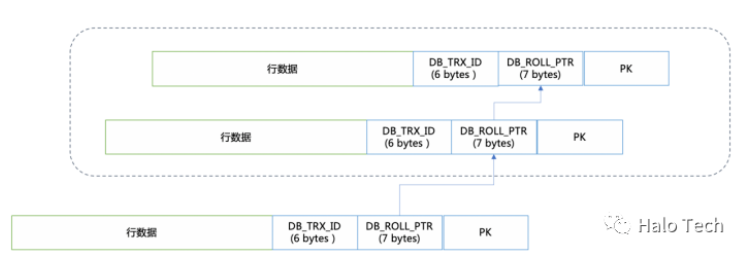
当数据记录被DML修改,将修改前的数据记录在undo log中,客户端可以读取数据时,通过undo log指针进行回滚找到对应可见的版本。
长事务、大事务会导致undo log暴涨,一定程度上会导致系统日志文件磁盘空间占用的暴涨。只有将事务提交/回滚,相关版本记录不再需要时,对应的版本数据才会被清理,undo系统文件空间才会把无效的版本空间进行释放,具体空间释放操作需要看数据库版本以及参数设置。
2、PostgreSQL
它是通过保留变更前的记录来实现MVCC的。
PostgreSQL中没有undo这一概念,PostgreSQL中的多版本并发是通过在表中数据行的多个版本来实现的,在一张表中我们要更新一条记录,PostgreSQL并不是直接修改该数据,而是通过插入一条全新的数据,同时对老数据加以标识。
当数据记录被DML修改,旧版本记录仍保留不变,仅仅需要修改相关记录的xmin、xmax属性,并新增写入变更后的版本记录数据。
由于历史版本数据仍然保留在原表空间中,默认情况下autovacuum会按照一定的参数设置策略检测并进行一定的清理,但频繁的数据变极大可能导致旧版本数据空间来不及进行空间回收,从而导致表空间膨胀。
3、SQL Server
它是通过tempdb数据库来实现的。
当数据记录被DML修改,将旧版本数据写入tempdb进行存储,客户端读取数据时,可从通过指针找到tempdb数据库中对应可见的版本。
长事务、大事务会导致tempdb空间暴涨,只有事务提交,相关版本记录不再需要时,才会将相关的版本记录进行释放,需要注意的是这部分磁盘空间消耗是没有释放给操作系统的,需要手动进行磁盘空间收缩。
二、各MVCC实现方法的优缺点对比
通过undo log或者tempdb来进行旧版本存储的方式,有效的避免了表空间膨胀,相对于PG直接保留旧版本数据的方式,每次DML操作都需要额外的日志写入,存在一定的IO消耗(目前SSD盘存储下,感觉影响不会很大);
PG这种直接保留旧版本数据的方式,无需额外的日志写入的消耗,但是一定程度上会导致旧版本数据没有及时清理,导致表空间膨胀,影响该表数据的查询效率(扫描了不必要的数据页)
