





论文链接:
https://arxiv.org/pdf/2207.07940.pdf
内存中近似最近邻搜索(ANNS)算法在快速高查全率查询处理方面取得了巨大成功,但在处理具有非结构化(特征向量)和结构化(相关属性)约束的混合查询时效率极低。在本文中,作者提出了HQANN,一个简单而高效的混合查询处理框架,可以很容易地嵌入到现有的基于接近图的ANNS算法中。本文利用属性间的导航感知,将向量相似度搜索与属性过滤相融合,保证了低延迟和高召回率。在公共和内部数据集上的实验结果表明,在达到相同的召回质量时,HQANN比最先进的混合ANNS解决方案快10倍,并且其性能几乎不受属性复杂性的影响。在具有数千个属性约束的GLOVE-1.2M上,它可以在大约50微秒内达到99% recall@10。
算法介绍
Vector Search
作者认为融合距离度量混合查询处理的关键是定义一个有效的距离度量,便于对属性进行分析。以融合的距离函数为基本前提,可以在不侵犯原始执行流程的情况下构造和检索基于接近图的复合索引。
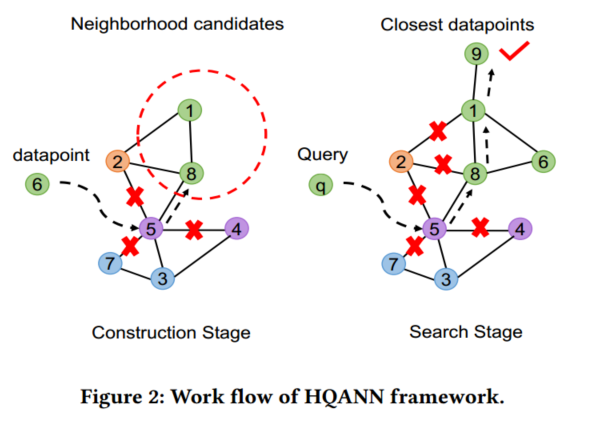
HQANN的基本思想是通过特征向量距离对属性距离进行微调来获得融合距离度量。具体来说,两个混合数据点之间的距离主要由它们的属性距离来定义,它们的特征向量距离作为一个调整因子,对融合距离的影响有限。在接近图的构建阶段,具有相同或非常相似属性的数据点将首先被链接,因为它们与我们的候选数据点相比往往具有更小的距离。然后,剩余的邻域空缺将被属性相对较远的数据点填充,这强有力地保持了图的连通性。
在搜索阶段,混合查询遍历图,直到到达具有相同属性的第一个节点,通过完全扫描节点的邻域,可以有效地访问高质量的返回候选列表。
距离函数定义:给定一个混合数据集𝑆,其中m维特征向量数据空间𝑋和n维属性数据空间V,则两个混合数据点𝑠i,𝑠𝑗∈𝑆之间的融合距离可表示为:
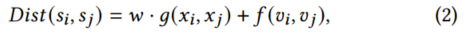
其中:g(.)与f(.)分别表示特征向量和属性的距离函数,可以表示任何常用的矢量距离度量。本文中f(.)要满足以下条件:
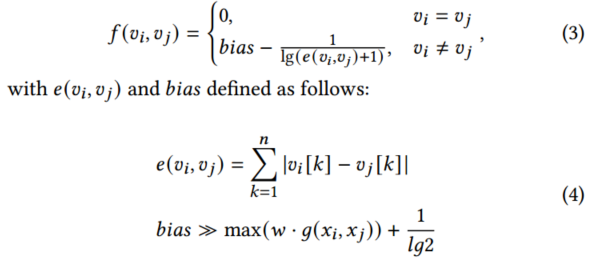
本文中g(.)采用如下定义:
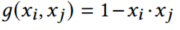
实验结果
Vector Search
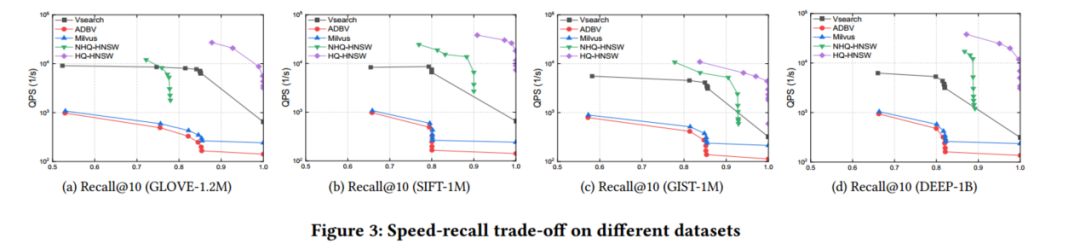
在四个公共数据集上的性能结果如图3所示。它表明,在所有四个数据集上,HQANN在速度和召回率(向上和向右更好)方面明显优于竞争方法,并且它可以在所有数据集上获得99%的召回。特别是,HQANN在达到良好的召回质量(95%)方面比其他方法快十倍以上。
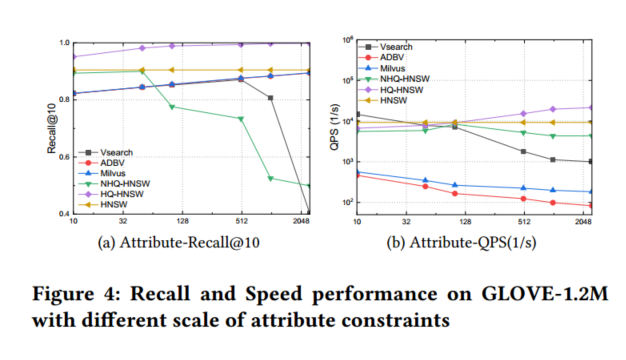
然后,作者在GLOVE-1.2M上进行了实验,比较了其与现有混合ANNS方案的鲁棒性,作者逐渐将属性约束的数量从10个增加到2500个,详细的结果如图4所示。HQANN可以保持非常高的召回质量(超过95% Recall@10),并且随着属性约束变得更复杂,其效率也会提高。向量相似性搜索可以从属性约束中获得延迟和召回的好处。例如,对于2500个属性约束,复合图的速度提高了两倍,召回率提高了10%
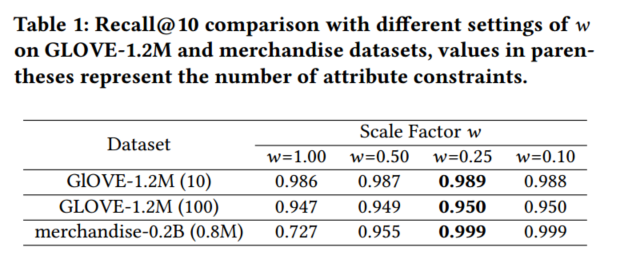
最后,作者选择了一些典型的场景来证明不需要针对特定的数据集调整HQANN的这些超参数。实验证明了进一步缩小𝑤不会导致召回增加,这意味着𝑤= 0.25是一个合适的临界点来对准两个距离部分的比例。
总结
Vector Search
本文提出了一种新的混合查询处理框架——HQANN。新框架利用属性约束之间的导航感知,产生一种融合距离度量,可以灵活地嵌入到基于接近图的ANNS算法中。实验结果表明,与现有的混合查询方案相比,HQANN在检索召回率和效率方面表现出了更好的性能。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

