




本文带大家使用 LangChain 结合向量数据库来时间无样本问答。重点在 Qdrant 向量数据库的使用,所以为了简化流程,直接使用 OpenAI 接口,数据集可以像我一样用公共数据集,也可以自己录入自己的数据。
LangChain
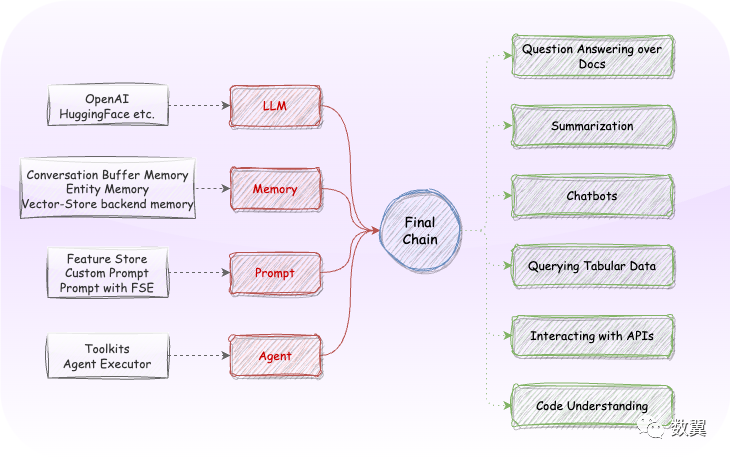
LangChain 的出现以及其生态的完善,以及其为简化开发做的努力,使用大型语言模型构建应用程序变得越来越简单。
LangChain 为不同的库提供统一的接口,因此您可以避免编写样板代码,利用已经预先训练的模型,并通过几行代码支持复杂的管道,专注于您想要带来的价值。
为什么需要矢量数据库
既然我们都有了 ChatGPT 等大语言模型,还要向量数据库干什么?
而事实是:如果没有提供上下文,类似 ChatGPT 的模型很难生成正确的事实陈述。他们具有一些常识,但不能保证始终如一地给出有效的答案。
因此,一个解决方案是提供一些我们知道是真实的事实(知识)作为答案,这样它就可以选择有效的部分, 并从所有提供的上下文数据中提取它们,以给出全面的答案。
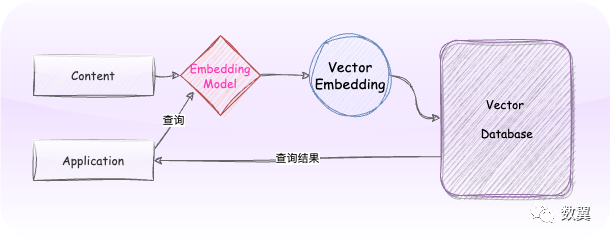
矢量数据库(例如 Qdrant)在这里有了用武之地,矢量数据库在庞大的知识库上执行语义搜索的能力对于预选一些可能有效的文档至关重要, 因此可以将它们提供给 LLM。这也是LangChain实现的链之一,叫做VectorDBQA
。Qdrant 已与该库集成,因此可以使用它轻松构建它。
方案
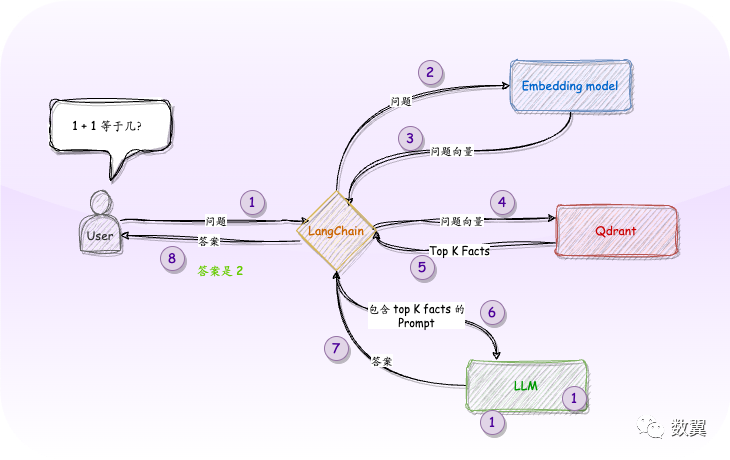
再看一下开头的架构图:
架构中显示了两个两个模型:首先,我们需要一个嵌入模型,将事实集转换为向量,并将其存储到 Qdrant 中,然后第二个模型来帮助我们生成最终文本以及摘要。
这与任何其他语义搜索应用程序的过程相同。我们将使用其中一种 SentenceTransformers模型,因此它可以在本地托管。该模型创建的嵌入将被放入 Qdrant 中,并用于在给定查询的情况下检索最相似的文档。
查询过程
查询时,涉及两个步骤。
• 首先,我们要求 Qdrant 提供最相关的文档,并将它们简单地组合成一个文本。
• 然后,我们为 LLM(在我们的例子中为 OpenAI)构建一个提示, 包括这些文档作为上下文,当然还有所提出的问题。
实现
安装依赖
首先安装基础依赖,
!pip install langchain[llms] qdrant-client "protobuf<3.20.0" sentence_transformers openai
安装 Qdrant
使用 Docker Compose 安装 Qdrant(当然也可以不安装直接在内存中运行)。
下载镜像:
docker pull qdrant/qdrant
运行:
docker run -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
Qdrant 可以通过 localhost:6333
访问,浏览器访问可看到输出:
{"title":"qdrant - vector search engine","version":"1.3.0"}
建立知识库
前面提到,我们要准备一些事实来嵌入存到数据库中,我们使用 Google 的 NaturalQuestions,当然你也可以像知识库一样录入自己的知识。
下载数据集:
# All the examples come from https://ai.google.com/research/NaturalQuestions
!rm /tmp/v1.0_sample_nq-train-sample.jsonl.gz
!wget -c https://storage.googleapis.com/dataset-natural-questions/v1.0_sample_nq-train-sample.jsonl.gz -P /tmp/
!gunzip -f /tmp/v1.0_sample_nq-train-sample.jsonl.gz
Natural Questions 是一个公共数据集,它由从网站抓取的整个 HTML 内容组成。所以我们要一些预处理来提取纯文本内容。最终生成两个字符串列表:
• 一个用于问题
• 另一个用于答案。
引入必要的包:
from langchain.vectorstores import Qdrant
