数据库向量化是一项工程性很大的挑战,但可为StarRocks等实时分析引擎提供数量级性能提升。1、向量化引擎为什么可以提升性能
本文讨论的数据库都是基于CPU架构,数据库向量化一般指基于CPU的向量化,因此数据库性能优化的本之在于:基于CPU的程序如何进行性能优化。这引出2个关键问题:1)如何衡量CPU性能
2)哪些因素影响CPU性能
第一个问题可以用以下公式总结:CPU Time = (instruction numbers) * CPI * (clock cycle time)。其中,instructions numbers指CPU产生的指令数;CPI(cycles per instruction)指执行一个指令需要的CPU周期;Clock cycle time是一个CPU周期需要的实际,和CPU硬件特性强相关。在软件层密可以改变的有前两项。那么具体到一个CPU程序,有哪些因素影响指令数和CPI?1)取指令
2)指令译码
3)执行指令
4)内存访问
5)结果写回寄存器
其中,CPU的frontend负责前两部分,backend负责后面三部分。Intel提出了《top-down microarchitecture analysis method》的CPU微架构性能分析方法,如下图: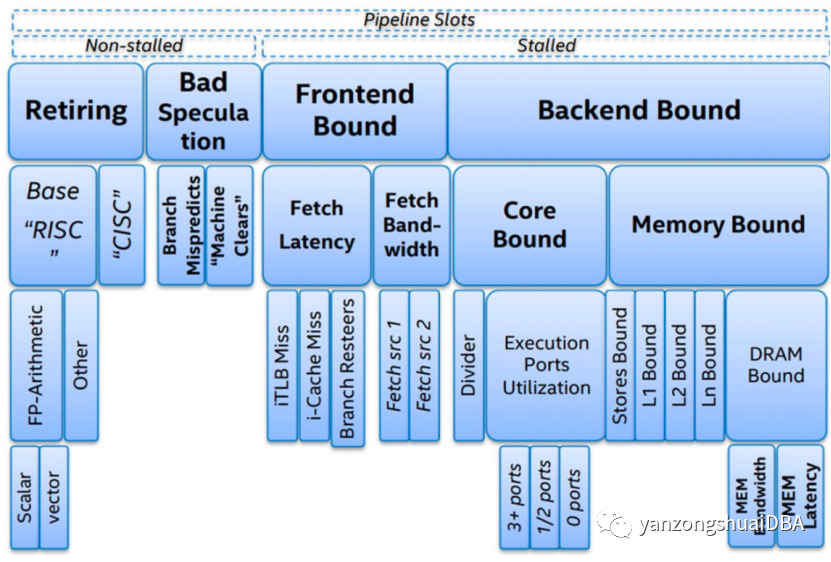
为了便于大家理解,我们可以将上图简化为下图(不完全准确):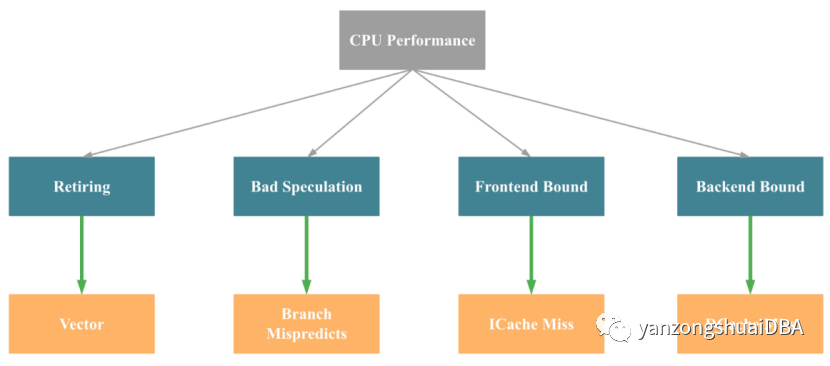
即影响一个 CPU 程序的性能瓶颈主要有4大点:Retiring、Bad Speculation、Frontend Bound 和 Backend Bound,4个瓶颈点导致的主要原因(不完全准确)依次是:缺乏 SIMD 指令优化,分支预测错误,指令 Cache Miss, 数据 Cache Miss。再对应到之前的 CPU 时间计算公式,我们就可以得出如下结论: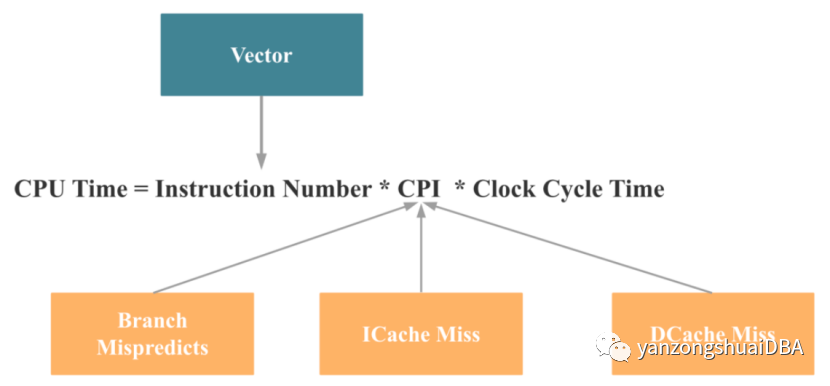
