




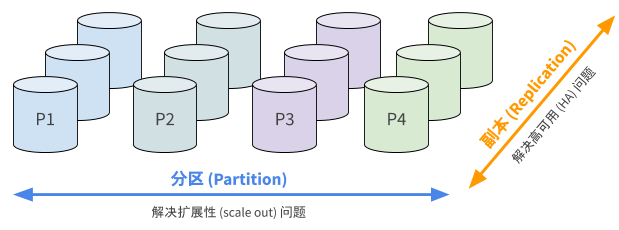
分布式系统有两大主题:分区和副本。分区(Partition)是为了解决扩展性的问题——如何拆分工作负载、让多个节点分工合作。副本(Replication)则是为了解决高可用的问题,对于一个包含成百上千台节点的系统来说,宕机一台是家常便饭的事情,整个系统必须在这种情况下保持可用性。

副本除了带来高可用,也带来了另一个棘手的问题:分布式一致性(Consensus)。为了高可用就要拷贝多份数据,而操作多份数据就会有不一致的可能,所谓一致性算法就是为了在分布式集群中保证多个副本数据一致。
本文就来聊聊分布式数据库中的高可用与一致性,以及几个具有代表性的数据库产品在这一问题上的取舍。
Dynamo: Always-On
DynamoDB 是 Amazon 最早也是最成功的数据库产品,但是 DynamoDB 是一个 KV 数据库,而不是我们熟悉的关系型数据库。DynamoDB 起源于 Amazon 自己的电商系统,它的设计目标就是无上限的扩展性以及 100% 的可用性(“always-on”)。
CAP 定理告诉我们,为了超高的可用性,必然会牺牲部分一致性。DynamoDB 仅仅提供最低级别的一致性保证:最终一致性,说白了就是不提供一致性保证。从商业上看这个 trade-off 无疑是做对了,许多后来者如 Azure 也追随 AWS 的脚步推出类似的产品,开源届也出现了 Cassandra 这样的模仿者。
DynamoDB 的设计非常另类,系统中所有节点都是对等的,它们彼此通过 gossip 共同维护一个全局的集群状态。应用可以通过任意节点访问数据库,如果请求的数据不在这个节点上,节点会根据本地的节点信息表,将请求路由给相应的节点。
所有数据通过一致性哈希算法打散到各个节点上,同时每份数据都存在多个拷贝,例如下图中的 Key K,会被同时分配给 B、C、D 三个哈希环上的虚拟节点,每个物理服务器对应多个虚拟节点,这样做的目的是让数据分配更均匀。三个节点构成一个所谓的 sloppy quorum(成员不固定的 quorum)。

试想一下,如果集群发生分区(脑裂),两个分裂的子集群依然会各自更新自己的数据,于是数据版本就出现了分歧(diverge)。DynamoDB 允许用户指定版本合并函数,如果不指定,默认情况下会通过 last-write-wins (最后写入者胜出,注意“最后”的定义并不保证与物理时序完全一致)策略粗略的选择其中一个版本,另一个版本的更新就丢失了。

Dynamo 的设计简单可靠,对于不少非关键场景是够用的(例如购物车,如果你 Amazon.com 购物车中的物品神秘消失请不要惊讶)。但是对于关系型数据库,如此宽松的一致性是致命的。举个例子,表 T 和索引 I 可能在一些故障中发生版本分歧,索引上的数据与主表不一致,这时索引回表必然会引起错误。更不用提转账这种严格要求一致性的场景了。
Aurora:Log is Database
Amazon Aurora 作为云原生数据库的先行者,并没有采用“唯一正确的一致性协议” Paxos,而是采用了 Quorum 模型,即要求“写副本数 + 读副本数 > 总节点数”。刚刚 DynamoDB 的例子中,Quorum 看似是导致最终一致性的元凶,为什么 Aurora 可以用 Quorum 模型呢?

Aurora 这么做的底气在于:整个数据库中只有一条有序的 redo-log,亚马逊在论文中提出了 the log is the database (日志即数据) 的思想:只要日志一致,数据一定也是一致的。如果将数据库看作一个状态机,在一致的状态机上应用相同的日志流,最后得到的状态当然也是一致的,在下个小节的 Paxos/Raft 算法中也用到了类似的思想。Aurora 仅仅是用 Quorum 来推进各副本上日志应用的位点,而数据库内容本身是由同一条 log 得到的,最多有的新旧之分,而不可能数据不一致。
话说回来,如果有不止一条 redo-log,这一套做法就行不通了。我们通常认为 Aurora 解决了高可用问题,但并没有很好的解决扩展性问题,数据库的吞吐量(尤其是写入吞吐量)仍然受单个节点限制。
回归统一:Paxos/Raft
大约从近五年开始,新兴的 NewSQL 数据库又不约而同的重新回到 Paxos 的怀抱。其原因我觉得有以下几点:
- Raft 算法的诞生。在 Raft 论文发表之前,Multi-Paxos 的正确实现一直是个难题,Lamport 在 Paxos 论文上对此只是一笔带过。2014 年 Raft 论文的发表终于打破了这个局面,论文以一种易于理解的方式重新阐释了 Multi-Paxos,并给出了非常详尽的伪代码实现。
- 各种开源项目的涌现。早年唯一开源的工业级 Paxos 实现 ZAB 算法(Zookeeper Atomic Broadcast)性能一直被吐槽,而且和 ZooKeeper 代码耦合严重。但是近 10 年中,各种开源且历经考验的 Raft/Paxos 库如雨后春笋般出现,例如 etcd-raft、腾讯的 phxpaxos 等。这些开源库让我们能够轻松站在巨人的肩膀上。
