




如果数据库是基于postgres开发的,为了适配其他各种类型的数据库,我们肯定会碰到词法和语法的各种问题,例如缺少适配的token,语法规则的增删改,扫描标识符正则表达式增删改和各种移进规约冲突等等。对以上这些问题好多人都比较茫然,不知如何入手,接下来我就以halo数据库适配DB2碰到的一些简单的语法问题作为举例说明,其中一个就是ORDER关键字在DB2环境中可以作为列名和表名标识符,SQL命令如下:
CREATE TABLE order ( id int, order VARCHAR(32));
INSERT INTO order VALUES(1, 'JACK') ,(2,'LEO');
SELECT id, order FROM order; 原生DB2执行后输出结果如下:
DB2INST1, database:):CREATE TABLE order ( id int, order VARCHAR(32));@
DB20000I The SQL command completed successfully.
(instance:DB2INST1, database:):INSERT INTO order VALUES(1, 'JACK') ,(2,'LEO');@
DB20000I The SQL command completed successfully.
(instance:DB2INST1, database:):SELECT id, order FROM order;@
ID ORDER
----------- --------------------------------
1 JACK
2 LEO
2 record(s) selected. 但是postgres执行却不支持,输出错误如下:
ERROR: syntax error at or near "order" at character 14 这是因为order是保留字关键字,移进规约冲突错误的是它只支持作为列的别名,其他都不支持。那怎么修改才能支持呢,我们先从了解查询处理的流程架构开始。
查询处理的流程架构
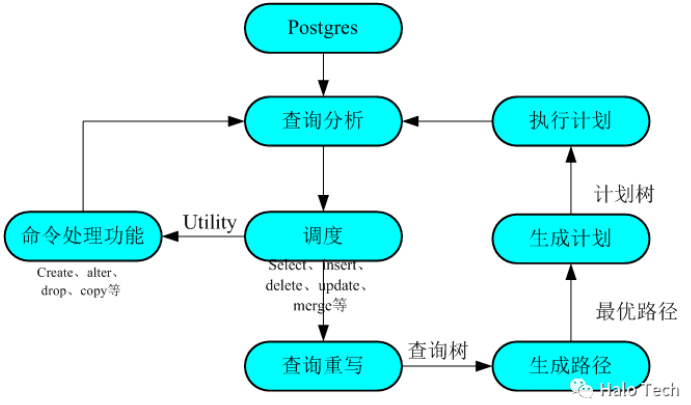
各模块简单说明如下:
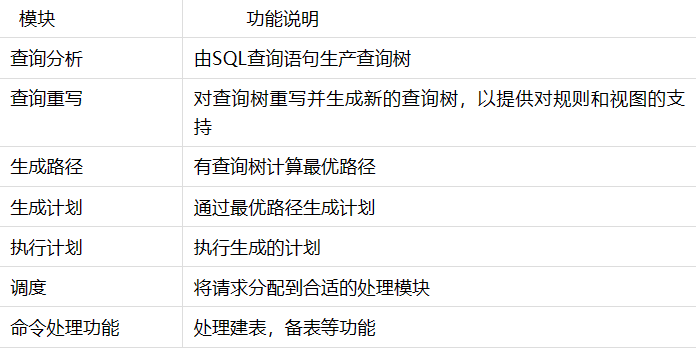
通过以上介绍的查询处理流程,有些反应快的朋友会想到,我们为什么不在查询分析前,用程序改写SQL命令字符串,把命令中ORDER关键字替换为“order”呢?这样也会输出同样的结果,是的,这是一种方法,修改如下:
CREATE TABLE "order" ( id INT, "order" VARCHAR(32));
INSERT INTO "order" VALUES(1, 'JACK') ,(2,'LEO');
SELECT id, “order" FROM "order";1、只对表名,列名order小写支持,不支持大写等其他各种写法。
2、碰到order by子句order也可能会被替换。
3、碰到字符串常量里带有order,这样会导致输出结果出现问题。
4、执行效率问题,增加了多次遍历字符串替换处理的过程。
5、代码可读性不强。
6、这些改写只适配特定的语境,随着语境的复杂多样化,以后处理更改就像打补丁,逻辑越来复杂,代码也越来越多,到最后维护的成本越来越高昂。