而数据库向量化对以上 4 点都会有提升。 主要原因如下,相比于传统的按行解释执行,向量化执行有以下优点:1)Interpretation 执行的开销更低(批量执行的优点),更少的虚函数调用,更少的分支预测失败
2)对 SIMD 执行更加优化 (按列执行的优点)
3)对 CPU Cache 更加优化 (经常操作顺序的内存)
4)延迟物化:只需要在最后必要的时候将最终需要的列拼成行
2、向量化基本原理
SIMD顾名思义,就是单指令多数据,一条指令可以并行操作多个数据。而SISD(单指令单数据)体系架构则是一套指令仅操作单个数据点。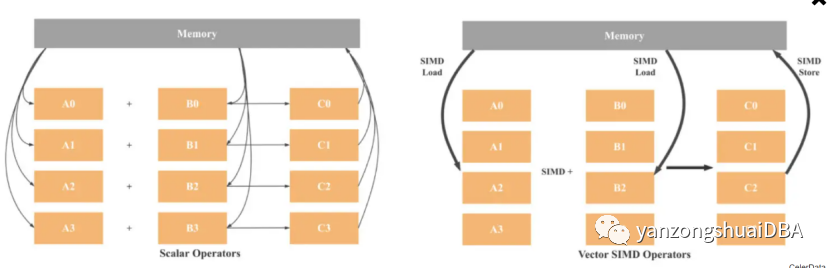
如上图,SISD架构,操作是标量的,一次进处理一个数据。4个加法会涉及8次load操作(每个变量1次),4个加法操作,4个存储操作。如果使用128位的SIMD,则仅需2次load、1次加法、一次存储。理论上可以达到4倍性能提升。现在CPU已支持512位SIMD寄存器,所以可以达到16倍性能提升,当然这仅是理论上的提升。2.1 如何进行向量化编程
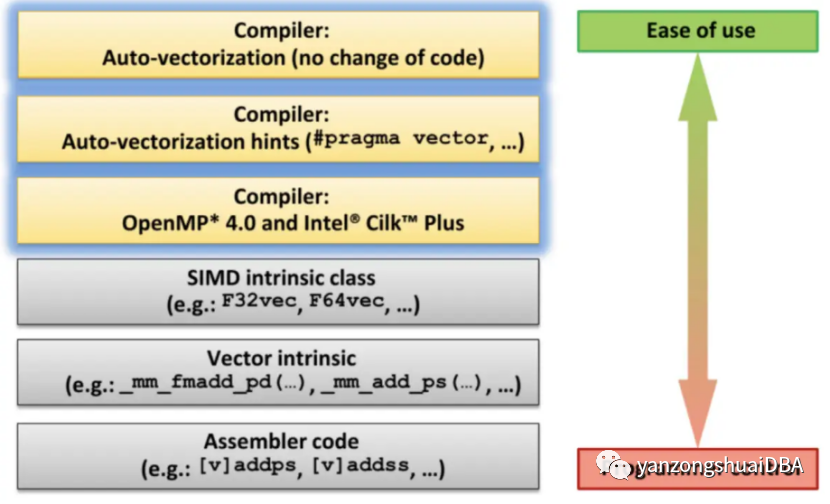
不需要更改代码,编译器会自动将标量代码转成向量化代码。只有一些简单的场景才能自动转换。OpenMP或者intel的TBB API可以帮助开发产生向量化代码。intrinsics是一组汇编码函数,允许使用C++函数调用和变量来代替汇编指令。考虑到上面的选项,我们希望尽可能多地调用编译器的自动生成矢量化。换言之,我们希望将重点放在方法1和方法2上。对于无法自动转换为矢量代码的性能关键操作,我们将使用SIMD内部函数。2.2 校验程序产生了SIMD代码
有这些选项,若产生了向量化代码则会输出,若没有产生会提示原因。例如添加:-fopt-info-vec-all, -fopt-info-vec-optimized, -fopt-info-vec-missed, 和-fopt-info-vec-note