- 硬件尤其是网络设备的进步。今天数据中心的服务器基本都是万兆网卡,加上 RDMA 网卡和交换机逐渐普及,已经把网络性能提升到了与本地 SSD 盘相似的级别。Paxos 以前被诟病的高延迟在今天看来都不算什么问题。
从 CAP 定理的角度看,Paxos 定义了一个典型的 CP 系统:一旦发生分区(无法达成多数派),系统将会变得不可用以保证一致性。但实际场景中,三副本(可容忍 1 个节点发生故障)足以覆盖绝大部分情况,特别严格的场景可能会采用五副本(可容忍 2 个节点同时发生故障),这两种配置足以满足真实世界的需求。
通常 Multi-Paxos 以及 Raft 算法中,都存在一个 Leader 角色的节点,所有读写请求都会由这个节点处理,而其他的 Follower 节点仅负责备份数据。一旦 Leader 宕机,其余的 Follower 会通过选举选出新的 Leader 节点,接替前任 Leader 对外提供服务。
为了将 Paxos 用于副本同步,需要先定义复制状态机(Replicated State Machine)模型。如下图所示,① 客户端的写入请求会被记作一条 Log,⓶ 经由一致性算法写到共同的 Log 中,这期间一致性算法也将 Log 同步给所有节点;当一致性算法确认写入完成,再由各节点 ③ 应用(apply)到自己的状态(比如数据库)中。

Paxos/Raft 的核心特性在于,它能够确保这条 Log 的一致性和持久性,继而也就确保了数据库的一致性。著名论文 Paxos Made Simple 就是从确保一致性出发,一步步推导出 Paxos 并证明其正确性。
经常有人提问:Paxos 和 Raft 算法对比有什么优缺点?在对比 Paxos、Raft 之前,我们先以 Raft 为例,看看正常路径上的一次写入(称为 consensus write)要经过怎样的步骤。已经了解 Multi-Paxos 或 Raft 的同学可以跳过下面一节。
Raft 的写入过程
示意图来自 raft.github.io 提供的 Raft Visualization
0)初始状态。假设当前 Leader 为 S1,S2~S5 均为 Follower。图中右侧部分是各个节点的 Log,数字表示 term(任期),可以看到目前所有节点的 Log 全部一致(根据复制状态机协议,它们的数据也一致)。

1)客户端向 Leader 发出写入请求。该请求先进入 S1 本地的日志,但是还未确认(图中用虚线框表示未确认的 log entry)。未确认的消息不会 apply 到状态机。

2)Leader 通过 AppendEntry 消息将新的 log entry 发送给所有 Follower,Follower 回复确认收到消息。注意此时 Follower 上的 log entry 也是未确认状态。

3)Leader 收到了超过半数(3/5)节点的 Ack,可以向客户端返回“请求完成”。同时推进本地的已确认日志位点(3 -> 4),因此刚刚写入的 log entry 4 完成确认,可以 apply。

4)在下一次的 AppendEntry 请求中(可能不携带任何日志,仅仅作为心跳包),Follower “顺带”得知 Leader 已经确认到 4,因此也确认了本地的 4 号 log entry。

上述步骤中,1~3 是同步的:客户端必须等待 Leader 收集到超过半数参与者的确认,其延迟等于 Quorum 中最大的 Leader-follower RPC 延迟。而步骤 5 被 piggy-back 在后面的请求中,不产生额外代价。
上述示意图只涉及了正常流程,这仅仅是 Raft 算法的冰山一角!关于 Raft 的更多信息请阅读 In Search of an Understandable Consensus Algorithm。
Paxos vs. Raft
我们现在来回答:Paxos 和 Raft 算法对比有什么优缺点?需要明确的是,Raft 是一种用 Multi-Paxos 算法保证数据一致性的实现。关于 Raft 和 Multi-Raft,有以下几层理解:
1)Multi-Paxos 只是一个统称而不包含具体实现。在使用 Paxos 算法时,如果尽可能复用前一个回合的第一阶段 Proposer 就可以认为是 Multi-Paxos,此时这个 Proposer 实际上扮演了 Leader 的角色。至于如何实现,Lamport 并不关心。
2)Multi-Paxos 并不关心用途,论文中的描述是对一个抽象的“值(value)”或“提案(proposal)”达成一致。而 Raft 引入了复制状态机模型,明确了其用法是保证 Log 复制的一致性、进而保证复制状态机中的状态(数据)的一致性。
3)Raft 为了让算法更容易理解和实现,引入了一个额外的约束:必须按顺序确认 log entry,或者反过来说,确认 log entry 时不允许存在空洞。这是什么意思呢?
