




0►
前言
之前我们有出过一篇文章知识图谱与大模型:微调 Vs. RAG介绍给大模型注入知识的两种方法,就目前而言如果我们想往大模型里边注入知识,最先能想到的就是对大模型进行微调。笔者曾实验过,只用几十万量级的数据对大模型进行微调并不能很好的将额外知识注入大模型,笔者在算力这方面囊中羞涩,只有4块卡,这几十万量级的数据训练6B的模型都要训练好几天。。。
如果不微调的话,其实还是可以利用外挂数据库的方式让大模型利用额外的知识的,比如向量数据库或者是图数据库,本文主要讲解大模型如何外挂向量数据库,外挂图数据库如果之后有时间,实践之后再分享出来。
我们知道,大模型有很好的根据上文来回答问题的能力。我们假设一个场景,我有个问题是:“请给我介绍一下万能青年旅店这支乐队“(假设模型内部并没有存储万青的相关信息),然后我有个100w字的文档,里边包含了世界上所有乐队的介绍。如果模型对无限长的输入都有很好的理解能力,那么我可以设计这样一个输入“以下是世界上所有乐队的介绍:[插入100w字的乐队简介文档],请根据上文给我介绍一下万青这支乐队”,让模型来回答我的问题。但模型支持的输入长度是很有限的,比如chatgpt支持4000长度的输入。实际上,如果想让大模型根据文档来回答问题,必须要精简在输入中文档内容的长度。
一种做法是,我们可以把文档切成若干段,只将少量的和问题有关的文档片段拿出来,放到大模型的输入里。至此,”大模型外挂数据库“的问题转换成了“文本检索的问题”了,目标是根据问题找出文档中和问题最相关的片段,这已经和大模型本身完全无关了。
文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化(通过语言模型,如bert等),然后存到向量数据库(如Annoy、 FAISS、hnswlib等)里边,来了一个问题之后,也对问题语句进行向量话,以余弦相似度或点积等指标,计算在向量数据库中和问题向量最相似的top k个文档片段,作为上文输入到大模型中。向量数据库都支持近似搜索功能,在牺牲向量检索准确度的情况下,提高检索速度。完整流程图如下所示。
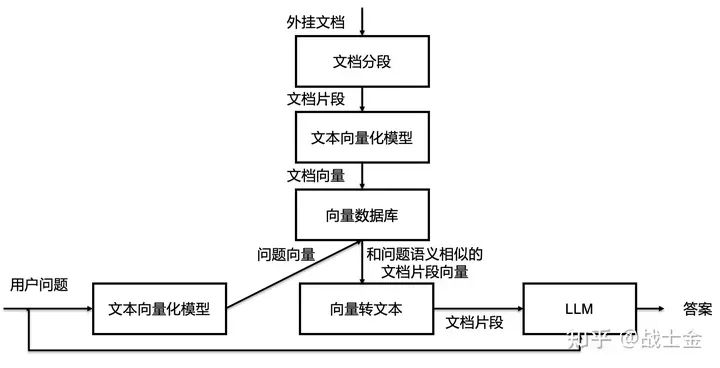
1►
自然语句向量化实践
本文接下来的内容多出自 sentence-transformers 官方文档,如果想更细致的了解,请自行查阅。该 python 库主打的功能是将句子向量化,并且官方提供了很多语言模型,如下图所示。
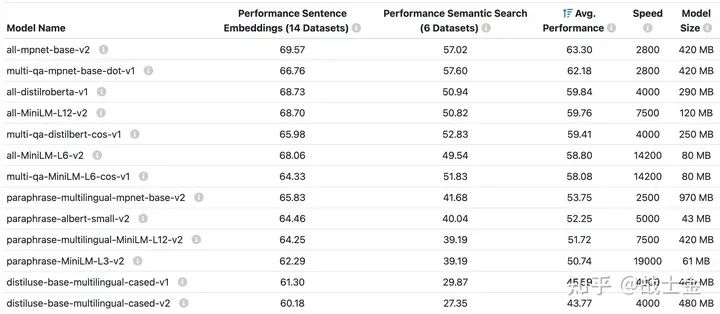
可以像 hugging face 的 transformers 库一样,几行代码就可以使用,实际上这个库的底层就是用 transformers 库实现的。并且请注意,这个库不只是只能用他提供的模型,任何 hugging face 上边的语言模型都可以使用,只要换成对应的名字就行(当然,效果不一定好),本质上就是在 transformers 库外边包了层壳(text2vec库也支持生成句子向量的功能)。
该项目对中文支持的模型不是很多,名字中带有“multilingual”的模型才支持中文,实践时可以用 hugging face 上的 shibing624/text2vec-base-chinese 模型,效果会好一些。
使用sentence-transformers库对句子向量化的示例代码如下:
from sentence_transformers import SentenceTransformer, util# multi-qa-MiniLM-L6-cos-v1可以替换成其他语言模型,即使不是sentence tranformers库官方列出的model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')# model.encode一行代码即可实现句子向量化query_embedding = model.encode('How big is London')# 可同时输入多个句子,后台按照batch一块推理passage_embedding = model.encode(['London has 9,787,426 inhabitants at the 2011 census','London is known for its finacial district'])print("Similarity:", util.dot_score(query_embedding, passage_embedding))
