




1.总体公式
路由选择考量分数计算=实例负载+缓存因子计算+网络消耗计算+SQL消耗分析
对应计算公式如下:
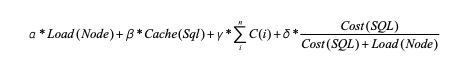
分数值越高,即综合评估负载越高,则对应节点被选择的可能性越低。
2.实例负载情况(权重α)
C代表实例节点CPU利用率,c代表该因子自定义权重。R代表实例节点内存利用率,N代表网络利用率,P代表连接利用率,Ability代表实例处理能力因子指标。
3.SQL最优缓存节点挑选(权重β)
解析SQL,记录历史SQL执行情况,根据同一库,同一表的情况判断是否可能缓存,及缓存存在可能分值(1~100) (缓存越有可能,分值越低)SQL缓存亲和性因子,记为Cache(SQL);
4.挑选到实例节点最优网络路径(权重γ)
类似于LDC路由、Primary Zone路由,通过路由到各个数据库实例节点的最优路径选择,同一子网>不同子网(几跳)>同机房>同城不同机房>不同城市,通过整体路由路径的几跳进行筛选。网络路由跳数记为i,每一跳涉及网络开销或者损耗用函数C(i)计算,则网络路径总体开销为:
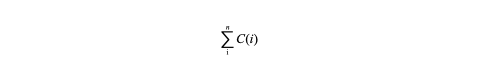
5. SQL分析消耗cpu和消耗io(权重δ)
通过Parser模块,类比数据库中的EXPLAIN (ANALYZE ``on``, TIMING ``on``, VERBOSE ``on``, BUFFERS ``on``, COSTS ``on``) sql,可以看到整体SQL执行花销,包括每个计划节点的启动成本预估和总成本的消耗。
主要分为启动和运行成本,为了区分SQL类型,主要分为以下两种:
顺序扫描成本:
(1)启动成本
0
(2)运行成本
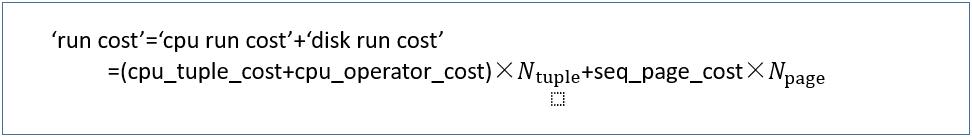
查询表的块数和行数

seq_page_cost=1.0默认,cpu_tupe_cost=0.01默认,cpu_operator_cost=0.0025默认;
索引扫描成本:
(1)启动成本
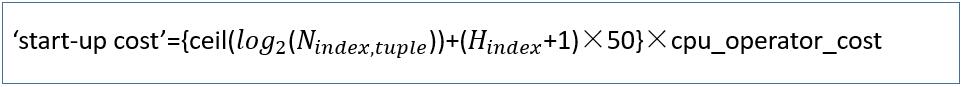
H_index指的是索引的高度,N是行数。
(2)运行成本
索引扫描的运行成本是表和索引的cpu成本和IO(输入/输出)成本之和
‘run cost’=(‘index cpu cost’+’table cpu cost’)+(‘index IO cost’+’table IO cost’)
计算如下:

table IO cost=max_IO_cost+indexCorrelation^2*(min_IO_cost-max_IO_cost)
- Selectivity选择性:
表的每一列的MCV(Most Common Value)作为一对most_common_vals和most_common_freqs的列存储在pg_stats视图中,most_common_vals(最常见的的值)是统计MCVs列表的列,most_common_freqs(最常见值的频率)是统计mcv的频率列,类似一个列值占所有值的比率。
cpu_index_tuple_cost=0.005,qual_op_cost=0.0025,random_page_cost=4.0
- Table IO Cost计算:
indexCorrelation为索引列相关性:asc为1,desc为-1,random为0.125874
max_IO_cost=N(page)*random_page_cost
min_IO_cost=1*random_page_cost=(ceil(Selectivity*N(page)-1)*seq_page_cost
