




TabPFN介绍
https://github.com/automl/TabPFN
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
TabPFN是一个经过训练的Transformer,可以在不到一秒的时间内对小型表格数据集进行监督分类,无需进行超参数调整,并且与最先进的分类方法竞争力相当。
TabPFN是一种先验数据拟合网络(PFN),经过一次线下训练,以近似贝叶斯推断合成数据集上的数据。这个先验包括来自因果推理的思想:它包含了大量的结构性因果模型,倾向于简单的结构。
TabPFN与复杂的最新AutoML系统相媲美,速度提高了230倍。当使用GPU时,这个提速增加到5700倍。论文还在OpenML的其他67个小型数值数据集上验证了这些结果。
PFN原理
在贝叶斯框架下进行监督学习时,先验定义了一组输入与输出标签之间关系的假设空间。每个假设可以被看作是生成数据分布的机制,我们可以从中抽取样本来构建数据集。
对于测试样本,后验预测分布(PPD)指定了其标签的分布,其中是训练样本的集合。
PPD可以通过对假设空间的积分来获得,其中假设的权重由其先验概率和给定的数据的似然决定:
先验拟合是训练PFN来近似PPD从而进行贝叶斯预测的过程。我们使用一个先验,它由形式为的先验采样方案指定,首先通过采样假设(生成机制),然后通过采样合成数据集。我们重复采样这样的合成数据集,并优化PFN的参数,以使其针对的其余数据集进行预测。
在推理期间,训练好的模型应用于未见过的现实世界数据集。对于一个新的数据集,其中包含训练样本和测试特征,将作为输入提供给上面训练过的模型,可以在单次前向传递中获得PPD 。然后,PPD的类别概率被用作我们现实世界任务的预测。因此,PFN在一个步骤中进行训练和预测(类似于使用高斯过程进行预测),不会在推理时对已见数据进行基于梯度的学习。
架构PFN依赖于Transformer,将每个特征向量和标签编码为一个标记,允许标记表示相互关注。它们接受可变长度的特征和标签向量的训练集(被视为集合值输入以利用排列不变性)以及可变长度的查询集特征向量,并返回每个查询的PPD估计。