2►
自然语句向量化原理
sentence-transformers 里边对自然语句向量化的深度学习模型基本都是基于 bert 系列(基于 transormer encoder 结构)的。
假设我们的输入是有 L 个词的句子,那么在模型的输出头之前会被转化为(L,D)维度的矩阵,每个单词对应一个 D 维向量。但是我们想要的是一个句子的向量表示,而不是每个词的向量表示,如何得到呢?很简单,直接将(L,D)维矩阵的 L 的维度上进行 mean pooling,当作句子的向量表示。还记得之前说过 sentence-tranformers 库只是对 transoformers 库外边包一个壳么?官方甚至给出了代码,教你不安装 sentence-tranformers 库去拿到句子的向量,具体实现方式就是对词向量序列做 mean pooling,代码如下:
from transformers import AutoTokenizer, AutoModelimport torchdef mean_pooling(model_output, attention_mask):# model_output第0个位置是transformer encoder最后的输出,维度为(B,L,D)token_embeddings = model_output[0]# input_mask_expanded记录句子哪些位置真的有东西,哪些位置是padding,防止把padding的向量也平均上。input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)return sum_embeddings sum_mask# 希望向量化的句子,支持多个句子同时输入sentences = ['This framework generates embeddings for each input sentence','Sentences are passed as a list of string.','The quick brown fox jumps over the lazy dog.']# huggingface接口加载模型tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")# 句子token化encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=128, return_tensors='pt')拿到模型的输出with torch.no_grad():model_output = model(**encoded_input)#Perform pooling. In this case, mean poolingsentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
我们直接把所有词向量取平均当作句子向量,会损失很多信息。所以,想通过向量检索的方式根据问题得到精确的检索答案是很难的。增加向量的维度可以减少 mean pooling 带来的信息损失。
3►
对称语义检索与非对称语义检索
先举两组例子。
1.适用于对称语义检索的例子:
问题1:How to learn Python online?
答案1:How to learn Python on the web?
2.适用于非对称语义检索的例子:
问题2:What is Python?
