




目 录
一、崖山数据库简介
二、单机部署
1、操作系统准备
2、操作系统参数调整
3、安装初始环境调整
4、创建安装用户
5、目录划分
6、下载软件包
7、YashanDB 命令行安装
三、单机启停及开机自启动
1、启停数据库实例
2、设置开机自启动
四、对比 Oracle 简单使用 YashanDB
1、表空间相关操作
2、用户相关操作
3、表相关操作
4、归档日志相关操作
5、参数管理
6、数据插入读取对比
下面直接说一下第一次使用崖山的感受吧,YashanDB 崖山数据库在 O 兼容性方面做的还是很不错的,包括数据库管理、表空间管理、很多“V$” 和“GV$”系统视图,"DBA_"和“ALL_"和“USER_”系统视图,exp/imp 传统导入导出均和 O 无太多差别,这让很多 O 记 DBA 能够快速上手,能尽快了解掌握这款国产数据库。对于简单的汇总查询以及数据的插入操作,YashanDB 是完全可以胜任的,但是像多表关联复杂查询,Oracle 强大的优化器让其他数据库望尘莫及,令人意外的是 YashanDB 通过列执行引擎的 HINT,性能查询也不输 O 记 12c 版本,值得期待崖山数据库后面的表现。最后要说的不仅仅是 YashanDB,我们的其他国产数据库仍然需要努力,在优化器上多多下功夫,性能这一块还是要努力,给国产数据库一些时间,期待它在未来的时间里走出国门走向世界。
一、崖山数据库简介
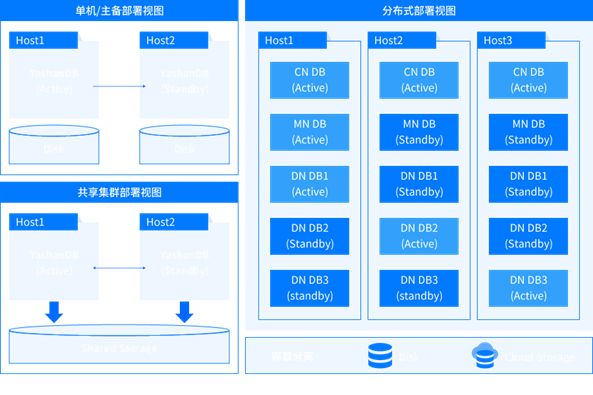
崖山数据库管理系统(YashanDB)是深圳计算科学研究院在经典数据库理论基础上,融入新的原创理论,自主设计、研发的新型数据库管理系统。业界传闻 YashanDB 和 Oracle 数据库很像很像,除了支持单机主备部署,还支持共享集群部署以及分布式部署。
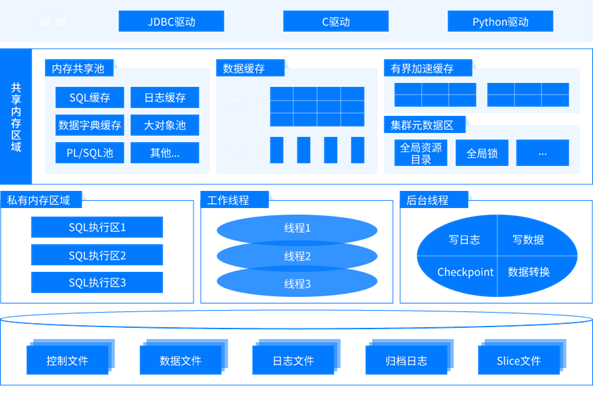
YashanDB 数据库系统架构
单机主备部署类似于 Oracle 的 Dataguard,也可以级联部署,分布式和共享集群主备部署中无级联备。崖山共享集群利用 Cohesive Memory 核心技术采用单进程、多线程的服务架构,负责管理共享集群数据库,提供集群配置管理、资源管理、资源监控、集群高可用等能力。YashanDB 分布式部署基于 Shared-Nothing 架构,由多个节点组(Coordinator Node Group、Management Node Group、Data Node Group)组成,节点组内有多个节点(Coordinator Node、Management Node、Data Node)。这些节点部署在不同主机上,有不同的安装目录、数据目录,并且通过一些网络端口进行内部通讯或对外提供服务。
YashanDB 会在今天发布个人版,2023 年 11 月 8 日,YashanDB 2023 年度发布会将于云端直播开启,面向个人开放下载 23.1 版本。
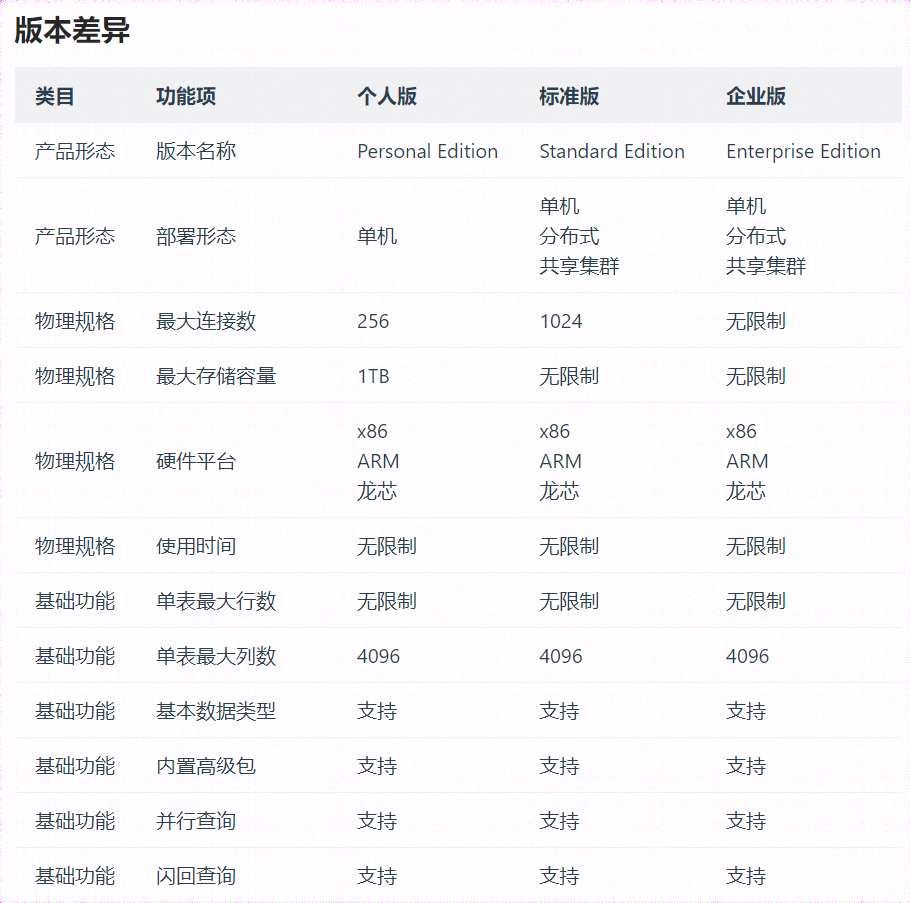
个人版:YashanDB 面向个人用户推出的免费试用版本,除不支持多模数据类型、高级安全能力、数据库集群等企业级功能,该版本包含 YashanDB 数据库所有基础核心能力,支持单机主备部署形态,配套开发者工具,供个人用户或开发者用于学习、测试、开发用途。
标准版:YashanDB 面向小规模用户推出的商业版本,该版本价格适中,除不支持多模数据类型、高级安全能力等企业级功能,该版本包含 YashanDB 数据库所有基础核心能力,支持单机主备、分布式、集群部署形态,配套完整数据迁移和监控运维工具,可以为政府或中小企业提供支持其操作所需的基本能力。
企业版:YashanDB 面向大规模用户推出的商业版本,该版本包含 YashanDB 数据库完整核心能力,支持 PB 级海量数据存储和大量的并发用户,支持多模数据类型、高级安全能力,支持单机主备、分布式、集群部署形态,配套完整数据迁移和监控运维工具,可以满足支撑各类企业应用。
二、单机部署
安装前准备包括如下事项:
服务器准备
操作系统参数调整
安装初始环境调整
创建安装用户
目录划分
下载软件包
1、操作系统准备
需要一台 Linux7.6 及以上的 x86 64 位系统,或者 kylin V10 的 ARM 64 位系统,配置则为 4c/16g,50G SSD 磁盘,ext4 或 xfs 的文件系统,千兆以上以太网。如果是个人开发版本,官方建议是 2c/4g 50G SSD 磁盘完全够用。

[root@JiekeXu ~]# cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) [root@JiekeXu ~]# uname -a Linux JiekeXu 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux [root@JiekeXu ~]# free -m total used free shared buff/cache available Mem: 11835 1131 985 112 9718 10200 Swap: 2047 0 2047 [root@JiekeXu ~]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/centos-root xfs 97G 70G 28G 73% / devtmpfs devtmpfs 5.8G 0 5.8G 0% /dev tmpfs tmpfs 5.8G 0 5.8G 0% /dev/shm tmpfs tmpfs 5.8G 45M 5.8G 1% /run tmpfs tmpfs 5.8G 0 5.8G 0% /sys/fs/cgroup /dev/sda1 xfs 1014M 180M 835M 18% /boot tmpfs tmpfs 1.2G 0 1.2G 0% /run/user/1001 tmpfs tmpfs 1.2G 36K 1.2G 1% /run/user/0
2、操作系统参数调整
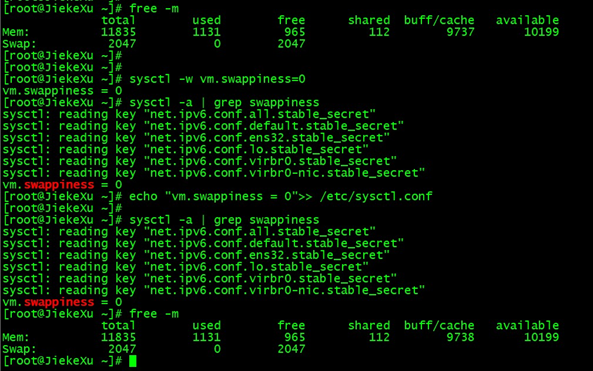
关闭交换分区
使用 sysctl -a | grep swappiness 查看当前状态。
# sysctl -w vm.swappiness=0
# echo "vm.swappiness = 0">> /etc/sysctl.conf
调整自动分配本地端口范围
下限值建议大于30000。
# sysctl -w net.ipv4.ip_local_port_range='32768 60999'
# echo "net.ipv4.ip_local_port_range = 32768 60999" >> /etc/sysctl.conf
调整进程的VMA上限
使用 sysctl -a|grep vm.max_map_count 查看当前上限值,建议大于 2000000。
# sysctl -w vm.max_map_count=2000000
# echo "vm.max_map_count=2000000" >> /etc/sysctl.conf
调整资源限制值
将一些内核参数所定义的资源限制值(使用ulimit -a可查看所有的资源限制值)调整为大于或等于最小要求的某个值,具体如下:
open files 最小要求 65536, ulimit -n 65536
max user processes 最小要求 65536,ulimit -u 65536
max memory size unlimited 最小要求 ulimited,ulimit -m unlimited
stack size 最小要求 8192,ulimit -s 8192
vi /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536 * soft rss unlimited * hard rss unlimited * soft stack 8192 * hard stack 8192
关闭透明大页
标准大页内存会在系统启动时预分配,而透明大页会在运行时动态分配大页内存,可能产生运行时错误,造成 YashanDB 被终止。我们建议您在安装时,关闭操作系统透明大页(Transparent HugePages)选项。
查看透明大页是否开启
在一些系统的内核中默认开启了透明大页选项。您可以通过以下指令确认:
## Red Hat Enterprise Linux 内核
# cat /sys/kernel/mm/redhat_transparent_hugepage/enabled
## 其他内核
# cat /sys/kernel/mm/transparent_hugepage/enabled
若显示 [always] madvise never ,则说明透明大页开启。
若显示 always madvise [never] ,则说明透明大页关闭。
关闭透明大页和 numa
在 GRUB_CMDLINE_LINUX 中添加或修改参数 transparent_hugepage=never numa=off 。
修改
sed -i 's/quiet/quiet transparent_hugepage=never numa=off/' /etc/default/grub
grep quiet /etc/default/grub
grub2-mkconfig -o /boot/grub2/grub.cfg
reboot 重启后检查是否生效:
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /proc/cmdline
#不重启,临时生效
echo never > /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/enabled
3、安装初始环境调整
开放端口
运行 YashanDB 产品需要占用一系列端口(通信矩阵中已列示这些端口的作用及相关信息)。YashanDB 制订了一套端口划分规则,并据此规则给出了安装部署过程中需要指定的端口号默认值。用户可根据自身网络状况修改这些端口号,但应该遵循这套规则,以避免出现端口冲突错误。
端口划分规则:
