




背景
大型语言模型(LLM)在回答未知领域的问题时,往往会出现幻觉问题,即胡言乱语。为了克服这种问题,我们需要让大模型学习额外的专业内容。这些内容可以是PDF文档、视频或其他形式的“外部知识库”。我们期望LLM可以帮助我们对这些知识库进行问答和总结。
在解决这个问题时,通常有两种方法:
1、通过预训练和finetune的方式对LLM进行微调。
2、采用基于提示学习(prompt learning)以及向量数据库来管理我们的专业内容。
早在2020年,OpenAI 就在论文Language Models are Few-Shot Learners 中提出了如何使用 prompt learning 提升大模型的推理能力,论文中提出了 Zero-shot、One-shot、Few-shot 三种不同的 prompt 方法,并且与Fine-tuning进行了对比。
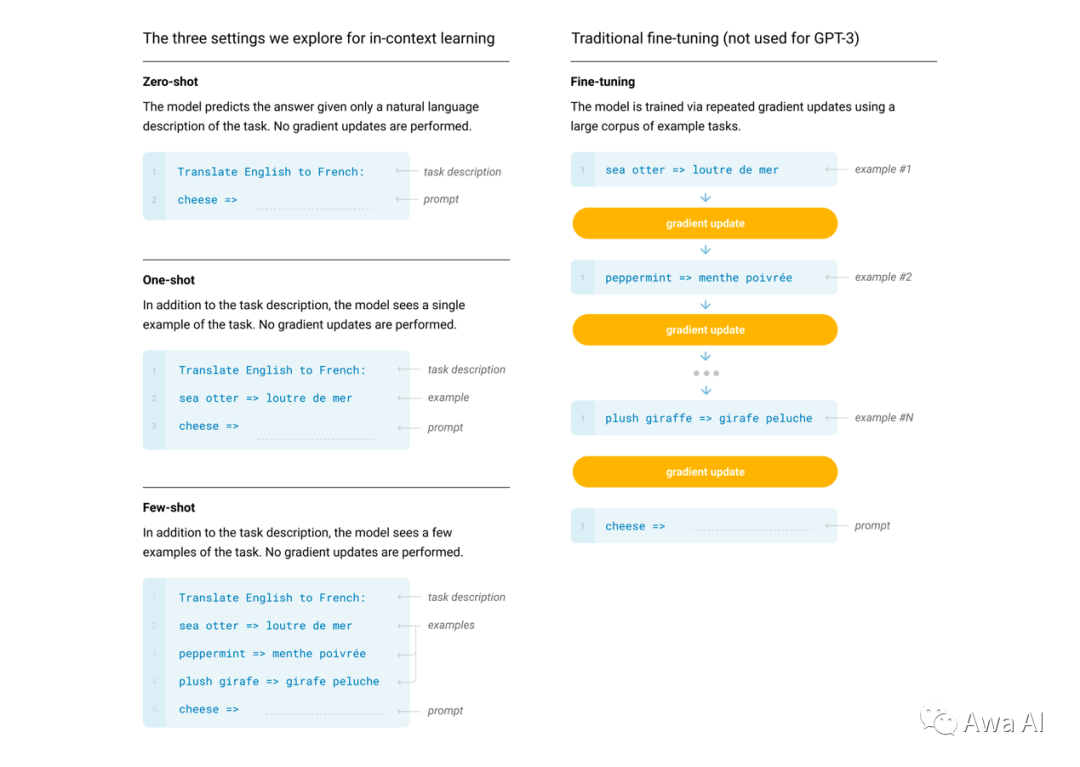
对比发现, Fine-tuning方案需要大量的数据处理和显卡资源,以及专业的NLP算法工程师。这对于个人或小团队来说,无论是从数据安全、金钱成本还是时间成本上来看,都是难以承受的。因此我们推荐使用向量数据库增强的提示学习(prompt learning)解决方案。
向量数据库增强对比测试demo及效果
接下来, 我们将基于向量数据库 awab, 通过使用向量数据库检索前后对比测试三体相关问题的问答, 来检验该方案的效果。测试步骤如下:
1、未使用向量数据库增强
关于三体以及awadb的提问,在没有相关输入时,模型出现幻觉,答非所问


2、使用向量数据库检索相关内容
在数据库中进行检索,返回与所提问题相关的内容。
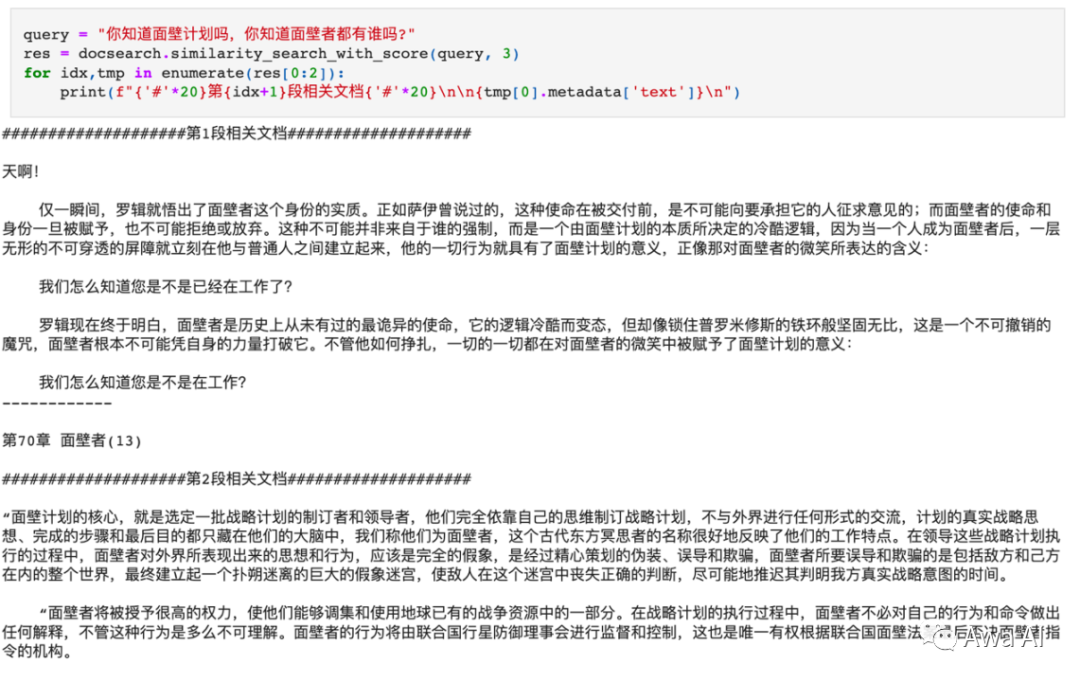

3、将专业知识一并交给模型


可以看到,在得到相关内容的增强,模型可以正确回答我们的提问了。