[1] kwlist.h: 声明keyword列表
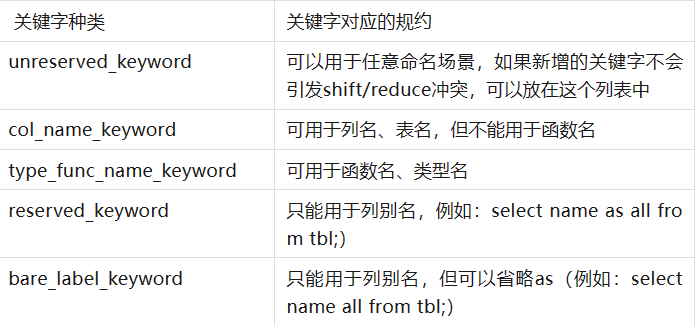
具体为:
PG_KEYWORD("order", ORDER, RESERVED_KEYWORD, AS_LABEL)[2] kwlookup.cpp: 定义ScanKeywordLookup函数实现,该函数判断输入的字符串是否是关键字,若是关键字,则返回关键字列表中单词的指针,采用二分查找。没有匹配的则返回NULL。
[3] scanup.c:提供几个词法分析时常用的函数。scanstr函数处理转义字符,downcase_truncate_identifier函数将大写英文字符转换为小写字符,truncate_identifier函数截断超过最大标识符长度的标识符,scanner_isspace函数判断输入字符是否为空白字符
[4] scan.l:定义词法结构,编译生成scan.c;这里会忽略comment等无用信息。
[5] gram.y:定义语法结构,编译生成gram.c;分析后生成语法分析树。
[6] check_keywords.pl: 检查在gram.y和kwlist.h中定义的关键字列表是否一致。
[7] parser.c: 提供词法与语法分析调用函数入口raw_parser函数,
list *raw_parser(const char *str, RawParseMode mode)它的主要作用:
初始化flex scanner:
yyscanner = scanner_init(str, &yyextra.core_yy_extra,
ScanKeywords, NumScanKeywords);初始化bison parser:
parser_init(&yyextra);parse解析:
yyresult = base_yyparse(yyscanner);除了raw_parser函数之外,此文件还有一个比较重要函数是
int base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp
, core_yyscan_t yyscanner)它负责在词法扫描与语法解析两个模块之间的关键字过滤处理的作用。
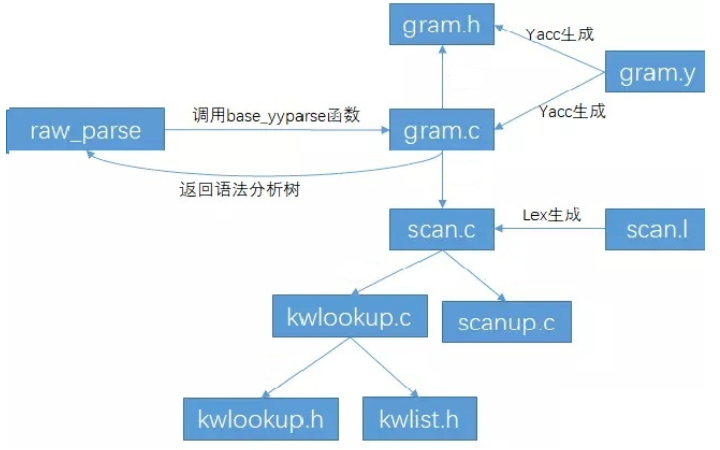
词法flex与语法bison工作原理的简单介绍
1、Flex工作原理:通过生成词法分析器的编译工具,生成词法分析器代码,将.l文件编译后生成.c和.h文件。
2、bison工作原理:通过生成语法分析器代码,将.y文件编译后生成.c和.h文件。
语法分析通常所做的就是对输入中的形式文法构架 LALR 分析表,并生成基于该分析表的语法分析器 C 语言源程序.tab.c,其语法分析函数原型为int yyparse(). 该语法分析器通过调用用户提供的词法分析函数int yylex(),对输入串 进行扫描得到的终结符进行语法分析,如果分析成功,则函数返回 0, 否则返回非 0. 其分析方法采用自底向上的移进/归约分析法,在完成归约时, yyparse()将执行 bison 源文件用户在当前归约产生式后附注的 C 语言 代码,bison 称之为语义动作 (Semantic Action).