一个实例需要配多个监听端口,给一个初始值,后面端口缺省+1。
一个物理机需要配多个实例,给一个初始值,后面实例缺省+10。
按照MN、CN、DN 的顺序生成端口号。
单机实例或分布式 CN 的监听端口初始值默认为 1688,对应后续安装中的 beging-port 参数。
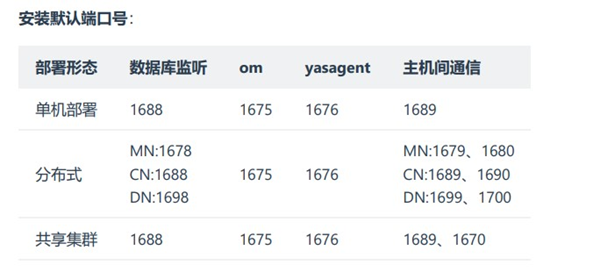
建议在所有服务器上开放上表所列示端口。此外,对启用可视化部署 web 服务的主机,还需开放 9001 端口。
方式一:关闭防火墙
在所有主机上执行如下命令关闭防火墙:
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
#关闭 selinux
cp /etc/selinux/config /etc/selinux/config_`date +"%Y%m%d_%H%M%S"`&& sed -i 's/SELINUX\=enforcing/SELINUX\=disabled/g' /etc/selinux/config
cat /etc/selinux/config
#不重启
setenforce 0
getenforce
sestatus
方式二:添加白名单
如果防火墙不能关闭,则必须按如下步骤添加端口到白名单中:
1.查看防火墙端口开放情况:
# firewall-cmd --zone=public --list-ports
2.添加端口到防火墙(Firewall):
这里以单机 1688 为例演示如何添加端口到防火墙中,其他端口操作方法相同。
## 添加(--permanent 永久生效,没有此参数重启后失效)
# firewall-cmd --zone=public --add-port=1688/tcp --permanent
## 重新载入
# firewall-cmd --reload
## 查看
# firewall-cmd --zone=public --query-port=1688/tcp
如需从白名单中删除已添加的端口,使用如下命令:
##删除已添加的端口
# firewall-cmd --zone=public --remove-port=1688/tcp --permanent
开启SSH服务
首先,请在所有服务器上检查 ssh 服务是否已打开,如输出信息中无 active (running) 内容,请参照如下命令开启ssh服务:
# systemctl status sshd.service
# systemctl start sshd.service
4、创建安装用户
强烈建议在所有服务器上创建 YashanDB 产品的安装用户,而不是使用 root 身份执行安装部署。
创建 yashan 用户
本文中,以 yashan 作为数据库安装用户名称,请在所有服务器上执行如下命令:
# useradd -d /home/yashan -m yashan
# passwd yashan
配置 sudo 免密
首先,请打开 /etc/sudoers 文件,通常情况下,即使 root 用户都无该文件的编辑权限,此时需要先对 root 授权。
在文件的最后添加如下内容后保存退出:
# cd /etc
# ll sudoers
# chmod +w sudoers
# vim /etc/sudoers
# yashan ALL=(ALL) NOPASSWD:ALL
最后,如该文件初始为只读,恢复其属性:
# chmod -w sudoers
将 yashan 用户加入到 YASDBA 用户组
# groupadd YASDBA
# usermod -a -G YASDBA yashan
5、目录划分
安装目录
YashanDB 采用集群多节点并行安装模式,只需在一台主机上创建安装目录,用于下载和解压软件包。
本文中,安装目录规划在 /home/yashan 下,由 yashan 用户执行软件包下载时自行创建。
HOME 目录和 DATA 目录
所有安装 YashanDB 的实例节点(一台服务器对应一个实例节点,或者一台服务器包含多个实例节点)上必须规划的两个目录为:
**HOME目录:**YashanDB 的产品目录,包含 YashanDB 所提供的命令、数据库运行所需的库及各关键组件。该目录由 yashan 用户执行安装部署时输入的 install-path 参数根据一定规则生成并创建。
**DATA目录:**YashanDB 的数据目录,包含数据库的各类系统数据文件、日志文件和配置文件,用户数据也缺省存储在该目录下。但对于共享集群,所有的数据文件和 redo 文件均需保存在共享存储上,DATA 目录将只用于存储实例运行相关的配置文件、日志文件等数据。该目录由 yashan 用户执行安装部署时输入的 data-path 参数根据一定规则生成并创建。
本文中,HOME 目录和 DATA 目录均规划在 /data/yashan 下,yashan 用户需要对该目录拥有全部权限,可执行如下命令授权:
# cd /
# mkdir data
# cd data
# mkdir yashan
# chmod -R 777 /data/yashan
6、下载软件包
软件包清单
包括如下三类:
由 DBA 在服务器上安装的YashanDB软件包。
用于连接 YashanDB 的客户端软件包,由需要使用的用户在本机安装。
用于进行 YashanDB 接口程序开发的各驱动软件包,由应用程序开发人员在需要时选择安装 。
yashandb-23.1.0.309-linux-x86_64.tar.gz
我这里已经两周前联系技术支持人员将软件包发给我了,大家可以等今天 2023 年 11 月 8 日,YashanDB 2023 年度发布会发布后,个人版免费下载,获取对应的安装包。
# su - yashan
$ mkdir install
$ cd /home/yashan/install
$ exit
--将原先上传到 /root 下的软件包移动到 install 目录
# mv /root/yashandb-23.1.0.309-linux-x86_64.tar.gz /home/yashan/install/
--然后使用 yashan 用户解压
$ su - yashan
$ cd /home/yashan/install
$ tar -zxvf yashandb-23.1.0.309-linux-x86_64.tar.gz
获取安装工具
YashanDB 所提供软件包中包含安装工具,位于 bin 目录下。其中,如执行命令行安装,需要用到 yasboot 命令,如执行可视化安装,则需要用到 yasom 命令。
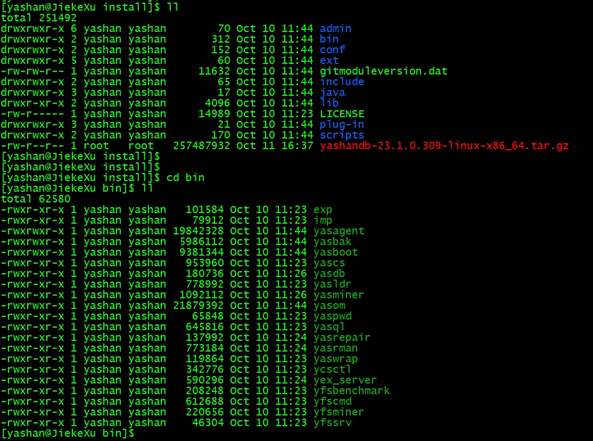
在执行完本步骤后,即可进入正式的 YashanDB 安装过程,请根据操作偏好选择如下安装方式:
**命令行安装:**本方式表示直接登录到服务器,且以 Linux 命令形式执行安装各步操作。
**可视化安装:**本方式表示①在服务器上启动 web 服务;②在本地 Windows 环境浏览器上,以网页形式执行安装各步操作。
7、YashanDB 命令行安装
执行安装部署前,以 yashan 用户登录 192.168.75.32 服务器,并进入 /home/yashan/install 安装目录。
单机部署
Step1:生成部署文件
- 执行 yasboot package 命令生成配置文件,命令详细参数可查阅 yasboot。
其中,–cluster 指定为要部署的数据库集群名称,该名称也将作为集群中所有节点上初始创建数据库的名称(database name),-u 指定安装用户为 yashan,-p 指定 yashan 用户密码(此用户密码为前面第四步创建的操作系统用户密码),–ip 为操作系统主机的 IP地址,切记不能使用 127.0.0.1 地址,否则会导致客户端无法连接到服务端数据库,–port 指定 SSH 服务端口,这里是默认的 22 端口,–install-path 指定数据库安装路径,–data-path 指定数据存放目录,–begin-port 指定数据库监听端口。
$ ./bin/yasboot package se gen --cluster yashandb -u yashan -p yashan --ip 192.168.75.32 --port 22 --install-path /data/yashan/yasdb_home --data-path /data/yashan/yasdb_data --begin-port 1688

-
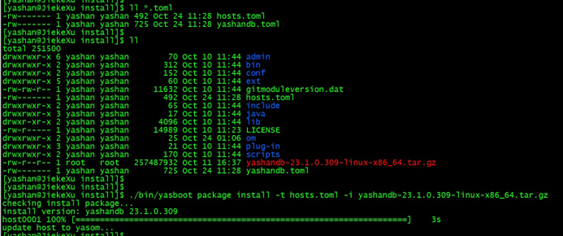
上一步骤执行完毕后,当前目录下将生成 yashandb.toml 和 hosts.toml 两个配置文件,yashandb.toml 为数据库集群的配置文件,hosts.toml 为主机的配置文件,可手动修改,但不建议删除文件中任何行,否则可能导致后续安装过程报错,或者所搭建的环境后续无法进行扩展配置。
[yashan@JiekeXu install]$ ./bin/yasboot package se gen --cluster yashandb -u yashan -p yashan --ip 192.168.75.32 --port 22 --install-path /data/yashan/yasdb_home --data-path /data/yashan/yasdb_data --begin-port 1688 192.168.75.32 ip:192.168.75.32 scan failed, 主机扫描失败:ssh: handshake failed: ssh: unable to authenticate, attempted methods [none password], no supported methods remain hostid | group | node_type | node_name | listen_addr | replication_addr | data_path -------------------------------------------------------------------------------------------------------------- host0001 | dbg1 | db | 1-1 | 192.168.75.32:1688 | 192.168.75.32:1689 | /data/yashan/yasdb_data ----------+-------+-----------+-----------+--------------------+--------------------+------------------------- Generate config success [yashan@JiekeXu install]$ ll *.toml -rw------- 1 yashan yashan 494 Oct 24 01:06 hosts.toml -rw------- 1 yashan yashan 725 Oct 24 01:06 yashandb.toml -