答案2:Python is an interpreted, high-level and general-purpose programming language. Python’s design philosophy …”
发现了吗?对称语义检索的“问题”和“答案”要求有差不多的意思,或者根本就不属于我们常规意义里的问答,而仅仅是同义句匹配。而非对称语义检索所做的任务才是我们常规意义下问答任务。很显然,通过向量检索的方式进行非对称语义检索的难度要大的多。
对称语义检索的目标是找相似的句子,与向量检索基于计算向量相似度的原理天然匹配,只需要模型有比较强的内容抽象能力就可以。但是非对称语义检索则要求模型能够将问题和答案映射到同一空间(问题2和答案2句子的 embedding 可能也会有较高的相似度,毕竟句子里边都出现了 python)。
官方提供的模型只有很少一部分支持非对称语义检索(支持对称语义检索的模型;支持非对称语义检索的模型)。在实践过程中我发现了一个有意思的小例子:
问题:信用卡欠账不还后果很严重吗?
答案1:严重 ===> 与问题的相似度:0.4100
答案2:不严重 ===> 与问题的相似度:0.4624
这个结果肯定不是我们想要的hhh,模型回答我们“不严重”和问题更匹配,原因可能在于“不严重”这三个字都出现在了问题中,而答案1只有2个字出现在问题中。由此可见,向量检索只能检索出意思差不多的内容,下游用一个真正能很好理解语义的大模型进一步提取检索出来的句子中的信息是十分有必要的。
那么模型是否支持非对称语义检索的根本原因是什么呢?是训练的数据不同(训练方式是一样的,后文会介绍)。sentence-transformer 提供的支持非对称语义检索的模型都是用 msmarco 数据集训练的,这是一个根据 bing 搜索构建的大规模问答数据集。正是因为训练数据有真正的问答属性,模型才有真正的问答检索能力(将问题与答案映射到同一向量空间)。
我的理解是,如果训练数据里没有某一领域的数据,比如金融领域,那么通用的非对称语义模型就不能很好的完成该领域的检索任务。但是对称语义检索有“泛化”到其他领域的能力,毕竟只需要理解“字面意思”。
4►
训练模式
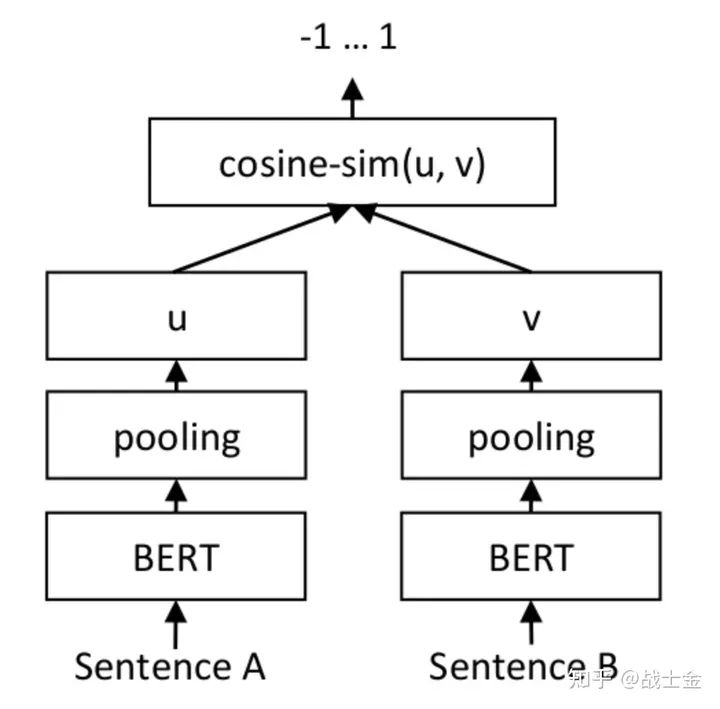