在进行实验测试对比后,我们发现在没有相关输入时,模型可能出现幻觉并回答与问题无关的答案。然而,一旦使用向量数据库检索相关内容后,模型就能够正确回答问题,并且掌握了相关的专业知识。
这种基于向量数据库的提示学习(prompt learning)的方法, 可以帮助大模型快速、高效、精准地学习相关专业知识,提高模型的智能化水平。
向量数据库与Prompt Learning简介
Prompt Learning
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
Prompt 是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的文本的技术。
所谓的Prompt Learning,是指模型在推理时给予少量样本,但不允许进行权重更新。对于一个典型数据集,Few-shot 有上下文和样例(例如英语句子和它的法语翻译)。
Zero-Shot(0S)和 One-shot 类似,但不允许提供样本,只给出描述任务的自然语言指令。该方法提供了最大的方便性、稳健性以及避免虚假相关的可能性,但也是最具挑战性的设置。
在某些情况下,即使是人类,在没有例子的情况下,也可能难以理解任务的格式。例如,如果要求某人“制作一张关于200米冲刺世界纪录的表格”,这个请求可能是模棱两可的,因为可能不清楚表格应该具有什么格式或包含什么内容。然而,至少在某些情况下,Zero-shot 是最接近人类执行任务的方法,例如图 1 中的翻译示例,人类可能仅凭文本指令就知道该做什么。
Prompt Learning是一种具有广泛应用前景的技术,可以在各种领域(如自然语言处理、计算机视觉、语音识别和推荐系统等)中实现。通过Prompt Learning,模型可以快速、高效地学习新任务,减少样本和计算资源的需求,提高模型的准确性和效率。因此,Prompt Learning将成为未来机器学习和人工智能研究中的重要方向。