依据企业实际需要调整 yashandb.toml 配置文件中的安装参数。其中,可在 group 级别设置 YashanDB 的所有建库参数,在 node 级别设置 YashanDB 的所有配置参数。
[yashan@JiekeXu install]$ more hosts.toml uuid = "6536a823f69e808d26e6d081d7941879" cluster = "yashandb" yas_type = "SE" secret_key = "5fd0e74f72772ee5" add_yasdba = true [om] hostid = "host0001" [om.config] LISTEN_ADDR = "192.168.75.32:1675" [[host]] hostid = "host0001" group = "yashan" user = "yashan" password = "yashan" ip = "192.168.75.32" port = 22 path = "/data/yashan/yasdb_home" jvm_path = "" total_memory = 0 [host.yasagent] [host.yasagent.config] LISTEN_ADDR = "192.168.75.32:1676" [yashan@JiekeXu install]$ more yashandb.toml cluster = "yashandb" create_simple_schema = false uuid = "6536a823f69e808d26e6d081d7941879" yas_type = "SE" [[group]] group_type = "db" name = "dbg1" [group.config] CHARACTER_SET = "utf8" ISARCHIVELOG = true REDO_FILE_NUM = 4 REDO_FILE_SIZE = "128M" [group.create_sql] [[group.node]] data_path = "/data/yashan/yasdb_data" hostid = "host0001" role = 1 [group.node.config] LISTEN_ADDR = "192.168.75.32:1688" REPLICATION_ADDR = "192.168.75.32:1689" RUN_LOG_FILE_PATH = "/data/yashan/yasdb_home/yashandb/23.1.0.309/log/yashandb/db-1-1/run" RUN_LOG_LEVEL = "INFO" SLOW_LOG_FILE_PATH = "/data/yashan/yasdb_home/yashandb/23.1.0.309/log/yashandb/db-1-1/slow"Step2:执行安装
$ cd /home/yashan/install $ ./bin/yasboot package install -t hosts.toml -i yashandb-23.1.0.309-linux-x86_64.tar.gz
Step3:数据库部署
执行部署命令。
$ ./bin/yasboot cluster deploy -t yashandb.toml

生效环境变量(此步骤需以 yashan 用户登录到每个节点上执行)。
# 部署命令成功执行后将会在 $YASDB_HOME 目录下的 conf 文件夹中生成<<集群名称>>.bashrc 环境变量文件
$ cd /data/yashan/yasdb_home/yashandb/23.1.0.309/conf
# 如~/.bashrc中已存在YashanDB相关的环境变量,将其清除
$ cat yashandb.bashrc >> ~/.bashrc
$ source ~/.bashrc
Step4:修改sys用户口令
YashanDB 不提供系统初始口令,请通过 yasboot 工具设置集群内所有节点 sys 用户的密码。-n 指定一个新密码,且密码为 8 位以上包含 1 位数字,我这里将其设置为 “Yashan23.1”。
$ cd /home/yashan/install
$ ./bin/yasboot cluster password set -n Yashan23.1 -c yashandb

Step5:验证安装是否成功
- 执行查看数据库状态命令。
[yashan@JiekeXu install]$ ./bin/yasboot cluster status -c yashandb -d hostid | node_type | nodeid | pid | instance_status | database_status | database_role | listen_address | data_path -------------------------------------------------------------------------------------------------------------------------------------------------- host0001 | db | 1-1:1 | 110837 | open | normal | primary | 192.168.75.32:1688 | /data/yashan/yasdb_data/db-1-1 ----------+-----------+--------+--------+-----------------+-----------------+---------------+--------------------+--------------------------------
-
使用 yasboot 工具连接数据库,查看实例状态。
$ ./bin/yasboot sql -d sys/Yashan23.1@192.168.75.32:1688 YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64 Connected to: YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux SQL> select STATUS,VERSION from v$instance; STATUS VERSION ------------- ---------------------------------------------------------------- OPEN Enterprise Edition Release 23.1.0.309 x86_64 1 row fetched. SQL> SELECT database_name FROM v$database; DATABASE_NAME ---------------------------------------------------------------- yashandb 1 row fetched.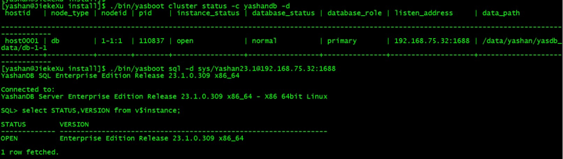
操作系统认证登录方式
yasql / as sysdba
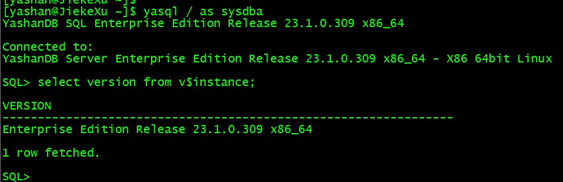
如连接报错,或执行SQL语句报错,请根据错误提示信息检查安装步骤,或咨询我们的技术支持。
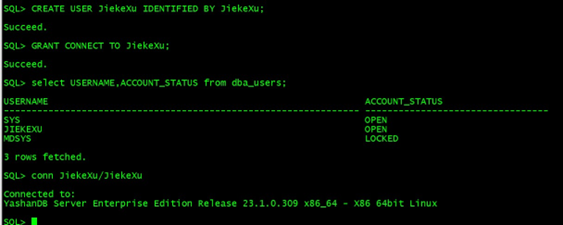
Step6:创建数据库用户(可选)
使用 yasql 工具连接数据库并创建 JiekeXu 用户。
$ ./bin/yasql sys/Yashan23.1@192.168.75.32:1688
SQL> CREATE USER JiekeXu IDENTIFIED BY JiekeXu;
SQL> GRANT CONNECT TO JiekeXu;
三、单机启停及开机自启动
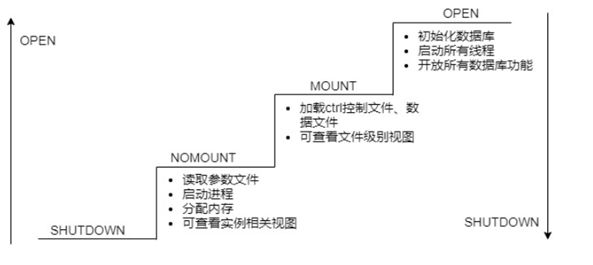
数据库实例从关闭启动到正常使用,要经过NOMOUNT、MOUNT 和 OPEN 三种状态,这一块和 Oracle 没有区别。
NOMOUNT:启动数据库实例, 此时读取参数文件,但是不加载数据库。
MOUNT:启动数据库实例,读取控制文件,加载数据库,但是数据库处于关闭状态。
OPEN:启动数据库实例,加载并打开数据库。
1、启停数据库实例
这里介绍 YashanDB 数据库的两种实例启停方式,分别为 SQL 命令方式和 OM 方式。数据库安装过程中将实例自动切换成 OPEN 状态,并创建名为 yashandb 的数据库。
SQL> SELECT i.status,d.database_name from v$instance i,v$DATABASE d where i.HOST_NAME=d.HOST_NAME;
STATUS DATABASE_NAME
------------- ----------------------------------------------------------------
OPEN yashandb
1 row fetched.