TabPFN网络结构
TabPFN是一个基于数据拟合的网络,根据表格数据先验中采样的数据进行拟合。论文对原始的PFN架构进行了两方面的轻微修改:
我们对注意力掩码进行了轻微修改,以减少推理时间 此外,我们通过零填充使我们的模型能够处理具有不同特征数量的数据集
在先验拟合阶段,训练了一个12层的Transformer,对每批次包含512个合成生成的数据集,总共需要8台GPU的一台机器上进行了20小时。这产生了一个用于我们所有评估的单一网络。
表格数据的先验
基本概率模型
拟合模型通常需要找到合适的超参数,例如,用于神经网络的嵌入大小、层数和激活函数。通常需要进行资源密集型搜索以找到合适的超参数(。然而,这些搜索的结果仅是对超参数选择的点估计。
PFN允许我们对我们的先验的超参数完全遵循贝叶斯原则。通过在先验中定义超参数空间的概率分布,例如BNN架构,由我们的TabPFN近似的PPD同时集成了这个空间和相应的模型权重。
简单性
在考虑竞争假设时,更简单的假设应该更受欢迎。认知科学的工作还揭示了人类思维中对简单解释的偏好。然而任何简单性的概念都取决于选择定义简单性的特定标准。
SCM先验
表格数据通常表现出列之间的因果关系,而因果机制已被证明是人类推理的一个强先验。因此,我们的TabPFN先验基于SCM,模拟因果关系。
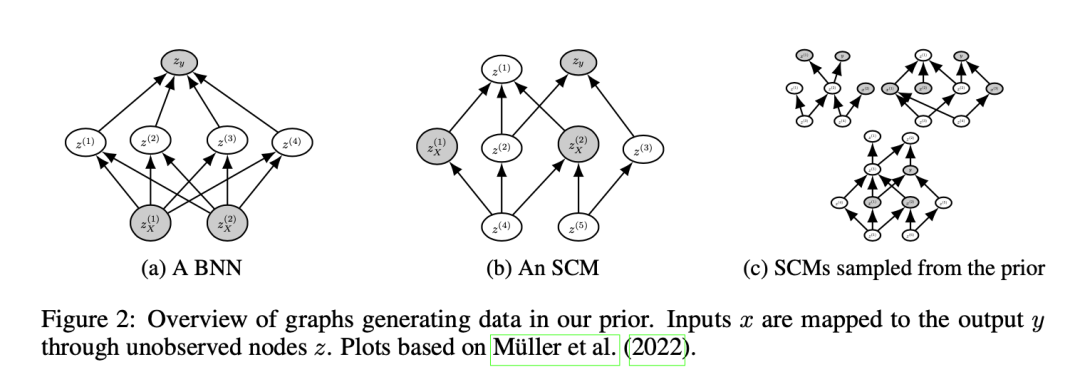
基于因果推理的想法进行的预测之前的研究已经应用了因果推理来预测未见数据的观察值,该方法寻求通过干预和观察数据来识别系统的组成部分之间的因果关系。
实验效果
玩具问题的评估
作者首先对TabPFN和标准分类器(无超参数调整)在玩具问题上进行了质量比较。他们使用了包括噪声的moons数据集、包含噪声的circles数据集以及iris和wine数据集的特征。
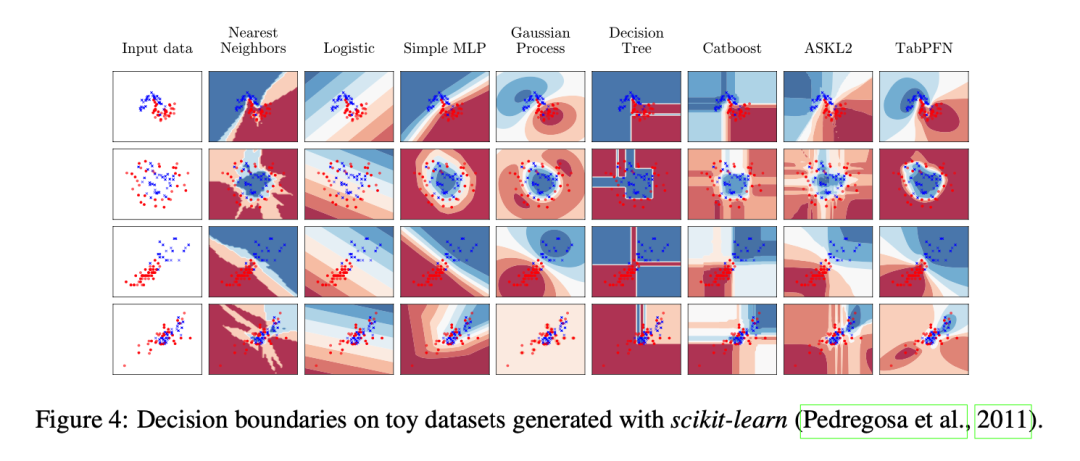