通过词法与语法分析对语法问题的解决
1、对于halodb2适配DB2增删改关键字或者语法规则,一般会涉及两个文件“gram.y”和“kwlist.h”。举个简单例子,添加DB2关键字microsecond。
首先在kwlist.h文件中增加一行,插入要按字母ASCII码排序,否则会产生移进规约冲突。
PG_KEYWORD("microsecond", MICROSECOND_P,
UNRESERVED_KEYWORD, AS_LABEL)在gram.y中添加关键字的说明和文法规则%token 声明新的终结符
%token <keyword> ... METHOD MICROSECOND_P MINUTE_P ...添加到非保留字列表中(要跟kwlist.h中的每一个关键字声明要一致,防止移进规约冲突)
/* "Unreserved" keywords --- available for use as any kind of name.
*/
unreserved_keyword:
ABORT_P
| ABSOLUTE_P
...
| MICROSECOND_P再声明新规则语法节点,返回类型list*
%type <list> interval_microsecond最后添加新语法规则
interval_microsecond:
MICROSECOND_P
{$$ = list_make1(makeIntConst(INTERVAL_MASK(SECOND), @1));}
;2、对于halodb2适配DB2词法规则的修改,主要涉及“scan.l”文件,例如DB2标识符支持带有"#"
SELECT * FROM USER#;修改“scan.l”文件如下
ident_start [A-Za-z\200-\377_]
ident_cont [A-Za-z\200-\377_0-9\$\#] /*添加#符号*/3、回到我们最初的ORDER关键字的例子,因为ORDER是保留字关键字,但在上述例子中它却作为列名与表名,在postgres测试时报移进规约冲突的错误。那有人就说为什么不把关键字声明改成unreserved类型,就都支持了,这个方法不错,但是试了一下,却是order by子句报移进规约错误,如下所示:
gram.y: error: shift/reduce conflicts: 18 found, 0 expected
gram.y: error: reduce/reduce conflicts: 5 found, 0 expected那接下来怎么把两种移进规约分离处理呢。在分离处理之前,我们了解一下伪token,伪token只在gram.y文件定义,它没有token关键字种类声明,也没有标识符值,编译后会自动生成注册tokentype枚举值,所以它也不受关键字的规约限制,只是一个占位关键字的作用。这个不错,我们可以利用起来。
/*gram.y中声明方式*/
%token ORDER_Q我们再回顾bison的基本原理,他是先调用词法分析函数int yylex()对输入串 进行扫描取词后再进行语法分析。此涉及两个文件“gram.y”和"parser.c",在"parser.c"文件中base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)函数正好给我们提供这个扫描功能,当取出的cur_token是“ORDER” token后,我们可以再多取一个next_token,通过判断next_token 是否 “BY” token,如果不是则替换为ORDER_Q token,反之则不替换,沿用原来的移进归约方法。代码如下:
base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)
{
base_yy_extra_type *yyextra = base_yyget_extra(yyscanner);
int cur_token;
int next_token;
int cur_token_length;
YYLTYPE cur_yylloc;
/* Get next token --- we might already have it */
if (yyextra->have_lookahead)
{
cur_token = yyextra->lookahead_token;
lvalp->core_yystype = yyextra->lookahead_yylval;
*llocp = yyextra->lookahead_yylloc;
if (yyextra->lookahead_end)
*(yyextra->lookahead_end) = yyextra->lookahead_hold_char;
yyextra->have_lookahead = false;
}
else
cur_token = base_core_yylex(&(lvalp->core_yystype), llocp, yyscanner);
/*
* If this token isn't one that requires lookahead, just return it. If it
* does, determine the token length. (We could get that via strlen(), but
* since we have such a small set of possibilities, hardwiring seems
* feasible and more efficient --- at least for the fixed-length cases.)