SQL命令方式
SQL 命令方式是于操作系统终端中执行 nohup yasdb 状态 & 命令的方式调整数据库实例状态。
执行如下命令可关闭并退出数据库:
SQL> SHUTDOWN; SQL> exit;
$ tail -90f /data/yashan/yasdb_home/yashandb/23.1.0.309/log/yashandb/db-1-1/run/run.log
2023-10-24 22:09:42.288 118589 [INFO] [DATABASE] start shuting down database
2023-10-24 22:09:42.337 110837 [INFO] [DATABASE] shutdown database, mode: shutdown normal
2023-10-24 22:09:42.530 110837 [INFO] [SESSION] wait for all sessions to end
2023-10-24 22:11:42.531 110837 [INFO] wait session: 0, handler: 24, name: release
-----这里一直在等待我登录的另一个会话断开
-----当退出另一个会话后,数据库实例立马关闭
2023-10-24 22:15:58.206 110837 [INFO] [DATABASE] reactor destroy
2023-10-24 22:15:58.206 110837 [INFO] [MMON] mmon thread exit
2023-10-24 22:15:58.211 110837 [INFO] [DATABASE] start database shutdown phase1
2023-10-24 22:15:58.324 110881 [INFO] [ARCH] arch data process exited
2023-10-24 22:15:58.324 110837 [INFO] [ARCH] arch data manager destroy success
2023-10-24 22:15:58.325 110837 [INFO] [DB] start full checkpoint, rcyBegin 0-2-6296-2221, flushpoint 0-2-6296-2221
2023-10-24 22:15:58.345 110837 [INFO] [DB] end full checkpoint, rcyBegin 0-2-6299-2222, flushpoint 0-2-6299-2222
2023-10-24 22:15:58.345 110837 [INFO] [DATABASE] database shutdown phase1 completed
2023-10-24 22:15:58.345 110837 [INFO] [ELECTION] stop election
2023-10-24 22:15:58.345 110837 [INFO] [DATABASE] replication module shutdown
2023-10-24 22:15:58.363 110837 [INFO] [HA] stop sender threads
2023-10-24 22:15:58.363 110837 [INFO] [HA] stop redo receiver 0
2023-10-24 22:15:58.370 110837 [INFO] [SCF] scfManager destroy succeed
2023-10-24 22:15:58.457 110903 [INFO] [MONITOR] health monitor process exited
2023-10-24 22:15:58.457 110837 [INFO] [MONITOR] health monit destroy success
2023-10-24 22:15:58.461 110880 [INFO] [ARCH] archive process exited
2023-10-24 22:15:58.465 110837 [INFO] [ARCH] archive manager destroy success
2023-10-24 22:15:58.470 110837 [INFO] [REDO] redo manager destroy success
2023-10-24 22:15:58.471 110837 [INFO] [SAVEPOINT] savepoint pool destroy success
2023-10-24 22:15:58.471 110837 [INFO] [XA] XA manager destroy success
2023-10-24 22:15:58.475 110837 [INFO] [XACT] XACT manager destroy success
2023-10-24 22:15:58.481 110837 [INFO] [TABLESPACE] tablespace manager destroy success
2023-10-24 22:15:58.483 110837 [INFO] [CTRL] ctrl manager destroy success
2023-10-24 22:15:58.483 110837 [INFO] [COAST] coast manager destroy success
2023-10-24 22:15:58.483 110837 [INFO] [ALLOCATOR] memory allocator destroy success
2023-10-24 22:15:58.484 110837 [INFO] [DB] kernel shutdown successfully
2023-10-24 22:15:58.487 110837 [INFO] [TIMER] timer stop success
2023-10-24 22:15:58.487 110837 [INFO] [PARAM] param context destroy success
2023-10-24 22:15:58.487 110837 [INFO] [SESSION_POOL] session pool destroy success
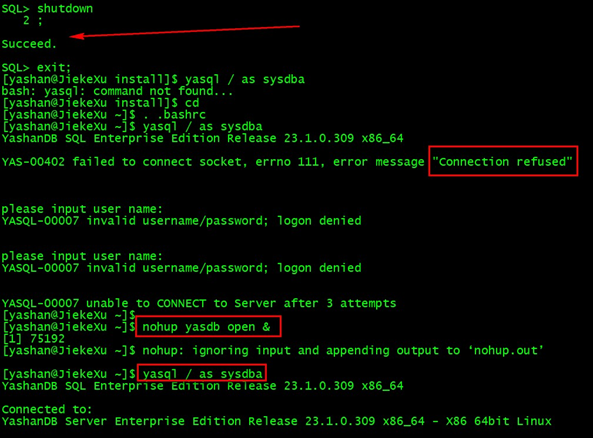
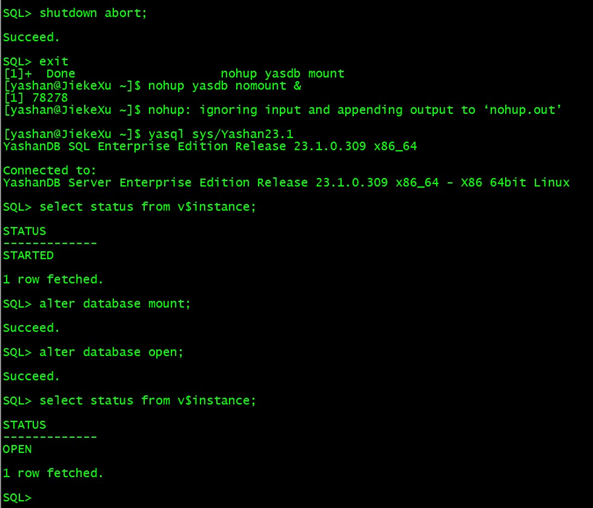
此时数据库实例为 SHUTDOWN 状态,无法通过 yasql 命令重新连接数据库,需先将实例切换至 OPEN 状态再进行连接:
$ nohup yasdb open &
执行如下命令将数据库实例切换为 MOUNT 状态或者也可以到 NOMOUNT 状态,你会发现和 Oracle 启停方式几乎没有差别,可以快速上手。
[yashan@JiekeXu ~]$ yasql / as sysdba
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> shutdown immediate; ##----采用 immediate 可立即关闭数据库,不用等待所有会话断开。
Succeed.
SQL> exit;
[yashan@JiekeXu ~]$ nohup yasdb mount &
[yashan@JiekeXu ~]$ yasql sys/Yashan23.1
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select status from v$instance;
STATUS
-------------
MOUNTED
SQL> alter database open; ##--从 mount 状态打开数据库
Succeed.
SQL> select status from v$instance;
STATUS
-------------
OPEN
SQL> shutdown abort;
Succeed.
SQL> exit
[1]+ Done nohup yasdb mount
[yashan@JiekeXu ~]$ nohup yasdb nomount &
[1] 78278
[yashan@JiekeXu ~]$ nohup: ignoring input and appending output to ‘nohup.out’
[yashan@JiekeXu ~]$ yasql sys/Yashan23.1
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select status from v$instance;
STATUS
-------------
STARTED
SQL> alter database mount;
Succeed.
SQL> alter database open;
Succeed.
SQL> select status from v$instance;
STATUS
-------------
OPEN
OM方式
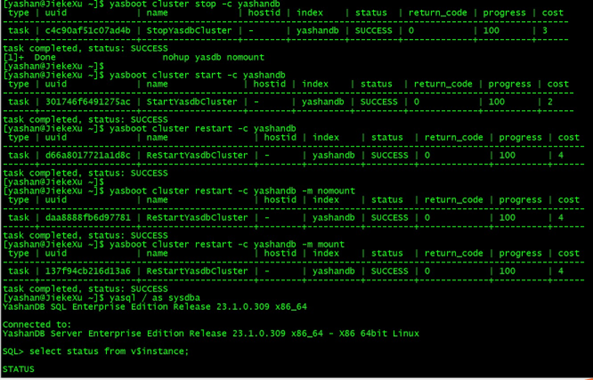
OM 方式是于操作系统终端中通过 yasboot 工具远端调整数据库实例状态。
- 执行如下命令关闭 YashanDB 服务,即将实例切换至 STOP 状态:
[yashan@JiekeXu ~]$ yasboot cluster stop -c yashandb type | uuid | name | hostid | index | status | return_code | progress | cost ---------------------------------------------------------------------------------------------------------- task | c4c90af51c07ad4b | StopYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 3 ------+------------------+------------------+--------+----------+---------+-------------+----------+------ task completed, status: SUCCESS [1]+ Done nohup yasdb nomount
- 执行如下命令开启 YashanDB 服务,即将实例切换至 OPEN 状态:
[yashan@JiekeXu ~]$ yasboot cluster start -c yashandb type | uuid | name | hostid | index | status | return_code | progress | cost ----------------------------------------------------------------------------------------------------------- task | 301746f6491275ac | StartYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 2 ------+------------------+-------------------+--------+----------+---------+-------------+----------+------ task completed, status: SUCCESS
- 执行如下命令重启 YashanDB 数据库,并重启至 OPEN 状态
[yashan@JiekeXu ~]$ yasboot cluster restart -c yashandb type | uuid | name | hostid | index | status | return_code | progress | cost ------------------------------------------------------------------------------------------------------------- task | d66a8017721a1d8c | ReStartYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 4 ------+------------------+---------------------+--------+----------+---------+-------------+----------+------ task completed, status: SUCCESS
- 执行如下命令重启 YashanDB 数据库,并重启至 NOMOUNT 状态:
[yashan@JiekeXu ~]$ yasboot cluster restart -c yashandb -m nomount type | uuid | name | hostid | index | status | return_code | progress | cost ------------------------------------------------------------------------------------------------------------- task | daa8888fb6d97781 | ReStartYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 4 ------+------------------+---------------------+--------+----------+---------+-------------+----------+------ task completed, status: SUCCESS
5)执行如下命令重启 YashanDB 数据库,并重启至 MOUNT 状态:
[yashan@JiekeXu ~]$ yasboot cluster restart -c yashandb -m mount
type | uuid | name | hostid | index | status | return_code | progress | cost
-------------------------------------------------------------------------------------------------------------
task | 137f94cb216d13a6 | ReStartYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 4
------+------------------+---------------------+--------+----------+---------+-------------+----------+------
task completed, status: SUCCESS
[yashan@JiekeXu ~]$ yasql / as sysdba
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select status from v$instance;
STATUS
-------------
MOUNTED
1 row fetched.