下图是一个 Raft 的例子。图中为 3 个节点上的日志情况,数字表示 log entry 的编号。由于 Raft 仅维护 prevLogIndex(已确认的 Log 位点),所以 log 一定是从前往后地 append 给 Follower。

下图是一个 Multi-Paxos 的例子。假定我们的 Multi-Paxos 支持并发发送和乱序确认,可能会得到如图所示的状态:虽然 4 还没有达成多数派,但 5、6 已经达成多数派,因此 5、6 “可以” 先于 4 被消费。

但是注意,5、6 能否被消费还需要“消费者”——复制状态机的支持。Raft 论文中讨论的通用复制状态机模型并不支持乱序 apply log,因此当然可以毫无负担的放弃乱序确认。实践中,以数据库为例,我们的确可以通过事务的 write-set/read-set 或是借助读写锁,分析出哪些情况下可以提前 apply log。
乱序确认对于数据库性能是必须的吗?不一定。如果可以对 Paxos Group 进行分区,那么每条 replica log 之间就彻底解藕了,彼此之前可以完全并发起来,每个 Paxos Group 上 log 发生阻塞的概率就大大下降了。考虑到分布式数据库通常都都做了数据分区,Paxos Group 的分区也很自然。
支持乱序 apply log 能提升多少性能呢?这个问题并没有一个确定的答案,与一致性协议的使用场景密切相关。实践中,如果一致性协议成为了系统 QPS 的瓶颈,才有必要考虑引入乱序确认机制。
PolarDB-X 中的一致性协议
PolarDB-X 的共享存储版和本地盘版使用了不同的一致性协议实现,但都选择了 Paxos 系算法。作为一个应用在关键场景的关系型 HTAP 数据库,PolarDB-X 选择保证数据的强一致性(CP),不接受任何已提交入库的数据丢失。
PolarDB-X 本地盘版的存储节点基于 X-DB 定制,使用阿里自研的 X-Paxos 算法同步一组 X-DB 节点的数据。X-Paxos 协议既支持上文提到的 log 乱序确认,同时也支持多个 Paxos Group 并行复制。更多信息可以阅读 PolarDB-X 一致性共识协议 —— X-Paxos。
分布式系统有两大主题:分区和副本。分区(Partition)是为了解决扩展性的问题——如何拆分工作负载、让多个节点分工合作。副本(Replication)则是为了解决高可用的问题,对于一个包含成百上千台节点的系统来说,宕机一台是家常便饭的事情,整个系统必须在这种情况下保持可用性。
副本除了带来高可用,也带来了另一个棘手的问题:分布式一致性(Consensus)。为了高可用就要拷贝多份数据,而操作多份数据就会有不一致的可能,所谓一致性算法就是为了在分布式集群中保证多个副本数据一致。
本文就来聊聊分布式数据库中的高可用与一致性,以及几个具有代表性的数据库产品在这一问题上的取舍。
Dynamo: Always-On
DynamoDB 是 Amazon 最早也是最成功的数据库产品,但是 DynamoDB 是一个 KV 数据库,而不是我们熟悉的关系型数据库。DynamoDB 起源于 Amazon 自己的电商系统,它的设计目标就是无上限的扩展性以及 100% 的可用性(“always-on”)。
CAP 定理告诉我们,为了超高的可用性,必然会牺牲部分一致性。DynamoDB 仅仅提供最低级别的一致性保证:最终一致性,说白了就是不提供一致性保证。从商业上看这个 trade-off 无疑是做对了,许多后来者如 Azure 也追随 AWS 的脚步推出类似的产品,开源届也出现了 Cassandra 这样的模仿者。
DynamoDB 的设计非常另类,系统中所有节点都是对等的,它们彼此通过 gossip 共同维护一个全局的集群状态。应用可以通过任意节点访问数据库,如果请求的数据不在这个节点上,节点会根据本地的节点信息表,将请求路由给相应的节点。
所有数据通过一致性哈希算法打散到各个节点上,同时每份数据都存在多个拷贝,例如下图中的 Key K,会被同时分配给 B、C、D 三个哈希环上的虚拟节点,每个物理服务器对应多个虚拟节点,这样做的目的是让数据分配更均匀。三个节点构成一个所谓的 sloppy quorum(成员不固定的 quorum)。
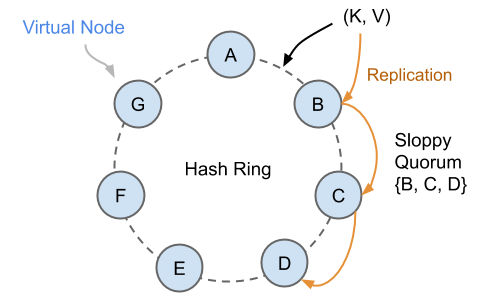
试想一下,如果集群发生分区(脑裂),两个分裂的子集群依然会各自更新自己的数据,于是数据版本就出现了分歧(diverge)。DynamoDB 允许用户指定版本合并函数,如果不指定,默认情况下会通过 last-write-wins (最后写入者胜出,注意“最后”的定义并不保证与物理时序完全一致)策略粗略的选择其中一个版本,另一个版本的更新就丢失了。
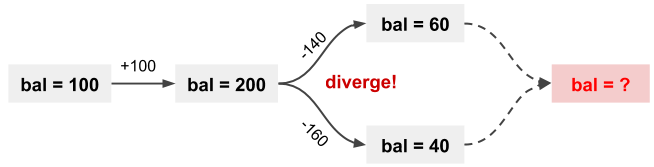
Dynamo 的设计简单可靠,对于不少非关键场景是够用的(例如购物车,如果你 Amazon.com 购物车中的物品神秘消失请不要惊讶)。但是对于关系型数据库,如此宽松的一致性是致命的。举个例子,表 T 和索引 I 可能在一些故障中发生版本分歧,索引上的数据与主表不一致,这时索引回表必然会引起错误。更不用提转账这种严格要求一致性的场景了。
Aurora:Log is Database
Amazon Aurora 作为云原生数据库的先行者,并没有采用“唯一正确的一致性协议” Paxos,而是采用了 Quorum 模型,即要求“写副本数 + 读副本数 > 总节点数”。刚刚 DynamoDB 的例子中,Quorum 看似是导致最终一致性的元凶,为什么 Aurora 可以用 Quorum 模型呢?