实验结果显示,TabPFN可以准确地模拟样本之间的决策边界,类似于高斯过程,对于远离观测样本的点,不确定性较大。TabPFN在各个玩具问题中都取得了直观、良好校准的预测结果。
在表格机器学习任务上的评估
接下来,作者在真实的表格机器学习任务中对TabPFN进行了实证分析,比较了其与表格分类的最先进机器学习方法和AutoML方法。他们使用OpenML-CC18基准测试套件中包含高达2000个样本,100个特征和10个类别的所有数据集作为测试数据集。作者将这些数据集分为18个仅包含数值特征且没有缺失值的数据集和12个包含分类特征和/或缺失值的数据集。
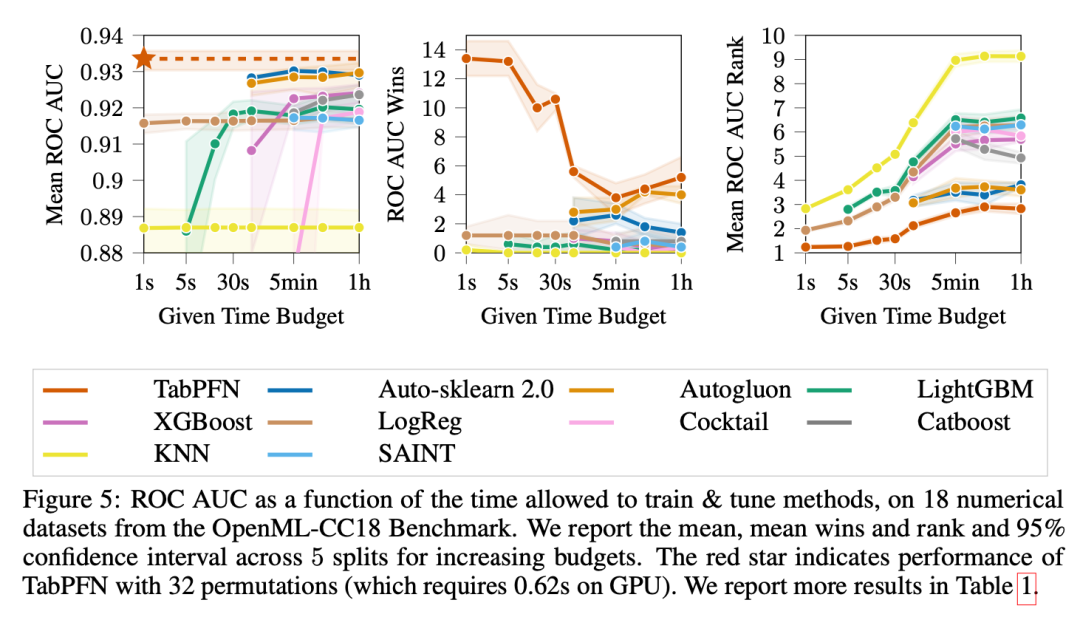
作者使用五种标准ML方法和两种最先进的AutoML系统作为基准,对这些数据集进行评估。他们考虑了k最近邻(KNN)、逻辑回归(LogReg)以及三种流行的基于树的增强方法,包括XGBoost、LightGBM和CatBoost。此外,他们还使用AutoGluon和Auto-sklearn 2.0作为更复杂但强大的基线。
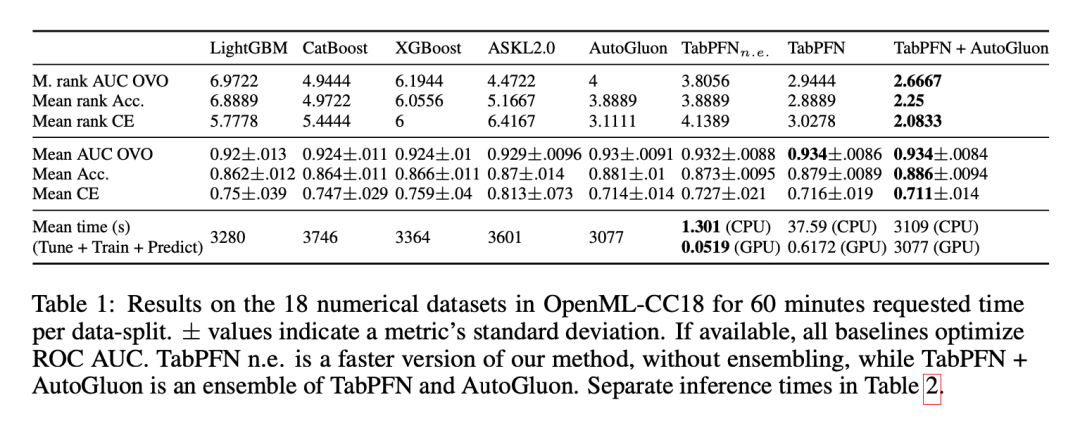
实验结果表明,TabPFN在准确性和训练速度之间取得了更好的平衡。在一个GPU上,TabPFN可以在不到一秒的时间内进行预测,而在训练了一个小时后,其性能与最佳竞争者(AutoML系统)相当。与表格基线方法相比,TabPFN要快得多,但性能相当。总体而言,TabPFN在数据集不包含分类特征或缺失值时表现特别出色。
总结与展望
TabPFN的Transformer架构仅适用于小型数据集,因此需要进一步研究如何扩展到大型数据集。 当前的研究主要关注了仅包含数值特征的分类数据集,未来可以研究如何更好地处理分类特征。 TabPFN目前对于缺失值的处理还有改进的空间,未来可以研究如何更好地处理缺失值。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