SQL> alter database open;
Succeed.
2、设置开机自启动
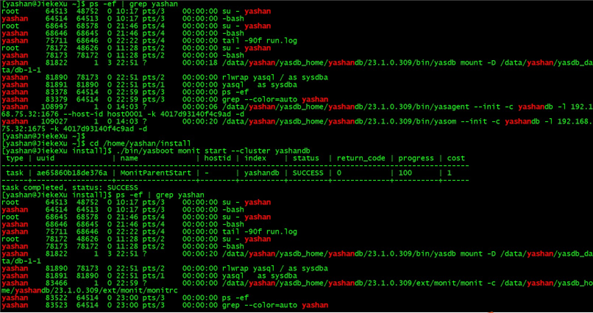
启动守护进程
守护进程用于持续监控 YashanDB 的各进程状态,并在进程异常时将其重新拉起。
如需启用此功能,以 yashan 用户登录至 192.168.75.32 服务器,并执行如下命令:
$ ps -ef | grep yashan
root 64513 48752 0 10:17 pts/3 00:00:00 su - yashan
yashan 64514 64513 0 10:17 pts/3 00:00:00 -bash
root 68645 68578 0 21:46 pts/4 00:00:00 su - yashan
yashan 68646 68645 0 21:46 pts/4 00:00:00 -bash
yashan 75711 68646 0 22:22 pts/4 00:00:00 tail -90f run.log
root 78172 48626 0 11:28 pts/2 00:00:00 su - yashan
yashan 78173 78172 0 11:28 pts/2 00:00:00 -bash
yashan 81822 1 3 22:51 ? 00:00:18 /data/yashan/yasdb_home/yashandb/23.1.0.309/bin/yasdb mount -D /data/yashan/yasdb_data/db-1-1
yashan 81890 78173 0 22:51 pts/2 00:00:00 rlwrap yasql / as sysdba
yashan 81891 81890 0 22:51 pts/1 00:00:00 yasql as sysdba
yashan 83378 64514 0 22:59 pts/3 00:00:00 ps -ef
yashan 83379 64514 0 22:59 pts/3 00:00:00 grep --color=auto yashan
yashan 108997 1 0 14:03 ? 00:00:06 /data/yashan/yasdb_home/yashandb/23.1.0.309/bin/yasagent --init -c yashandb -l 192.168.75.32:1676 --host-id host0001 -k 4017d93140f4c9ad -d
yashan 109027 1 0 14:03 ? 00:00:20 /data/yashan/yasdb_home/yashandb/23.1.0.309/bin/yasom --init -c yashandb -l 192.168.75.32:1675 -k 4017d93140f4c9ad -d
$ cd /home/yashan/install
$ ./bin/yasboot monit start --cluster yashandb
注册开机自启动
当服务器由于各种原因发生重启时,将守护进程到开机自启动,可以在系统重启后自动拉起 YashanDB 的各进程。
如需启用此功能,请以 yashan 用户登录至所有服务器,打开 /etc/rc.local 文件,并加入如下一行启动命令:
$ sudo vim /etc/rc.local
su - yashan -c '/data/yashan/yasdb_home/yashandb/23.1.0.309/ext/monit/monit -c /data/yashan/yasdb_home/yashandb/23.1.0.309/ext/monit/monitrc'
保存后退出,即完成注册开启自启动操作。
如用户选择不注册开机自启动功能,那么在服务器发生重启的情况下,需要执行如下手动拉起进程命令:
$ yasboot process yasom start -c yashandb
$ yasboot process yasagent start -c yashandb
在 yasom 和 yasagent 进程拉起后,才可执行数据库的启动命令:
$ yasboot cluster start -c yashandb
四、对比 Oracle 简单使用 YashanDB
1、表空间相关操作
表空间是数据库的逻辑存储结构,所有数据库对象均存储于指定的表空间内。
创建表空间
执行 CREATE TABLESPACE 语句创建表空间:
CREATE TABLESPACE yashan_tbs;
ALTER TABLESPACE yashan_tbs ADD DATAFILE;
--删除表空间,生产环境慎用。
-- DROP TABLESPACE yashan_tbs; --数据库层删除了,但操作系统层面仍然保留,和 Oracle 一样
默认会在 dbfiles 目录创建一个大小为 64M 的数据文件,也可以从 run.log 中看到路径: [TABLESPACE] succeed to create datafile /data/yashan/yasdb_data/db-1-1/dbfiles/YASHAN_TBS0。添加数据文件也是会生成一个 64M 大小的文件,且文件名默认大写,以序号 1,2,3,4 递增。
查看表空间
通过查询 DBA_TABLESPACES 视图查看当前数据库中存在的所有表空间:
SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES;
TABLESPACE_NAME
----------------------------------------------------------------
SYSTEM
SYSAUX
TEMP
SWAP
USERS
UNDO
YASHAN_TBS
7 rows fetched.
--其他查询表空间和数据文件命令,和 Oracle 几乎一样
select id,name,TS#,BLOCKS,BLOCK_SIZE,BYTES/1024/1024 M,STATUS from v$datafile;
select id,NAME,STATUS from v$tablespace;
select file_id,file_name from dba_data_files;
执行如下语句收缩表空间大小:
ALTER TABLESPACE yashan_tbs SHRINK SPACE;
执行此语句可将 yashan_tbs 表空间数据文件均缩小到 1M 大小。
[yashan@JiekeXu dbfiles]$ du -sh YASHAN_TBS* 64M YASHAN_TBS0 64M YASHAN_TBS1 --shrink space 之后 [yashan@JiekeXu dbfiles]$ du -sh YASHAN_TBS* 1.0M YASHAN_TBS0 1.0M YASHAN_TBS1
2、用户相关操作
创建用户
执行如下 SQL 命令创建新用户 yashan,并为其指定密码 yashan,语法和 Oracle 完全一样,查看所有用户也是一样的操作。
SQL> CREATE USER yashan IDENTIFIED BY yashan;
SQL> ALTER USER yashan IDENTIFIED BY "yashandb";
SQL> select username,account_status from dba_users;
USERNAME ACCOUNT_STATUS
----------------------------------------------------- ---------------------------------
SYS OPEN
YASHAN OPEN
JIEKEXU OPEN
MDSYS LOCKED
4 rows fetched.
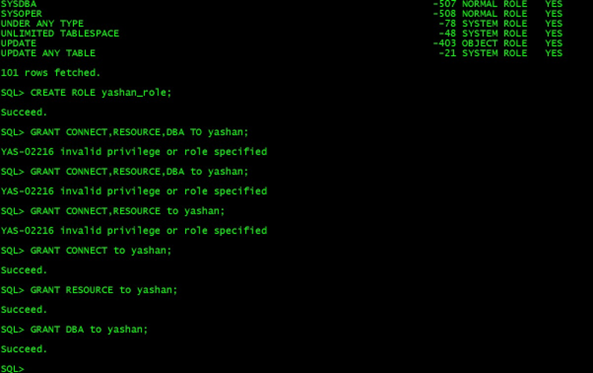
角色也和 Oracle 一样,我们创建用户可以给用户赋予相应的角色权限,当然也可以创建角色。
SQL> select * from dba_roles;
SQL> CREATE ROLE yashan_role;
SQL> GRANT CONNECT to yashan;
SQL> GRANT RESOURCE to yashan;
SQL> GRANT DBA to yashan;
查看用户相关表和视图
--这些视图和 Oracle 几乎一样,可直接使用。
select username,account_status from dba_users;
select * from dba_roles;
select * from dba_role_privs where granted_role='DBA';
#查看用户具有的权限
1、查询用户有哪些角色:
select * from dba_role_privs where grantee='&username';
2、查询角色包含哪些权限:
select * from role_sys_privs where role='&role';
3、查询用户系统权限:
select * from dba_sys_privs where grantee='&username';
select * from dba_tab_privs where grantee='&username';
3、表相关操作
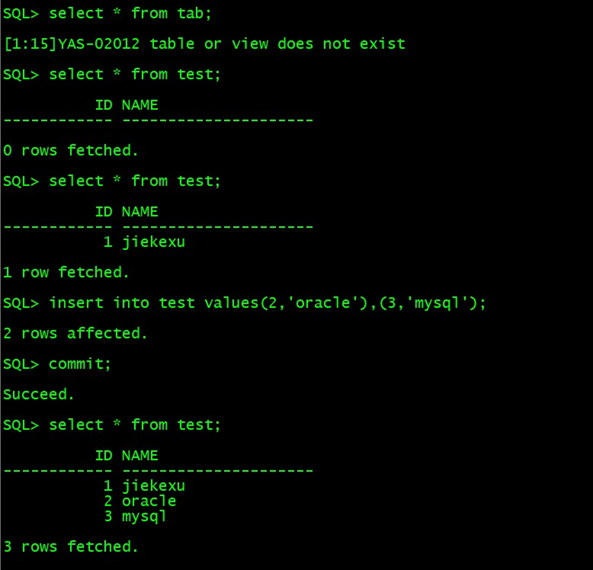
创建表、删除表,插入表数据,删除表数据,更新表数据,这都和 Oracle 一样,值得一提的是可一次性插入多行数据,这个功能在 Oracle 23c 才实现,其他数据库 PG、MySQL 中早就有这个功能了,感觉不错。
SQL> SELECT TABLE_NAME,TABLE_TYPE FROM USER_TABLES;
SQL> create table test(id int,name varchar2(20));
SQL> insert into test values(1,'jiekexu');
1 row affected.
