





随着商业智能、数据科学等领域的数据发掘和应用需求深化,将数据湖和大数据平台整合为一个协同工作的整体成为大数据领域的重要趋势,来更好地满足企业对海量多模数据的实时处理与分析需求。
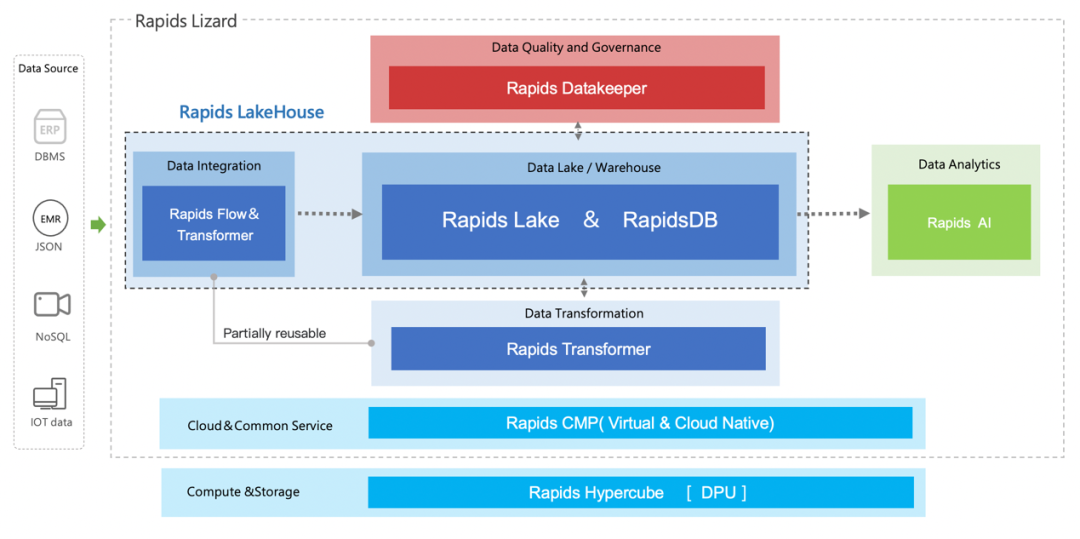

