




2023年,向量数据库随着大模型在科技圈的火热也成功出圈。在Google Trends上搜索Vector Database(向量数据库),其关注度先显著提升。
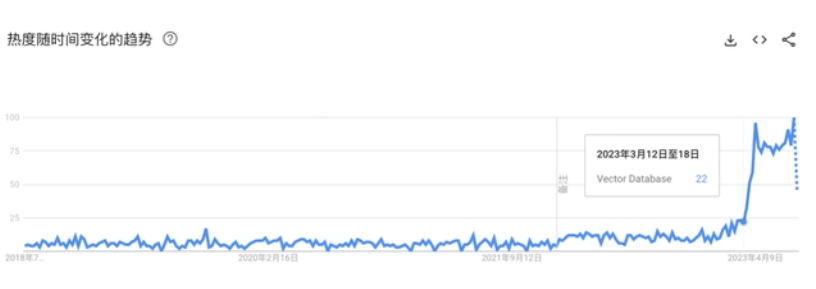
来源:Google Trends
随着向量数据库技术的不断发展,我们可以预见,它将在未来的大数据和人工智能领域发挥越来越重要的作用。
什么是向量数据?
在人工智能时代,传统的结构化数据(如文本、数字等)已经无法满足我们的需求。而向量数据,是一种高维数据,它可以在多维空间中表示复杂的关系和模式,可以用来表示图像、语音、视频等非结构化数据,也可以用来表示深度学习模型的特征。
典型的向量数据包括:
图像向量,通过深度学习模型提取的图像特征向量,这些特征向量捕捉了图像的重要信息,如颜色、形状、纹理等,可以用于图像识别、检索等任务;
文本向量,通过词嵌入技术如Word2Vec、BERT等生成的文本特征向量,这些向量包含了文本的语义信息,可以用于文本分类、情感分析等任务;
语音向量,通过声学模型从声音信号中提取的特征向量,这些向量捕捉了声音的重要特性,如音调、节奏、音色等,可以用于语音识别、声纹识别等任务。
这些向量数据由于其高维性和稀疏性,不能有效地使用传统的关系型数据库(如MySQL)或者NoSQL数据库(如MongoDB)进行存储和检索。比如,如果把一个300维的文本向量作为一行数据存储在MySQL中,那么在进行高维空间的近邻查询(比如,找出与某个文本向量在语义上最相似的文本向量)时,性能会非常低下。
向量数据库为向量数据提供了专门的存储和索引机制。在向量数据库中,向量数据被存储为高维空间中的点,数据库会为这些点建立索引,常用的索引方法有KD-树、BB-Tree、HNSW等。这些索引结构使得向量数据库可以高效地进行向量间的相似度查询,如余弦相似度、欧几里得距离等,从而极大地提升了处理向量数据的效率。
向量数据库的发展历程可以大致划分为三个阶段:
第一阶段是向量数据的初级阶段,这个阶段的向量数据库主要是以文件形式存储向量数据,没有有效的索引和查询能力,典型的产品如早期的Lucene等。
第二阶段是向量数据的发展阶段,这个阶段的向量数据库开始使用KD树等索引结构,可以实现一定的查询性能,但是在高维空间的查询效率还不高,典型的产品有FAISS、Annoy等。
第三阶段是向量数据的成熟阶段,这个阶段的向量数据库已经可以实现高效的向量索引和查询,可以处理海量的高维向量数据,典型的产品有Milvus、Elasticsearch等。
需要指出的是,向量数据库是伴随着人工智能的发展而发展的,并在不断满足人工智能的数据存储需求过程中持续演进。
向量数据库跟大模型是什么关系?