可以使用perf或vtun或者https://gcc.godbolt.org/来检测。如果汇编代码中有xmm,ymm,zmm等或者以v开头的指令,那么就知道代码被向量化了。3、数据库向量化
虽然StarRocks项目已经发展成为一个成熟、稳定、行业领先的MPP数据库(甚至从CelerData衍生出了一个企业版),但社区必须克服许多挑战才能实现这一目标。我们最大的突破之一,数据库矢量化,也是我们最大的挑战之一3.1 挑战
数据的存储、传输、处理都需要以列式格式,需要消除存储、网络、内存层的“格式不匹配”。需要重新设计存储引擎和查询引擎。需要重新设计内存管理,从而充分利用CPU的SIMD并行能力核心算子需要的数据结构,比如Join\agg\sort等都需要重新设计以支持向量化5)算子和表达式需要尽可能使用SIMD指令。这需要逐行进行优化StarRocks目标是提升5倍性能,这就需要数据库中每个部件都进行充分优化。3.2 向量化算子和表达式
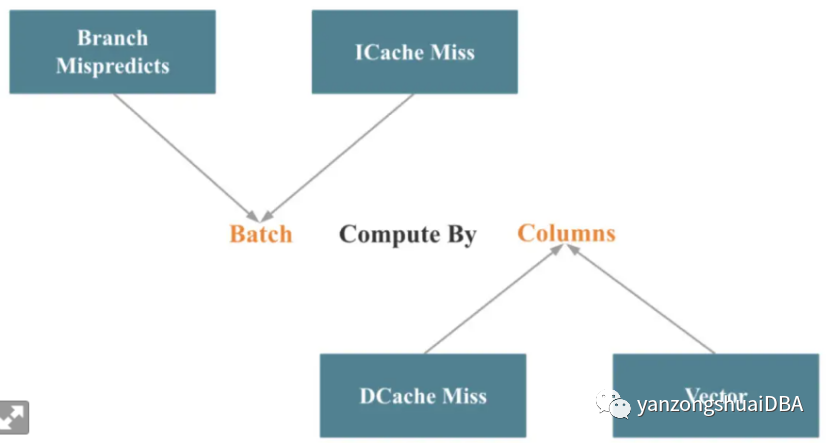
算子向量化和表达式向量化是主要模块。如上图,可总结为按列批量计算。Batch可以减少分支 misperdictions和instruction cache miss。按列计算可减少数据cache miss以及简化SIMD优化。实现batch计算相对容易,困难的是对关键操作比如join\agg\sort\shuffle等算子的列式处理。在进行列式处理的同时调用尽可能多的SIMD优化是一个更大的挑战。3.3 如何用数据库向量化提高数据库性能
前面提到,数据库向量化是一个巨大的、系统的性能优化工程,两年来,我们实现了数百个大大小小的优化点。我将 StarRocks 向量化两年多的性能优化经验总结为 7 个方面 (注意,由于向量化执行是单线程执行策略,所以下面的性能优化经验不涉及并发相关):高性能第三方库:在一些局部或者细节的地方,已经存在大量性能出色的开源库,这时候,我们可能没必要从头实现一些算法或者数据结构,使用高性能第三方库可以加速我们整个项目的进度。