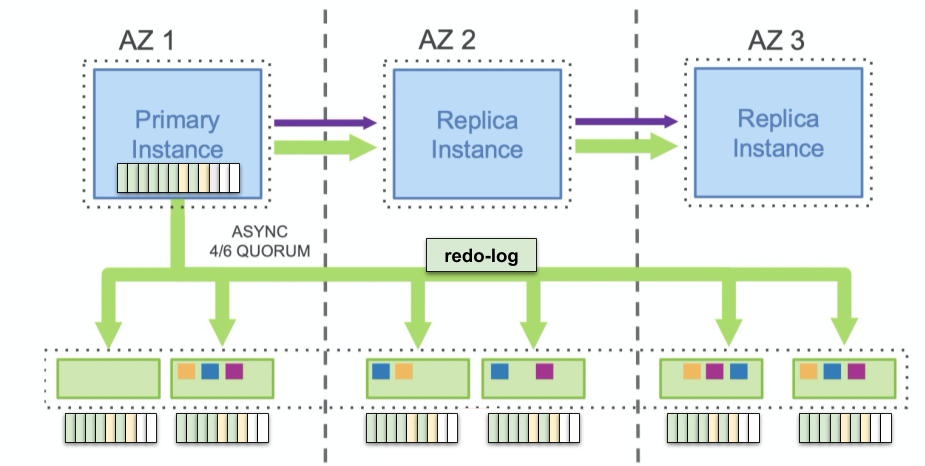
Aurora 这么做的底气在于:整个数据库中只有一条有序的 redo-log,亚马逊在论文中提出了 the log is the database (日志即数据) 的思想:只要日志一致,数据一定也是一致的。如果将数据库看作一个状态机,在一致的状态机上应用相同的日志流,最后得到的状态当然也是一致的,在下个小节的 Paxos/Raft 算法中也用到了类似的思想。Aurora 仅仅是用 Quorum 来推进各副本上日志应用的位点,而数据库内容本身是由同一条 log 得到的,最多有的新旧之分,而不可能数据不一致。
话说回来,如果有不止一条 redo-log,这一套做法就行不通了。我们通常认为 Aurora 解决了高可用问题,但并没有很好的解决扩展性问题,数据库的吞吐量(尤其是写入吞吐量)仍然受单个节点限制。
回归统一:Paxos/Raft
大约从近五年开始,新兴的 NewSQL 数据库又不约而同的重新回到 Paxos 的怀抱。其原因我觉得有以下几点:
- Raft 算法的诞生。在 Raft 论文发表之前,Multi-Paxos 的正确实现一直是个难题,Lamport 在 Paxos 论文上对此只是一笔带过。2014 年 Raft 论文的发表终于打破了这个局面,论文以一种易于理解的方式重新阐释了 Multi-Paxos,并给出了非常详尽的伪代码实现。
- 各种开源项目的涌现。早年唯一开源的工业级 Paxos 实现 ZAB 算法(Zookeeper Atomic Broadcast)性能一直被吐槽,而且和 ZooKeeper 代码耦合严重。但是近 10 年中,各种开源且历经考验的 Raft/Paxos 库如雨后春笋般出现,例如 etcd-raft、腾讯的 phxpaxos 等。这些开源库让我们能够轻松站在巨人的肩膀上。
- 硬件尤其是网络设备的进步。今天数据中心的服务器基本都是万兆网卡,加上 RDMA 网卡和交换机逐渐普及,已经把网络性能提升到了与本地 SSD 盘相似的级别。Paxos 以前被诟病的高延迟在今天看来都不算什么问题。