*/
switch (cur_token)
{
case NOT:
cur_token_length = 3;
break;
...
case ORDER:
cur_token_length = 5;
break;
...
default:
return cur_token;
}
/*
* Identify end+1 of current token. base_core_yylex() has temporarily stored a
* '\0' here, and will undo that when we call it again. We need to redo
* it to fully revert the lookahead call for error reporting purposes.
*/
yyextra->lookahead_end = yyextra->core_yy_extra.scanbuf +
*llocp + cur_token_length;
Assert(*(yyextra->lookahead_end) == '\0');
/*
* Save and restore *llocp around the call. It might look like we could
* avoid this by just passing &lookahead_yylloc to base_core_yylex(), but that
* does not work because flex actually holds onto the last-passed pointer
* internally, and will use that for error reporting. We need any error
* reports to point to the current token, not the next one.
*/
cur_yylloc = *llocp;
/* Get next token, saving outputs into lookahead variables */
next_token = base_core_yylex(&(yyextra->lookahead_yylval), llocp, yyscanner);
yyextra->lookahead_token = next_token;
yyextra->lookahead_yylloc = *llocp;
*llocp = cur_yylloc;
/* Now revert the un-truncation of the current token */
yyextra->lookahead_hold_char = *(yyextra->lookahead_end);
*(yyextra->lookahead_end) = '\0';
yyextra->have_lookahead = true;
/* Replace cur_token if needed, based on lookahead */
switch (cur_token)
{
case NOT:
/* Replace NOT by NOT_LA if it's followed by BETWEEN, IN, etc */
switch (next_token)
{
case BETWEEN:
case IN_P:
case LIKE:
case ILIKE:
case SIMILAR:
cur_token = NOT_LA;
break;
}
break;
...
case ORDER:
if(next_token != BY)
cur_token = ORDER_Q;
break;
...
}
return cur_token;
}最后gram.y文件中给token ORDER_Q 添加新规则来支持ORDER_Q作为列名与表名,并且设置“order”字符串作为标识符名称,再SQL命令调用时它可以支持大小写:
/* Column identifier --- names that can be column, table, etc names.
*/
ColId: IDENT { $$ = $1; }
| unreserved_keyword { $$ = pstrdup($1); }
| col_name_keyword { $$ = pstrdup($1); }
| ORDER_Q { $$ = pstrdup("order");}
;编译后我们重启测试以下命令输出结果,发现与原生DB2一致。
CREATE TABLE order (id int, order VARCHAR(32));
INSERT INTO order VALUES(1, 'JACK'), (2,'LEO');
halodb2=# SELECT id, ORDER FROM ORDER;
id | order
----+-------
1 | jack
2 | LEO
(2 rows)总结以上,如果适配各种类型的数据库,词法与语法修改是不可或缺的,特别是第三种技巧很有用,比如halodb2适配DB2的values a_expr语法,DB2要支持各种类型函数进行强制转化,例如int(12.32),但在POSTGRES直接修改关键字声明后,却存在着移进规约冲突等情况,这些其实都可以采用这种方法完美解决。最后大家如果想更深入第三种技巧的使用方式,可以思考一下问题,如何解决适配DB2产生的类型 char(Iconst)语法与强制转换函数char(func_arg_list_opt)语法的移进规约冲突。
