




1、什么是标量子查询
在Oracle中,标量子查询是指返回单个值的子查询。它可以嵌套在SELECT语句的列表中,作为一个列的值返回。标量子查询经常用于计算和检索单个值,然后将其用于其他查询或操作中的条件。
示例:
create table dw1106 as select * from dba_objects where rownum <10000;
create table dw1106a as select * from dba_objects where rownum <1000;
update dw1106 set edition_name=object_name;
commit;select a.object_name,(select object_name from dw1106a b where a.object_id=b.object_id) as new from dw1106 a where a.object_id<5000; 其中(select object_name from dw1106a b where a.object_id=b.object_id)就是标量子查询部分,在满足a.object_id<5000中的每一行数据中,都需要对(select object_name from dw1106a b where a.object_id=b.object_id)标量子查询进行扫描运算如循环运算,在满足a.object_id<5000;所有行中,每一个值都要进行(select object_name from dw1106a b where b.object_id= :x),如果b.object_id= x在子查询没有值的时候,返回为空值而且子查询部分必须是唯一一个值,多值时,在扫描到该行时则会报错 ORA 01427 单行子查询返回多个行查看标量子查询的真实的执行计划
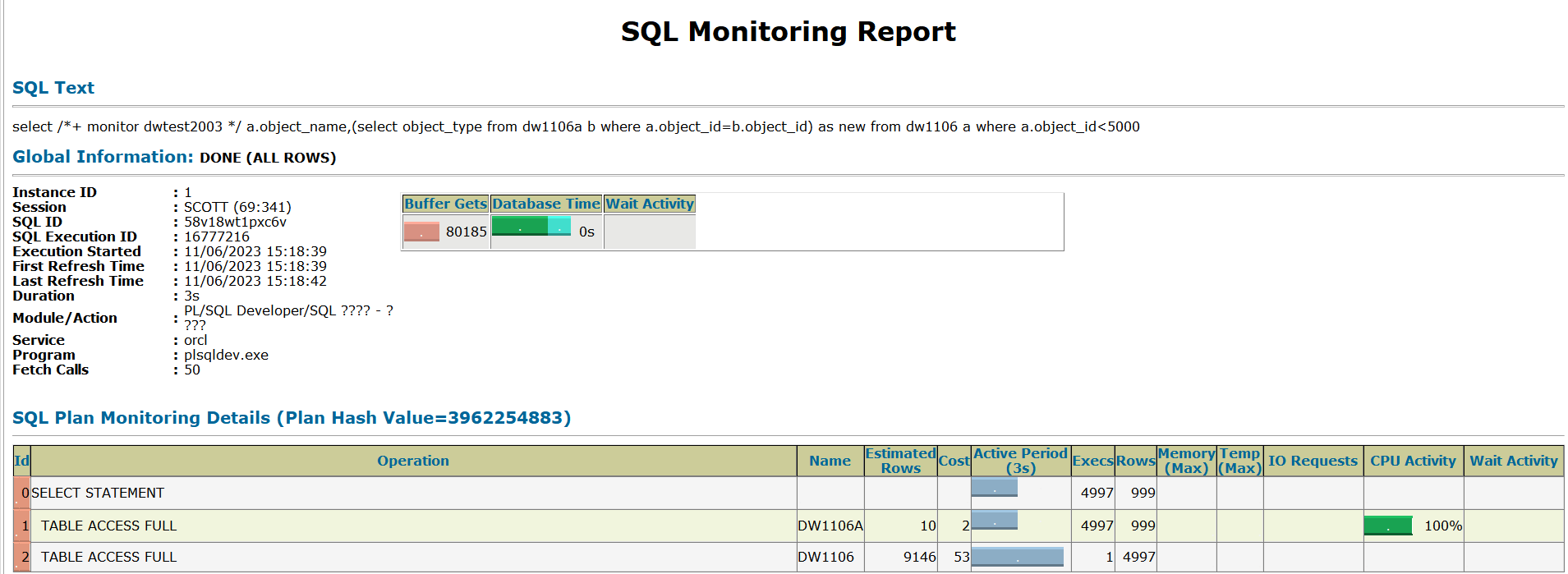
可以看到DW1106A 被执行了4997次,因为select count(1) from dw1106 a where a.object_id<5000; a.object_id<5000对应的行数就是4997;
这样的标量子查询消耗大量逻辑读,多次对子查询部分进行扫描,在不改写语句的情况下,如果关联字段适合创建索引的话,可以创建索引。
create index idex1 on dw1106(object_id);
create index idex2 on dw1106a(object_id);此时查看标量子查询的真实的执行计划:
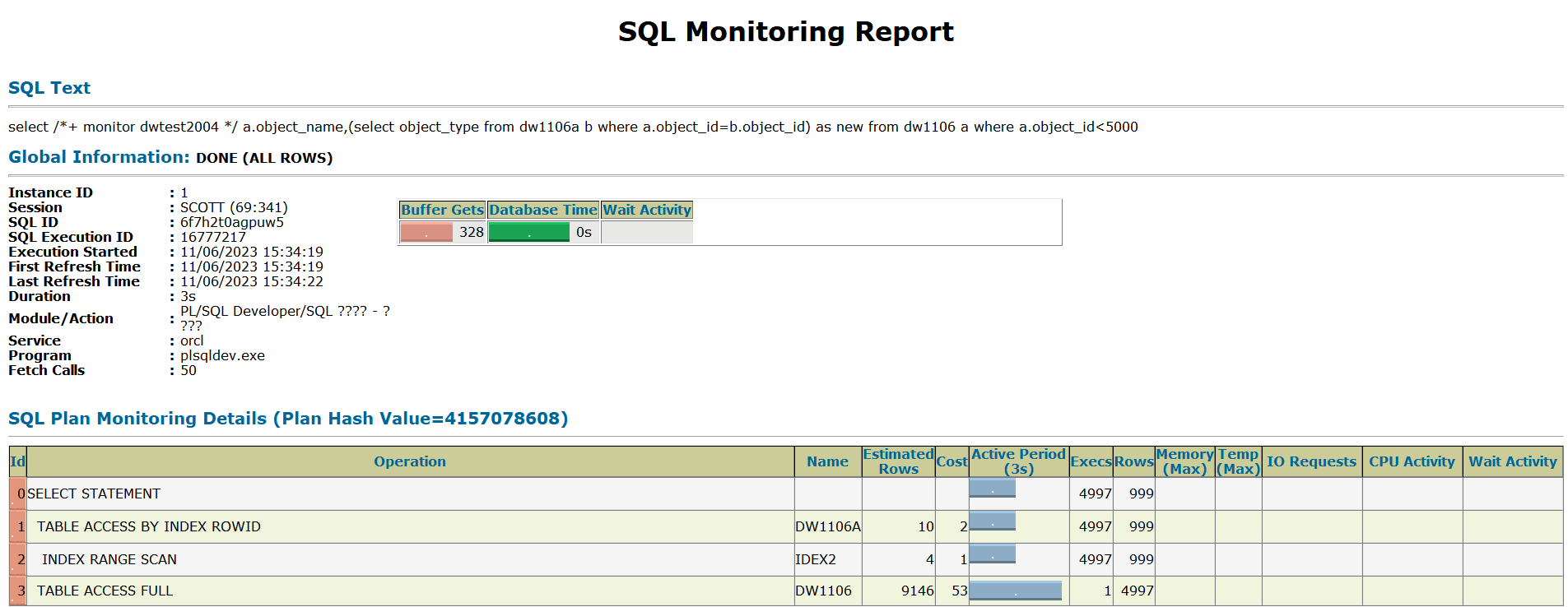