联汇科技首席科学家赵天成博士认为,向量数据库和大模型技术两者都是人工智能领域的重要技术基座。其中,向量数据库提供了存储、记忆能力,大模型提供了问题处理和分析能力。与传统数据库相比,向量数据库使用向量化计算,高速地处理大规模的、高维的、复杂数据,例如图像、音频和视频等,并支持复杂查询操作,扩展到多个节点,以处理更大规模的数据。
大模型具有的强大的学习和表示能力,能够处理庞大和复杂的数据,并从中提取出有用的特征和模式,并通过大规模的数据集预训练,加速迭代精进,提升模型性能,向量数据库为大模型提供了高效的数据存储和查询支撑,是大模型落地应用的重要条件。
大模型与向量数据库两项关键技术的深度融合应用为通用人工智能(AGI)的实现提供了可靠路径。以联汇科技为例,依托技术创新,联汇科技研发OmBot自主智能体,它集认知、记忆、思考、行动四大核心能力,作为一种自动、自主的智能体,它能够感知环境、自主决策并且具备短期与长期记忆的计算机模型,模仿人类大脑工作机制,根据任务目标,主动完成任务。
向量数据库对于大模型的应用价值分析:
GPT-4等大模型,通过学习大量的训练数据,能够提供高准确度的预测和生成结果,从而在各种复杂的任务中表现出色。然而,这也带来了大规模向量数据处理的需求,包括存储、索引和查询。传统的数据库技术,无论是关系型数据库还是NoSQL数据库,都在处理这种类型的数据时面临挑战。
首先,大模型的训练需要大量的输入数据,这些数据通常是高维度的向量。传统的数据库在存储这种高维度数据时,往往需要大量的存储空间,而且查询效率也相对较低。向量数据库通过优化的数据结构和索引算法,可以高效地存储和查询大规模的向量数据,从而大大提高了大模型训练的效率。
其次,在训练过程中,大模型需要根据输入数据的相似度进行学习。这需要数据库提供高效的相似度查询功能,而这是传统数据库往往无法满足的。向量数据库通过使用诸如KD树、球树等高效的索引结构,可以快速找出与给定向量最相似的数据,从而支持大模型的训练需求。
此外,在模型训练完成后,需要对新的输入数据进行预测。这同样需要高效的相似度查询功能,以找出与新输入数据最相似的训练数据,然后基于这些数据进行预测。向量数据库在这方面同样展现出了优越的性能,从而支持了大模型在实际应用中的部署。
在人工智能领域,通用大模型的微调成为了一种常见且有效的策略。这种策略允许模型学习一种更具体、更详细的领域知识,从而能更好地解决领域内的问题。然而,这个微调过程的成功在很大程度上依赖于向量数据库的功能和性能。
当我们将通用大模型微调为专用大模型时,这个过程需要对特定领域的大量数据进行深入学习。这些数据通常包含大量高维度的特征向量,例如在自然语言处理中的词向量、在图像识别中的像素向量等。这些高维度向量数据的处理,传统的数据库无法满足其性能需求,而向量数据库却能有效地管理这些数据,支持对这些数据的高效检索和查询。
一个关键步骤是需要进行大量的相似度查询。为了寻找和给定向量最相似的向量,向量数据库通常采用特定的索引结构,如KD树、球树等,这些索引结构允许在大规模高维向量数据中进行高效的近似最近邻查找。这种查询效率的提升,直接导致了模型微调过程的效率提升。微调过程中,模型需要频繁地读取数据进行训练,向量数据库可以提供高效的读取能力。此外,模型训练过程中的更新数据也需要写回数据库,向量数据库的高效写入性能也能满足这一需求。
以联汇科技的向量数据库产品Om-iBase为例,Om-iBase基于智能算法提取需存储内容的特征,使用AI深度学习模型和自监督学习技术,对文本、图片、音频和视频等非结构化数据进行特征提取,有效实现非结构化数据向量化存储,并通过向量化编辑器、向量索引加速技术(ANN)、向量聚类、向量降纬、数据聚类、异常分析等核心技术与算法,确保向量分析的全面性和检索的准确性,实现数据库的高性能检索、高性能分析。此外,Om-iBase提供完整的SDK支持和灵活可配的插件体系,开发者可以最大化的自主发觉潜能。
总的来说,大模型的发展催生了向量数据库的需求,而向量数据库的发展又反过来推动了大模型的发展。这种良性循环,使得向量数据库在人工智能领域获得了前所未有的关注和应用,其重要性也日益突出。同时,向量数据库的发展也带来了一系列的技术挑战和研究热点,包括如何提高存储和查询效率、如何支持复杂的查询需求、如何提高易用性等,这将是未来研究的重要方向。