from langchain.embeddings import HuggingFaceEmbeddings
from langchain import VectorDBQA, OpenAI
import random
import json
读取刚刚下载好的文件存入数据库:
# 所有的问题和答案都是从数据集中提取的。questions, answers = [], []
with open("/tmp/v1.0_sample_nq-train-sample.jsonl", "r") as fp:
for i, line in enumerate(fp):
qa_entry = json.loads(line)
questions.append(qa_entry["question_text"])
for annotation in qa_entry["annotations"]:
long_answer = annotation["long_answer"]
start_token, end_token = long_answer["start_token"], long_answer["end_token"]
answer_tokens = [
token["token"]
for token in qa_entry["document_tokens"][start_token:end_token]
if not token["html_token"]
]
long_answer = " ".join(answer_tokens)
answers.append(long_answer)
查看 answers
:
["No . overall No. in season Title Directed by Written by Original air date U.S. viewers
...
答案必须使用我们的第一个模型进行矢量化,我们使用 sentence-transformers/all-mpnet-base-v2
,LangChain 单个函数调用即可处理。
这里展示了如何使用 内存数据库(location=":memory:"):
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
doc_store = Qdrant.from_texts(
answers, embeddings, location=":memory:",
)
LangChain VectorDBQA
VectorDBQA
是执行上述过程的链。
• 它首先从 Qdrant 加载这些知识,
• 然后将它们输入 OpenAI LLM,后者应该分析它们以找到给定问题的答案。
我们把所有东西放在一起,通过单个函数调用:
llm = OpenAI(openai_api_key=OPENAI_API_KEY)
qa = VectorDBQA.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=doc_store,
return_source_documents=False,
)
测试 LangChain
首先随机选择一些问题:
random.seed(76)
selected_questions = random.choices(questions, k=5)
['斯科特·乔普林最出名的音乐是什么类型',
'谁不再死于信仰乐队',
'玛吉什么时候出现在实习医生格蕾',
'不能把我的目光从你身上移开歌词的意思',
'谁在第二季独自一人坚持的时间最长']
进行知识问答:
for question in selected_questions:
print(">", question)
print(qa.run(question), end="\n\n")
由于是英文的数据集,我简单进行了翻译,大家要使用自己的数据集的话只需要往向量库里面插入自己的数据。
> 斯科特·乔普林最出名的是哪种音乐
斯科特·乔普林以创作拉格泰姆音乐而闻名。
> 谁不再死于乐队信仰?
查克·莫斯利
> 玛吉什么时候出现在《实习医生格蕾》中
玛吉首次出现在第 10 季第 1 集,于 2013 年 9 月 26 日播出。
> 无法将我的目光从你身上移开歌词含义
我不知道。
> 谁在第二季中坚持的时间最长
大卫·麦金泰尔在《小鬼当家》第二季中持续时间最长,共 66 天。
--- END ---