SQL> commit;
Succeed.
---上面窗口 commit 才可以看到提交的一条数据
SQL> select * from test;
ID NAME
------------ ---------------------
0 rows fetched.
SQL> select * from test;
ID NAME
------------ ---------------------
1 jiekexu
1 row fetched.
--插入多行数据
SQL> insert into test values(2,'oracle'),(3,'mysql');
2 rows affected.
SQL> commit;
Succeed.
SQL> select * from test;
ID NAME
------------ ---------------------
1 jiekexu
2 oracle
3 mysql
-- 也存在虚拟表 dual
SQL> select 1+3 from dual;
1+3
---------------------
4
1 row fetched.
SQL> select sysdate from dual;
SYSDATE
--------------------------------
2023-10-25
SQL> set autotrace on
SQL> select count(*) from t1;
COUNT(*)
---------------------
11010048
Execution Plan
----------------------------------------------------------------
SQL hash value: 3866607212
Optimizer: ADOPT_C
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| Id | Operation type | Name | Owner | E - Rows | A - Rows | Cost(%CPU) | A - Time | Loops | Memory | Disk | Partition info |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | | | | | | |
| 1 | AGGREGATE | | | 1| | 103776( 0)| | | | | |
| 2 | TABLE ACCESS FULL | T1 | YASHAN | 11273766| | 103584( 0)| | | | | |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
Statistics
----------------------------------------------------------------------------------------------------
11 rows fetched.
4、归档日志相关操作
查看归档路径参数
--修改参数值,date_format 为需重启生效参数
SQL> ALTER SYSTEM SET date_format='yyyy-mm-dd hh24:mi:ss' scope=spfile;
SQL> show parameter ARCHIVE_LOCAL_DEST
--查看归档模式
SQL> SELECT database_name,log_mode,open_mode FROM v$DATABASE;
--修改归档路径
SQL> ALTER SYSTEM SET ARCHIVE_LOCAL_DEST='/data/yashan/archive' scope=spfile;
--强制切换
SQL> ALTER SYSTEM SWITCH LOGFILE;
--归档并进行切换(须处于归档模式否则返回错误)
SQL> ALTER SYSTEM ARCHIVE LOG CURRENT;
归档日志清理
--删除所有归档日志
ALTER DATABASE DELETE ARCHIVELOG ALL;
--删除包括2022-01-06 11:30:00之前的归档日志
ALTER DATABASE DELETE ARCHIVELOG until TIME TO_DATE('2023-10-26 11:30:00', 'yyyy-mm-dd hh24:mi:ss');
--删除序列号包括 100 号之前的归档日志
ALTER DATABASE DELETE ARCHIVELOG until SEQUENCE 100;
--强制归档清理
ALTER DATABASE DELETE ARCHIVELOG ALL FORCE;
----------直接清理时需要备份才能删除--------------------------------------
SQL> ALTER DATABASE DELETE ARCHIVELOG until TIME TO_DATE('2023-10-27 11:30:00', 'yyyy-mm-dd hh24:mi:ss');
YAS-02386 expected to delete the archived logs until sequence 40, but failed when deleting sequence 1
YAS-02385 archived log /data/yashan/yasdb_data/db-1-1/archive/arch_0_1.ARC not deleted, needed for backup
SQL> ALTER DATABASE DELETE ARCHIVELOG until TIME TO_DATE('2023-10-27 11:30:00', 'yyyy-mm-dd hh24:mi:ss') FORCE;
YAS-02386 expected to delete the archived logs until sequence 40, but failed when deleting sequence 1
YAS-02385 archived log /data/yashan/yasdb_data/db-1-1/archive/arch_0_1.ARC not deleted, needed for backup
SQL> ALTER DATABASE DELETE ARCHIVELOG ALL FORCE;
Succeed.
5、参数管理
参数文件名为 yasdb.ini,为文本文件,存放在 $YASDB_DATA/config 路径下,产品安装时所指定的数据库初始配置参数将保存在此文件中,后续数据库运行过程中对配置参数的非 memory 修改也将持久化到此文件中。YashanDB 的所有系统参数都存在一个默认值,允许在产品安装后不做任何处理也能启动实例。默认值一般基于在个人 PC 也能运行的最小配置给出,可能并不适用于生产环境,因此建议在安装 YashanDB 时也进行参数的初始化配置工作 。YashanDB 提供参数自适应功能,依据环境信息给出针对当前负载的调参配置推荐。
--选择无业务运行的时间,并清理其他进程,避免干扰对资源的计算和测试
--使用默认参数生成推荐参数,不写入配置文件。
EXEC DBMS_PARAM.OPTIMIZE();
--使用TAC表类型,分配80%的内存,100%的CPU,生成推荐参数后,写入配置文件。
EXEC DBMS_PARAM.OPTIMIZE(True, 'TAC', 80);
--使用默认的HEAP表类型,分配100%的内存,100%的CPU,生成推荐参数后,不写入配置文件。
EXEC DBMS_PARAM.OPTIMIZE(NULL, NULL, 100, 100);
--使用LSC表类型,分配100%的内存,100%的CPU,指定datafile和redofile的路径,生成推荐参数后,不写入配置文件。
EXEC DBMS_PARAM.OPTIMIZE(NULL,'LSC',NULL,NULL,'/home/yashan/data','/home/yashan/redo');
--查看最新的推荐参数信息
SELECT DBMS_PARAM.SHOW_RECOMMEND() FROM dual;
--将推荐的参数配置写入 yasdb.ini文件,此过程并不会生效参数。
EXEC DBMS_PARAM.APPLY_RECOMMEND();
--查看参数
show parameter DATA_BUFFER_SIZE
--修改参数并重启数据库
alter system set DATA_BUFFER_SIZE=2G scope=spfile;
alter system set VM_BUFFER_SIZE=2G scope=spfile;
shutdown immediate;
exit
nohup yasdb open &
scope 用于设定对配置参数修改后的生效方式,默认为both。
spfile:将参数值写入参数文件,需重启才能生效。
memory:将参数值写入内存,立即生效,但重启后失效。
both:将参数值同时写入内存和参数文件,立即生效,重启后也生效。
可以看出,参数管理这块也和 Oracle 差不多,类似于 Oracle 的 pfile 文件,看来暂时没有 spfile 参数。但是提供了上面展示的参数自适应功能,这里就不配置了,仅展示一下,接下来我们介绍一下我们上面手动修改的 DATA_BUFFER_SIZE 和 VM_BUFFER_SIZE 这两个参数的含义。
DATA_BUFFER_SIZE:数据缓存区的大小,该值对数据库的性能表现至关重要,合理的缓存区配置将有效降低IO的开销。
该参数设置过小可能会出现启动或建库失败,最小值近似公式:(UNDO_SEGMENTS * 99 + 1K)*DB_BLOCK_SIZE,计算时 UNDO_SEGMENTS 最小取 64(该值还可能和某些隐藏参数有关联)。
**VM_BUFFER_SIZE:**VM 用于保存数据运算的中间结果,例如 order by,group by。如对其配置过小,将容易导致频繁的 VM 换入换出(产生IO)。
6、数据插入读取对比
接下来我们关闭此 Yashan 数据库打开以前安装的 Oracle 数据库,查看插入统计以及多表关联的情况。
[oracle@JiekeXu dbs]$ $ORACLE_HOME/OPatch/opatch lspatches
30138470;Database Oct 2019 Release Update : 12.2.0.1.191015 (30138470)
[oracle@JiekeXu dbs]$ sys
SQL*Plus: Release 12.2.0.1.0 Production on Fri Oct 27 17:27:35 2023
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SYS@JiekeXu> show parameter sga_max_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 2G
SYS@JiekeXu> show parameter pga_aggre
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_limit big integer 2G
pga_aggregate_target big integer 16M
SYS@JiekeXu> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED MOUNTED
3 JIEKEXUPDB READ WRITE NO
4 JIEKEXUPDB1 READ WRITE NO
SYS@JiekeXu> alter session set container=JIEKEXUPDB1;
SYS@JiekeXu> select count(*) from dba_objects;
COUNT(*)
----------
74071
上面展示信息 Oracle 补丁为 19 年 10 月份的,sga 内存配置为 2GB,其他参数均为默认,使用 PDB 模式,查看 dba_objects 有 74071 个对象,我们基于这个对象构建两个表,一个大表一个小表,并将其导出导入到 Yashan 数据库进行同样的操作进行对比。
SYS@JiekeXu> grant connect,resource,dba to test;
SYS@JiekeXu> conn test/test@JIEKEXUPDB1
TEST@JIEKEXUPDB1> create table T_base_table as select * from dba_objects;
TEST@JIEKEXUPDB1> select count(*) from t_base_table;
COUNT(*)
----------
74071
TEST@JIEKEXUPDB1> set long 9999
TEST@JIEKEXUPDB1> SELECT DBMS_METADATA.GET_DDL('TABLE','T_BASE_TABLE','TEST') DDL_SQL FROM DUAL;
--我们将其结果集导出成 sql 文本并在 Yashan 数据库进行建表插入数据
CREATE TABLE "T_BASE_TABLE"
( "OWNER" VARCHAR2(128),
"OBJECT_NAME" VARCHAR2(128),
"SUBOBJECT_NAME" VARCHAR2(128),
"OBJECT_ID" NUMBER,
"DATA_OBJECT_ID" NUMBER,
"OBJECT_TYPE" VARCHAR2(23),
"CREATED" DATE,
"LAST_DDL_TIME" DATE,
"TIMESTAMP" VARCHAR2(19),
"STATUS" VARCHAR2(7),
"TEMPORARY" VARCHAR2(1),
"GENERATED" VARCHAR2(1),
"SECONDARY" VARCHAR2(1),
"NAMESPACE" NUMBER,
"EDITION_NAME" VARCHAR2(128),
"SHARING" VARCHAR2(18),
"EDITIONABLE" VARCHAR2(1),
"ORACLE_MAINTAINED" VARCHAR2(1),
"APPLICATION" VARCHAR2(1),
"DEFAULT_COLLATION" VARCHAR2(100),
"DUPLICATED" VARCHAR2(1),
"SHARDED" VARCHAR2(1),
"CREATED_APPID" NUMBER,
"CREATED_VSNID" NUMBER,
"MODIFIED_APPID" NUMBER,
"MODIFIED_VSNID" NUMBER
);
--将 Oracle 中导出的 t_base_table _insert.sql 文件上传至崖山数据库,然后创建对应的表插入数据。
SQL> @t_base_table _insert.sql
SQL> commit;
Succeed.
