




背景
情况4:
- 数据库隐式使用函数原因与情况3相同
我们创建了一个字符列的索引,但这个列中只存放了一些数值数据。下面的查询就不走索引
select * from t where indexed_column=5
– 注意:这个查询中指定的常量是数值5.这个查询等价于以下查询
select * from t where to_number(indexed_column)=5
数据库会对这个列隐式地使用一个函数,所以查询就不能再用索引了。
示例:
SQL>create table t (x char(1) constraint t_pk primary key);
SQL>insert into t values('5');
SQL>set autotrace traceonly explain;
SQL>select * from t where x=5;
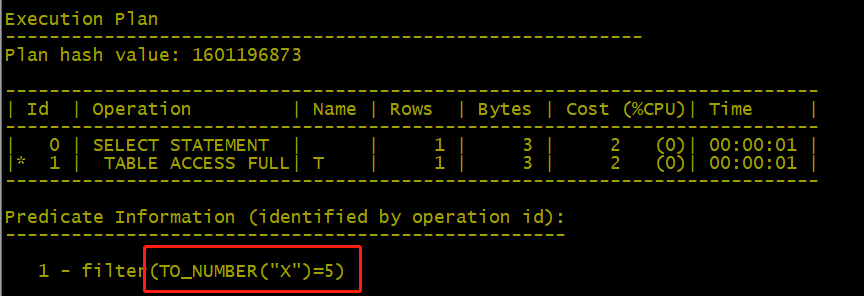
即使给这个查询加上提示,强制它使用索引,数据库也不会按照我们原来设想的那样对索引使用union scan ,而是对这个索引进行full scan:
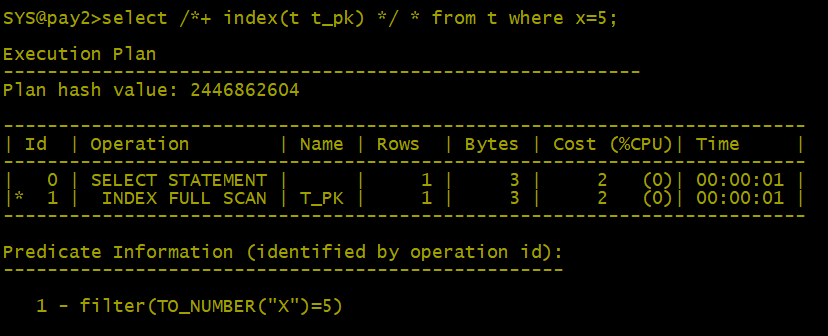
因为它必有将X中存储的字符串转换为数字,才能与数值5进行比较。我们不能把数字5转换成字符5,因为数据库的NLS设置会对转成的字串样式有所影响(也就是转换的结果不是确定性的,不同的NLS设置产生不同的字符串),所以我们只能把字符串转成数字,而这样一来(由于应用了函数),数据库就无法使用索引了。
此例子得出一个结论:一定要尽可能地避免隐式转换。另外如果可能的话,尽量不要在SQL语句的谓词部分对数据库列使用函数。
情况5
如果用了索引,数据库的处理速度反而会变慢。这种情况比较常见,Oracle (对CBO而言)只在需要的时候才使用索引。
SQL>create table t (x int);
SQL>insert into t select rownum from dual connect by level < 1000000;
999999 rows created.
SQL>create index t on t(x);
SQL>exec dbms_stats.gather_table_stats(user,'T');
SQL>set autotrace traceonly explain
-- 如果我们的查询只取表中的少量数据:
SQL>select count(*) from t where x< 50;
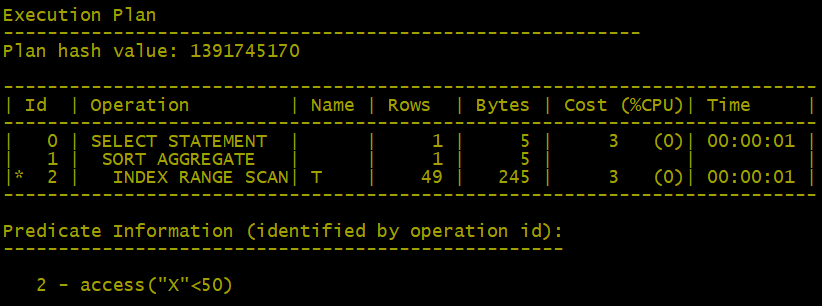
此时优化器很乐意使用索引。不过我们发现,如果优化器估计通过索引取得的数据超过一个阀值(取决于不同的优化器设计、物理统计等,这个阀值可能有所变化),它就会进行全表扫描。
SQL>select count(*) from t where x<500000;
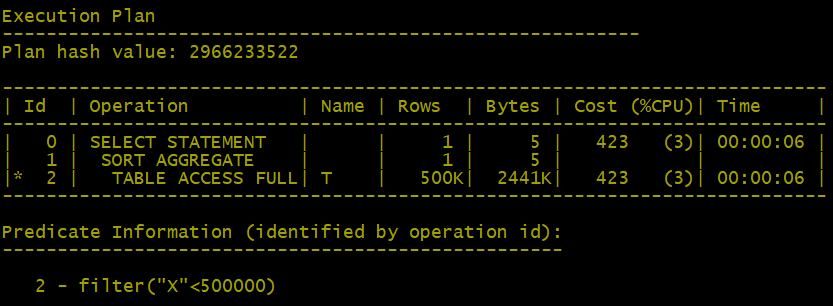
这个例子显示出优化器不一定会使用索引;查询优化器在这里使用全表扫描是个正确的选择。当你进行调优时,如果发现那个查询没有使用你认为应该用到的索引,不要贸然强制使用这个索引,应该先做个测试,证明使用这个索引后确实会加快速度(通过比较耗用时间和I/O次数等),然后再考虑让CBO就范(强制它使用这个索引)。
情况6:
表上的统计信息过旧也会影响查询使用索引,所以一般没走索引先收集下统计信息也能解决问题。
总结:
数据库不使用索引原因一般为建的索引与使用的条件不一致,要不就是走索引比走全表更耗时(需要进行测试验证来确诊),要不就是走索引不能得到正确的答案。