向量数据库八大技术趋势
面对着未来,向量数据库的发展将会和大模型的发展更加紧密地结合,共同迎接一系列的新机遇和新挑战。在这个过程中,向量数据库的技术将会发展出一些重要的趋势。
1、更好的分布式与并行计算能力
随着数据规模的不断扩大以及大模型对计算能力的强烈需求,向量数据库必须对分布式与并行计算能力进行深度优化。更高效的分布式与并行计算可以让大规模向量数据在多个计算节点间进行分配,使得查询、排序等操作能够并发进行,大大缩短了计算时间。在具体实施上,分布式系统设计、数据切分策略、负载均衡算法等都将是挑战与机遇。
2、实时处理能力提升
对于许多AI应用来说,如自动驾驶、智能客服等,它们的决策过程需要在瞬息之间完成。这就要求向量数据库有高效的实时处理能力,即使是对大规模的向量数据,也能在最短的时间内找到最匹配的结果。因此,优化查询算法、提升数据存取效率,甚至是实现实时数据更新,都将是实时处理能力提升所需面对的关键问题。
3、高级查询功能
随着用户对数据处理需求的复杂化,传统的简单查询方式已经无法满足需求。高级查询功能,如范围查询、最近邻查询,甚至基于语义的查询等,将是向量数据库的必备功能。这不仅需要向量数据库本身的技术突破,还需要与AI技术深度融合,通过理解数据的深层含义,提供更符合用户需求的查询结果。
4、硬件加速尤其是GPU加速
CPU在处理大规模向量数据时,可能会遇到瓶颈。为了更高效地处理数据,硬件加速将是一种有效的解决方案。例如,利用GPU的强大并行计算能力,或者利用定制的AI芯片,都可以大大提高向量数据库的处理能力。但这也会带来新的挑战,比如如何将数据库操作高效地映射到硬件操作,如何管理和调度硬件资源等。
5、针对不同类型大模型的性能优化
不同类型的大模型对数据的处理和计算需求可能会有所不同。向量数据库需要能够针对这些差异进行优化,以提供最佳的性能。这可能包括特定类型模型的存储优化,或者是查询优化,甚至是针对特定类型模型的特殊查询功能等。
6、多模态数据处理能力
随着大模型向多模态发展,如图文混合模型、音视频混合模型等,对应的数据也将会更为复杂多元。向量数据库需要能够有效地处理这些多模态数据。这不仅需要数据库本身的技术突破,也需要和AI模型的深度融合,以理解和处理多模态数据中的关联和交互。
7、提升向量数据库的通用性和易用性
随着向量数据库的应用场景不断拓宽,提升其通用性和易用性成为一项重要任务。这包括提供更简单的数据导入导出,提供更易用的查询接口,以及提供更灵活的数据管理功能。同时,也需要提供丰富的文档和示例,降低用户的学习成本。
8、向量数据库与深度学习、大模型的深度融合
未来,向量数据库将和深度学习、大模型更紧密地结合,共同推动AI的发展。向量数据库需要能够理解大模型的需求,为其提供最合适的数据服务。而大模型也需要能够利用向量数据库的能力,以提高自身的效率和效果。这种融合可能会带来许多新的可能性,例如模型和数据库的联合优化,或者是数据库自身的自动学习和优化等。
在经历了大数据时代的高速蓬勃发展之后,向量数据库已然成为新一轮技术浪潮中的明亮新星。这背后并非偶然,而是科技与时代需求的完美结合。在探索无垠的人工智能宇宙中,我们渐渐明白,每一个巨大的计算模型都需要一颗稳固的“心脏”——一个可以储存、检索和管理高维向量数据的强大核心,而向量数据库正是这颗“心脏”。
关于联汇科技
公司介绍:
杭州联汇科技股份有限公司,成立于2023年,长期专注于多模态数据分析、 视觉语义理解、预训练大模型、AIGC等前瞻性人工智能技术。大幅度降低人工智能技术与算法开发和使用门槛,加速推动普惠AI赋能千行百业。自主研发iBase向量数据库、欧姆多模态预训练大模型、OmBot自主智能体等技术产品,打造以人工智能通用大模型为核心的AaaS(AI Agent as a Service)服务体系。
技术团队:
首席技术官、首席科学家赵天成博士毕业于卡耐基梅隆大学计算机学院,从事多模态机器学习、自然语言处理等领域研究,是国际多模态交互AI领域领军人物,率先突破非结构化数据直接使用、跨模态数据融合分析等行业难题,填补技术空白。核心技术团队是由卡内基梅隆大学、加州大学、纽约大学、浙江大学的博士后、博士等组成,100%硕士学历以上。 团队在ECCV(2022)、CVPR(2023)等国际顶级会议中多次获 得ODinW开放域目标检测挑战赛的冠军。