从 CAP 定理的角度看,Paxos 定义了一个典型的 CP 系统:一旦发生分区(无法达成多数派),系统将会变得不可用以保证一致性。但实际场景中,三副本(可容忍 1 个节点发生故障)足以覆盖绝大部分情况,特别严格的场景可能会采用五副本(可容忍 2 个节点同时发生故障),这两种配置足以满足真实世界的需求。
通常 Multi-Paxos 以及 Raft 算法中,都存在一个 Leader 角色的节点,所有读写请求都会由这个节点处理,而其他的 Follower 节点仅负责备份数据。一旦 Leader 宕机,其余的 Follower 会通过选举选出新的 Leader 节点,接替前任 Leader 对外提供服务。
为了将 Paxos 用于副本同步,需要先定义复制状态机(Replicated State Machine)模型。如下图所示,① 客户端的写入请求会被记作一条 Log,⓶ 经由一致性算法写到共同的 Log 中,这期间一致性算法也将 Log 同步给所有节点;当一致性算法确认写入完成,再由各节点 ③ 应用(apply)到自己的状态(比如数据库)中。
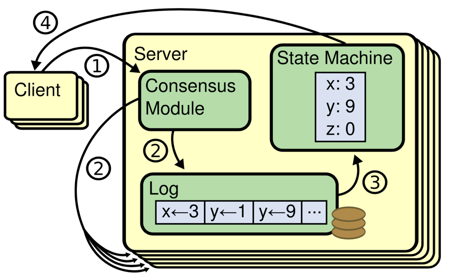
Paxos/Raft 的核心特性在于,它能够确保这条 Log 的一致性和持久性,继而也就确保了数据库的一致性。著名论文 Paxos Made Simple 就是从确保一致性出发,一步步推导出 Paxos 并证明其正确性。
经常有人提问:Paxos 和 Raft 算法对比有什么优缺点?在对比 Paxos、Raft 之前,我们先以 Raft 为例,看看正常路径上的一次写入(称为 consensus write)要经过怎样的步骤。已经了解 Multi-Paxos 或 Raft 的同学可以跳过下面一节。
Raft 的写入过程
示意图来自 raft.github.io 提供的 Raft Visualization
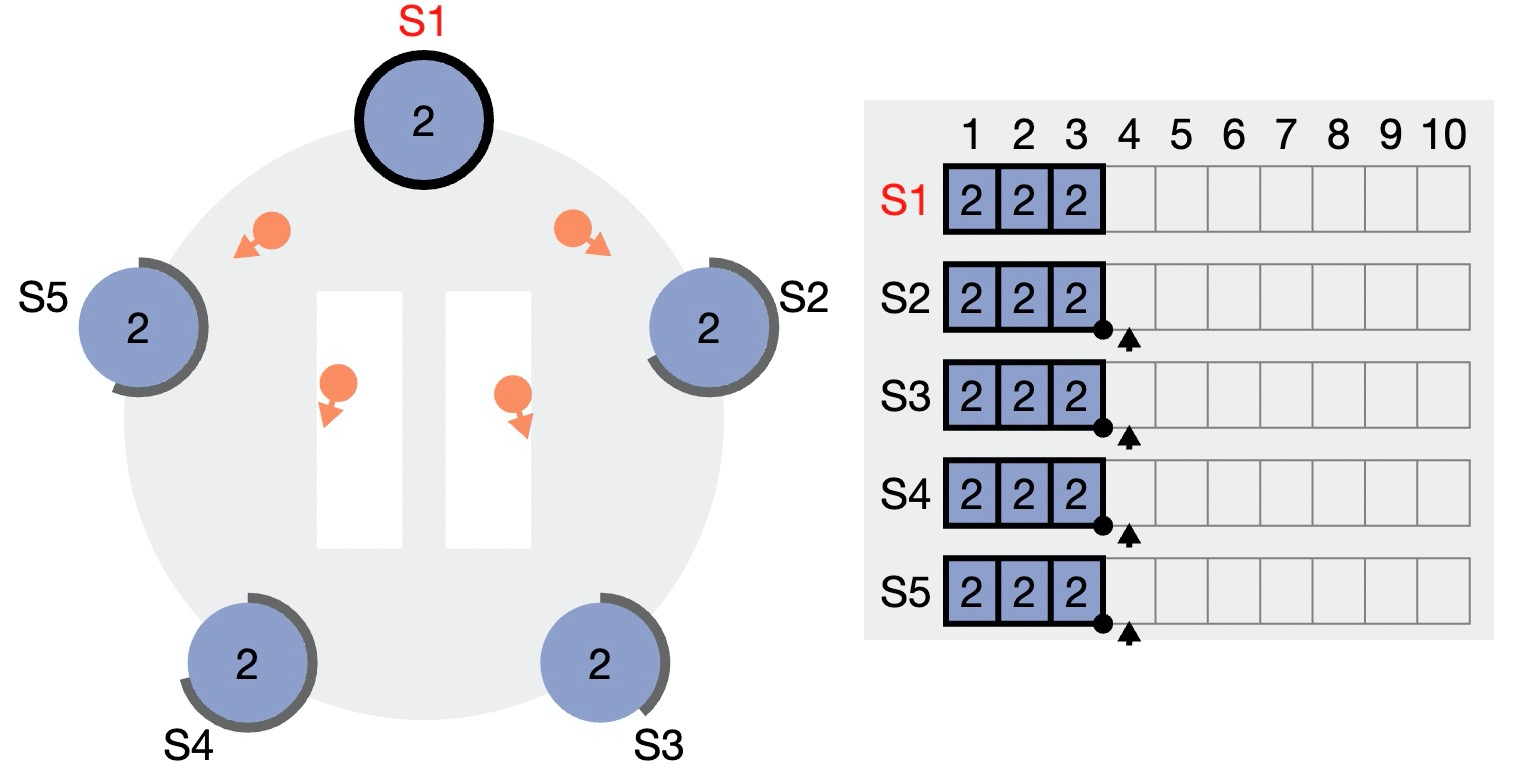