SQL> select count(*) from t_base_table;
COUNT(*)
---------------------
74071
1 row fetched.
接下来我们进行一个简单的插入和表关联对比。为了避免影响,同一时刻只有一个数据库是启动状态的,现在我们在 Oracle 中进行插入数据。
create table T_BIG_TABLE as select * from T_BASE_TABLE;
create table T_SMALL_TABLE as select * from T_BASE_TABLE;
begin
for i in 1..8 loop
insert into T_BIG_TABLE select * from T_BIG_TABLE;
end loop;
commit;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:01:56.90
TEST@JIEKEXUPDB1> select count(*) from T_BIG_TABLE;
COUNT(*)
----------
18962176
Elapsed: 00:00:14.92
begin
for i in 1..5 loop
insert into T_SMALL_TABLE select * from T_SMALL_TABLE;
end loop;
commit;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:23.06
TEST@JIEKEXUPDB1> select count(*) from T_SMALL_TABLE;
COUNT(*)
----------
2370272
Elapsed: 00:00:01.17
TEST@JIEKEXUPDB1> SELECT COUNT(*) from T_SMALL_TABLE t1,T_BIG_TABLE t2 where t1.object_id=t2.object_id;
COUNT(*)
----------
606781440
Elapsed: 00:00:29.88
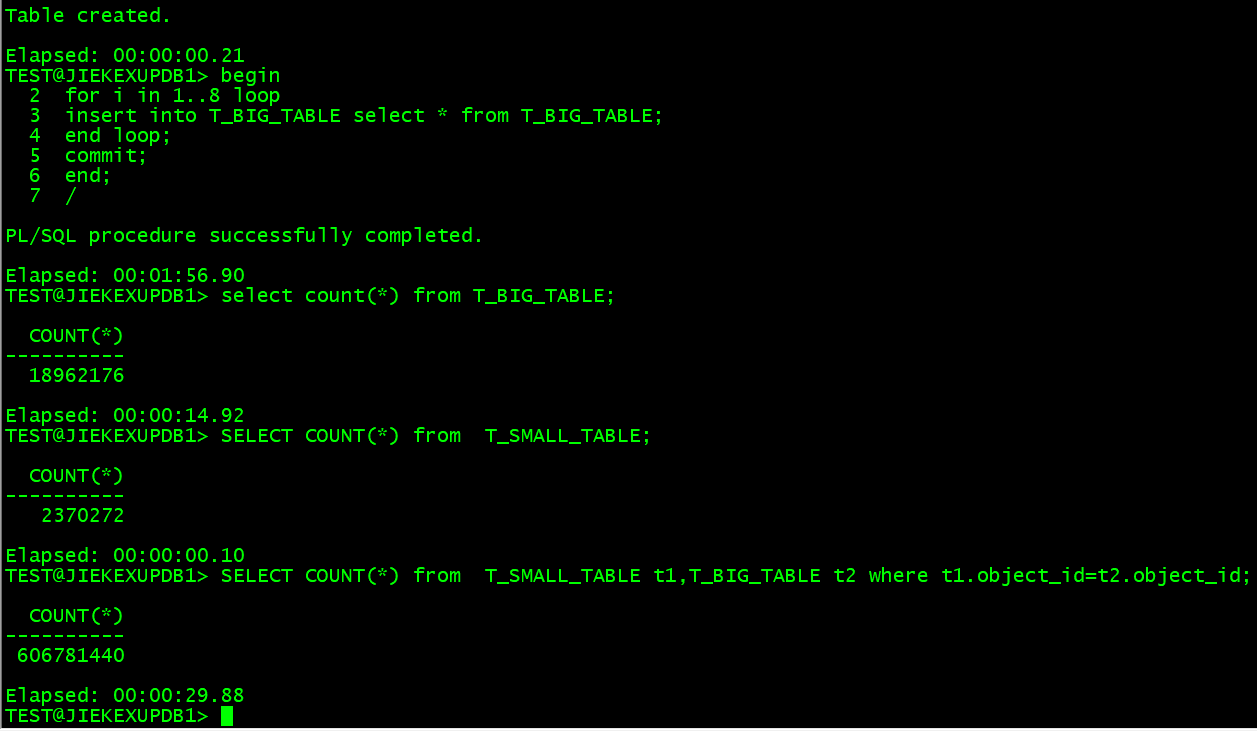
从上面可以看出来在 Oracle 12c 中大表 T_BIG_TABLE 插入 1896W 条数据需要 116.9 秒,count 统计需要 14.92 秒,小表 T_SMALL_TABLE 插入 237W 需要 23.06 秒,count 统计需要 1.17 秒;两表关联查询需要 29.88 秒。注意这里的查询时间均为第一次查询时间,由于缓存和统计信息等的因素可能和实际执行时间有所区别。接下来我们关闭 Oracle 数据库,重启操作系统,启动 Yashan 数据库。
--YashanDB 操作示例
create table T_BIG_TABLE as select * from T_BASE_TABLE;
create table T_SMALL_TABLE as select * from T_BASE_TABLE;
SELECT database_name,log_mode,open_mode FROM v$DATABASE;
begin
for i in 1..8 loop
insert into T_BIG_TABLE select * from T_BIG_TABLE;
end loop;
commit;
end;
/
PL/SQL Succeed.
Elapsed: 00:01:31.284
SQL> select count(*) from T_BIG_TABLE;
COUNT(*)
---------------------
18962176
1 row fetched.
Elapsed: 00:00:02.295
begin
for i in 1..5 loop
insert into T_SMALL_TABLE select * from T_SMALL_TABLE;
end loop;
commit;
end;
/
PL/SQL Succeed.
Elapsed: 00:00:09.198
SQL> select count(*) from T_SMALL_TABLE;
COUNT(*)
---------------------
2370272
1 row fetched.
Elapsed: 00:00:00.083
SQL> SELECT COUNT(*) from T_SMALL_TABLE t1,T_BIG_TABLE t2 where t1.object_id=t2.object_id;
COUNT(*)
---------------------
606781440
1 row fetched.