在 StarRcoks 中,我们使用了 Parallel Hashmap、Fmt、SIMD Json 和 Hyper Scan 等优秀的第三方库。数据结构和算法:高效的数据结构和算法可以直接在数量级上减少 CPU 指令数。在 StarRocks 2.0 中,我们引入了低基数全局字典,可以通过全局字典将字符串的相关操作转变成整型的相关操作。如下图所示,StarRcoks 将之前基于两个字符串的 Group By 变成了基于一个整型的 Group By,这样 Scan、Hash 计算、Equal、Memcpy 等操作都会有数倍的性能提升,整个查询最终会有 3 倍的性能提升。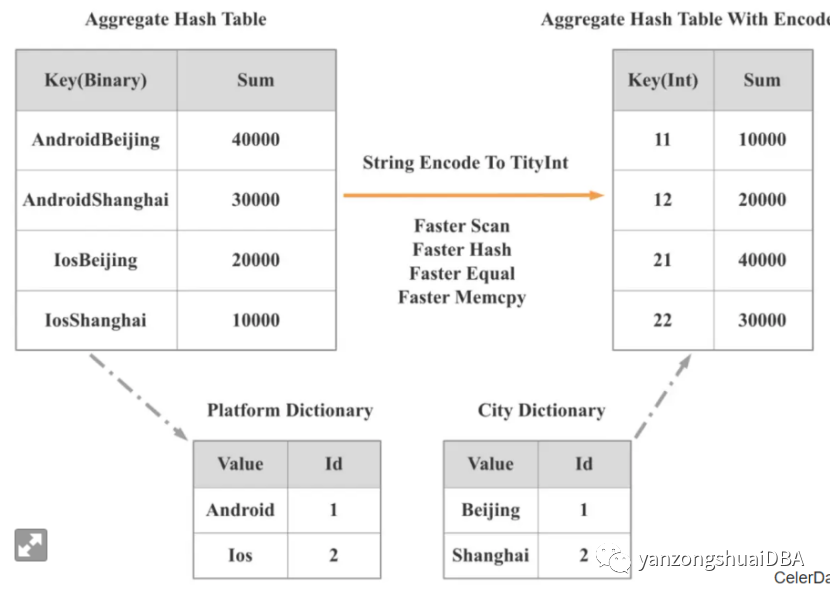
自适应优化:很多时候,如果我们拥有更多的上下文或者更多的信息,我们就可以做出更多针对性的优化,但是这些上下文或者信息有时只能在查询执行时才可以获取,所以我们必须在查询执行时根据上下文信息动态调整执行策略,这就是所谓的自适应优化。下图展示了一个根据选择率动态选择 Join Runtime Filter 的例子,有 3 个关键点:a. 如果一个 Filter 几乎不能过滤数据,我们就不选择;b. 如果一个 Filter 几乎可以把数据过滤完,我们就只保留一个 Filter;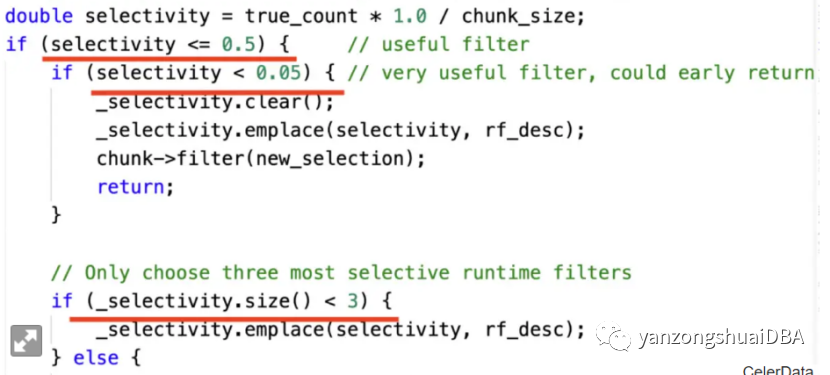
SIMD 优化:如下图所示,StarRcoks 在算子和表达式中大量使用了 SIMD 指令提升性能。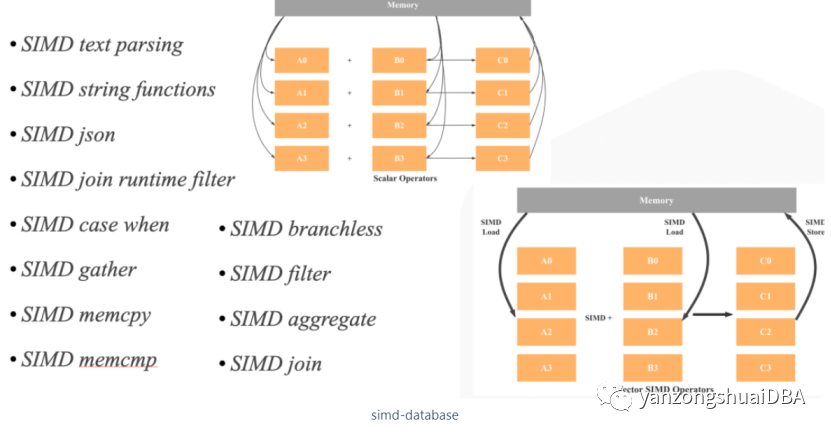
C++ Low Level 优化:即使是相同的数据结构、相同的算法,C++ 的不同实现,性能也可能相差好几倍,比如 Move 变成了 Copy,Vector 是否 Reserve,是否 Inline, 循环相关的各种优化,编译时计算等等。内存管理优化:当 Batch Size 越大、并发越高,内存申请和释放越频繁,内存管理对性能的影响越大。