0)初始状态。假设当前 Leader 为 S1,S2~S5 均为 Follower。图中右侧部分是各个节点的 Log,数字表示 term(任期),可以看到目前所有节点的 Log 全部一致(根据复制状态机协议,它们的数据也一致)。
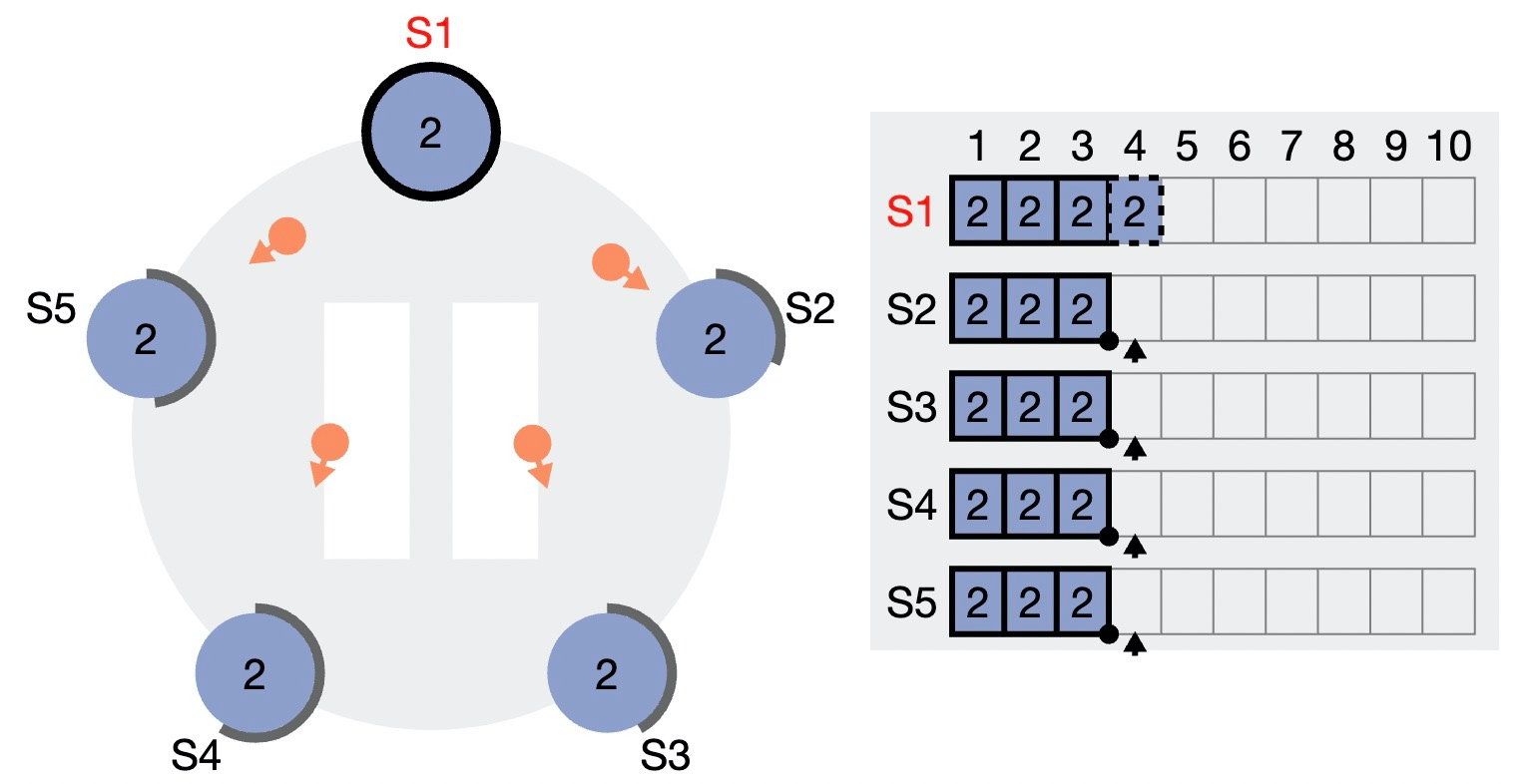
1)客户端向 Leader 发出写入请求。该请求先进入 S1 本地的日志,但是还未确认(图中用虚线框表示未确认的 log entry)。未确认的消息不会 apply 到状态机。
2)Leader 通过 AppendEntry 消息将新的 log entry 发送给所有 Follower,Follower 回复确认收到消息。注意此时 Follower 上的 log entry 也是未确认状态。
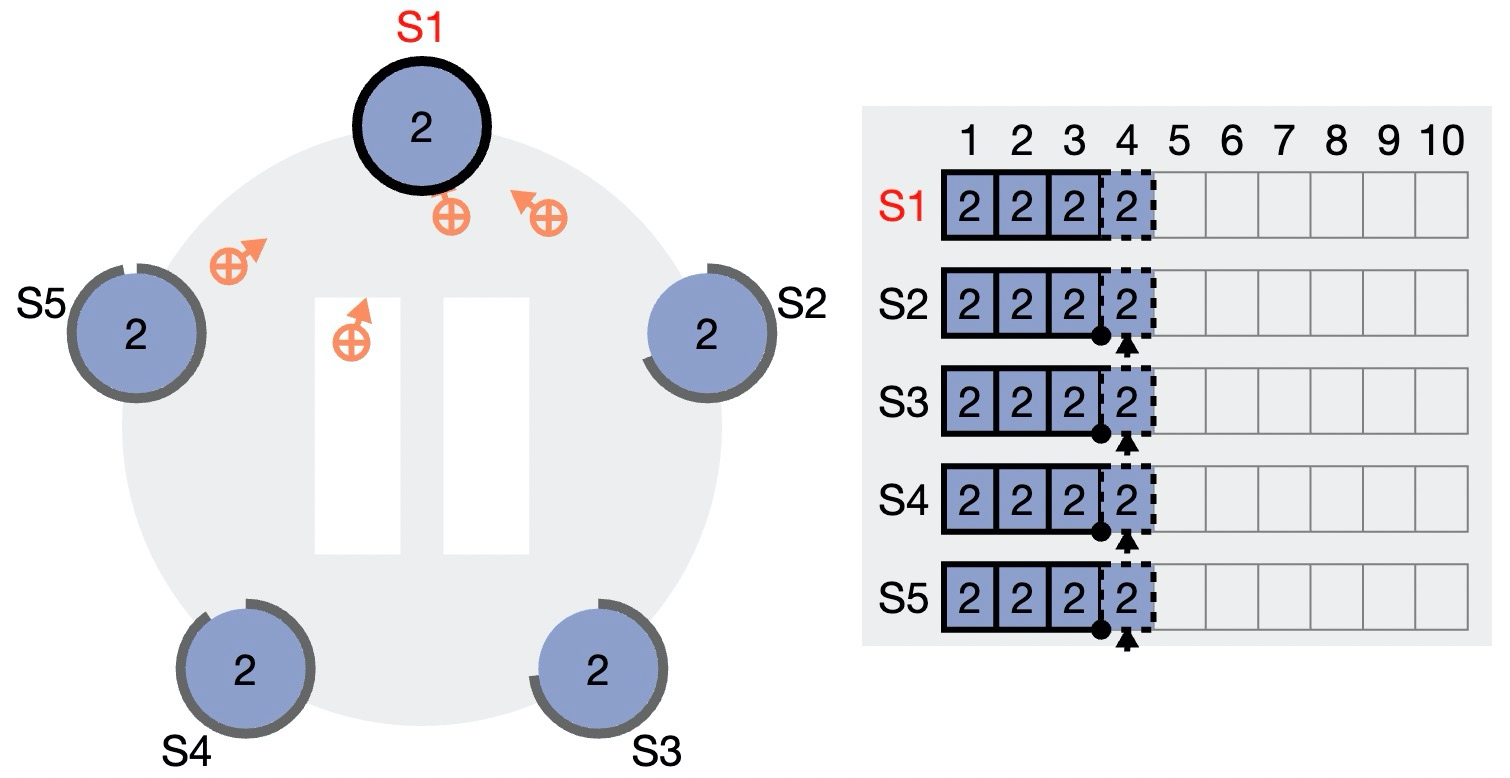
3)Leader 收到了超过半数(3/5)节点的 Ack,可以向客户端返回“请求完成”。同时推进本地的已确认日志位点(3 -> 4),因此刚刚写入的 log entry 4 完成确认,可以 apply。
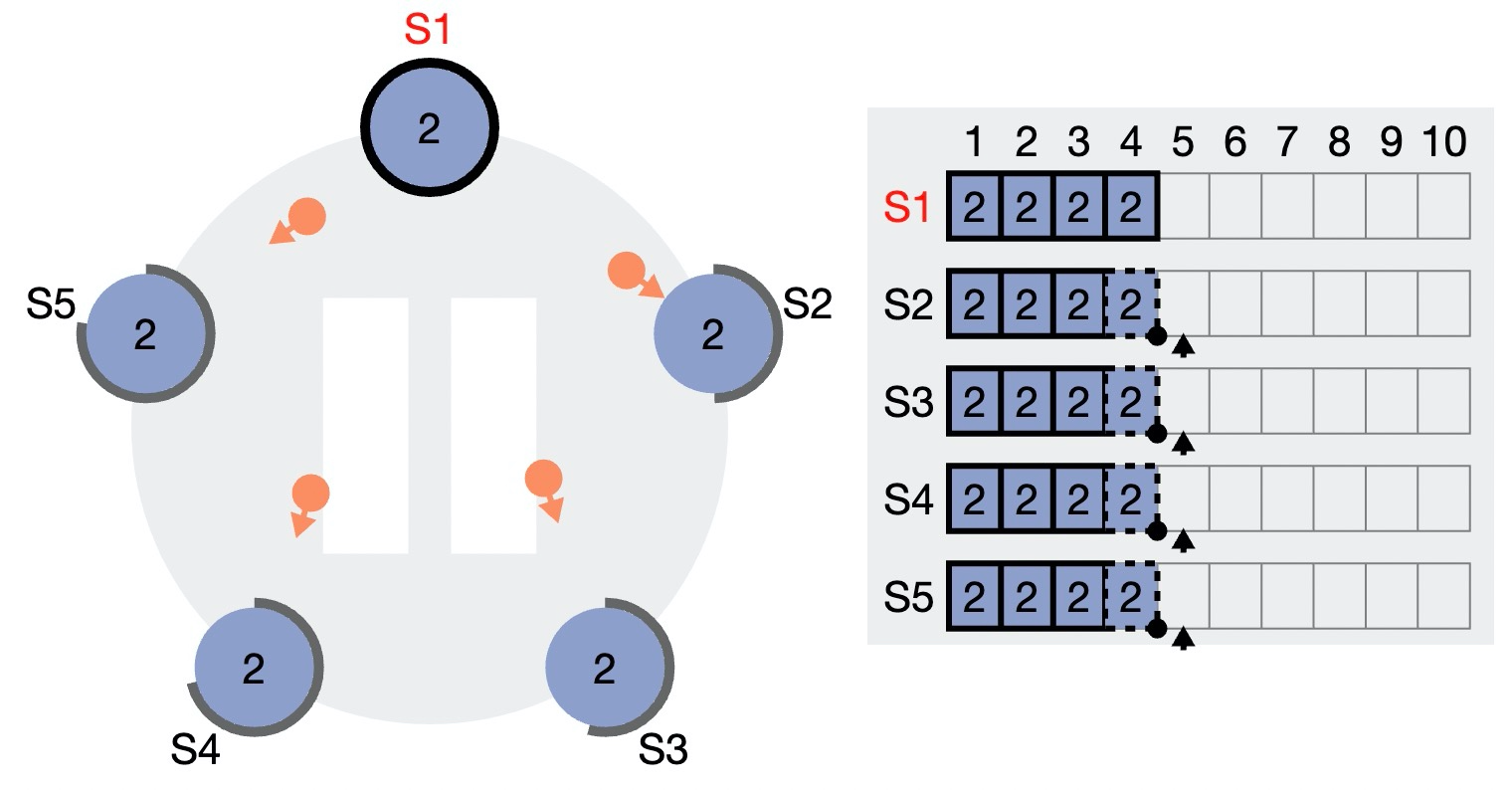
4)在下一次的 AppendEntry 请求中(可能不携带任何日志,仅仅作为心跳包),Follower “顺带”得知 Leader 已经确认到 4,因此也确认了本地的 4 号 log entry。
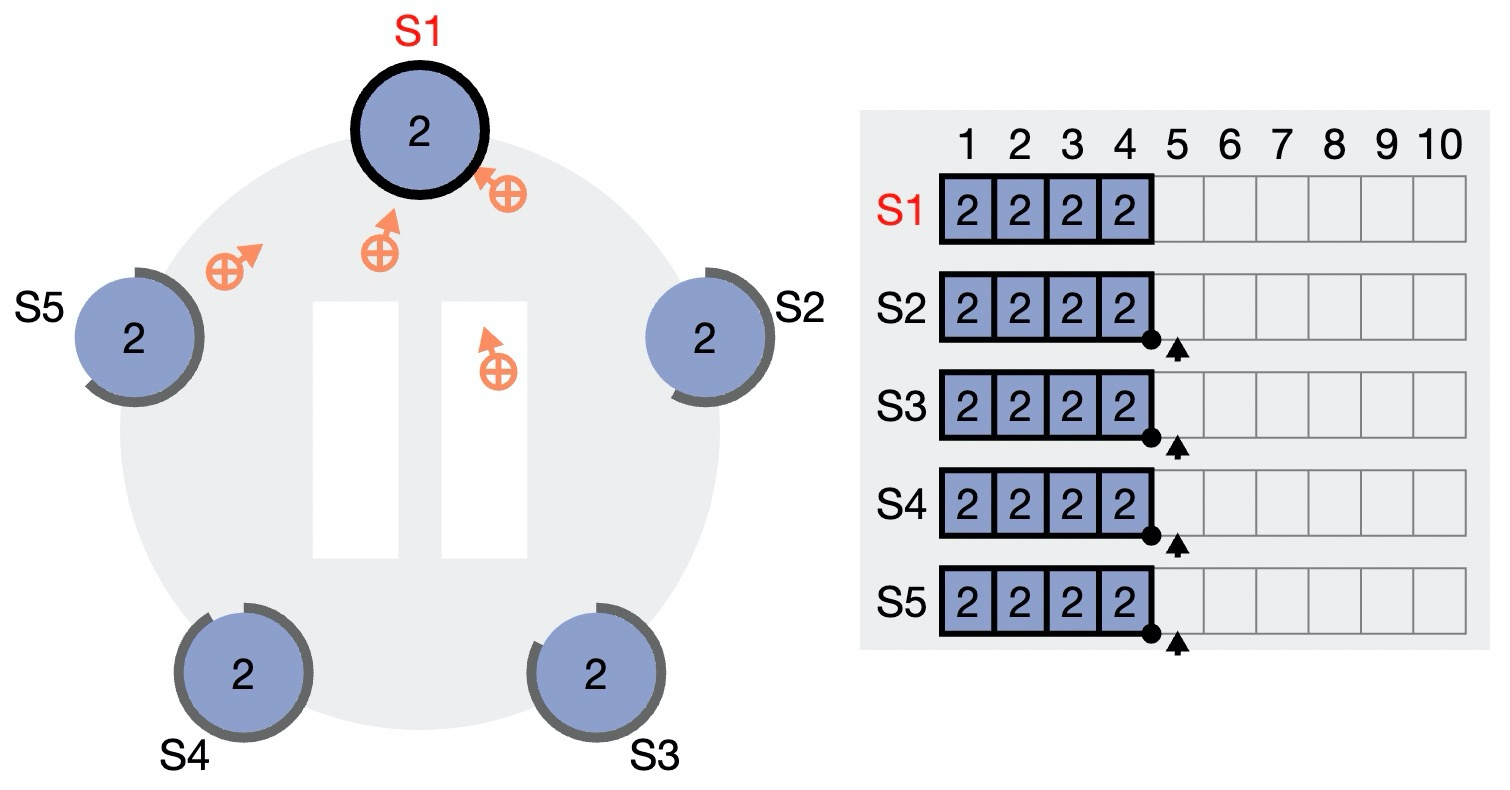
上述步骤中,1~3 是同步的:客户端必须等待 Leader 收集到超过半数参与者的确认,其延迟等于 Quorum 中最大的 Leader-follower RPC 延迟。而步骤 5 被 piggy-back 在后面的请求中,不产生额外代价。
上述示意图只涉及了正常流程,这仅仅是 Raft 算法的冰山一角!关于 Raft 的更多信息请阅读 In Search of an Understandable Consensus Algorithm。
