




TiKV compaction
TiKV 底层存储引擎使用 RocksDB ,RocksDB 是一个基于 LSM tree 的单机嵌入式数据库, 对于LSM Tree 来说compaction是个非常重要的操作,本文对TiKV中涉及的compaction相关内容进行了整理总结。
为什么需要 compaction ?
LSM Tree 通过将所有的数据修改操作转换为追加写方式:对于 insert 直接写入新的kv,对于 update 则写入修改后的kv,对于 delete 则写入一条 tombstone 标记删除的记录。通过这种方式将磁盘的随机写入转换为顺序写从而提高了写入性能,但不能进行 in-place 更新,由此带来了以下问题:
1、 大量的冗余和无效数据占用磁盘空间,造成空间放大。
2、 读取数据时如果内存中没有的话,需要从L0层开始进行查找sst file,造成读放大。
因此通过 compaction 操作将数据下层进行合并、清理已标记删除的数据降低空间放大、读放大的影响。但是compaction 又带来了写放大的问题,因此不同的数据库根据需要使用不同的compact 策略,以达到读、写、空间最优的平衡。Compaction属于资源密集型操作,需要读写大量的数据并进行排序,消耗较多的IO、CPU资源。
Compaction做什么?
RocksDB的compaction 包含2方面:一是memtable写满后flush到磁盘,这是一种特殊的compacttion,也称为minor compaction。二是从L0 层开始往下层合并数据,也被称为major compaction,也是常说的compaction。
Compaction 实际上就是一个归并排序的过程,将Ln层写入Ln+1层,过滤掉已经delete的数据,实现数据物理删除。其主要过程:
1、 准备:根据一定条件和优先级等从Ln/Ln+1层选择需要合并的sst文件,确定需要处理的key范围。
2、处理:将读到key value数据,进行合并、排序,处理不同类型的key的操作。
3、写入:将排序好的数据写入到Ln+1层sst文件,更新元数据信息。
Compaction有哪些常见算法?
以下几种算法是学术性的理论算法,不同的数据库在具体实现时会有优化调整
- Classic Leveled
由O'Neil 在 LSM tree 论文中第一次提出,该算法中每层只有一个Sorted-Run(每个sorted-run 是一组有序的数据集合) , 以分区方式包含在多个文件内,每一层大小是上一层的固定倍数(叫fanout)。合并时使用all-to-all方式, 每次都将Ln的所有数据合并到Ln+1层,并将Ln+1层重写,会读取Ln+1层所有数据。 RocskDB使用some-to-some方式每次合并时只读写部分数据。
- Leveled-N
和上面Classic Leveled 类似,不过每层可以有N个Rorted-Run,每层的数据不是完全有序的。
- Tiered
Tiered 方式同样每层可以包含多个Sorted-Run ,Ln 层所有的数据向下合并到Ln+1层新的Sorted-Run,不需要读取Ln+1层原有的数据。Tiered方式能够最大的减少写放大,提升写入性能。
- FIFO
只有1层,写放大最小,每次compaction删除最老的文件,适合于带时间序列的数据。
RocksDB中compaction 算法支持Leveled compaction、Universal compaction、FIFO compaction。 对于Leveled compaction实际上是 tiered+leveled组合方式(后续描述均为此方式),Universal compaction 即 tiered compaction。
RocksDB的leveled compaction中 level 0包含有多个sorted-run,有多个sst文件,之间存在数据重叠,在compaction时将所有L0文件合并到L1层。对于L1-Lmax 层,每一层都是一个有序的Rorted-Run,包含有多个sst file。在进行读取时首先使用二分查找可能包含数据的文件,然后在文件内使用二分查找需要的数据。
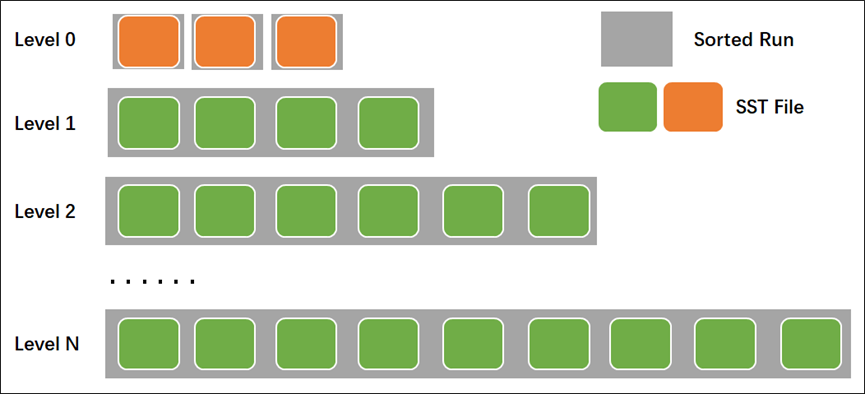 在TiKV 内可使用compaction-style参数修改每个CF的compaction 算法,支持的选项值包括0- level compaction(默认)、1-universal compaction 、2- FIFO,而Level总层数可通过参数num-levels控制,默认为7层。