Elapsed: 00:01:34.713
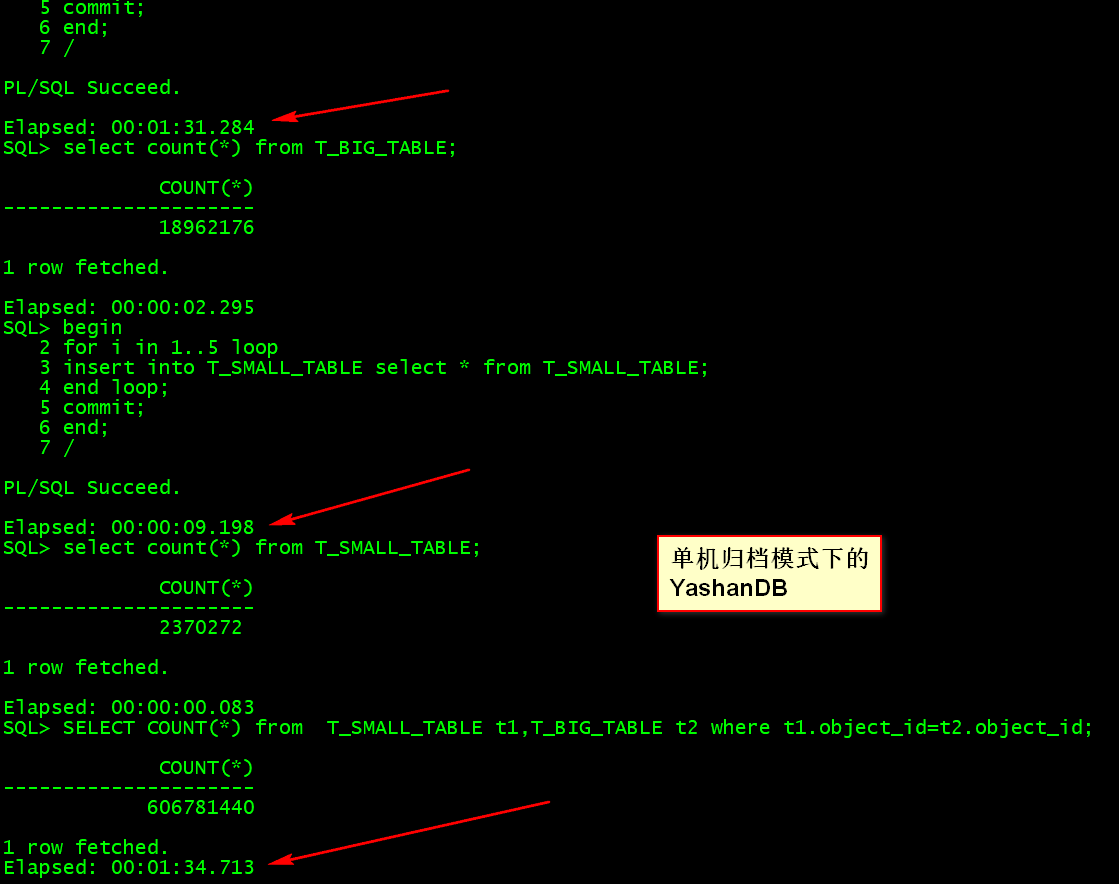
从上面结果可以看出来在 Yashan 23.1 中大表 T_BIG_TABLE 插入 1896W 条数据需要 91.284 秒,count 统计需要 2.295 秒,小表 T_SMALL_TABLE 插入 237W 需要 9.198 秒,count 统计需要 0.083 秒;但是两表关联查询需要 94.713 秒。下面我做了一个简单的对比表格可以明显的看看。
| 统计对比(单位为秒) | Oracle 12c | YashanDB23.1 | 备注 |
|---|---|---|---|
| 插入1896W T_BIG_TABLE | 116.90s | 91.284s | Y |
| Count(*) T_BIG_TABLE | 14.92s | 2.295s | Y |
| 插入 237W T_SMALL_TABLE | 23.06s | 9.198s | Y |
| Count(*) T_SMALL_TABLE | 1.17s | 0.083s | Y |
| 两表关联查询 | 29.88s | 94.713s/22.590s | O |
上述结果反馈崖山厂商后,说可以优化加 hint 指定走列执行引擎会变快,那么我们来试试吧。亲身体验才有发言权,如下,我们先收集一下两个表的统计信息,然后可以通过 explain 或者 set autotrace on 查看执行计划,然后我们通过添加 HINT 发现执行两表关联查询时间比 Oracle 还快,执行时间在 22.590s 左右,这点让人很意外,另外官方也介绍在今天的个人版发布前会优化掉这个问题,这样就不用添加 HINT 也会很快了。
SQL> show parameter COLUMNAR_VM_BUFFER_SIZE
NAME VALUE
---------------------------------------------------------------- ----------------------------------------------------------------
COLUMNAR_VM_BUFFER_SIZE 2G
SQL> exec DBMS_STATS.GATHER_TABLE_STATS('YASHAN', 'T_BIG_TABLE', null, 0.1, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'ALL', TRUE);
PL/SQL Succeed.
Elapsed: 00:00:22.316
SQL> exec DBMS_STATS.GATHER_TABLE_STATS('YASHAN', 'T_SMALL_TABLE', null, 0.1, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'ALL', TRUE);
PL/SQL Succeed.
Elapsed: 00:00:05.518
SQL> set autotrace on
SQL> SELECT /*+ ENGINE_COL */ COUNT(*) FROM T_SMALL_TABLE T1,T_BIG_TABLE T2 WHERE t1.object_id=t2.object_id;
COUNT(*)
---------------------
606781440
Execution Plan
----------------------------------------------------------------
SQL hash value: 2264754326
Optimizer: ADOPT_C
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| Id | Operation type | Name | Owner | E - Rows | A - Rows | Cost(%CPU) | A - Time | Loops | Memory | Disk | Partition info |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | | | | | | |
| 1 | COL TO ROW | | | 1| | 1965795( 0)| | | | | |
| 2 | AGGREGATE | | | 1| | 1965795( 0)| | | | | |
|* 3 | HASH JOIN INNER | | | 465667168| | 1957875( 0)| | | | | |
| 4 | TABLE ACCESS FULL | T_BIG_TABLE | YASHAN | 19232200| | 1948179( 0)| | | | | |
| 5 | TABLE ACCESS FULL | T_SMALL_TABLE | YASHAN | 2374089| | 3007( 0)| | | | | |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
Operation Information (identified by operation id):
---------------------------------------------------
1 - Projection: RemoteTable[2][BIGINT]
2 - Projection: COUNT(1)[BIGINT]
3 - Predicate : access(Tuple[0, 0] = Tuple[1, 0])
4 - Projection: Tuple[0, 3][NUMBER]
5 - Projection: Tuple[0, 3][NUMBER]
Statistics
----------------------------------------------------------------------------------------------------
23 rows fetched.
Elapsed: 00:00:22.921
SQL> set autotrace off
SQL> SELECT /*+ ENGINE_COL */ COUNT(*) FROM T_SMALL_TABLE T1,T_BIG_TABLE T2 WHERE t1.object_id=t2.object_id;
COUNT(*)
---------------------
606781440
1 row fetched.
Elapsed: 00:00:22.590
SQL> explain SELECT /*+ ENGINE_COL */ COUNT(*) FROM T_SMALL_TABLE T1,T_BIG_TABLE T2 WHERE t1.object_id=t2.object_id;
PLAN_DESCRIPTION
----------------------------------------------------------------
SQL hash value: 2264754326
Optimizer: ADOPT_C
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) | Partition info |
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | |
| 1 | COL TO ROW | | | 1| 1570019( 0)| |
| 2 | AGGREGATE | | | 1| 1570019( 0)| |
|* 3 | HASH JOIN INNER | | | 465667168| 1562099( 0)| |
| 4 | TABLE ACCESS FULL | T_BIG_TABLE | YASHAN | 19232200| 1552403( 0)| |
| 5 | TABLE ACCESS FULL | T_SMALL_TABLE | YASHAN | 2374089| 3007( 0)| |
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
Operation Information (identified by operation id):
---------------------------------------------------
1 - Projection: RemoteTable[2][BIGINT]
2 - Projection: COUNT(1)[BIGINT]
3 - Predicate : access(Tuple[0, 0] = Tuple[1, 0])
4 - Projection: Tuple[0, 3][NUMBER]
5 - Projection: Tuple[0, 3][NUMBER]
22 rows fetched.
Elapsed: 00:00:00.000
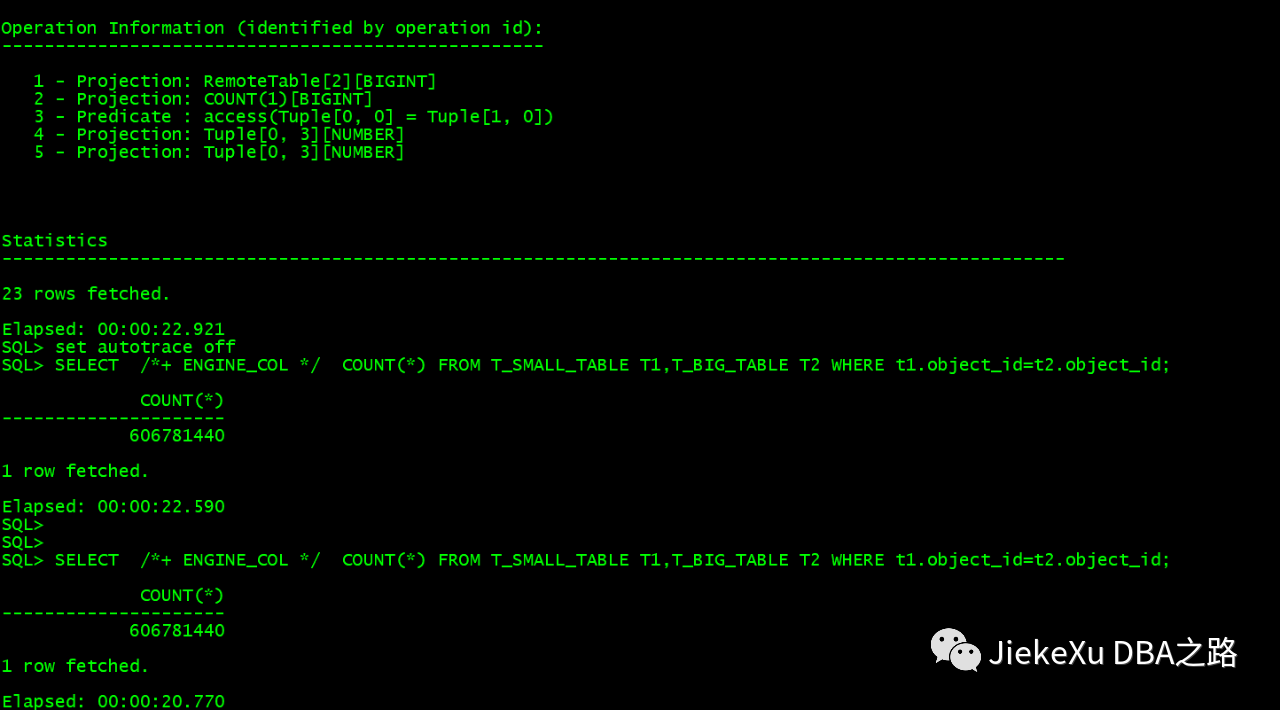
总结:通过上面表格对比发现,YashanDB 还是很强大的,对于简单的汇总查询以及数据的插入操作,YashanDB 是完全可以胜任的,像多表关联查询,Yashan 数据库提供了丰富的优化方案,还是挺让人惊喜的。Oracle 强大的优化器让其他数据库望尘莫及,这一点毋庸置疑不可否认,这里只是简单的测试了两表关联的查询性能,还有太多太多场景没有测试,感兴趣的小伙伴可以自行测试。最后,不仅仅是 YashanDB,我们的其他国产数据库任然需要努力,在优化器上多多下功夫。崖山数据库在 Oracle 兼容性方面做的还是很不错的,包括数据库管理、表空间管理、很多“V$” 和“GV$”系统视图,"DBA_"和“ALL_"和“USER_”系统视图均和 Oracle 无太多差别,这让很多 Oracle DBA 们能够快速上手,能尽快了解掌握这款国产数据库。
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