Paxos vs. Raft
我们现在来回答:Paxos 和 Raft 算法对比有什么优缺点?需要明确的是,Raft 是一种用 Multi-Paxos 算法保证数据一致性的实现。关于 Raft 和 Multi-Raft,有以下几层理解:
1)Multi-Paxos 只是一个统称而不包含具体实现。在使用 Paxos 算法时,如果尽可能复用前一个回合的第一阶段 Proposer 就可以认为是 Multi-Paxos,此时这个 Proposer 实际上扮演了 Leader 的角色。至于如何实现,Lamport 并不关心。
2)Multi-Paxos 并不关心用途,论文中的描述是对一个抽象的“值(value)”或“提案(proposal)”达成一致。而 Raft 引入了复制状态机模型,明确了其用法是保证 Log 复制的一致性、进而保证复制状态机中的状态(数据)的一致性。
3)Raft 为了让算法更容易理解和实现,引入了一个额外的约束:必须按顺序确认 log entry,或者反过来说,确认 log entry 时不允许存在空洞。这是什么意思呢?
下图是一个 Raft 的例子。图中为 3 个节点上的日志情况,数字表示 log entry 的编号。由于 Raft 仅维护 prevLogIndex(已确认的 Log 位点),所以 log 一定是从前往后地 append 给 Follower。
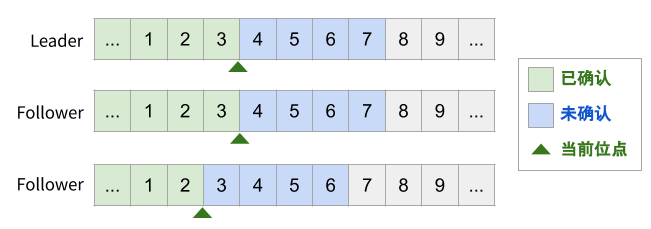
下图是一个 Multi-Paxos 的例子。假定我们的 Multi-Paxos 支持并发发送和乱序确认,可能会得到如图所示的状态:虽然 4 还没有达成多数派,但 5、6 已经达成多数派,因此 5、6 “可以” 先于 4 被消费。
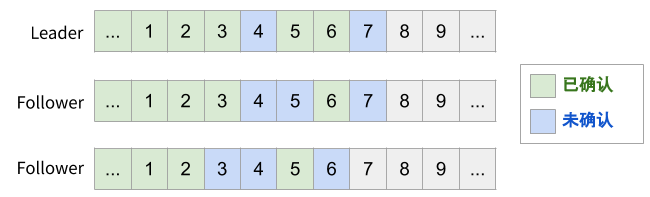
但是注意,5、6 能否被消费还需要“消费者”——复制状态机的支持。Raft 论文中讨论的通用复制状态机模型并不支持乱序 apply log,因此当然可以毫无负担的放弃乱序确认。实践中,以数据库为例,我们的确可以通过事务的 write-set/read-set 或是借助读写锁,分析出哪些情况下可以提前 apply log。