不管是对称还是非对称语义检索模型,微调模式如下图所示,基于 bert 模型,出自论文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》(一点细节:原文只有推理时是如下架构,训练时loss用的交叉熵损失),两路的 bert 是共享参数的。目标是将“配对”的两个句子对应的向量空间拉近,“不配对”的两个句子的向量空间拉远,cosine 相似度衡量两个句子在向量空间的相似度(一个问题+一个答案可以说是配对的,两个相似的句子也可以说是配对的,看用的是什么数据集)。推理时用同样的架构计算两个句子之间的相似度。
cos相似度公式:
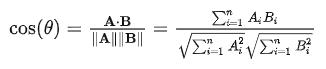
5►
优化向量检索链路
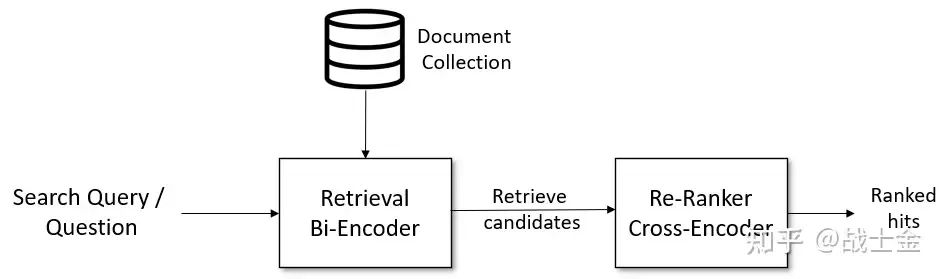
之前讲的向量化检索方式能够快速找出和问题比较匹配的内容,但是比较不准,官方提供一种匹配准确率和匹配速度权衡的 pipeline。图中 Bi-encoder 代表上文介绍的向量检索技术,快速匹配和问题相似的候选答案。然后再通过 cross-encoder 模型更精确的从候选答案中挑选出匹配的答案。做过搜广推的同学一定非常这个结构,这不就是召回、粗排、精排那种思路嘛。cross-encoder 的结构如下图所示:
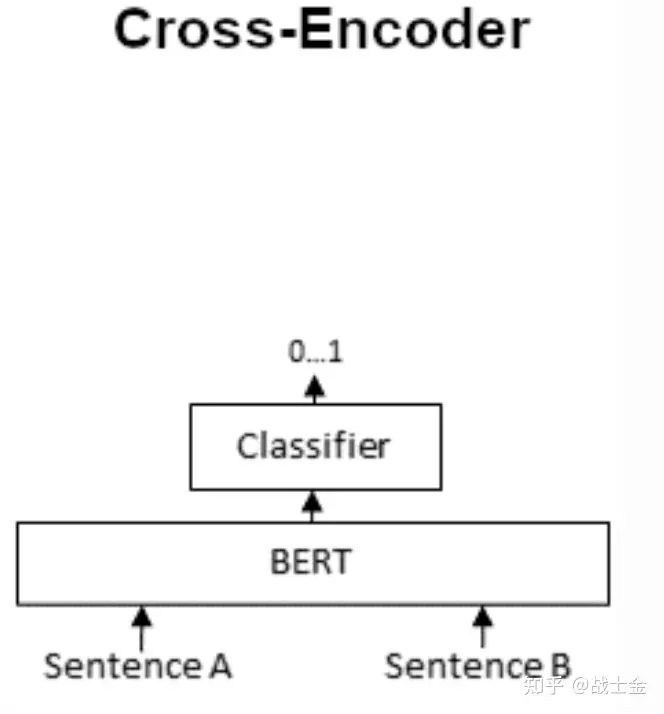
很好理解,就直接把问题+答案拼在一起,做个二分类嘛。模型同时有了问题+答案这样一对的上下文信息,当然比直接分别将问题+答案映射到相同的向量空间、再计算相似度准的多了。但是这种计算向量相似度的模式会慢。假设有 m 个问题和 n 个答案,向量检索(图中的 bi-encoder 环节)只需要跑 m+n 次 bert 模型就够了,但是 cross-encoder 需要将所有问题和答案分别组合起来,跑 m*n 次 bert 模型。
我们很难通过微调的方式将新的知识注入到大模型里,通过外挂数据库的方式让大模型利用额外的知识其实是个不错的选择。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