标量子查询部分还是被执行4997次,但是其扫描方式是索引范围扫描了,主表这次还是全表扫描,是因为object_id<5000扫描的数量太多,全表的一半,走索引还不如全表扫描(多块读)效率高。
走索引后逻辑读大大降低了。
2、left join 改写优化标量子查询
可以将上述标量子查询修改下
select a.object_name,b.object_name as new from dw1106 a left join dw1106a b on a.object_id=b.object_id where a.object_id<5000;
其执行计划如下:
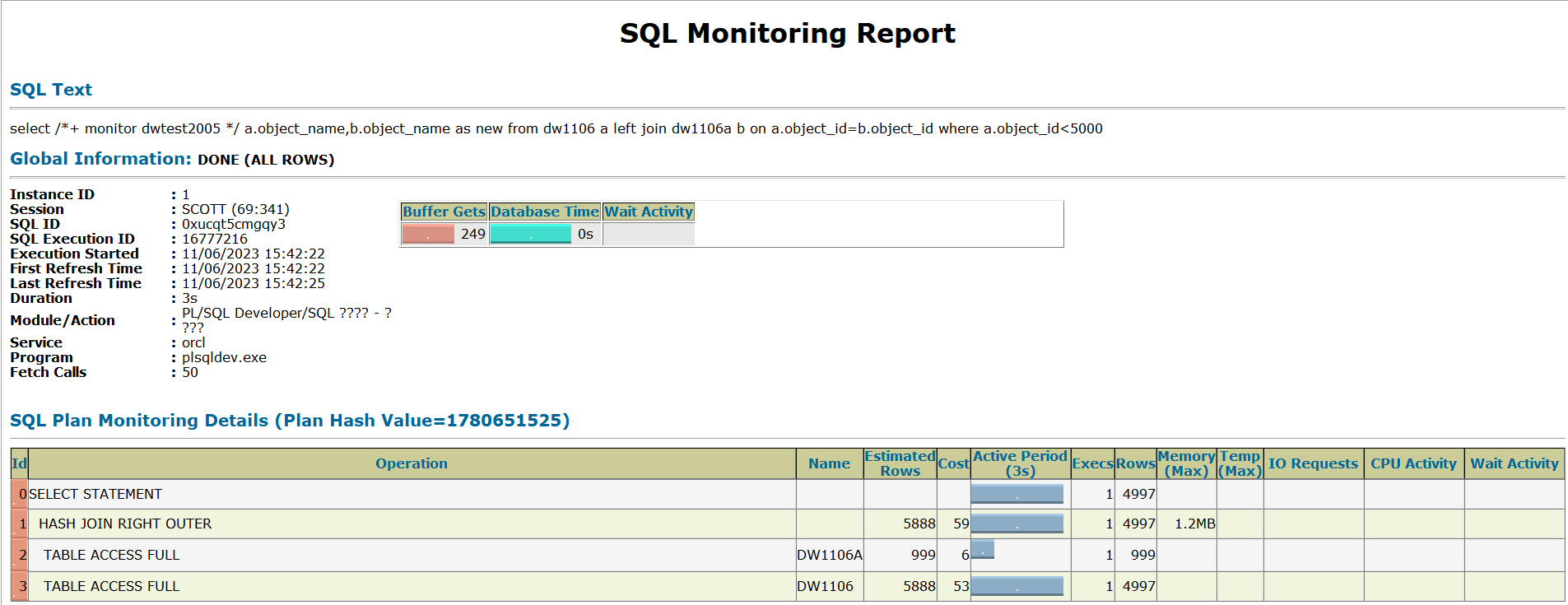
对两个表都是扫描了一次,相比第一次的语句逻辑读降低很多,如果两个表都很大时,而且关联字段没有索引是,多次对子查询部分扫描将非常耗时。
所以建议在存在标量子查询是建议对其进行left join改写。
3、关于update的标量子查询类似的更新(一般update不称为标量子查询)
生产上类似如下这样的语句:
update dw1106 a set a.edition_name=(select b.object_name from dw1106a b where a.object_id=b.object_id) where a.object_id<5000;
其中a.edition_name=(select b.object_name from dw1106a b where a.object_id=b.object_id) 也是相当于select时候的标量子查询,在
where a.object_id<5000满足多少行时,子查询部分就需要执行多少次。
那么我们将该更新方式通过merge Into的方式改写下:
MERGE INTO dw1106 a USING dw1106a b ON (a.object_id=b.object_id)
WHEN MATCHED THEN UPDATE SET a.edition_name=b.object_name where a.object_id<5000;可能有什么问题呢?
!!!
注意此时,如果b.object_id= x在子查询没有值的时候,返回为空值,但是merge因为务必是条件满足时才更新操作,所以merger对不满足a.object_id=b.object_id时
是不更新的。
而,update dw1106 a set a.edition_name=(select b.object_name from dw1106a b where a.object_id=b.object_id) where a.object_id<5000;这语句是会更新的为空的。