向量数据库
向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,范围从几十到几千不等,具体取决于数据的复杂性和粒度。向量数据库同时具有CRUD操作、元数据过滤和水平扩展等功能。
通常情况下,向量是通过对原始数据(例如文本、图像、音频、视频等)应用某种变换或嵌入函数来生成的。这些嵌入函数可以基于各种方法,例如机器学习模型、词嵌入、特征提取算法。
向量数据库的主要优点是它允许根据向量距离或相似性对数据进行快速准确的相似性搜索和检索。这意味着您可以使用向量数据库根据语义或上下文含义查找最相似或相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。
向量数据库将向量嵌入组织在一起,使我们能够比较任何向量与搜索查询的向量或其他向量之间的相似度。它们也可以执行CRUD操作和元数据过滤。将传统数据库功能与搜索和比较向量的能力相结合,使得向量数据库成为强大的工具。它们在相似度搜索方面表现出色,或称为“向量搜索”。
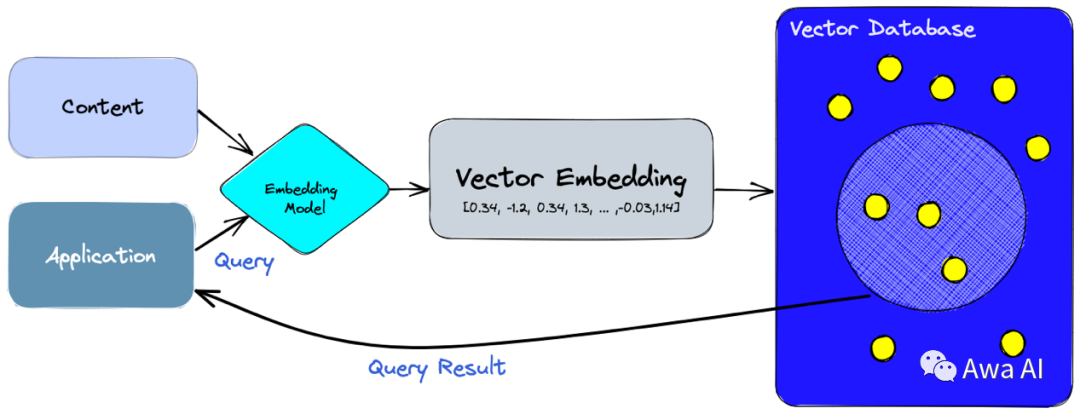
通过使用向量数据库,您可以快速搜索和检索包含所需信息的向量,这对于许多应用程序非常有用,例如自然语言处理、图像搜索、音频分析和推荐系统等。因此,向量数据库已成为许多领域中的重要组成部分,并且在未来将继续发挥重要作用。
后记
Awadb是一个轻量级的向量数据库,可以帮助用户快速地创建本地的知识库,通过这种方式,无论您是管理小型文档集合还是大型数据库,都可以在查询的时候,快速准确地找到最相关的信息,来增强LLM模型的能力。
附完整代码:https://github.com/awa-ai/awadb/blob/main/examples/chatglm/chatglm-6b.ipynb