在柏睿大数据平台上,柏睿一体化流湖仓具备如下优势特性:
柏睿大数据平台能够充分发挥柏睿一体化流湖仓的上述优势价值,在于其深度融合了柏睿一体化流湖仓的两大关键组件——数据湖、Transformer。
数据湖是柏睿一体化流湖仓的底层数据存储,为企业客户构建成本高效、性能卓越的统一数据存储提供了开放性的成熟技术方案。
数据湖为数仓和流数据引擎提供针对多源异构海量数据的存储空间,具有以下特点:
01. 存算分离,摆脱对Hadoop的强依赖。
柏睿数据湖支持使用S3或者Hadoop 3(单独或混合使用均可)作为主要存储技术。通过存算分离,柏睿数据湖中的YARN仅作为兼容性运算服务,在用户需要YARN作为底层运算服务框架进行应用部署时提供。
02. 统一元数据目录,隐藏了底层存储技术的实现方法。
柏睿数据湖采用Hive Metastore作为数据湖表格数据的统一元数据目录,并增加了对Iceberg开放文件协议集成支持。统一的元数据服务层,使得数据湖表格的底层存储技术和存储位置可与数仓访问解耦,因此数据湖存算架构的扩展更容易。同时,作为数仓部分RapidsDB通过数据联邦功能中的Hive和Iceberg连接器即可快速便捷的访问统一的各类底层数据。
03. 支持HDFS、S3等分布式文件系统的对象存储,提供无限扩展能力。
04. 支持数据增删改(事务)功能。
柏睿一体化流湖仓结合Iceberg的事务支持能力,在数据湖全范围提供分析性表格的批量事务支持,使全功能数据管理操作在数据湖内成为可能,避免受限于HDFS存储服务“append only”的数据读写方式。
05. 支持对结构化、半结构化、非结构化数据的集成、处理和分析。
柏睿数据湖基于自研数据集成工具Transformer等产品,可为结构化、半结构化、非结构化和标准机器学习模型等入湖数据提供高性能、高效率的透明操作支持,并利用各种工具对这些数据进行后续处理和分析。
06. ETL引擎湖内按需运算、精炼,汇总数据,打造专业数据产品。
柏睿数据湖支持用户在湖内按需自助建模,及对湖内数据进行各种转换、合并分析操作,逐步生成经过精炼和汇总处理后的数据,并最终形成各种形式的、可对外发布的专业数据产品。
07. 湖内海量数据和ELT引擎,为AI特征库提供大规模可用数据和按需转换数据的运算引擎。
柏睿数据湖形成了一个整合企业全域海量数据的统一平台,可为基于数据湖的数仓提供高度结构化的海量分析数据,同时也为当下备受关注的AI分析提供海量基础数据。用户能够利用Transformer将算法模型所需要的数据,按需转换为训练模型所需的特征数据,并利用统一调度工具来调度模型训练和更新。
08. 统一元数据管理工具,保障数据质量和数据权威性。
Transformer是一个流批一体的数据集成工具,为数据工程师提供高性能、多样化的数据同步解决方案。基于Transformer,柏睿一体化流湖仓产品能够助力用户将多源异构数据以精准的方式同步到目标平台,同时在同步时效性和吞吐性能之间实现最佳平衡。
01. 连接多种异构数据源,支持数据源表结构变化。
02. 流批结合,对数据源可以采用CDC或批处理方式进行数据ELT同步,CDC同步方式近实时同步原始数据,能精确捕捉数据源事务变化。
03. 支持批量同步,提供高性能数据提取、加载能力。
04. 支持在目标平台库内高效按需自助建模,以及在库内、湖内高性能按需转换,为自助数据分析服务提供底层数据处理能力。
05. 支持镜像模式与历史模式两种同步方式。
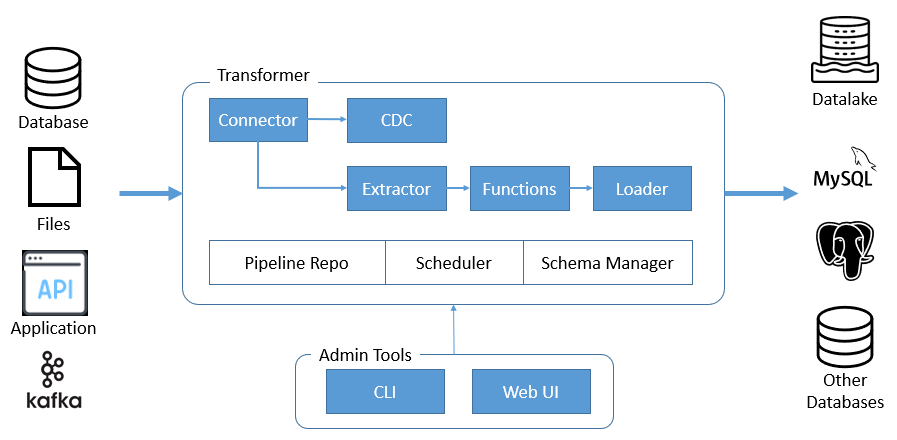
具体通过以下功能实现:
连接器
Transformer以连接器的形式为不同的数据源提供提取、加载的功能支持。每一个连接器根据数据源的性质会对提取或者写入有不同的支持能力和实现方式。
同步工作方式
Transformer采用ELT数据同步方式,来最大程度确保得到的数据格式源端一致,从而允许数据建模可以按照业务需要灵活执行。在保持ELT架构灵活性的同时,也为用户提供在数据源定义提取范围时对提取字段进行筛选的功能,让ELT更加贴近用户实际工作需要。
同步数据格式
Transformer产品为多源异构数据提供高性能的数据集成功能。从数据源提取的数据,可以自动匹配、加载到对应数据类型的同构或异构的目标平台。
远程管理工具
未来,柏睿大数据平台也将基于全体系数据智能产品,朝着更加高性能、智能化、安全可靠、灵活部署的方向发展,满足企业不断增长的多元化、智能化数据处理及应用需求,助力AI大模型时代加速到来。
推荐阅读



你的 在看 为智能数据算力点赞
