




频繁模式增长算法(FP-growth)
频繁模式增长算法(Frequent Pattern-Growth, FP-Growth),它采取如下分治策略:将提供频 繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。其中使用了一种称为 频繁模式树(Frequent Pattern Tree)的数据结构,FP-tree 是一种特殊的前缀树,由频繁项头表和 项前缀树构成。FP-Growth 算法基于以上的结构加快整个挖掘过程。
关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集 合或对象集合之间的频繁模式、关联、相关性或因果结构。关联分析的一个典型例子是购物篮分 析。通过发现顾客放入购物篮中不同商品之间的联系,分析顾客的购买习惯。比如,67%的顾客 在购买尿布的同时也会购买啤酒。通过了解哪些商品频繁地被顾客同时购买,可以帮助零售商制 定营销策略。关联分析也可以应用于其他领域,如生物信息学、医疗诊断、网页挖掘和科学数据 分析等。
FP 树的算法主要由两大步骤完成:
(1)利用数据集构建 FP-Tree
(2)建立频繁项集规则
为了更好的理解建树规则,这里以具体例子进行说明。
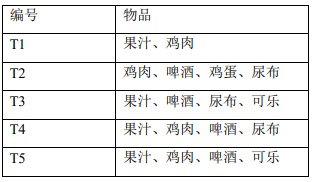
假设有一个购物清单,如下表:
购物清单
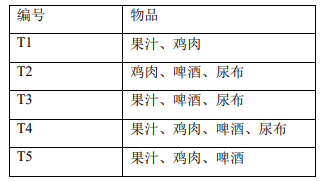
FP 树算法第一步就是扫描数据集,将样本按照递减规则排序,删除小于最小支持度的样本, 排序后的物品清单如下表所示:
过滤并排序后的物品清单
下面开始构建 FP 树。将表 5.1.1.2 中重新生成的数据插入到 FP 树中。root 是空集,用来建立
后续的 FP 树。之后继续插入第二条记录。之后逐条将记录插入到该树中,直
至全部插入完成。
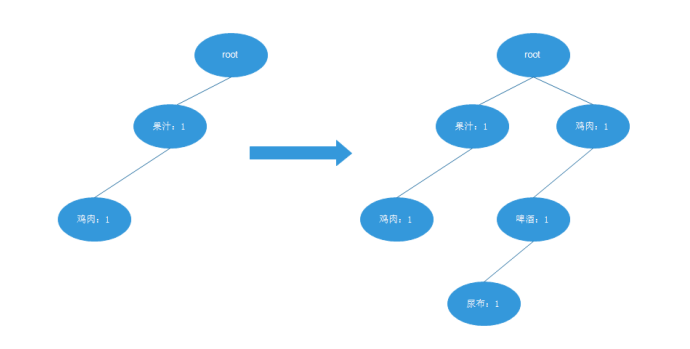
FP-growth 算法流程 1-2 记录插入
建立对应的树之后,就可以开始频繁项集挖掘工作。这里采用逆向路径工程对数据进行数据 归类。首先需要建立的是样本路径。
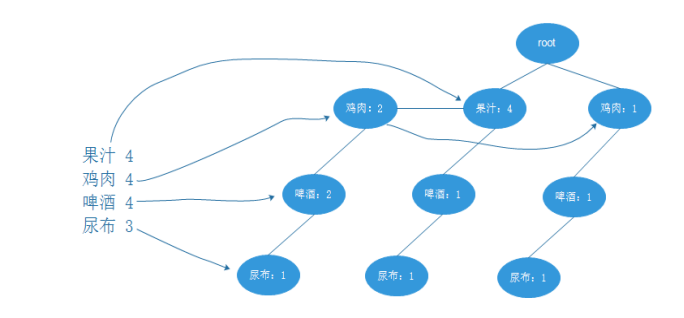
FP-Growth 算法流程
假设这里求“啤酒、尿布”的包含清单,则从支持度最小项开始,可以获得如下数据:

之后从这个新生成的表中递归查找包含“尿布”的项,并计算相关置信度。