我们实现了一个 Column Pool,用来复用 Column 的内存,显著优化了整体的查询性能。下图是一个 HLL 聚合函数内存优化的代码示意,通过将 HLL 的内存分配变成按 Block 分配,并实现复用,将 HLL 的聚合性能直接提升了 5 倍。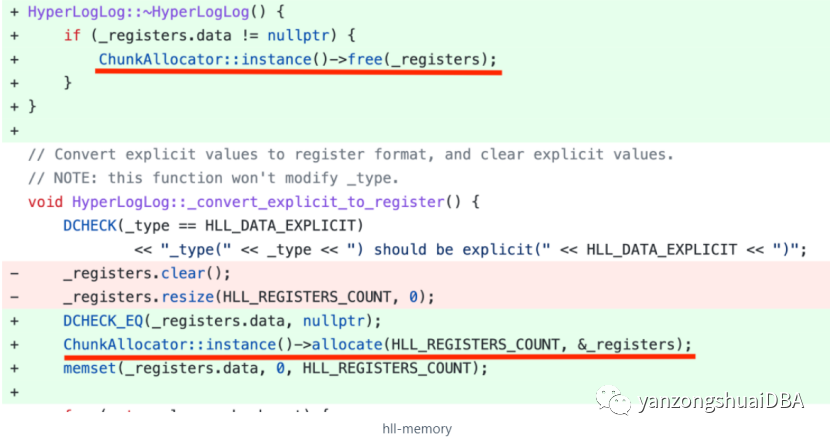
CPU Cache 优化:做性能优化的同学都应该对下图的数据了熟于心,清楚 CPU Cache Miss 对性能的影响是十分巨大的,尤其是我们启用了 SIMD 优化之后,程序的瓶颈就从 CPU Bound 变成了 Memory Bound。同时我们也应该清楚,随便程序的不断优化,程序的性能瓶颈会不断转移。L1 cache访问需要3个CPU周期,L2需要9个CPU周期,L3需要大约40个,主存则需要大约200个CPU周期。下面的代码展示了我们利用 Prefetch 优化 Cache Miss 的示例,我们需要知道,Prefetch 应该是最后一项优化 CPU Cache 的尝试手段,因为 Prefetch 的时机和距离比较难把握,需要充分测试。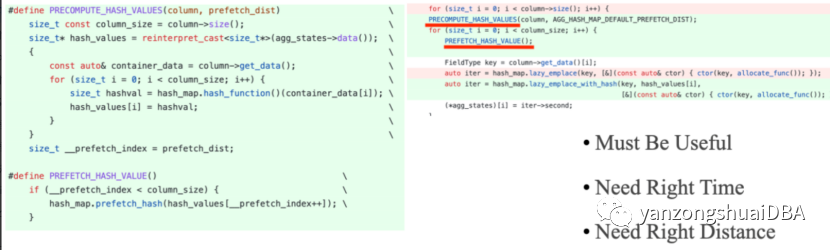
4、总结
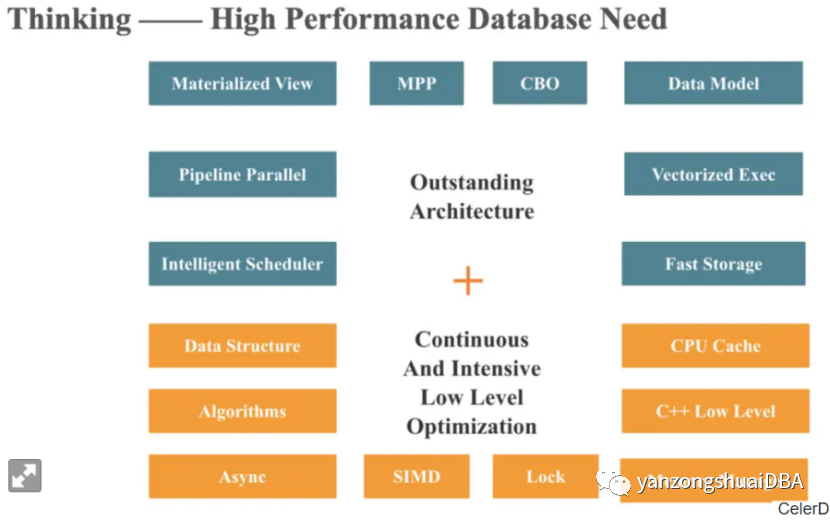
查询编译和SIMD向量化并不互相排斥,可结合协作提升性能。5、参考
https://www.infoworld.com/article/3678300/how-vectorization-improves-database-performance.htmlhttps://perf.bcmeng.com/2%20database-principle/executor.html#%E7%AE%97%E5%AD%90%E5%92%8C%E8%A1%A8%E8%BE%BE%E5%BC%8F%E5%90%91%E9%87%8F%E5%8C%96%E7%9A%84%E5%85%B3%E9%94%AE%E7%82%B9