乱序确认对于数据库性能是必须的吗?不一定。如果可以对 Paxos Group 进行分区,那么每条 replica log 之间就彻底解藕了,彼此之前可以完全并发起来,每个 Paxos Group 上 log 发生阻塞的概率就大大下降了。考虑到分布式数据库通常都都做了数据分区,Paxos Group 的分区也很自然。
支持乱序 apply log 能提升多少性能呢?这个问题并没有一个确定的答案,与一致性协议的使用场景密切相关。实践中,如果一致性协议成为了系统 QPS 的瓶颈,才有必要考虑引入乱序确认机制。
PolarDB-X 中的一致性协议
PolarDB-X 的共享存储版和本地盘版使用了不同的一致性协议实现,但都选择了 Paxos 系算法。作为一个应用在关键场景的关系型 HTAP 数据库,PolarDB-X 选择保证数据的强一致性(CP),不接受任何已提交入库的数据丢失。
PolarDB-X 本地盘版的存储节点基于 X-DB 定制,使用阿里自研的 X-Paxos 算法同步一组 X-DB 节点的数据。X-Paxos 协议既支持上文提到的 log 乱序确认,同时也支持多个 Paxos Group 并行复制。更多信息可以阅读 PolarDB-X 一致性共识协议 —— X-Paxos。
PolarDB-X 共享存储版基于 Parallel-Raft 算法保证分布式存储(PolarFS)的数据一致性,Parallel-Raft 基于 Raft 算法,但是增加了对乱序确认的支持,如果想了解更多可以阅读 PolarFS 论文,未来我们会专门撰文解释 PolarFS。PolarDB-X 共享存储版基于 Parallel-Raft 算法保证分布式存储(PolarFS)的数据一致性,Parallel-Raft 基于 Raft 算法,但是增加了对乱序确认的支持,如果想了解更多可以阅读 PolarFS 论文,未来我们会专门撰文解释 PolarFS。