一切改写都是要满足不改变其原有结果集的,所以上面的改写方式存在问题 。
而且merge into 不支持 WHEN not MATCHED THEN UPDATE SET的方式(我这测试没有通过,万能网友是否有其他的merge的对不满足情况下还能更新吗)。
此时建议:1、咨询业务情况,是否有关联条件不匹配的情况,如果没有,则按上述方式改写。
2、其他方式改写,针对此例我尝试了下这样的方式,对主表进行两次全表扫描,对子查询表一次全表扫描,其意义就是用关联将object_id,空值也关联出来,再进行merge
更新。
MERGE INTO dw1106 a USING (select d.object_name,c.object_id as object_id from dw1106 c left join dw1106a d on c.object_id=d.object_id where c.object_id<5000)
b ON (a.object_id=b.object_id )
WHEN MATCHED THEN UPDATE SET a.edition_name=b.object_name where a.object_id<5000; Plan Hash Value : 4089592994
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
---------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 5848 | 1672528 | 112 | 00:00:02 |
| 1 | MERGE | DW1106 | | | | |
| 2 | VIEW | | | | | |
| * 3 | HASH JOIN | | 5848 | 1818728 | 112 | 00:00:02 |
| * 4 | HASH JOIN RIGHT OUTER | | 5848 | 538016 | 59 | 00:00:01 |
| * 5 | TABLE ACCESS FULL | DW1106A | 999 | 78921 | 6 | 00:00:01 |
| * 6 | TABLE ACCESS FULL | DW1106 | 5848 | 76024 | 53 | 00:00:01 |
| * 7 | TABLE ACCESS FULL | DW1106 | 5848 | 1280712 | 53 | 00:00:01 |
4、总结
4.1、遇到标量子查询都需要多注意,尝试改写
4.2、针对改写后的结果集与改写前进行比较,避免极端情况
4.3、理解标量子查询的运算方法,万变不离其宗
